不幸的是,我找不到质量更好的免费模型,但是我仍然对这位海外雕塑家以数字方式吸引我表示感谢!正如您可能已经猜到的那样,我们将讨论编写CPU-渲染。
理念
随着着色器语言的发展以及GPU功能的增强,越来越多的人对图形编程感兴趣。已经出现了新的发展方向,例如Ray迅速普及。
考虑到NVidia会发布一个新的怪兽,我决定写我自己的文章(关于管子和老派的文章),介绍CPU渲染的基础知识。这反映了我个人编写渲染的经验,在其中我将尝试传达在编码过程中遇到的概念和算法。应当理解,由于处理器不适合执行此类任务,因此该软件的性能将非常低。
语言的选择最初落入c ++或rust,但我决定使用c#由于易于编写代码和充足的优化机会。本文的最终产品将是能够产生如下图像的渲染器:


我在这里使用的所有模型都是在公共领域分发的,请勿盗版和尊重艺术家的作品!
数学
不用说,在不了解其数学基础的情况下将渲染写在哪里。在本节中,我将仅介绍我在代码中使用的概念。我不建议那些不确定其知识的人跳过本节,如果不了解这些基础知识,将很难理解进一步的介绍。我还希望那些决定学习计算几何的人将具有线性代数,几何以及三角学(角度,向量,矩阵,点积)的基础知识。对于那些想更深入地了解计算几何的人,我可以推荐E. Nikulin的书《计算机几何和计算机图形算法》。
矢量转弯。旋转矩阵
旋转是向量空间的基本线性变换之一。这也是正交变换,因为它保留了变换后的矢量的长度。2D空间中有两种旋转类型:
- 相对于原点的旋转
- 旋转一点
在这里,我将仅考虑第一种类型,因为 第二个是第一个的派生,仅在旋转坐标系的变化上有所不同(我们将进一步分析坐标系)。
让我们得出在二维空间中旋转向量的公式。让我们表示原始向量的坐标- {x,y}。旋转了角度f的新矢量的坐标将表示为{x'y'}。
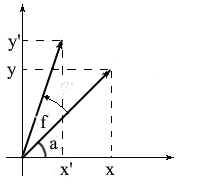
我们知道这些向量的长度是常见的,因此我们可以使用余弦和正弦的概念,以便根据围绕OX轴的长度和角度来表达这些向量:

注意,我们可以使用求和和余弦公式来扩展x'和y'值。对于那些已经忘记的人,我会提醒这些公式:
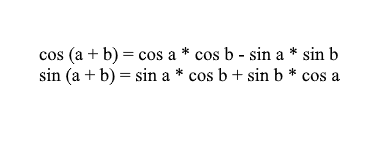
通过它们扩展旋转矢量的坐标,我们得到:

在这里容易看出,因子l * cos a和l * sin a是原始向量的坐标:x = l * cos a,y = l * sin a。让我们用x和y替换它们:

因此,我们根据原始矢量的坐标及其旋转角度来表达旋转后的矢量。作为矩阵,此表达式将如下所示:
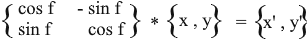
乘以并检查结果是否等于我们推导出的结果。
在3D空间中旋转
我们考虑了二维空间中的旋转,并为其导出了矩阵。现在出现了问题,如何在三个维度上获得这种转换?在二维情况下,我们在一个平面上旋转矢量,但是这里相对于无限个平面,我们可以做到这一点。但是,可以使用三种基本的旋转类型来表达矢量在三维空间中的任何旋转-分别是XY,XZ,YZ旋转。
XY旋转。
通过这种旋转,我们绕着坐标系的OZ轴旋转矢量。想象一下,向量是直升飞机的桨叶,而OZ轴是它们保持的桅杆。带XY向量的旋转将绕OZ轴旋转,就像直升机相对于桅杆的叶片一样。

请注意,通过这种旋转,矢量的z坐标不会改变,但是x和x坐标会改变-这就是为什么将其称为XY旋转。
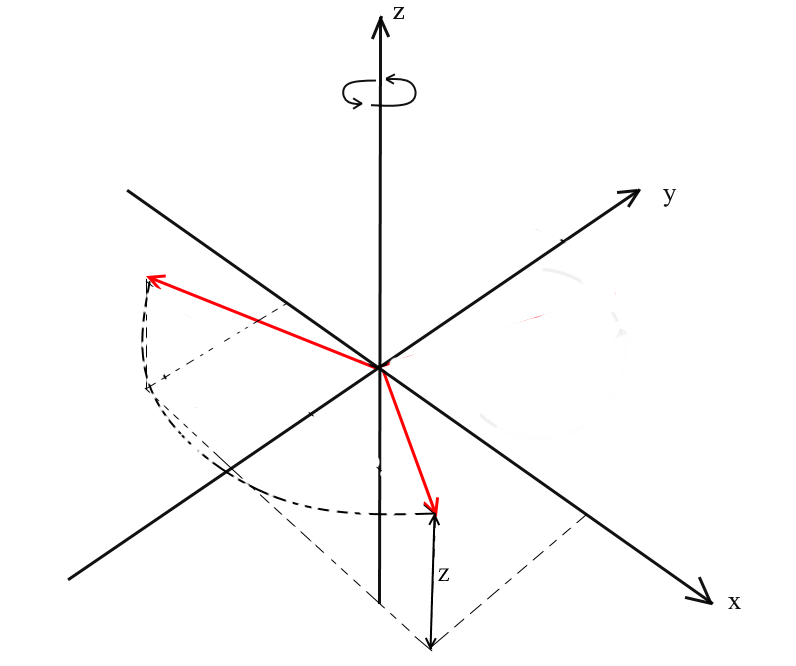
不难得出这种旋转的公式:z-坐标保持不变,x和y根据与2D旋转相同的原理进行更改。
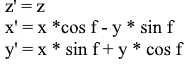
矩阵形式相同:
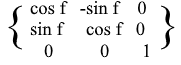
对于XZ和YZ旋转,一切都相同:


投影
投影的概念可以根据使用的上下文而变化。许多人可能听说过这样的概念,例如在平面上投影或在坐标轴上投影。
根据我们在此使用的理解,向量上的投影也是向量。它的坐标是从向量a到b的垂直线与向量b的交点。
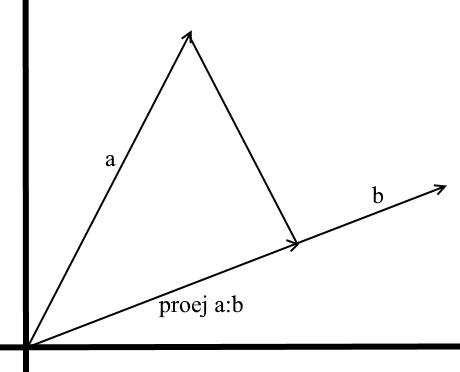
为了定义这样一个向量,我们需要知道它的长度和方向。众所周知,直角三角形中的相邻边和斜边与余弦比相关,因此我们用它来表示投影矢量的长度:
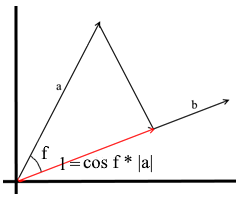
根据定义,投影向量的方向与向量b一致,这意味着投影由以下公式确定:
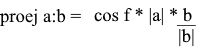
在这里,我们将投影的方向作为单位矢量,并将其乘以投影的长度。不难理解,结果将正是我们所寻找的。
现在让我们用点积来表示一切:

我们得到一个方便的公式来找到投影:
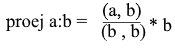
坐标系。基地
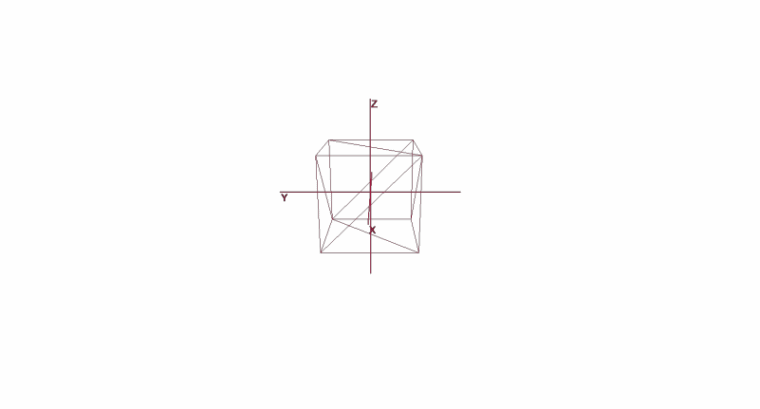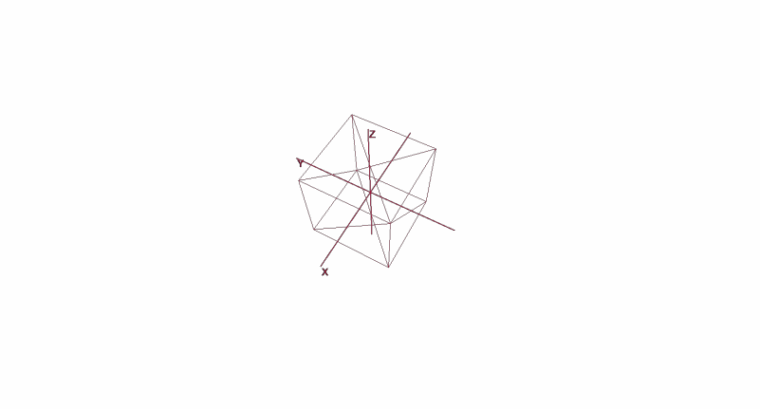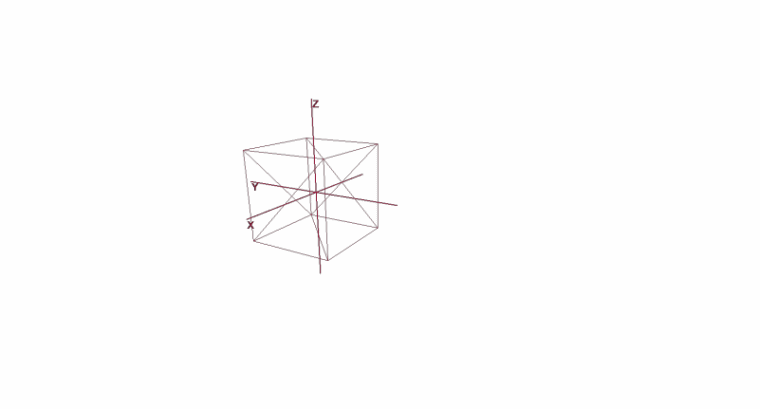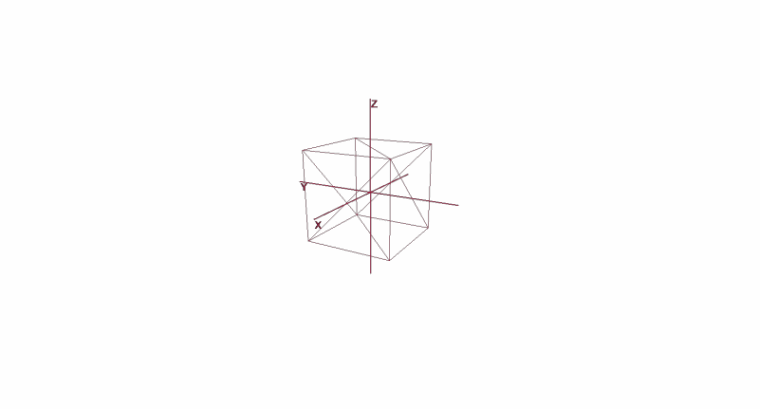
许多人习惯于在标准XYZ坐标系中工作,在该坐标系中,任意两个轴将相互垂直,并且坐标轴可以表示为单位向量:

实际上,有无限多个坐标系,每个坐标系都是一个基础。n维空间的基础是向量{v1,v2…vn}的集合,通过这些向量表示该空间的所有向量。在这种情况下,无法通过其其他向量表示基础中的向量。实际上,每个基础都是一个单独的坐标系,其中矢量将具有其自己的唯一坐标。
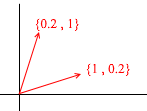
让我们看看二维空间的基础是什么。以熟悉的向量X {1,0},Y {0,1 }的笛卡尔坐标系为例,它是二维空间的底数之一:
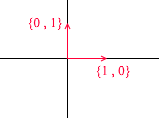
平面上的任何向量都可以表示为具有某些系数的该基础向量的总和,或表示为线性组合。记住写下向量的坐标时所做的操作-输入x-坐标,然后输入-y。这就是您实际根据基向量确定膨胀系数的方式。

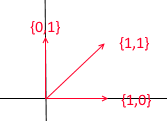
现在让我们再考虑一个基础:
任何2D向量也可以通过其向量表示:

但是这样的向量集不是二维空间的基础:

其中,两个向量{1,1}和{2,2}位于一条直线上。无论采用哪种组合,您都只会收到位于公共直线y = x上的向量。就我们的目的而言,这种有缺陷的功能将无用,但是,我认为有必要了解它们之间的区别。根据定义,所有基都由一个属性组合在一起-没有一个基矢量可以表示为具有系数的其他基矢量的总和,或者没有一个基矢量是其他基矢量的线性组合。这是一组3个向量的示例,这也不是基础:
的二维平面中的任何载体可以通过它来表达,但向量{1,1}中它是多余的,因为它本身可以通过载体表达{1,0}和{0,1}为{1,0} + {0,1 }。
通常,n维空间的任何基础都将恰好包含n个向量,对于2e而言,该n分别等于2。
让我们转向3d。三维基础将包含3个向量:
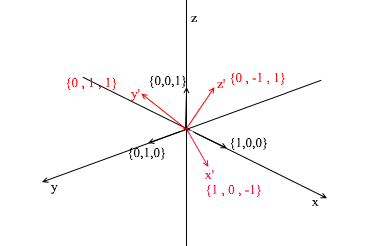
如果以二维为基础,两个向量不在一条直线上就足够了,那么在三维空间中,如果满足以下条件,则向量集将成为基础:
- 1)2个向量不在一条直线上
- 2)第三个不位于其他两个所形成的平面上。
从现在开始,我们使用的基数将是正交的(它们的任何向量都是垂直的)并进行规范化(任何基向量的长度为1)。我们根本不需要其他人。例如,标准依据
符合这些条件。
过渡到另一个基础
到目前为止,我们已经将向量的分解写为具有系数的基本向量之和:

再次考虑标准基础-其中的向量{1、3、6}可以写成如下形式:
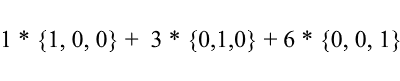
如您所见,向量在该基础上的展开系数就是该基础上的坐标。让我们看下面的例子:
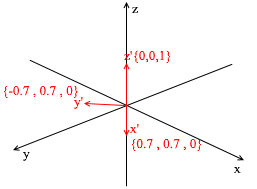
通过向该标准应用XY旋转45度,可以从该标准中得出此基础。在标准系统中以坐标{0,1,1}取向量a
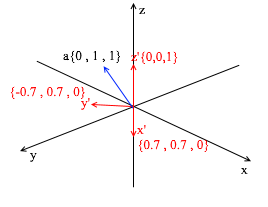
通过新基础的向量,可以将其扩展如下:
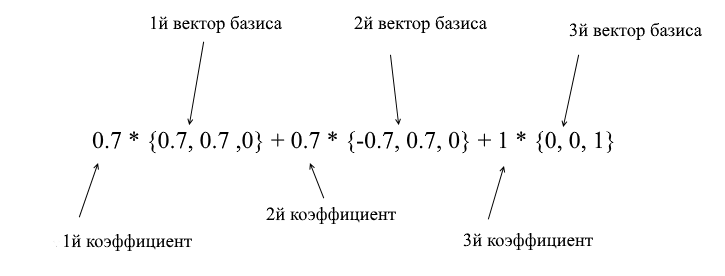
如果您计算此金额,您将得到{0,1,1} -标准中的向量a。基于新表达式中的该表达式,向量a具有坐标{0.7,0.7,1} -膨胀系数。如果从其他角度看,这将更加明显:
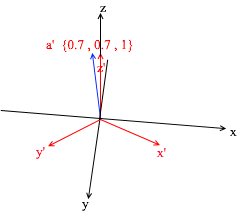
但是,您如何找到这些系数?通常,通用方法是一个相当复杂的线性方程组的解。但是,正如我之前所说,我们将仅使用正交和归一化的碱基,对于它们而言,这是一种非常欺骗的方法。它在于找到对基向量的投影。让我们用它在X {0.7,0.7,0} Y {-0.7,0.7,0} Z {0,0,1}的基础上找到向量a的分解
首先,让我们找到y'的系数。第一步是找到向量a在向量y'上的投影(我在上面讨论了如何执行此操作):
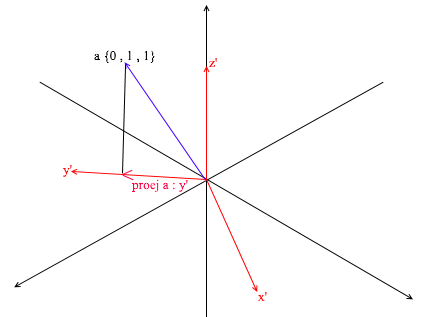
第二步:将找到的投影的长度除以向量y'的长度,从而找出“投影向量中适合多少个向量y'”-这个数字将是y'的系数,并且y-向量a在新的基础上的坐标!对于x'和z',重复类似的操作:

现在,我们有了从标准基础到新基础的过渡公式:
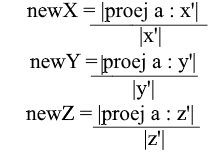
好吧,由于我们仅使用归一化的基数,并且其向量的长度等于1,因此在转移公式中无需除以向量的长度:
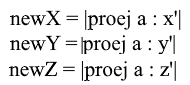
通过投影公式 展开x坐标:

注意,在归一化的情况下,分母(x',x')和向量x'也为1,可以丢弃。我们得到:

我们看到,基础中的x坐标分别表示为点积(a,x'),y坐标表示为(a,y'),z坐标表示为(a,z')。现在,您可以创建一个过渡到新坐标的矩阵:

偏移坐标系
我们上面考虑的所有坐标系的原点均为{0,0,0}。此外,还有一些原点偏移的系统:
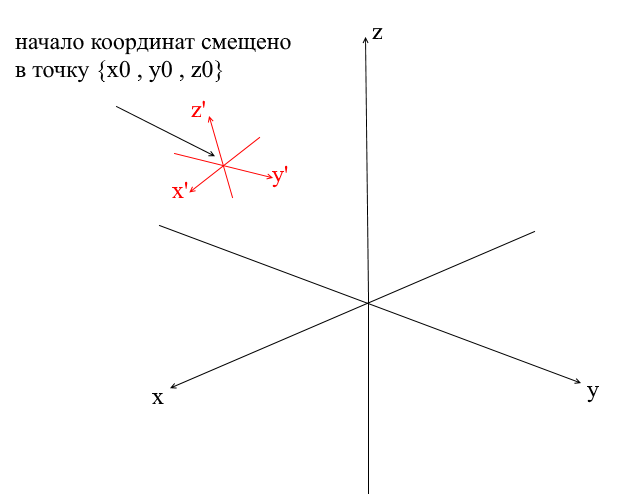
为了将向量转换成这样的系统,必须首先相对于新的坐标中心表达它。要做到这一点很简单-从向量中减去该中心。因此,您可以将坐标系本身“移动”到新的中心,而矢量仍保留在原位。接下来,您可以使用我们已经熟悉的转换矩阵。
编写几何引擎。创建导线渲染。
好吧,我认为可以通过一些有趣的事情来洗脑,这是谁完成了数学部分并且没有关闭本文的内容!在本节中,我们将开始编写3D引擎和渲染的基础知识。通常,渲染是一个相当复杂的过程,其中包括许多不同的操作:切掉不可见的边缘,光栅化,计算光,处理各种效果,材质(有时甚至是物理)。将来,我们将部分分析所有这些内容,但是现在,我们将做更多简单的事情-我们将编写连线渲染。它的本质是它以连接其顶点的线的形式绘制对象,因此结果看起来像是一个线网:

多边形图形
传统上,计算机图形使用3D对象数据的多边形表示。因此,数据以OBJ,3DS,FBX和许多其他形式呈现。在计算机中,此类数据以两组形式存储:一组顶点和一组面(多边形)。一个对象的每个顶点由其在空间中的位置(一个向量)表示,每个面(多边形)由三个整数表示,这些整数是该对象的顶点的索引。最简单的对象(立方体,球体等)由这些多边形组成,称为基本体。
在我们的引擎中,图元将是3D几何的主要对象-所有其他对象都将从其继承。让我们描述原语的类:
abstract class Primitive
{
public Vector3[] Vertices { get; protected set; }
public int[] Indexes { get; protected set; }
}
到目前为止,一切都很简单-存在图元的顶点,并且存在用于形成多边形的索引。现在,您可以使用此类创建多维数据集:
public class Cube : Primitive
{
public Cube(Vector3 center, float sideLen)
{
var d = sideLen / 2;
Vertices = new Vector3[]
{
new Vector3(center.X - d , center.Y - d, center.Z - d) ,
new Vector3(center.X - d , center.Y - d, center.Z) ,
new Vector3(center.X - d , center.Y , center.Z - d) ,
new Vector3(center.X - d , center.Y , center.Z) ,
new Vector3(center.X + d , center.Y - d, center.Z - d) ,
new Vector3(center.X + d , center.Y - d, center.Z) ,
new Vector3(center.X + d , center.Y + d, center.Z - d) ,
new Vector3(center.X + d , center.Y + d, center.Z + d) ,
};
Indexes = new int[]
{
1,2,4 ,
1,3,4 ,
1,2,6 ,
1,5,6 ,
5,6,8 ,
5,7,8 ,
8,4,3 ,
8,7,3 ,
4,2,8 ,
2,8,6 ,
3,1,7 ,
1,7,5
};
}
}
int Main()
{
var cube = new Cube(new Vector3(0, 0, 0), 2);
}

实施坐标系
仅用一组多边形设置对象是不够的;要计划和创建复杂的场景,您需要将对象放置在不同的位置,旋转它们,减小或增大它们的大小。为了方便这些操作,使用了所谓的局部和全局坐标系。场景中的每个对象都有其自己的坐标系-局部坐标以及自己的中心点。
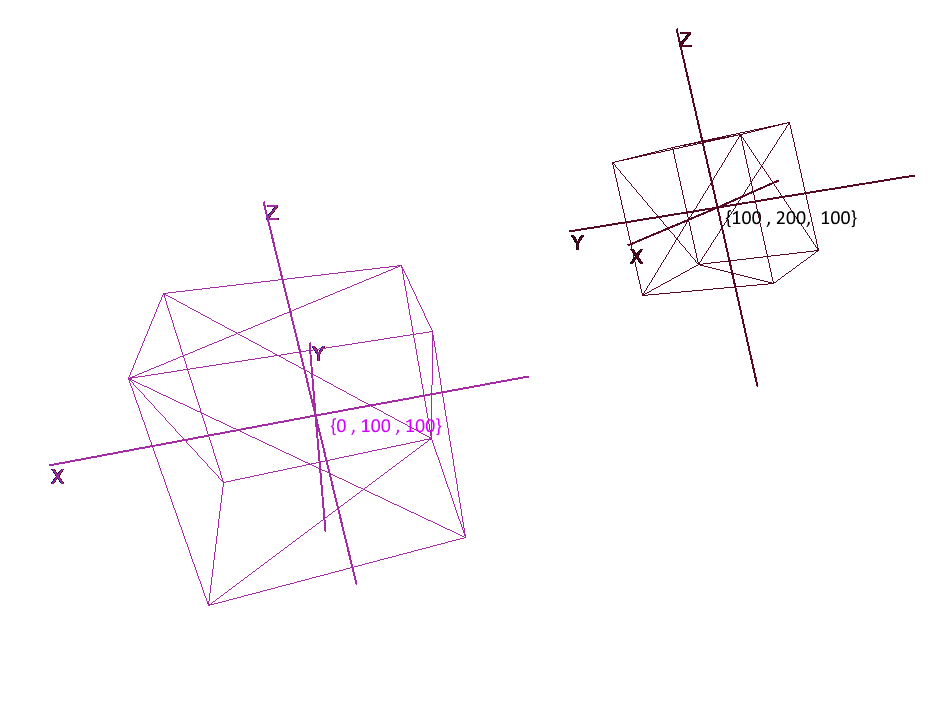
用局部坐标表示对象可以轻松地对其执行任何操作。例如,要将对象移动向量a,将其坐标系的中心移动此向量就足够了,从而旋转对象-旋转其局部坐标。
使用对象时,我们将在局部坐标系中对其顶点进行操作;在渲染过程中,我们将首先将场景中的所有对象转换为一个坐标系-全局坐标系。让我们向代码添加坐标系。为此,创建一个Pivot类的对象(pivot,枢轴点),该对象将表示该对象的本地基础及其中心点。将点转换为Pivot呈现的坐标系将分两个步骤完成:
- 1)相对于新坐标中心的点的表示
- 2)扩展新的向量
相反,为了以全局坐标表示对象的局部顶点,必须以相反的顺序执行以下操作:
- 1)扩大全球基础
- 2)相对于全球中心的代表
让我们编写一个表示坐标系的类:
public class Pivot
{
//
public Vector3 Center { get; private set; }
// -
public Vector3 XAxis { get; private set; }
public Vector3 YAxis { get; private set; }
public Vector3 ZAxis { get; private set; }
//
public Matrix3x3 LocalCoordsMatrix => new Matrix3x3
(
XAxis.X, YAxis.X, ZAxis.X,
XAxis.Y, YAxis.Y, ZAxis.Y,
XAxis.Z, YAxis.Z, ZAxis.Z
);
//
public Matrix3x3 GlobalCoordsMatrix => new Matrix3x3
(
XAxis.X , XAxis.Y , XAxis.Z,
YAxis.X , YAxis.Y , YAxis.Z,
ZAxis.X , ZAxis.Y , ZAxis.Z
);
public Vector3 ToLocalCoords(Vector3 global)
{
//
return LocalCoordsMatrix * (global - Center);
}
public Vector3 ToGlobalCoords(Vector3 local)
{
// -
return (GlobalCoordsMatrix * local) + Center;
}
public void Move(Vector3 v)
{
Center += v;
}
public void Rotate(float angle, Axis axis)
{
XAxis = XAxis.Rotate(angle, axis);
YAxis = YAxis.Rotate(angle, axis);
ZAxis = ZAxis.Rotate(angle, axis);
}
}
现在,使用此类,向原语添加旋转,移动和增加的功能:
public abstract class Primitive
{
//
public Pivot Pivot { get; protected set; }
//
public Vector3[] LocalVertices { get; protected set; }
//
public Vector3[] GlobalVertices { get; protected set; }
//
public int[] Indexes { get; protected set; }
public void Move(Vector3 v)
{
Pivot.Move(v);
for (int i = 0; i < LocalVertices.Length; i++)
GlobalVertices[i] += v;
}
public void Rotate(float angle, Axis axis)
{
Pivot.Rotate(angle , axis);
for (int i = 0; i < LocalVertices.Length; i++)
GlobalVertices[i] = Pivot.ToGlobalCoords(LocalVertices[i]);
}
public void Scale(float k)
{
for (int i = 0; i < LocalVertices.Length; i++)
LocalVertices[i] *= k;
for (int i = 0; i < LocalVertices.Length; i++)
GlobalVertices[i] = Pivot.ToGlobalCoords(LocalVertices[i]);
}
}
使用局部坐标旋转和移动对象
绘制多边形。相机
场景的主要对象将是相机-借助它,对象将被绘制在屏幕上。像场景中的所有对象一样,相机将具有Pivot类对象形式的局部坐标-通过它,我们将移动和旋转相机:

为了在屏幕上显示对象,我们将使用一种简单的透视投影方法。此方法所基于的原理是,对象离我们越远,看起来就越小。大概很多人曾经在学校解决过有关测量距观察者一定距离的树的高度的问题:
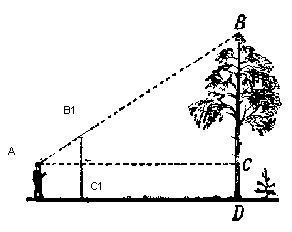
想象一下,一棵树的顶端发出的光线落在某个投影平面上,该投影平面与观察者的距离为C1,并在其上绘制一个点。观察者看到了这一点,并希望从中确定树的高度。如您所见,树的高度和投影平面上点的高度由相似三角形的比率相关。然后,观察者可以使用该比率确定点的高度:
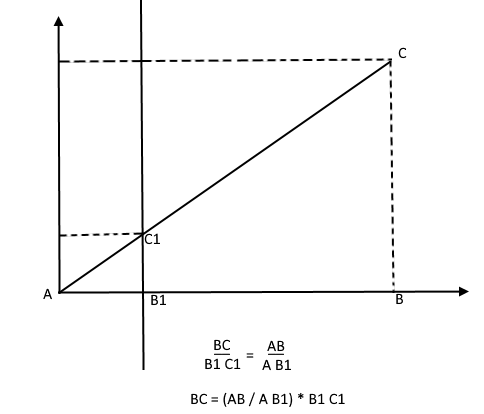
相反,在知道树的高度的情况下,他可以找到投影平面上一个点的高度:

现在,让我们回到相机。想象一下,有一个投影平面连接到相机的z轴,距原点的距离为z'。这种平面的公式为z = z',可以用一个数字-z'给出。来自各种对象的顶点的光线落在此平面上。当射线撞击飞机时,它将在其上留下一点。通过连接这些点,可以绘制对象。

该平面将代表屏幕。我们将分两个阶段找到屏幕上对象顶点投影的坐标:
- 1)我们将顶点转换为相机的本地坐标
- 2)通过相似三角形的比例找到点的投影

投影将是一个二维矢量,其x'和y'坐标将定义该点在计算机屏幕上的位置。
舱室等级1
public class Camera
{
//
public Pivot Pivot { get; private set; }
//
public float ScreenDist { get; private set; }
public Camera(Vector3 center, float screenDist)
{
Pivot = new Pivot(center);
ScreenDist = screenDist;
}
public void Move(Vector3 v)
{
Pivot.Move(v);
}
public void Rotate(float angle, Axis axis)
{
Pivot.Rotate(angle, axis);
}
public Vector2 ScreenProection(Vector3 v)
{
var local = Pivot.ToLocalCoords(v);
//
var delta = ScreenDist / local.Z;
var proection = new Vector2(local.X, local.Y) * delta;
return proection;
}
}
这段代码有几个错误,稍后我们将讨论修复。
切除不可见的多边形
以这种方式在屏幕上投影了多边形的三个点后,我们得到了与屏幕上多边形显示相对应的三角形坐标。但是通过这种方式,相机将处理任何顶点,包括那些投影超出屏幕区域的顶点,如果您尝试绘制这样的顶点,则捕获错误的可能性很高。相机还将处理其后面的多边形(它们在本地相机基线中的点的z坐标小于z')-我们也不需要这种“枕形”视觉。
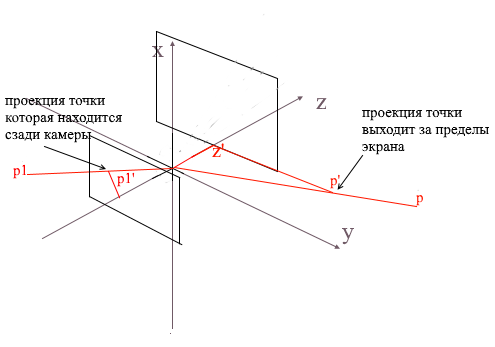
为了在开放gl中剪切不可见的顶点,使用了截断金字塔方法。它包括设置两个平面-近(近平面)和远(远平面)。这两个平面之间的所有内容都将受到进一步处理。我使用带有一个剪切平面-z'的简化版本。它后面的所有顶点都是不可见的。
让我们向摄像机添加两个新字段-屏幕宽度和高度。
现在,我们将检查每个投影点是否击中屏幕区域。让我们也切断相机后面的点。如果该点位于后面或投影不在屏幕上,则该方法将返回点{float.NaN,float.NaN}。
相机代码2
public Vector2 ScreenProection(Vector3 v)
{
var local = Pivot.ToLocalCoords(v);
//
if (local.Z < ScreenDist)
{
return new Vector2(float.NaN, float.NaN);
}
//
var delta = ScreenDist / local.Z;
var proection = new Vector2(local.X, local.Y) * delta;
// -
if (proection.X >= 0 && proection.X < ScreenWidth && proection.Y >= 0 && proection.Y < ScreenHeight)
{
return proection;
}
return new Vector2(float.NaN, float.NaN);
}
转换为屏幕坐标
在这里,我要澄清一点。与此相关的事实是,在许多图形库中,绘制都是在屏幕坐标系中进行的,在这种坐标中,原点是屏幕的左上点,x向右移动时增加,而y向右移动时,y。在我们的投影平面上,点以普通的笛卡尔坐标表示,在绘制之前,必须将这些坐标转换为屏幕坐标。这并不难,只需要将原点移到左上角并反转y:
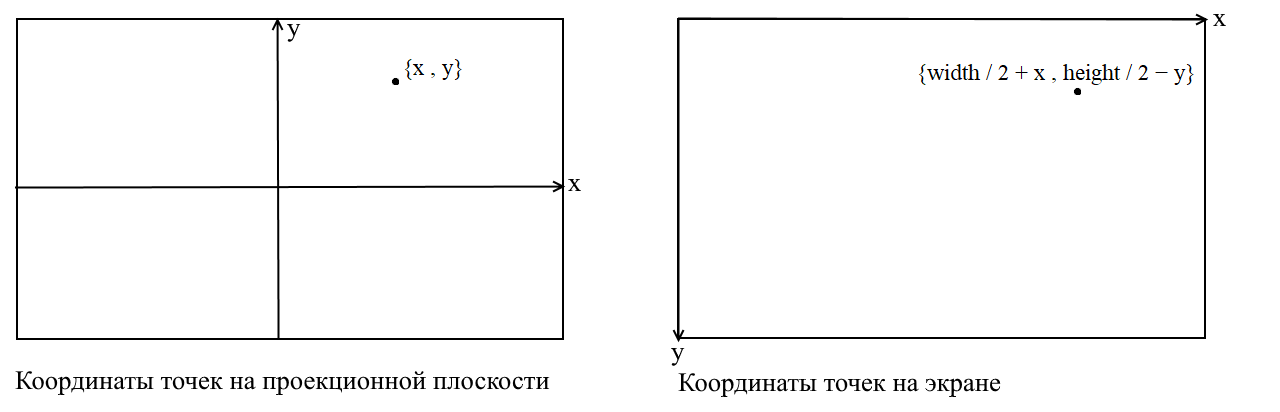
相机代码3
public Vector2 ScreenProection(Vector3 v)
{
var local = Pivot.ToLocalCoords(v);
//
if (local.Z < ScreenDist)
{
return new Vector2(float.NaN, float.NaN);
}
//
var delta = ScreenDist / local.Z;
var proection = new Vector2(local.X, local.Y) * delta;
//
var screen = proection + new Vector2(ScreenWidth / 2, -ScreenHeight / 2);
var screenCoords = new Vector2(screen.X, -screen.Y);
// -
if (screenCoords.X >= 0 && screenCoords.X < ScreenWidth && screenCoords.Y >= 0 && screenCoords.Y < ScreenHeight)
{
return screenCoords;
}
return new Vector2(float.NaN, float.NaN);
}
调整投影影像的尺寸
如果使用前面的代码绘制对象,则会得到以下内容:

由于某些原因,所有对象都绘制得非常小。为了理解原因,请记住我们是如何计算投影的-我们将x和y坐标乘以z'/ z比的差值。这意味着屏幕上物体的尺寸取决于到投影平面z'的距离。但是我们可以根据需要设置z'。因此,我们需要根据当前的z值调整投影大小。为此,让我们向摄像机添加另一个字段-它的视角。

我们需要它来使屏幕的角度大小与其宽度匹配。角度将以这种方式与屏幕的宽度相匹配:相机所看的最大角度是屏幕的左边缘或右边缘。然后,与相机z轴的最大夹角为o / 2。落在屏幕右侧的投影应该具有x = width / 2坐标,而在左侧:x = -width / 2。知道了这一点,我们导出了用于计算投影拉伸系数的公式:
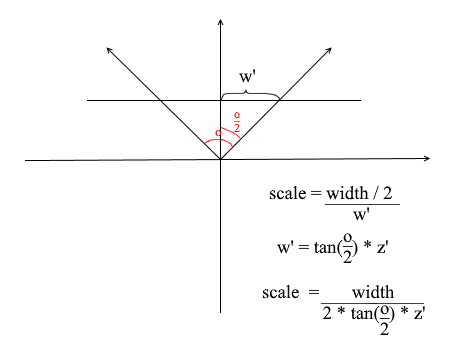
相机代码4
public float ObserveRange { get; private set; }
public float Scale => ScreenWidth / (float)(2 * ScreenDist * Math.Tan(ObserveRange / 2));
public Vector2 ScreenProection(Vector3 v)
{
var local = Pivot.ToLocalCoords(v);
//
if (local.Z < ScreenDist)
{
return new Vector2(float.NaN, float.NaN);
}
//
var delta = ScreenDist / local.Z * Scale;
var proection = new Vector2(local.X, local.Y) * delta;
//
var screen = proection + new Vector2(ScreenWidth / 2, -ScreenHeight / 2);
var screenCoords = new Vector2(screen.X, -screen.Y);
// -
if (screenCoords.X >= 0 && screenCoords.X < ScreenWidth && screenCoords.Y >= 0 && screenCoords.Y < ScreenHeight)
{
return screenCoords;
}
return new Vector2(float.NaN, float.NaN);
}
这是我用于测试的简单渲染代码:
对象绘图代码
public DrawObject(Primitive primitive , Camera camera)
{
for (int i = 0; i < primitive.Indexes.Length; i+=3)
{
var color = randomColor();
//
var i1 = primitive.Indexes[i];
var i2 = primitive.Indexes[i+ 1];
var i3 = primitive.Indexes[i+ 2];
//
var v1 = primitive.GlobalVertices[i1];
var v2 = primitive.GlobalVertices[i2];
var v3 = primitive.GlobalVertices[i3];
//
DrawPolygon(v1,v2,v3 , camera , color);
}
}
public void DrawPolygon(Vector3 v1, Vector3 v2, Vector3 v3, Camera camera , color)
{
//
var p1 = camera.ScreenProection(v1);
var p2 = camera.ScreenProection(v2);
var p3 = camera.ScreenProection(v3);
//
DrawLine(p1, p2 , color);
DrawLine(p2, p3 , color);
DrawLine(p3, p2 , color);
}
让我们检查场景和多维数据集上的渲染:
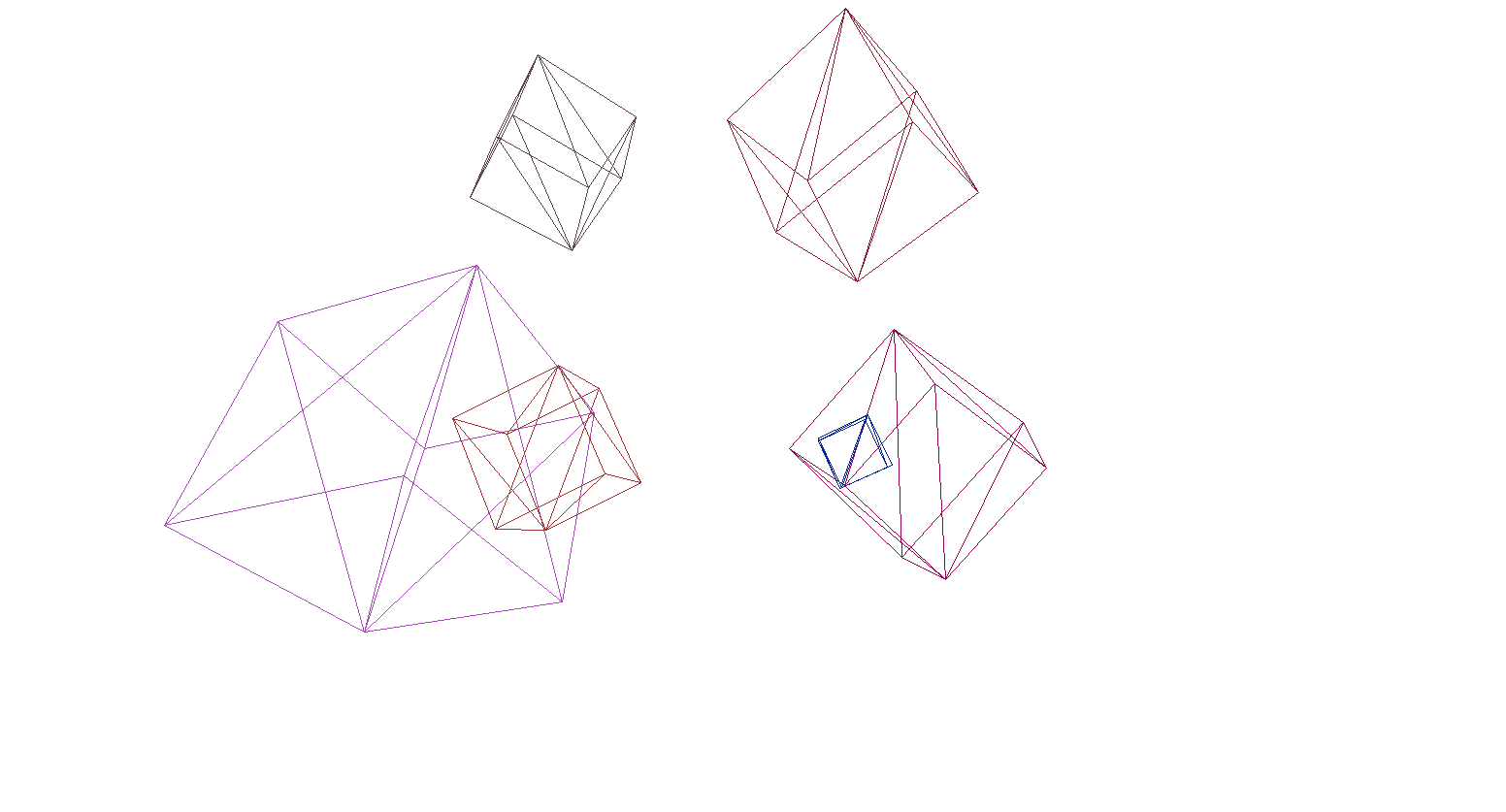
是的,一切正常。对于那些没有发现丰富多彩的立方体的人,我编写了一个函数,用于将OBJ格式模型解析为Primitive对象,用黑色填充背景并渲染了几个模型:
渲染结果

多边形的栅格化。我们带来美丽。
在上一节中,我们编写了线框渲染。现在我们将处理其现代化-我们将实现多边形的栅格化。
简单地对多边形进行栅格化就意味着对其进行绘制。在已经具有现成的三角栅格化功能的情况下,为什么要写一辆自行车似乎是为什么。如果使用默认工具绘制所有内容,则会发生以下情况:

当代艺术,前面的多边形被画成一个粥。另外,如何以这种方式纹理化对象?是的,没有办法。因此,我们需要编写自己的imba光栅化器,它将能够消除不可见的点,纹理甚至着色器!但是为了做到这一点,值得了解一般如何绘制三角形。
Bresenham的线条绘制算法。
让我们从线条开始。如果谁不知道Bresenham算法,这是在计算机图形中绘制直线的主要算法。他或它的修改字面上无处不在:绘图线,线段,圆等。任何对更详细的描述感兴趣的人-阅读Wiki。布雷森汉姆算法
有一条线段连接点{x1,y1}和{x2,y2}。要在它们之间绘制线段,您需要绘制掉落在其上的所有像素。对于线段的两个点,您可以找到它们所在的像素的x坐标:您只需要获取坐标x1和x2的整个部分。为了绘制段上的像素,我们从x1到x2开始循环,并在每次迭代时计算y-落在直线上的像素的坐标。这是代码:
void Brezenkhem(Vector2 p1 , Vector2 p2)
{
int x1 = Floor(p1.X);
int x2 = Floor(p2.X);
if (x1 > x2) {Swap(x1, x2); Swap(p1 , p2);}
float d = (p2.Y - p1.Y) / (x2 - x1);
float y = p1.Y;
for (int i = x1; i <= x2; i++)
{
int pixelY = Floor(y);
FillPixel(i , pixelY);
y += d;
}
}

维基图片
栅格化一个三角形。填充算法
我们知道如何绘制线,但是使用三角形会更加困难(不多)!绘制三角形的任务被简化为多个绘制线的任务。首先,让我们将三角形分成两部分,之前已按x的升序对点进行了排序:
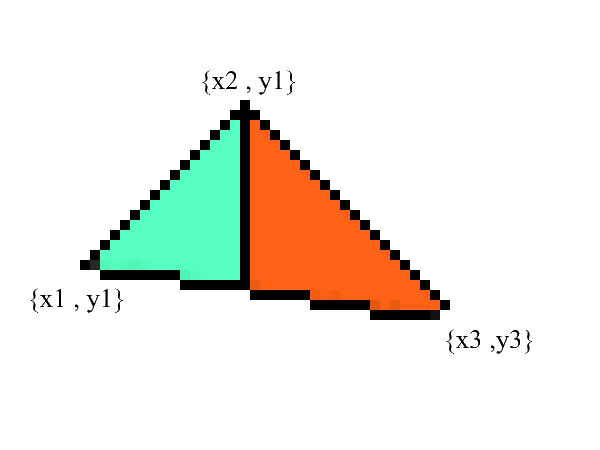
通知-现在我们有两个部分,其中下部和上部边缘有明确表示。剩下的就是填充它们之间的所有像素!这可以分两个周期完成:从x1到x2和从x3到x2。
void Triangle(Vector2 v1 , Vector2 v2 , Vector2 v3)
{
// BubbleSort x
if (v1.X > v2.X) { Swap(v1, v2); }
if (v2.X > v3.X) { Swap(v2, v3); }
if (v1.X > v2.X) { Swap(v1, v2); }
// y x
// 0: x1 == x2 -
var steps12 = max(v2.X - v1.X , 1);
var steps13 = max(v3.X - v1.X , 1);
var upDelta = (v2.Y - v1.Y) / steps12;
var downDelta = (v3.Y - v1.Y) / steps13;
//
if (upDelta < downDelta) Swap(upDelta , downDelta);
// y1
var up = v1.Y;
var down = v1.Y;
for (int i = (int)v1.X; i <= (int)v2.X; i++)
{
for (int g = (int)down; g <= (int)up; g++)
{
FillPixel(i , g);
}
up += upDelta;
down += downDelta;
}
//
var steps32 = max(v2.X - v3.X , 1);
var steps31 = max(v1.X - v3.X , 1);
upDelta = (v2.Y - v3.Y) / steps32;
downDelta = (v1.Y - v3.Y) / steps31;
if (upDelta < downDelta) Swap(upDelta, downDelta);
up = v3.Y;
down = v3.Y;
for (int i = (int)v3.X; i >=(int)v2.X; i--)
{
for (int g = (int)down; g <= (int)up; g++)
{
FillPixel(i, g);
}
up += upDelta;
down += downDelta;
}
}
毫无疑问,此代码可以重构,并且不会重复循环:
void Triangle(Vector2 v1 , Vector2 v2 , Vector2 v3)
{
if (v1.X > v2.X) { Swap(v1, v2); }
if (v2.X > v3.X) { Swap(v2, v3); }
if (v1.X > v2.X) { Swap(v1, v2); }
var steps12 = max(v2.X - v1.X , 1);
var steps13 = max(v3.X - v1.X , 1);
var steps32 = max(v2.X - v3.X , 1);
var steps31 = max(v1.X - v3.X , 1);
var upDelta = (v2.Y - v1.Y) / steps12;
var downDelta = (v3.Y - v1.Y) / steps13;
if (upDelta < downDelta) Swap(upDelta , downDelta);
TrianglePart(v1.X , v2.X , v1.Y , upDelta , downDelta);
upDelta = (v2.Y - v3.Y) / steps32;
downDelta = (v1.Y - v3.Y) / steps31;
if (upDelta < downDelta) Swap(upDelta, downDelta);
TrianglePart(v3.X, v2.X, v3.Y, upDelta, downDelta);
}
void TrianglePart(float x1 , float x2 , float y1 , float upDelta , float downDelta)
{
float up = y1, down = y1;
for (int i = (int)x1; i <= (int)x2; i++)
{
for (int g = (int)down; g <= (int)up; g++)
{
FillPixel(i , g);
}
up += upDelta; down += downDelta;
}
}
剪切不可见的点。
首先,考虑一下您的看法。现在,在您前面有一个屏幕,而在屏幕后面的东西则不可见。在渲染中,一种类似的机制起作用-如果一个多边形与另一个多边形重叠,则渲染会将其绘制在重叠的多边形上。相反,它不会绘制多边形的封闭部分:
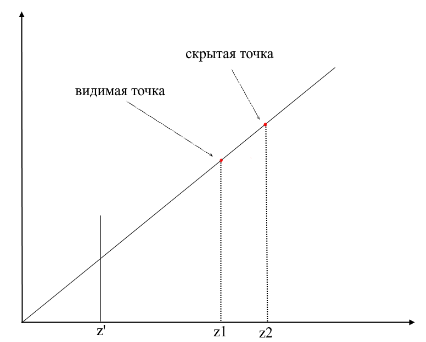
为了了解这些点是否可见,在渲染中使用了zbuffer机制(深度缓冲区)。可以将zbuffer视为具有width * height的二维数组(可以压缩为一维)。对于屏幕上的每个像素,它存储一个z值-从该点开始投影的原始多边形上的坐标。因此,该点离观察者越近,其z坐标越小。最终,如果多个点的投影重合,则需要使用最小z-坐标栅格化该点:
现在出现了问题-如何找到原始多边形上点的z坐标?这可以通过几种方式来完成。例如,您可以从相机的原点发出光线,使其穿过投影平面{x,y,z'}上的一点,并找到与多边形的交点。但是寻找路口是一项极其昂贵的操作,因此我们将使用另一种方法。为了绘制一个三角形,我们对它的投影坐标进行了插值,现在,除了此以外,我们还将对原始多边形的坐标进行插值。为了消除不可见的点,我们将在光栅化方法中将zbuffer状态用于当前帧。
我的zbuffer看起来像Vector3 [] -它不仅包含z坐标,而且还包含每个屏幕像素的多边形点(片段)的插值。这样做是为了节省内存,因为将来我们仍然需要这些值来编写着色器!同时,我们具有以下代码来确定可见顶点(片段):
代码
public void ComputePoly(Vector3 v1, Vector3 v2, Vector3 v3 , Vector3[] zbuffer)
{
//
var v1p = Camera.ScreenProection(v1);
var v2p = Camera.ScreenProection(v2);
var v3p = Camera.ScreenProection(v3);
// x -
//, -
if (v1p.X > v2p.X) { Swap(v1p, v2p); Swap(v1p, v2p); }
if (v2p.X > v3p.X) { Swap(v2p, v3p); Swap(v2p, v3p); }
if (v1p.X > v2p.X) { Swap(v1p, v2p); Swap(v1p, v2p); }
//
int x12 = Math.Max((int)v2p.X - (int)v1p.X, 1);
int x13 = Math.Max((int)v3p.X - (int)v1p.X, 1);
//
float dy12 = (v2p.Y - v1p.Y) / x12; var dr12 = (v2 - v1) / x12;
float dy13 = (v3p.Y - v1p.Y) / x13; var dr13 = (v3 - v1) / x13;
Vector3 deltaUp, deltaDown; float deltaUpY, deltaDownY;
if (dy12 > dy13) { deltaUp = dr12; deltaDown = dr13; deltaUpY = dy12; deltaDownY = dy13;}
else { deltaUp = dr13; deltaDown = dr12; deltaUpY = dy13; deltaDownY = dy12;}
TrianglePart(v1 , deltaUp , deltaDown , x12 , 1 , v1p , deltaUpY , deltaDownY , zbuffer);
// -
}
public void ComputePolyPart(Vector3 start, Vector3 deltaUp, Vector3 deltaDown,
int xSteps, int xDir, Vector2 pixelStart, float deltaUpPixel, float deltaDownPixel , Vector3[] zbuffer)
{
int pixelStartX = (int)pixelStart.X;
Vector3 up = start - deltaUp, down = start - deltaDown;
float pixelUp = pixelStart.Y - deltaUpPixel, pixelDown = pixelStart.Y - deltaDownPixel;
for (int i = 0; i <= xSteps; i++)
{
up += deltaUp; pixelUp += deltaUpPixel;
down += deltaDown; pixelDown += deltaDownPixel;
int steps = ((int)pixelUp - (int)pixelDown);
var delta = steps == 0 ? Vector3.Zero : (up - down) / steps;
Vector3 position = down - delta;
for (int g = 0; g <= steps; g++)
{
position += delta;
var proection = new Point(pixelStartX + i * xDir, (int)pixelDown + g);
int index = proection.Y * Width + proection.X;
//
if (zbuffer[index].Z == 0 || zbuffer[index].Z > position.Z)
{
zbuffer[index] = position;
}
}
}
}

光栅化器步骤的动画(在zbuffer中重写深度时,像素以红色突出显示):
为方便起见,我将所有代码移到了单独的光栅化器模块中:
光栅器类
public class Rasterizer
{
public Vertex[] ZBuffer;
public int[] VisibleIndexes;
public int VisibleCount;
public int Width;
public int Height;
public Camera Camera;
public Rasterizer(Camera camera)
{
Shaders = shaders;
Width = camera.ScreenWidth;
Height = camera.ScreenHeight;
Camera = camera;
}
public Bitmap Rasterize(IEnumerable<Primitive> primitives)
{
var buffer = new Bitmap(Width , Height);
ComputeVisibleVertices(primitives);
for (int i = 0; i < VisibleCount; i++)
{
var vec = ZBuffer[index];
var proec = Camera.ScreenProection(vec);
buffer.SetPixel(proec.X , proec.Y);
}
return buffer.Bitmap;
}
public void ComputeVisibleVertices(IEnumerable<Primitive> primitives)
{
VisibleCount = 0;
VisibleIndexes = new int[Width * Height];
ZBuffer = new Vertex[Width * Height];
foreach (var prim in primitives)
{
foreach (var poly in prim.GetPolys())
{
MakeLocal(poly);
ComputePoly(poly.Item1, poly.Item2, poly.Item3);
}
}
}
public void MakeLocal(Poly poly)
{
poly.Item1.Position = Camera.Pivot.ToLocalCoords(poly.Item1.Position);
poly.Item2.Position = Camera.Pivot.ToLocalCoords(poly.Item2.Position);
poly.Item3.Position = Camera.Pivot.ToLocalCoords(poly.Item3.Position);
}
}
现在让我们检查渲染工作。为此,我使用著名的RPG游戏“ WOW”中的希尔瓦娜斯模型:

不太清楚吧?这是因为这里没有纹理或照明。但是我们会尽快修复。
纹理!正常!灯光!发动机!
为什么将所有内容合并为一个部分?而且因为本质上纹理化和法线的计算是绝对相同的,您很快就会明白这一点。
首先,让我们看一下一个多边形的纹理化任务。现在,除了多边形顶点的常规坐标外,我们还将存储其纹理坐标。顶点的纹理坐标表示为2D向量,并指向纹理图像中的像素。我在互联网上找到了一张很好的图片来显示:

请注意,纹理坐标中纹理的起点(左下像素)为{0,0},结点(右上像素)为{1,1}。考虑纹理坐标系和当纹理坐标为1时超出图像边界的可能性。
让我们创建一个类来立即表示顶点数据:
public class Vertex
{
public Vector3 Position { get; set; }
public Color Color { get; set; }
public Vector2 TextureCoord { get; set; }
public Vector3 Normal { get; set; }
public Vertex(Vector3 pos , Color color , Vector2 texCoord , Vector3 normal)
{
Position = pos;
Color = color;
TextureCoord = texCoord;
Normal = normal;
}
}
我将在稍后解释为什么需要法线,现在我们只知道顶点可以具有法线。现在,要对多边形进行纹理化,我们需要以某种方式将纹理中的颜色值映射到特定像素。还记得我们是如何对顶点进行插值的吗?在这里做同样的事情!我不会再次重写光栅化代码,但是我建议您自己在渲染中实现纹理。结果应该是模型上纹理的正确显示。这是我得到的:
纹理模型

有关模型的纹理坐标的所有信息都在OBJ文件中。要使用此格式,请学习:OBJ格式。
灯光
有了纹理,一切都变得更加有趣,但是当我们为场景实现照明时,它将真的很有趣。为了模拟“便宜”的照明,我将使用Phong模型。
冲模型
通常,此方法模拟照明的三个组成部分:背景(环境),散射(漫射)和反射镜(反射)。这三个成分的总和最终将模拟光的物理行为。

Phong模型
要计算Phong照明,我们需要表面法线,为此,我将它们添加到了Vertex类中。我们在哪里可以找到这些法线的值?不,我们不需要计算任何东西。事实是,慷慨的3D编辑器通常会自己考虑它们,并在OBJ格式的上下文中提供模型以及数据。解析模型文件后,我们获得每个多边形的3个顶点的法线值。
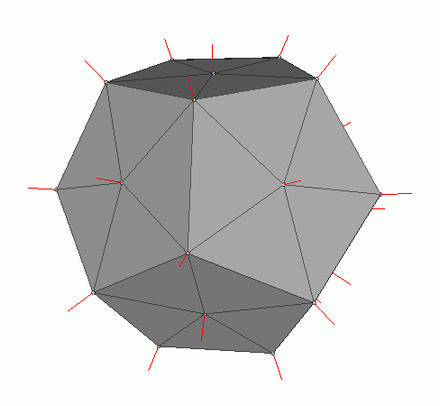
从维基图片
为了计算正常的多边形上的每个点,需要插这些价值观,我们已经知道如何做到这一点。现在,让我们看一下计算Phong照明的所有组件。
背景灯(环境光)
最初,我们设置恒定的背景照明,对于非纹理对象,您可以为具有纹理的对象选择任何颜色,我以基本阴影(baseShading)的比率划分了每个RGB分量。
漫射光
当光线照射到多边形表面时,光线被均匀散射。为了计算特定像素处的漫射值,要考虑到光线撞击表面的角度。要计算该角度,可以应用入射射线和法线的点积(当然,矢量必须在此之前进行归一化)。该角度将乘以光强度系数。如果点积为负,则表示向量之间的角度大于90度。在这种情况下,我们将开始不计算闪电,而是计算阴影。避免这一点是值得的,您可以使用max函数来实现。
代码
public interface IShader
{
void ComputeShader(Vertex vertex, Camera camera);
}
public struct Light
{
public Vector3 Pos;
public float Intensivity;
}
public class PhongModelShader : IShader
{
public static float DiffuseCoef = 0.1f;
public Light[] Lights { get; set; }
public PhongModelShader(params Light[] lights)
{
Lights = lights;
}
public void ComputeShader(Vertex vertex, Camera camera)
{
if (vertex.Normal.X == 0 && vertex.Normal.Y == 0 && vertex.Normal.Z == 0)
{
return;
}
var gPos = camera.Pivot.ToGlobalCoords(vertex.Position);
foreach (var light in Lights)
{
var ldir = Vector3.Normalize(light.Pos - gPos);
var diffuseVal = Math.Max(VectorMath.Cross(ldir, vertex.Normal), 0) * light.Intensivity;
vertex.Color = Color.FromArgb(vertex.Color.A,
(int)Math.Min(255, vertex.Color.R * diffuseVal * DiffuseCoef),
(int)Math.Min(255, vertex.Color.G * diffuseVal * DiffuseCoef,
(int)Math.Min(255, vertex.Color.B * diffuseVal * DiffuseCoef));
}
}
}
让我们施加散射的光并消除黑暗:

镜光(反射)
要计算镜像组件,您需要考虑从中观察对象的点。现在,我们将采取的点积从观察者射线和从表面反射的射线乘以光强度因子。
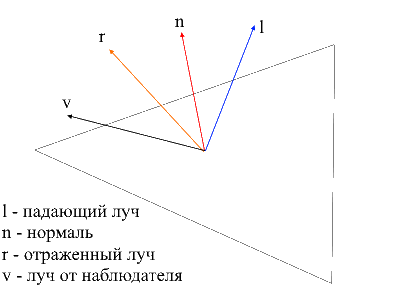
从观察者到表面的光线很容易找到-只是经过处理的顶点在局部坐标中的位置。为了找到反射的射线,我使用了以下方法。可以将入射光线分解为两个向量:其在法线上的投影和第二个向量,可以通过从入射光线中减去此投影来找到。要找到反射射线,您需要从法线投影上减去第二个矢量的值。
代码
public class PhongModelShader : IShader
{
public static float DiffuseCoef = 0.1f;
public static float ReflectCoef = 0.2f;
public Light[] Lights { get; set; }
public PhongModelShader(params Light[] lights)
{
Lights = lights;
}
public void ComputeShader(Vertex vertex, Camera camera)
{
if (vertex.Normal.X == 0 && vertex.Normal.Y == 0 && vertex.Normal.Z == 0)
{
return;
}
var gPos = camera.Pivot.ToGlobalCoords(vertex.Position);
foreach (var light in Lights)
{
var ldir = Vector3.Normalize(light.Pos - gPos);
//
var proection = VectorMath.Proection(ldir, -vertex.Normal);
var d = ldir - proection;
var reflect = proection - d;
var diffuseVal = Math.Max(VectorMath.Cross(ldir, -vertex.Normal), 0) * light.Intensivity;
//
var eye = Vector3.Normalize(-vertex.Position);
var reflectVal = Math.Max(VectorMath.Cross(reflect, eye), 0) * light.Intensivity;
var total = diffuseVal * DiffuseCoef + reflectVal * ReflectCoef;
vertex.Color = Color.FromArgb(vertex.Color.A,
(int)Math.Min(255, vertex.Color.R * total),
(int)Math.Min(255, vertex.Color.G * total),
(int)Math.Min(255, vertex.Color.B * total));
}
}
}
现在图片如下:

暗影
我的演讲的终点将是渲染阴影的实现。起源于我的头骨的第一个死胡同的想法是检查每个点与光源之间是否有多边形。如果是这样,则无需照亮该像素。希尔瓦娜斯的模型包含超过220k的多边形。如果要检查每个点是否与所有这些多边形相交,则最多需要对相交方法进行最大220000 * 1920 * 1080 * 219999的调用!在10分钟内,我的计算机就能掌握所有计算的第十部分(220,000个多边形中的2600个多边形),此后我进行了一次换班,然后我寻找了一种新方法。
在互联网上,我遇到了一种非常简单漂亮的方法,可以执行相同的计算快数千倍。这称为阴影贴图(构建阴影贴图)。记住我们如何确定观察者可见的点-我们使用了zbuffer。阴影贴图也一样!在第一遍中,我们的相机将处于灯光位置并看着物体。这将为光源生成一个深度图。深度图是熟悉的zbuffer。在第二遍中,我们使用此贴图确定应照亮的顶点。现在,我将打破良好代码的规则并采用作弊的方式-我只是给着色器一个新的光栅化器对象,它将使用它为我们创建深度图。
代码
public class ShadowMappingShader : IShader
{
public Enviroment Enviroment { get; set; }
public Rasterizer Rasterizer { get; set; }
public Camera Camera => Rasterizer.Camera;
public Pivot Pivot => Camera.Pivot;
public Vertex[] ZBuffer => Rasterizer.ZBuffer;
public float LightIntensivity { get; set; }
public ShadowMappingShader(Enviroment enviroment, Rasterizer rasterizer, float lightIntensivity)
{
Enviroment = enviroment;
LightIntensivity = lightIntensivity;
Rasterizer = rasterizer;
// ,
// /
Camera.OnRotate += () => UpdateDepthMap(Enviroment.Primitives);
Camera.OnMove += () => UpdateDepthMap(Enviroment.Primitives);
Enviroment.OnChange += () => UpdateDepthMap(Enviroment.Primitives);
UpdateVisible(Enviroment.Primitives);
}
public void ComputeShader(Vertex vertex, Camera camera)
{
//
var gPos = camera.Pivot.ToGlobalCoords(vertex.Position);
//
var lghDir = Pivot.Center - gPos;
var distance = lghDir.Length();
var local = Pivot.ToLocalCoords(gPos);
var proectToLight = Camera.ScreenProection(local).ToPoint();
if (proectToLight.X >= 0 && proectToLight.X < Camera.ScreenWidth && proectToLight.Y >= 0
&& proectToLight.Y < Camera.ScreenHeight)
{
int index = proectToLight.Y * Camera.ScreenWidth + proectToLight.X;
if (ZBuffer[index] == null || ZBuffer[index].Position.Z >= local.Z)
{
vertex.Color = Color.FromArgb(vertex.Color.A,
(int)Math.Min(255, vertex.Color.R + LightIntensivity / distance),
(int)Math.Min(255, vertex.Color.G + LightIntensivity / distance),
(int)Math.Min(255, vertex.Color.B + LightIntensivity / distance));
}
}
else
{
vertex.Color = Color.FromArgb(vertex.Color.A,
(int)Math.Min(255, vertex.Color.R + (LightIntensivity / distance) / 15),
(int)Math.Min(255, vertex.Color.G + (LightIntensivity / distance) / 15),
(int)Math.Min(255, vertex.Color.B + (LightIntensivity / distance) / 15));
}
}
public void UpdateDepthMap(IEnumerable<Primitive> primitives)
{
Rasterizer.ComputeVisibleVertices(primitives);
}
}
对于静态场景,只需调用一次深度图的构造,然后在所有帧中使用它就足够了。作为测试,我使用了较少多边形的枪支模型。这是输出图像:

你们中的许多人可能已经注意到了此着色器的伪像(未经光处理的黑点)。再一次,转向无所不知的网络,我发现了这种效果的描述,带有讨厌的名称“暗疮”(原谅外观复杂的人)。这种“间隙”的本质是我们使用深度图的有限分辨率来定义阴影。这意味着渲染时多个顶点会从深度图接收一个值。最容易受到这种伪影影响的是光以浅角度入射的表面。可以通过增加灯光的渲染分辨率来校正效果,但是有一种更优雅的方法。它包括添加根据光束与表面之间的角度,深度的具体偏移。这可以使用点积完成。
改善阴影

public class ShadowMappingShader : IShader
{
public Enviroment Enviroment { get; set; }
public Rasterizer Rasterizer { get; set; }
public Camera Camera => Rasterizer.Camera;
public Pivot Pivot => Camera.Pivot;
public Vertex[] ZBuffer => Rasterizer.ZBuffer;
public float LightIntensivity { get; set; }
public ShadowMappingShader(Enviroment enviroment, Rasterizer rasterizer, float lightIntensivity)
{
Enviroment = enviroment;
LightIntensivity = lightIntensivity;
Rasterizer = rasterizer;
// ,
// /
Camera.OnRotate += () => UpdateDepthMap(Enviroment.Primitives);
Camera.OnMove += () => UpdateDepthMap(Enviroment.Primitives);
Enviroment.OnChange += () => UpdateDepthMap(Enviroment.Primitives);
UpdateVisible(Enviroment.Primitives);
}
public void ComputeShader(Vertex vertex, Camera camera)
{
//
var gPos = camera.Pivot.ToGlobalCoords(vertex.Position);
//
var lghDir = Pivot.Center - gPos;
var distance = lghDir.Length();
var local = Pivot.ToLocalCoords(gPos);
var proectToLight = Camera.ScreenProection(local).ToPoint();
if (proectToLight.X >= 0 && proectToLight.X < Camera.ScreenWidth && proectToLight.Y >= 0
&& proectToLight.Y < Camera.ScreenHeight)
{
int index = proectToLight.Y * Camera.ScreenWidth + proectToLight.X;
var n = Vector3.Normalize(vertex.Normal);
var ld = Vector3.Normalize(lghDir);
//
float bias = (float)Math.Max(10 * (1.0 - VectorMath.Cross(n, ld)), 0.05);
if (ZBuffer[index] == null || ZBuffer[index].Position.Z + bias >= local.Z)
{
vertex.Color = Color.FromArgb(vertex.Color.A,
(int)Math.Min(255, vertex.Color.R + LightIntensivity / distance),
(int)Math.Min(255, vertex.Color.G + LightIntensivity / distance),
(int)Math.Min(255, vertex.Color.B + LightIntensivity / distance));
}
}
else
{
vertex.Color = Color.FromArgb(vertex.Color.A,
(int)Math.Min(255, vertex.Color.R + (LightIntensivity / distance) / 15),
(int)Math.Min(255, vertex.Color.G + (LightIntensivity / distance) / 15),
(int)Math.Min(255, vertex.Color.B + (LightIntensivity / distance) / 15));
}
}
public void UpdateDepthMap(IEnumerable<Primitive> primitives)
{
Rasterizer.ComputeVisibleVertices(primitives);
}
}
奖金
, , 3 . , .

:

:
FPS 1-2 /. realtime. , , .. cpu.
, , 3 . , .
:
float angle = (float)Math.PI / 90;
var shader = (preparer.Shaders[0] as PhongModelShader);
for (int i = 0; i < 180; i+=2)
{
shader.Lights[0] = = new Light()
{
Pos = shader.Lights[0].Pos.Rotate(angle , Axis.X) ,
Intensivity = shader.Lights[0].Intensivity
};
Draw();
}
:
- : 220 .
- : 1920x1080.
- : Phong model shader
- : cpu — core i7 4790, 8 gb ram
FPS 1-2 /. realtime. , , .. cpu.
结论
我认为自己是3D图形的初学者,我不排除自己在演示过程中犯的错误。我唯一依赖的是在创作过程中获得的实际结果。您可以在评论中保留所有更正和优化(如果有),我很高兴阅读它们。链接到项目存储库。