本文是neptune.ai帖子之一的译文,并重点介绍了在ICLR 2020机器学习会议上介绍的最有趣的深度学习工具。

在哪里创建和讨论高级深度学习?
深度学习的主要讨论场所之一是ICLR-深度学习领先会议,于2020年4月27日至30日举行。超过5500名参与者和近700个演讲和讲座,对于完全在线的活动而言是巨大的成功。您可以在此处,此处或此处找到有关会议的全面信息。
虚拟社交会议是ICLR 2020的亮点之一。组织者决定启动一个名为“最新DL研究中的开源工具和实践”的项目。选择该主题的原因是,相应的工具包是深度学习研究人员不可避免的一部分。该领域的进展已导致大型生态系统的扩散(TensorFlow,PyTorch,MXNet)以及较小的针对性工具,这些工具可以满足研究人员的特定需求。
提及活动的目的是与开源工具的创建者和用户会面,并在深度学习社区之间分享经验和印象。总计有100多人聚集在一起,其中包括主要的鼓舞者和项目负责人,我们在短时间内介绍了他们的工作。与会者和组织者对所展示的工具和库的多样性和创意感到惊讶。
本文包含从虚拟舞台展示的出色项目。
工具和库
以下是在ICLR上展示的八个工具,并详细介绍了这些功能。
每个部分都以非常简洁的方式给出了对以下几点的答案:
- 工具/库解决什么问题?
- 如何运行或创建最小用例?
- 外部资源,可更深入地研究库/工具。
- 如果希望与他们联系,请与项目代表联系。
您可以跳到下面的特定部分,也可以仅一个一个地浏览它们。享受阅读!
AmpliGraph
主题:基于知识图的嵌入模型。
编程语言:Python的
人:卢卡Costabello
微博| LinkedIn | GitHub |网站
知识图是表示复杂系统的通用工具。无论是社交网络,生物信息学数据集还是零售购买数据,图知识建模都可以使组织识别出否则会被忽略的重要联系。
揭示数据之间的关系需要专门设计用于处理图形的特殊机器学习模型。
AmpliGraph是Apache2许可的一组机器学习模型,用于从知识图中提取嵌入。此类模型以矢量形式对图形的节点和边缘进行编码,并将它们组合以预测缺失的事实。图嵌入用于诸如知识图的顶部,知识发现,基于链接的聚类等任务中。
通过将这些模型提供给经验不足的用户,AmpliGraph降低了研究人员进入图形嵌入主题的障碍。利用开源API,该项目支持在机器学习中使用图形的爱好者社区。通过该项目,您可以学习如何基于真实数据从知识图创建嵌入并可视化嵌入,以及如何在后续的机器学习任务中使用嵌入。
首先,下面是一小段代码,可以在一个参考数据集中训练模型并预测缺失的链接:


AmpliGraph最初是在都柏林埃森哲实验室开发的,用于各种工业项目。
自治区
表格数据中试平台
的编程语言:Python的
发布由尼古拉斯·蒂格
微博| LinkedIn | GitHub | Automunge网站
是一个Python库,可帮助准备用于机器学习的表格数据。通过该软件包的工具包,可以简单地进行特征增强的转换,以规范化,编码和填补空白。将转换应用于训练子样本,然后以相同方式应用于来自测试子样本的数据。转换可以自动执行,从内部库分配或由用户灵活配置。填充选项包括“基于机器学习的填充”,其中训练了模型以预测每列数据的丢失信息。
简而言之:
automunge(。)准备用于机器学习的表格数据,
postmunge(。)附加数据将按顺序高效处理。
Automunge可通过pip安装:

安装后,只需将库导入Jupyter Notebook进行初始化:

要使用默认参数自动处理训练样本中的数据,只需使用以下命令即可:

此外,对于后续处理来自测试子样本的数据,使用通过调用上面的automunge(。)获得的postprocess_dict字典来运行命令就足够了:

automunge(。)调用中的assigncat和assigninfill参数可用于定义转换详细信息和数据类型以填补空白。例如,可以基于带有列1的ML填充的最小值和最大值('mnmx')分配具有列'column1'和'column2'的数据集的缩放比例,并使用基于填充的column-hot编码('text') column2的最常用值。来自其他未明确指定的列的数据将被自动处理。

资源和链接
网站| GitHub | 简报
动态ML
机器学习的Scala的
编程语言:Scala的
发布者:Mandar多卡尔
微博| LinkedIn | GitHub
DynaML是一个基于Scala的研究和机器学习工具箱。它旨在为用户提供端到端环境,可以帮助:
- 模型的开发/原型制作,
- 使用庞大而复杂的管道,
- 可视化数据和结果,
- 以脚本和笔记本的形式重复使用代码。
DynaML利用Scala语言和生态系统的优势来创建一个提供性能和灵活性的环境。它基于出色的项目,例如Ammonite scala,Tensorflow-Scala和Breeze高性能数值计算库。
DynaML的关键组件是REPL / shell,它具有语法突出显示功能和高级自动完成系统。
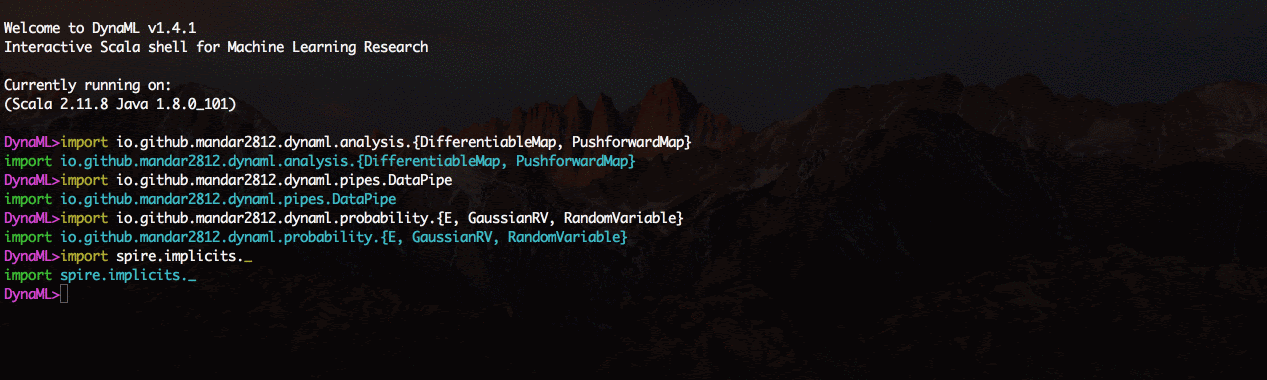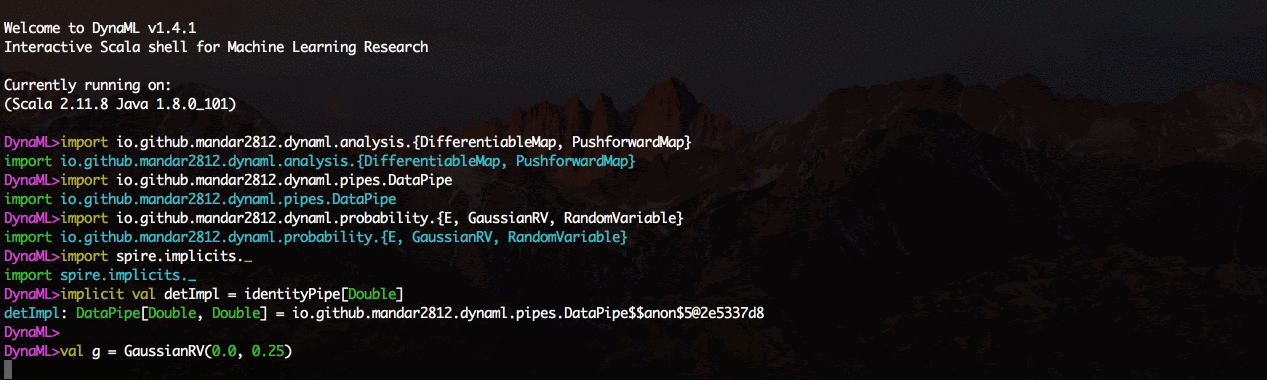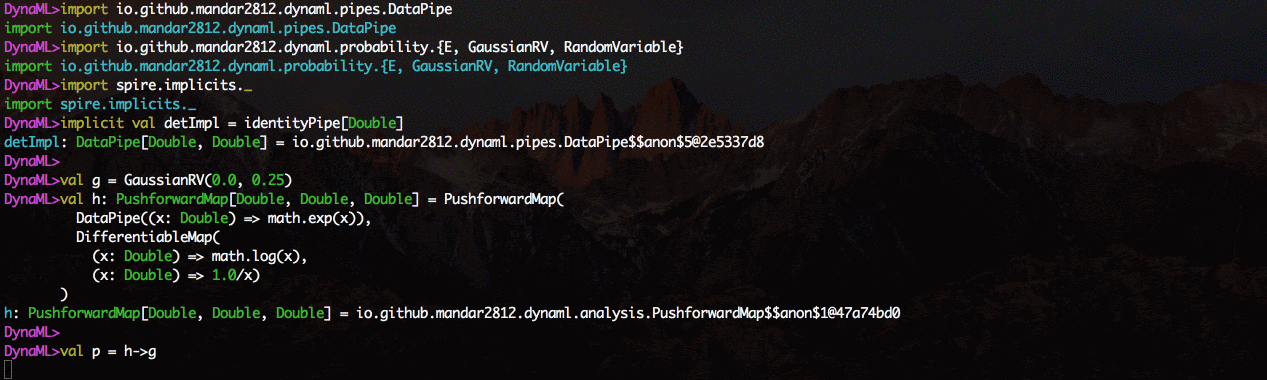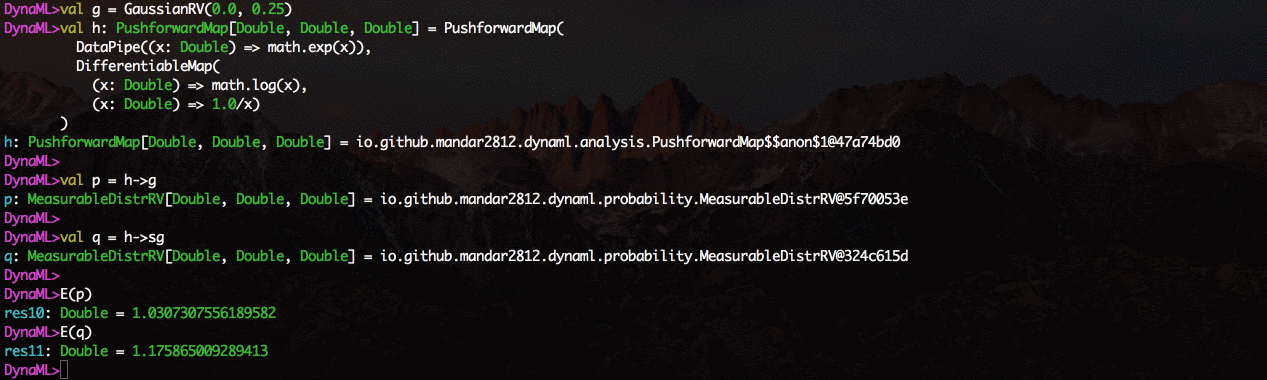
该环境支持2D和3D可视化,可以直接从命令外壳中显示结果。

模块使以易于布局的模块化方式轻松创建数据处理管道。创建函数,使用DataPipe构造函数包装它们,并使用>运算符构造函数块。
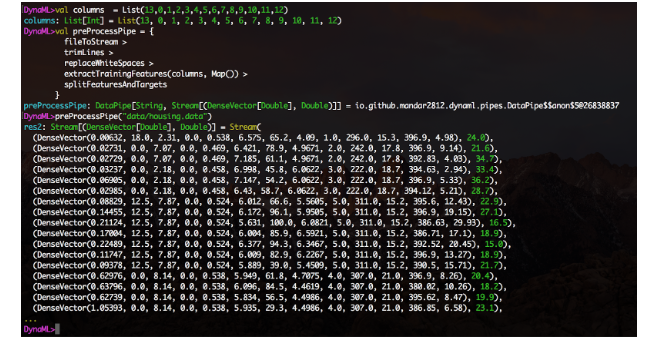
还提供了实验性的Jupyter笔记本集成功能,存储库的笔记本目录包含使用DynaML-Scala Jupyter内核的几个示例。

用户指南包含大量参考资料和文档,可帮助您掌握和充分利用DynaML环境。
以下是一些有趣的应用程序,它们突出了DynaML的优势:
- 受物理学启发的神经网络解决了Burger方程和Fokker-Planck系统,
- 深度学习培训,
- 用于自回归时间序列预测的高斯过程模型。
GitHub资源和链接| 用户手册
九头蛇
配置和参数管理
的编程语言:Python的
发布者Omry雅丹
微博| GitHub
由Facebook AI开发,Hydra是一个Python平台,通过提供使用配置文件和命令行创建和覆盖配置的功能,简化了研究应用程序的开发。该平台还支持自动参数扩展,通过插件进行远程和并行执行,自动工作目录管理以及通过按TAB键动态建议完成选项。
使用Hydra还可以使您的代码在各种机器学习环境中更易于移植。使您可以在个人工作站,公共和私有群集之间切换,而无需更改代码。以上是通过模块化架构实现的。
基本示例
此示例使用数据库配置,但是您可以轻松地用模型,数据集或其他任何所需的配置替换它。
config.yaml:

my_app.py:

您可以从命令行覆盖配置中的所有内容:

组成示例:
您可能需要在两个不同的数据库配置之间切换。
创建此目录结构:

config.yaml:
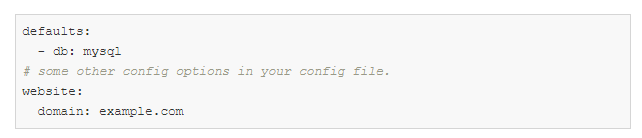
defaults是一个特殊的指令,它告诉Hydra在构成配置对象时使用db / mysql.yaml。
现在您可以选择要使用的数据库配置,以及从命令行覆盖参数值:

查看教程以了解更多信息。
此外,新的有趣功能即将推出:
- 强类型配置(结构化配置文件),
- 使用Ax和Nevergrad插件优化超参数,
- 使用Ray启动器插件启动AWS,
- 通过joblib插件进行本地并行启动等等。
拉克
二值化神经网络
编程语言:Python的
发布者:卢卡斯盖革
微博| LinkedIn | GitHub
Larq是一个开放源码的Python软件包生态系统,用于构建,训练和部署二值神经网络(BNN)。 BNN是深度学习模型,其中的激活和权重不是使用32位,16位或8位编码,而是仅使用1位编码。这可以大大加快推理时间并降低功耗,从而使BNN非常适合移动和外围应用。
开源Larq生态系统具有三个主要组成部分。
- Larq — , . API, TensorFlow Keras. . Larq BNNs, .
- Larq Zoo BNNs, . Larq Zoo , BNN .
- Larq Compute Engine — BNNs. TensorFlow Lite MLIR Larq FlatBuffer, TF Lite. ARM64, , Android Raspberry Pi, , , BNN.
该项目的作者不断创建更快的模型,并将Larq生态系统扩展到新的硬件平台和深度学习应用程序。例如,目前正在进行端到端集成8位量化的工作,以便能够使用Larq训练和部署二进制和8位网络的组合。
资源和链接
网站| GitHub larq / larq | GitHub larq / zoo | GitHub larq /计算引擎| 课本 | 博客| 推特
麦克尔内尔
核方法在对数线性时间
的编程语言:C / C ++
发布者:J.德Curtó我迪亚斯
微博| 网站
第一个开源C ++库提供了内核方法的随机特征近似值和成熟的深度学习框架。
McKernel提供了四种不同的用途。
- 自包含的快速闪电式开源Hadamard代码。用于压缩,加密或量子计算等领域。
- 极快的核技术。可以在支持向量机方法的任何地方使用(支持向量方法:ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%BE%D0%BF%D0 %BE%D1%80%D0%BD%D1%8B%D1%85_%D0%B2%D0%B5%D0%BA%D1%82%D0%BE%D1%80%D0%BE%D0%B2)优于深度学习。例如,医疗保健和其他领域中的某些机器人应用程序和机器学习用例包括联合学习和渠道选择。
- 深度学习和核方法的集成允许在先验的拟人化/数学方向上开发深度学习架构。
- 深度学习研究框架,用于解决机器学习中的许多开放性问题。
描述所有计算的方程式如下所示:

在这里,作为开拓者的作者形式主义曾用来解释使用随机症状作为深度学习方法和核技术。理论基础基于四大巨头:高斯,维纳,傅里叶和卡尔曼。 Rahimi和Rekht(NIPS 2007)和Le等人奠定了这一基础。 (ICML 2013)。
针对典型用户
McKernel的主要受众是机器人技术,医疗保健机器学习,信号处理和通信领域的研究人员和从业人员,他们需要在C ++中高效,快速地实现。在这种情况下,大多数深度学习库不满足给定条件,因为它们主要基于高级Python实现。此外,听众可能是更广泛的机器学习和深度学习社区的代表,他们正在寻求使用核方法改善神经网络的体系结构。
一个无需花费时间即可运行库的超简单直观示例,如下所示:

下一步是什么?
端至端学习,自我监督学习,元学习,集成进化策略,大大降低了搜索空间与NAS,...
资源和链接
的GitHub | 完整介绍
SCCH培训引擎
深学习自动化程序
的编程语言:Python的
发布者纳塔利娅Shepeleva
微博| LinkedIn |网站
开发一条典型的深度学习管道是相当标准的:数据预处理,任务设计/实施,模型训练和结果评估。然而,从一个项目到另一个项目,其使用需要工程师在开发的每个阶段参与,这导致重复相同的动作,重复代码,最终导致错误。
SCCH培训引擎的目标是统一和自动化两个最受欢迎的框架PyTorch和TensorFlow的深度学习开发流程。单项架构可最大程度地缩短开发时间并防止错误。
为了谁?
SCCH培训引擎的灵活体系结构具有两个级别的用户体验。
主要。在此级别上,用户必须提供用于训练的数据并将模型的训练参数写入配置文件中。此后,将自动执行所有过程,包括数据处理,模型训练和结果验证。结果,将在其中一个主要框架内获得经过训练的模型。
高级。由于采用了模块化组件的概念,用户可以根据需要修改模块,部署自己的模型以及使用各种损失函数和质量指标。这种模块化体系结构使您可以添加其他功能,而不会干扰主管道的运行。
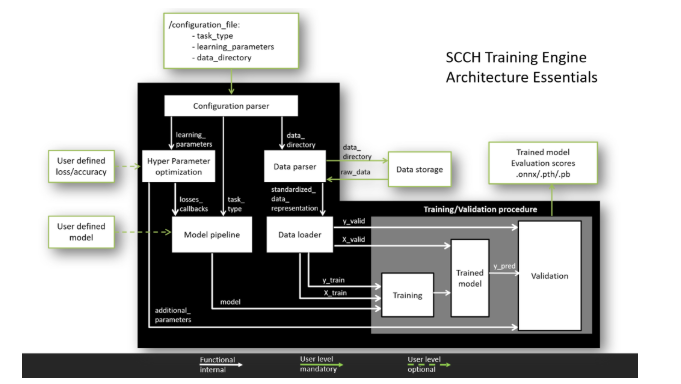
他能做什么?
当前功能:
- 与TensorFlow和PyTorch合作,
- 用于解析各种格式的数据的标准化管道,
- 用于模型训练和结果验证的标准化管道,
- 支持分类,细分和检测任务,
- 交叉验证支持。
开发中的功能:
- 搜索最佳模型超参数,
- 从特定控制点加载模型权重并进行训练,
- GAN架构支持。
怎么运行的?
要全面了解SCCH培训引擎,您需要执行两个步骤。
- 只需复制存储库并使用以下命令安装所需的软件包:pip install requirements.txt。
- 运行python main.py以查看MNIST案例研究,其中包括对LeNet-5模型的处理和培训。
有关如何创建配置文件以及如何使用高级功能的所有信息,请参见GitHub页面。
稳定的发行与核心功能:定于5月下旬到2020年
资源和链接
的GitHub | 网站
分词器
文本断词
编程语言:铁锈与Python API
发布者:安东尼·姆瓦
微博| LinkedIn | GitHub
主页/ tokenizers提供对最现代的tokenizer的访问,重点是性能和多用途。令牌生成器使您可以轻松地训练和使用令牌生成器。无论您是NLP领域的学者还是从业者,令牌生成器都可以为您提供帮助。
主要特征
- 极高的速度:令牌化不应该成为您管道中的瓶颈,并且您不需要预处理数据。多亏了本机的Rust实现,千兆字节文本的标记化仅需几秒钟。
- 偏移/对齐:即使使用复杂的规范化过程处理文本,也可以提供偏移控制。这使为NER或问题解答之类的任务提取文本变得容易。
- 预处理:在将数据输入语言模型之前,需要进行所有必要的预处理(截断,填充,添加特殊标记等)。
- 易于学习:在新机箱上训练所有令牌生成器。例如,以一种新的语言学习BERT的标记器从未如此简单。
- 多国语言:捆绑多种语言。您可以立即通过Python,Node.js或Rust使用它。继续朝这个方向努力!
例:

等等:
- 序列化为单个文件并为任何令牌生成器加载一行,
- Unigram支持。
Hugging Face认为他们的使命有助于促进NLP并使之民主化。GitHub
资源和链接
/变形金刚| GitHub表面/ tokenizers | 推特
结论
总而言之,应该指出的是,对于一般的深度学习和机器学习而言,有大量的库有用,并且无法在一篇文章中描述所有这些库。上述某些项目在特定情况下将很有用,有些已经广为人知,但是不幸的是,一些出色的项目并未纳入本文。
我们的CleverDATA致力于与新工具和有用库保持同步,并在与深度学习和机器学习相关的工作中积极采用新方法。就我而言,我想引起读者的注意,这两个库未包含在主要文章中,但对使用神经网络有很大帮助:Catalyst(https://catalyst-team.com)和白化(https://albumentations.ai/)。
我相信,每位执业专家都有自己喜欢的工具和库,包括那些鲜为人知的工具和库。如果您觉得自己的工作中所有有用的工具都被白白忽略了,那么请在评论中写下它们:即使在讨论中提及它们也将有助于有前途的项目吸引新的关注者,而受欢迎程度的提高反过来又会导致功能的改进和自身的发展库。
感谢您的关注,我希望所提供的库对您的工作有所帮助!