 Yandex杯编程冠军赛的试训比赛今天开始。这意味着您可以使用Yandex.Contest系统解决与排位赛中类似的问题。到目前为止,结果什么都没有影响。
Yandex杯编程冠军赛的试训比赛今天开始。这意味着您可以使用Yandex.Contest系统解决与排位赛中类似的问题。到目前为止,结果什么都没有影响。
在帖子中,您会发现分析跟踪和分析的任务条款,这些条款故意隐藏在破坏者中。您可以查看解决方案或尝试自己先执行任务。这项检查是自动进行的-比赛将立即报告结果,您将有机会提出其他解决方案。
A.数全国的骗子
解决竞赛10,000人居住在该州。他们分为真相和撒谎者。热爱真理的人以80%的概率讲真话,撒谎者以40%的概率讲真话。该州决定根据对100位居民的调查,对喜欢真相的人和说谎者进行计数。每次问到一个随机选择的人时,“您是骗子吗?” -写下答案。但是,一个人可以多次参与调查。如果居民已经参加了调查,则其答案与第一次相同。我们知道,有70%的真相爱好者和30%的骗子。国家低估骗子人数的可能性有多大?即一项调查显示,骗子人数不到30%?以百分比作为答案,并以句点作为分隔符,将结果四舍五入到最接近的百分数(输入示例:00.00)。
决断
1. «» « ?».
«, » «» «» .
«, » :
: «» * = 0,2 * 0,7.
: «» * ( – ) + «» * ( ) = «» * = 0,2 * 0,7.
«, » 0,14 , . .
, «, » : 0,2 * 0,7 + 0,4 * 0,3 = 0,26.
2. .
, , — n = 100, p = 0,26.
, 30 (30% 100 ): P (x < 30). n = 100, p = 0,26 0,789458. : stattrek.com/online-calculator/binomial.aspx.
, : 78,95.
«, » «» «» .
«, » :
: «» * = 0,2 * 0,7.
: «» * ( – ) + «» * ( ) = «» * = 0,2 * 0,7.
«, » 0,14 , . .
, «, » : 0,2 * 0,7 + 0,4 * 0,3 = 0,26.
2. .
, , — n = 100, p = 0,26.
, 30 (30% 100 ): P (x < 30). n = 100, p = 0,26 0,789458. : stattrek.com/online-calculator/binomial.aspx.
, : 78,95.
B.剧院季节和电话
参加比赛国际票务服务已决定评估戏剧季。作为指标之一,项目经理希望统计购买不同演出门票的用户数量。
购买机票时,用户指出他的电话号码。您需要找到具有最多唯一电话号码的节目。并计算匹配的唯一电话号码的数量。
输入格式
可以在ticket_logs.csv文件中找到购买日志。第一列包含服务数据库中的性能名称。第二个-用户购买时留下的电话号码。请注意,出于阴谋目的,电话国家/地区代码已替换为当前未使用的区域。
输出格式
唯一编号的数量。
决断
main.py.
. . 801–807.
:
1. 8-(801)-111-11-11
2. 8-801-111-11-11
3. 8801-111-11-11
4. 8-8011111111
5. +88011111111
6. 8-801-flowers, — ( )
:
1. 1–4 replace.
2. 5 , 1. 11 , .
3. 6 , . , .
, . .
. . 801–807.
:
1. 8-(801)-111-11-11
2. 8-801-111-11-11
3. 8801-111-11-11
4. 8-8011111111
5. +88011111111
6. 8-801-flowers, — ( )
:
1. 1–4 replace.
2. 5 , 1. 11 , .
3. 6 , . , .
, . .
C.计算pFound
解决比赛的存档包含三个文本文件:
- qid_query.tsv-查询ID和查询文本,以制表符分隔;
- qid_url_rating.tsv-请求ID,文档URL,与请求相关的文档;
- hostid_url.tsv-主机ID和文档URL。
必须显示请求文本,该文本带有从前10个文档计算得出的pFound度量的最大值。根据要求,按照以下规则发行:
- 在一个主机上,只能发布一份文档。如果有多个具有相同主机ID的请求文档,则采用最相关的文档(如果几个文档最相关,则采用任何一个)。
- 按需文档按相关性从高到低的顺序排序。
- 如果来自不同主机的多个文档具有相同的相关性,则它们的顺序可以是任意的。
计算pFound的公式:
pFound =pLook [i]⋅pRel [i]
pLook [1] = 1
pLook [i] = pLook [i-1]⋅(1-pRel [i-1])⋅(1-pBreak)
pBreak = 0.15
输出格式
具有最大度量标准值的请求文本。例如,对于open_task.zip,正确答案是:
决断
. - — pFound . pandas — .
import pandas as pd
#
qid_query = pd.read_csv("hidden_task/qid_query.tsv", sep="\t", names=["qid", "query"])
qid_url_rating = pd.read_csv("hidden_task/qid_url_rating.tsv", sep="\t", names=["qid", "url", "rating"])
hostid_url = pd.read_csv("hidden_task/hostid_url.tsv", sep="\t", names=["hostid", "url"])
# join , url
qid_url_rating_hostid = pd.merge(qid_url_rating, hostid_url, on="url")
def plook(ind, rels):
if ind == 0:
return 1
return plook(ind-1, rels)*(1-rels[ind-1])*(1-0.15)
def pfound(group):
max_by_host = group.groupby("hostid")["rating"].max() #
top10 = max_by_host.sort_values(ascending=False)[:10] # -10
pfound = 0
for ind, val in enumerate(top10):
pfound += val*plook(ind, top10.values)
return pfound
qid_pfound = qid_url_rating_hostid.groupby('qid').apply(pfound) # qid pfound
qid_max = qid_pfound.idxmax() # qid pfound
qid_query[qid_query["qid"] == qid_max]D.体育比赛
解决比赛| 测试时间 | 2秒 |
| 每次测试的内存限制 | 256兆字节 |
| 输入项 | 标准输入或input.txt |
| 输出量 | 标准输出或output.txt |
输入格式
的第一行包含一个整数3≤N≤2 16 - 1,n = 2的ķ -1-过去的比赛次数。接下来的n行包含玩家的两个姓氏(拉丁大写字母),中间用空格隔开。播放器的名称不同。所有姓氏都是唯一的,同事之间没有同名。
输入格式
如果玛莎(Masha)记忆不正确的比赛,并且无法根据奥林匹克系统使用该网格来获得锦标赛,则打印“无解决方案”(不带引号)。如果可以使用锦标赛网格,请在一行上打印两个姓氏-第一名的候选人姓名(顺序并不重要)。
例子1
| 输入项 | 输出量 |
7
|
IURKOVSKII GORBOVSKII |
| 输入项 | 输出量 |
3
|
NO SOLUTION |
奥林匹克系统(也称为季后赛)是一种比赛组织系统,其中,比赛对手在第一次失利后被淘汰出比赛。您可以在Wikipedia上阅读有关奥林匹克系统的更多信息。
从条件上进行第一次测试的方案:
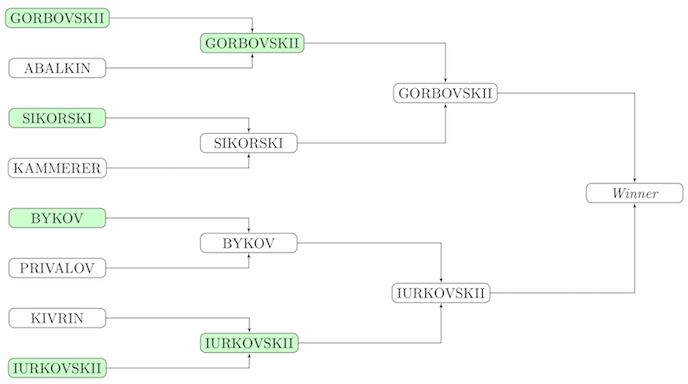
决断
n = 2^k – 1 k. , i- , n_i. , ( k ). , . , i j min(n_i, n_j), - ( ). r (i, j), min(n_i, n_j) = r. :
. 2^k – 1 , :
1. .
2. r 2^{k – r}.
. : , . k. k = 1 — . k – 1 -> k.
-, , . , q . , q- . , 1, 2, ..., q. , , , , 2^k. , 2^{k – 1} n_i = 1. .
, 2^{k – 1} n_i > 1 — . , n_i = 1 2^{k – 1}, . , : n_i = 1, — n_i > 1. k – 1 ( n_i 1). , .
. 2^k – 1 , :
1. .
2. r 2^{k – r}.
. : , . k. k = 1 — . k – 1 -> k.
-, , . , q . , q- . , 1, 2, ..., q. , , , , 2^k. , 2^{k – 1} n_i = 1. .
, 2^{k – 1} n_i > 1 — . , n_i = 1 2^{k – 1}, . , : n_i = 1, — n_i > 1. k – 1 ( n_i 1). , .
import sys
import collections
def solve(fname):
games = []
for it, line in enumerate(open(fname)):
line = line.strip()
if not line:
continue
if it == 0:
n_games = int(line)
n_rounds = n_games.bit_length()
else:
games.append(line.split())
gamer2games_cnt = collections.Counter()
rounds = [[] for _ in range(n_rounds + 1)]
for game in games:
gamer_1, gamer_2 = game
gamer2games_cnt[gamer_1] += 1
gamer2games_cnt[gamer_2] += 1
ok = True
for game in games:
gamer_1, gamer_2 = game
game_round = min(gamer2games_cnt[gamer_1], gamer2games_cnt[gamer_2])
if game_round > n_rounds:
ok = False
break
rounds[game_round].append(game)
finalists = list((gamer for gamer, games_cnt in gamer2games_cnt.items() if games_cnt == n_rounds))
for cur_round in range(1, n_rounds):
if len(rounds[cur_round]) != pow(2, n_rounds - cur_round):
ok = False
break
cur_round_gamers = set()
for gamer_1, gamer_2 in rounds[cur_round]:
if gamer_1 in cur_round_gamers or gamer_2 in cur_round_gamers:
ok = False
break
cur_round_gamers.add(gamer_1)
cur_round_gamers.add(gamer_2)
print ' '.join(finalists) if ok else 'NO SOLUTION'
def main():
solve('input.txt')
if name == '__main__':
main()要解决锦标赛其他赛道的问题,您需要在这里注册。