
想象一下,构建失败后有2.5 GB的日志。那是三百万行。您正在寻找出现在百万分之一行的错误或回归。可能根本不可能手动找到一条这样的线。一种选择是在上次成功和失败的构建之间进行区分,以希望该错误将异常行写入日志。Netflix的解决方案比LogReduce更快,更准确-削减了。
Netflix和日志堆栈中的行
标准md5 diff速度很快,但由于它会显示行差异,因此它会打印至少数十万条候选行供查看。对数缩减的变体是使用k最近邻搜索的模糊差异,它可以找到约40,000个候选者,但需要一个小时。下面的解决方案在20分钟内找到20,000个候选字符串。多亏了开源的魔力,它只有大约一百行Python代码。
解决方案-编码单词和句子的语义信息的矢量单词表示与基于位置的哈希的组合(LSH-本地敏感哈希),可有效地将接近的元素分布到某些组中,而将遥远的元素分布到其他组中。结合文字和LSH的矢量表示是一个伟大的想法小于 十 多年的 前。
注意:我们在CPU上运行Tensorflow 2.2,并立即执行了转移学习和scikit-learnNearestNeighbor用于k个最近的邻居。存在最接近的邻居的复杂近似,这对于解决基于模型的最接近的邻居问题会更好。
矢量字表示法:这是什么,为什么?
构建具有k个类别的单词袋(k-hot编码,unit编码的泛化)是重复数据删除,搜索以及非结构化文本和半结构化文本之间的相似性问题的典型(并且非常有用)起点。这种类型的单词编码袋看起来像是带有单个单词及其编号的字典。句子“登录错误,检查日志”的示例。
{"log": 2, "in": 1, "error": 1, "check": 1}
此编码也由向量表示,其中索引对应于一个单词,而值对应于一个单词的数量。短语“登录错误,检查日志”在下面显示为矢量,其中第一个条目保留用于对单词“ log”进行计数,第二个条目用于对单词“ in”进行计数,依此类推:
[2, 1, 1, 1, 0, 0, 0, 0, 0, ...]
请注意:向量由许多零组成。零是字典中所有不在此句子中的其他单词。可能的向量条目的总数,或向量的维数,是语言词汇量的大小,通常为数百万个单词或更多,但通过巧妙的 技巧将其压缩成数十万个。
让我们看一下短语“问题验证”的字典和矢量表示。匹配前五个向量条目的单词根本不会出现在新句子中。
{"problem": 1, "authenticating": 1}
事实证明:
[0, 0, 0, 0, 1, 1, 0, 0, 0, ...]
句子“问题验证”和“登录错误,检查日志”在语义上相似。也就是说,它们本质上是相同的,但是在词汇上尽可能地不同。他们没有共同的词。就模糊差异而言,我们可以说它们太相似以致无法区分它们,但是md5编码和由k-hot使用kNN处理的文档不支持此功能。
降维使用线性代数或人工神经网络在新矢量空间中将语义相似的单词,句子或日志行彼此相邻放置。使用向量表示。在我们的示例中,“登录错误,检查日志”可以具有一个五维向量来表示:
[0.1, 0.3, -0.5, -0.7, 0.2]
短语“问题验证”可以是
[0.1, 0.35, -0.5, -0.7, 0.2]
这些向量在诸如余弦相似度的度量上彼此接近,而不是其单词袋向量。密集的低维视图对于诸如组装线或syslog之类的简短文档非常有用。
实际上,您将仅用100维表示的信息(而不是5种)来替换字典中成千上万的维。现代的降维方法包括单词共现矩阵(GloVe)的奇异值分解和专用神经网络(word2vec,BERT,ELMo)。
集群呢?让我们回到构建日志
我们开玩笑说Netflix是偶尔会流式传输视频的日志制作服务。日志记录,流式传输,异常处理-这些是每秒数十万个请求。因此,当我们想在遥测和测井中应用应用的ML时,缩放是必要的。因此,我们在缩放文本重复数据删除,寻找语义相似性以及检测文本异常值时要格外小心。实时解决业务问题时,别无他法。
我们的解决方案涉及以低维向量表示每一行,并可以选择“微调”或同时更新嵌入模型,将其分配给聚类,并将不同聚类中的线定义为“不同”。位置感知哈希-一种概率算法,可让您在恒定时间内分配聚类,并在几乎恒定时间内搜索最近的邻居。
LSH通过将矢量表示映射到一组标量来工作。标准哈希算法倾向于避免任何两个匹配输入之间的冲突。如果输入相距较远,则LSH会尝试避免冲突,如果输入相异但在向量空间中彼此接近,则LSH会促进冲突。
表示短语“登录错误,检查错误”的向量可以与二进制数匹配
01。然后01代表集群。向量“问题验证”的可能性也很高,可以在01中显示。因此LSH提供了模糊比较,并解决了反问题-模糊差。 LSH的早期应用是针对一组单词的多维向量空间。我们无法想到他不使用单词的矢量表示空间的单一原因。种种迹象表明,其他人 认为 相同。

上面显示了当将字符放在同一组中时,LSH的使用,但颠倒了。
我们通过检测构建日志中的文本异常值来应用LSH和矢量剖视图的工作现在使工程师可以查看一小部分日志行,以识别和修复潜在的关键业务错误。它还使您可以实时实现几乎所有日志行的语义聚类。
现在,这种方法适用于所有Netflix版本。语义部分允许您根据看似不同的元素的含义进行分组,并在排放报告中显示这些元素。
一些例子
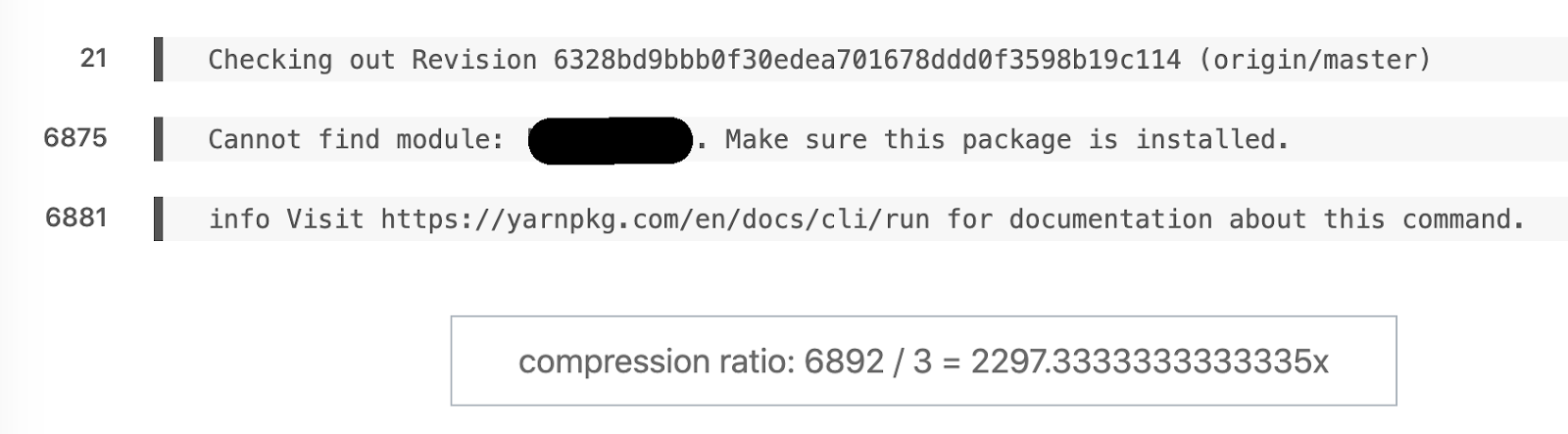
最喜欢的语义差异示例。6892行变成3。
另一个示例:该装配记录了6044行,但是报告中仍然保留171条,主要问题几乎立即出现在4036行上

。当然,解析171行比6044行更快,但是我们如何得到如此大的装配日志?对消费类电子产品进行压力测试的成千上万个构建任务中的某些任务是在跟踪模式下执行的。如果不进行初步处理,就很难处理如此大量的数据。

压缩比:91366/455 = 205.3。
有各种示例反映了框架,语言和构建脚本之间的语义差异。
结论
开源转移学习产品和SDK的成熟使LSH可以用很少的几行代码解决语义最近邻搜索问题。我们对转移学习和微调带给应用程序的特殊利益感兴趣。我们很高兴能够解决此类问题并帮助人们更快更好地完成自己的工作。
我们希望您正在考虑加入Netflix,并成为伟大的同事之一,通过机器学习,我们的生活会让我们的生活更轻松。敬业度是Netflix的核心价值,我们特别希望培养对技术团队的不同见解。因此,如果您从事分析,工程,数据科学或任何其他领域,并且具有非典型的行业背景,我们尤其希望收到您的来信!
如果您对Netflix功能有任何疑问,请联系LinkedIn投稿人:Stanislav Kirdey,William High您如何解决日志
搜索问题?
通过在线SkillFactory课程,了解如何从头开始或在技能和薪资水平上获得高知名度的职业的详细信息:
- Machine Learning (12 )
- «Machine Learning Pro + Deep Learning» (20 )
- « Machine Learning Data Science» (20 )
- Data Science (12 )
E
