
介绍了用Python编写的可自定义的交互式决策树结构。此实现适用于从数据中提取知识,测试直觉,增进您对决策树内部工作的理解以及探索学习问题的替代因果关系。它可以用作更复杂的算法,可视化和报告的一部分,用于任何研究目的,也可以用作易于测试决策树算法思想的可访问平台。
TL; DR
帖子是关于什么的?
我在论文中编写的决策树的另一种实现。这项工作分为以下三个部分:
- 我将尝试解释为什么我决定花时间自己制定决策树。我将列出它的一些功能,以及当前实现的缺点。
- 我将通过一些代码片段向您展示HDTree的基本用法,并在此过程中解释一些细节。
- 有关如何使用您的想法自定义和扩展HDTree的提示。
动机和背景
在我的论文中,我开始研究决策树。我现在的目标是实现一个以人为中心的ML模型,其中HDTree(就此而言,是人为决策树)是作为该模型的真实UI的一部分应用的附加成分。尽管这个故事完全是关于HDTree的,但是我可以写一个续集来详细介绍其他组件。
HDTree功能以及与scikit的比较学习决策树
自然,我遇到了决策树的实现
scikit-learn[4]。该实现sckit-learn具有许多优点:
- 快速,精简;
- 用Cython方言写的。Cython编译为C代码(然后编译为二进制代码),同时保留了与Python解释器进行交互的能力;
- 简便;
- ML中的许多人都知道如何使用模型
scikit-learn。得益于其用户群,可以在任何地方获得帮助; - 它已经在战斗条件下进行了测试(许多人都在使用);
- 它只是工作;
- 它支持多种前修剪和后修剪技术[6],并提供许多功能(例如,以最小的成本和样品重量进行修剪)。
- 支持基本渲染[7]。
但是,它当然具有一些缺点:
- 进行更改并不是一件容易的事,部分原因是因为Cython方言非常不寻常(请参见上面的优势)。
- 无法考虑用户对主题领域的了解或更改学习过程;
- 可视化非常简单;
- 不支持分类功能;
- 不支持缺失值;
- 访问节点和遍历树的界面繁琐且不直观。
- 不支持缺失值;
- 仅二进制分区(请参见下文);
- 没有多元分区(请参见下文)。
HDTree功能
HDTree为大多数这些问题提供了解决方案,同时牺牲了scikit-learn实施的许多好处。稍后我们将回到这些要点,所以如果您还不了解下面的整个列表,请不要担心:
- 与学习行为互动;
- 主要组件是模块化的,并且相当容易扩展(实现接口);
- 用纯Python编写(更多可用信息)
- 具有丰富的可视化;
- 支持分类数据;
- 支持缺失值;
- 支持多元拆分;
- 具有方便的导航树结构的界面;
- 支持n元分区(超过2个子节点);
- 解决方案文字表示;
- 通过打印人类可读的文本来鼓励可解释性。
缺点:
- 慢;
- 未经战斗测试;
- 软件质量中等。
- 裁剪选项不多。该实现虽然支持一些基本参数。
缺点并不多,但是很关键。让我们马上清楚:不要将大数据馈入此实现。您将永远等待。不要在生产环境中使用它。它可能会意外中断。您已被警告!上面的一些问题可以随着时间的推移而解决。但是,学习率可能会保持较低(尽管推论是有效的)。您将需要提出一个更好的解决方案来解决此问题。我邀请你来贡献。但是,可能有什么应用?
- 从数据中提取知识;
- 检查数据的直观视图;
- 了解决策树的内部运作;
- 探索与您的学习问题有关的其他因果关系;
- 用作更复杂算法的一部分;
- 创建报告和可视化;
- 用于任何研究目的;
- 作为可访问的平台,可轻松测试决策树算法的想法。
决策树结构
尽管本文不会详细介绍决策树,但我们将总结它们的基本构建块。这将为以后理解示例提供基础,并突出显示HDTree的某些功能。下图显示了HDTree的实际输出(不包括标记)。
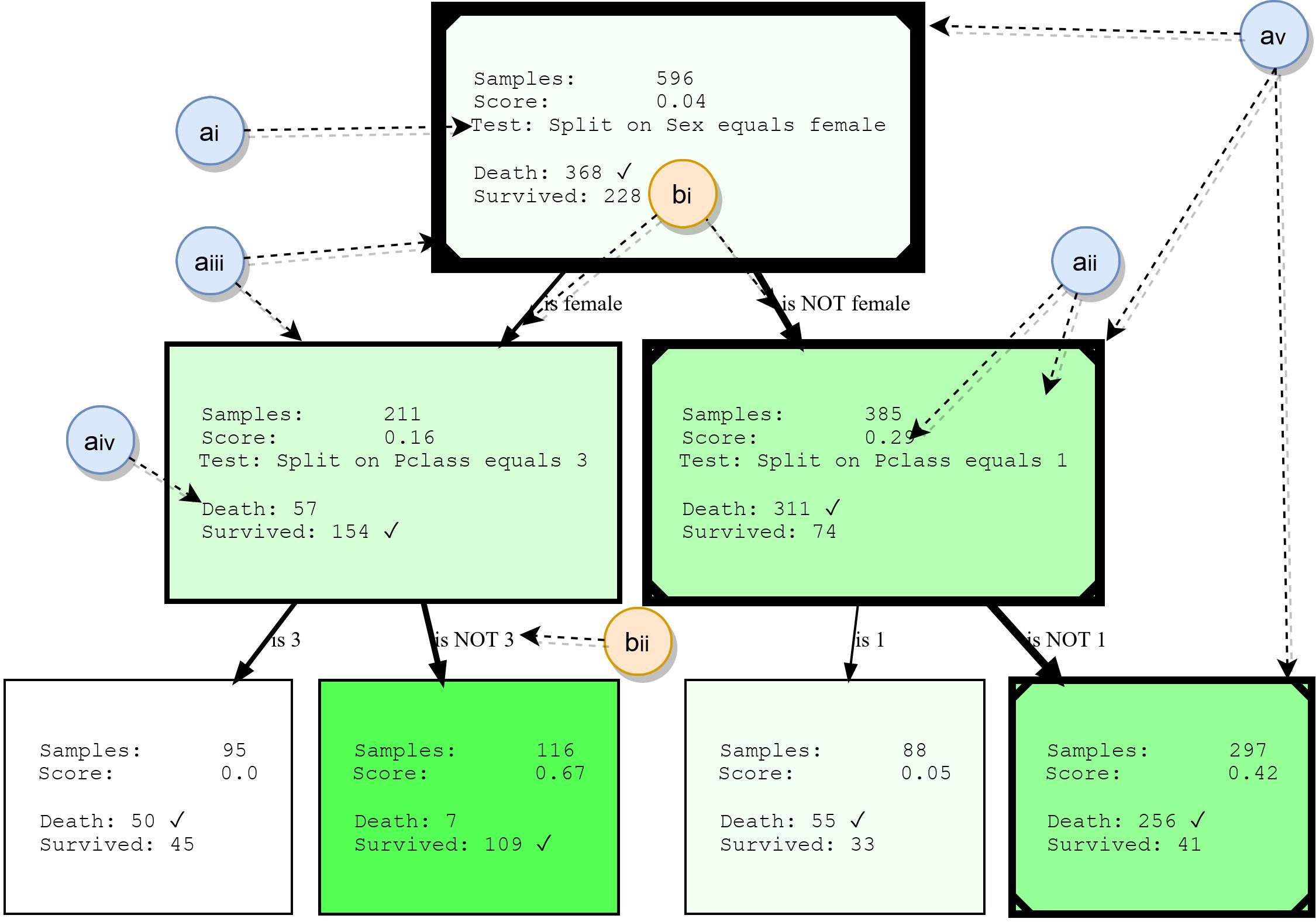
节点数
- ai: , . . * * . . 3.
- aii: , , , , . , . . , ( , .. ). HDTree.
- aiii:节点框指示有多少数据点通过该节点。边界越厚,流经节点的数据越多。
- aiv:具有数据点通过此节点的预测目标和标签的列表。最常见的类别已标记。
- av:(可选)可视化可以标记各个数据点遵循的路径(说明数据点横越树时做出的决定)。在决策树的一角标记有一条线。
肋骨
- bi:箭头将每个可能的拆分结果(ai)连接到其子节点。相对于父“流动”在边缘周围的数据越多,显示的内容越厚。
- bii:每条边都有对应拆分结果的可读文本表示。
不同的拆分集和测试来自哪里?
在这一点上,您可能已经想知道HDTree与树
scikit-learn(或任何其他实现)有何不同,为什么我们可能希望拥有不同种类的分区?让我们尝试澄清一下。也许您对特征空间有一个直观的了解。我们使用的所有数据都在一个特定的多维空间中,该空间由数据中要素的数量和类型决定。任务的分类算法是现在划分此空间为互不重叠的区域和分配这些领域是一流的。让我们将其可视化。由于我们的大脑很难解决高维问题,因此我们将坚持一个2D示例和一个非常简单的两类问题,如下所示:

您会看到一个非常简单的数据集,由两个维度(特征/属性)和两个类组成。生成的数据点通常分布在中心。只是线性函数的街道
f(x) = y将两个类别分隔开:1类(右下)和2类(左上)。还添加了一些随机噪声(蓝色数据点为橙色,反之亦然),以说明以后过度拟合的影响。像HDTree这样的分类算法(尽管它也可以用于回归问题)的工作是找出每个数据点属于哪个类。换句话说,给定一对坐标,(x, y)例如(6, 2)... 目的是找出该坐标是属于橙色类别1还是属于蓝色类别2。判别模型将尝试将对象空间(此处为(x,y)轴)分别划分为蓝色和橙色区域。
有了这些数据,关于如何对数据进行分类的决定(规则)似乎非常简单。一个有理智的人会说“首先考虑自己”。“如果x> y,则为1类,否则为2类。”
y=x点分功能将创建完美的分隔。实际上,诸如支持向量机[8]之类的最大余量分类器将提出类似的解决方案。但是,让我们看看哪些决策树以不同的方式解决了这个问题:

该图显示了深度增加的标准决策树将数据点分类为1类(橙色)或2类(蓝色)的区域。
决策树使用阶跃函数近似线性函数。这是由于决策树使用的验证和分区规则的类型。它们都以某种模式工作,
attribute < threshold这将导致超平面与轴平行。在2D空间中,“切出”矩形。在3D中,这些将是长方体,依此类推。另外,当已经有8个级别时,决策树开始对数据中的噪声进行建模,即发生重新训练。但是,它永远找不到一个真正的线性函数的良好近似值。为了验证这一点,我使用了训练和测试数据的典型2对1拆分,并计算了树的准确性。测试集为93.84%,93.03%,90.81%,培训集为94.54%,96.57%,98.81%(按树深4、8、16排序)。虽然测试的准确性下降,训练的准确性却有所提高。
训练效率的提高和测试结果的降低是过度训练的标志。对于这样一个简单的功能,最终的决策树非常复杂。使用scikit Learn呈现的最简单的这些(深度4)看起来像这样:
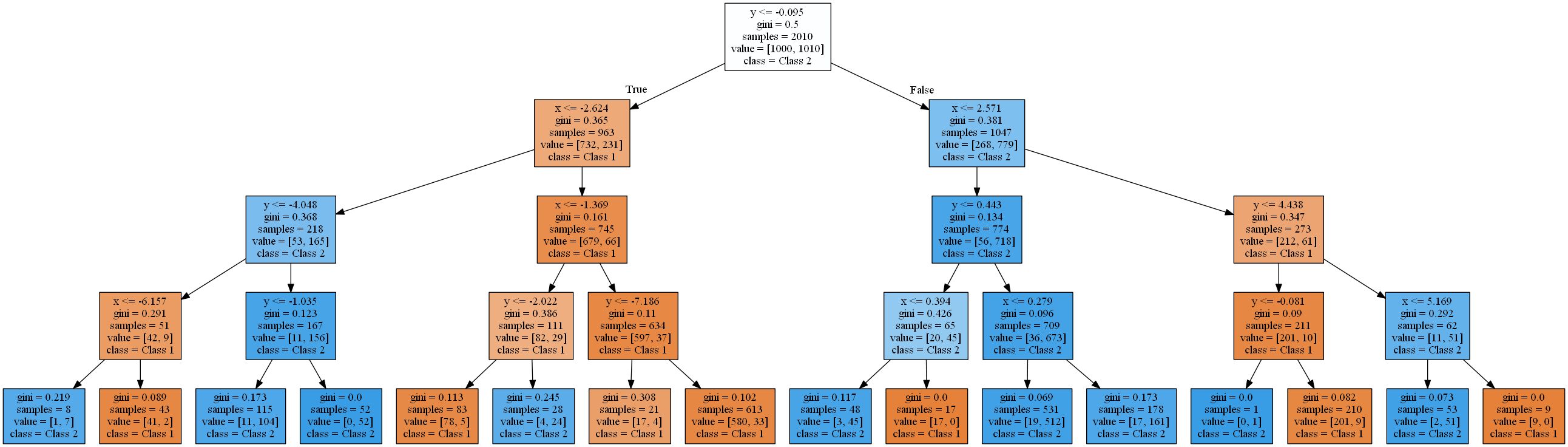
我会把你的树木除掉更困难。在下一节中,我们将从使用HDTree包解决此问题开始。HDTree将允许用户应用有关数据的知识(就像示例中有关线性分离的知识一样)。它还将使您能够找到问题的替代解决方案。
HDTree包的应用
本节将向您介绍HDTree的基础知识。我将尝试介绍其API的某些部分。如果您对此有任何疑问,请随时在评论中提问或与我联系。我很乐意回答,并在必要时补充本文。安装HDTree比
pip install hdtree。抱歉。首先,您需要Python 3.5或更高版本。
- 创建一个空目录,并在其中创建一个名为hdtree(
your_folder/hdtree)的文件夹 - 将存储库克隆到hdtree目录(而不是另一个子目录)。
- 安装所需的依赖关系:
numpy,pandas,graphviz,sklearn。 - 添加
your_folder到PYTHONPATH。这将包括Python导入引擎中的目录。您将能够像普通的Python包一样使用它。
或者,将其添加
hdtree到site-packages您的安装文件夹中python。我可以稍后添加安装文件。在撰写本文时,该代码在pip存储库中不可用。生成下面的图形和输出的所有代码(以及之前显示的代码)都在存储库中,并直接发布在此处。用同级树解决线性问题
让我们从代码开始:
from hdtree import HDTreeClassifier, SmallerThanSplit, EntropyMeasure
hdtree_linear = HDTreeClassifier(allowed_splits=[SmallerThanSplit.build()], # Split rule in form a < b
information_measure=EntropyMeasure(), # Use Information Gain for the scores attribute_names=['x', 'y' ]) # give the
attributes some interpretable names # standard sklearn-like interface hdtree_linear.fit(X_street_train,
y_street_train) # create tree graph hdtree_linear.generate_dot_graph() 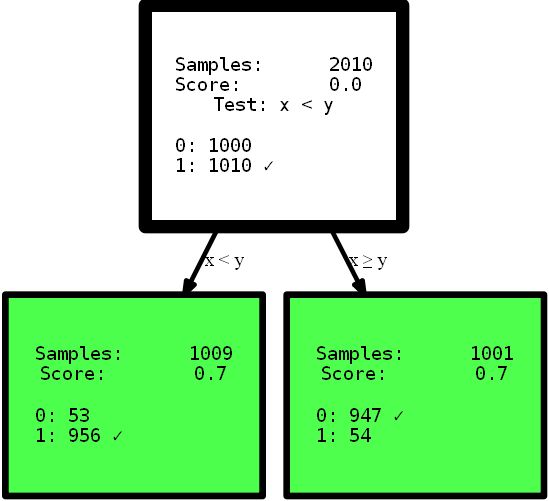
是的,生成的树只有一级高,可以为该问题提供完美的解决方案。这是一个显示效果的人工示例。但是,我希望它可以澄清这一点:对数据有直观的了解,或者只是为决策树提供用于划分特征空间的不同选项,这可能会提供更简单,有时甚至更准确的解决方案。想象一下,您需要从此处介绍的树中解释规则,以找到有用的信息。您首先可以理解哪种解释,而您更信任哪种解释?使用多步函数的复杂解释还是小的精确树?我认为答案很简单。但是,让我们更深入地研究代码本身。初始化时,
HDTreeClassifier最重要的是allowed_splits。在这里,您提供了一个列表,其中包含算法在训练每个节点以查找数据的良好本地分区时算法尝试使用的分区规则。在这种情况下,我们仅提供了 SmallerThanSplit。此拆分操作完全符合您的见解:它具有两个属性(尝试任意组合),并根据schema拆分数据a_i < a_j。哪个(不太随机)与我们的数据尽可能匹配。
这种分割类型称为多元分割这意味着分离使用多个功能来做出决定。这与大多数其他树中使用的单向分区不同,例如
scikit-tree(请参阅上文以了解更多详细信息)仅考虑一个属性。当然,它HDTree也具有实现“常规分区”的选项,例如scikit树中的“家庭” QuantileSplit。随着文章的进展,我将向您展示更多。您可能会在代码中看到的另一个陌生的事物是超参数information_measure。该参数表示一个维,用于评估单个节点或完整拆分(父节点及其子节点)的值。选择的选项基于熵[10]。您可能也听说过基尼系数,这将是另一个有效的选择。当然,您可以通过简单地实现适当的接口来提供自己的尺寸。如果愿意,可以实现可在树中使用的gini-Index,而无需重新实现其他功能。只是复制EntropyMeasure()并适应自己。让我们深入探讨泰坦尼克号灾难。我喜欢从自己的例子中学到东西。现在,您将看到更多带有特定示例的HDTree函数,而不是生成的数据。
资料集
我们将为年轻的战斗机课程使用著名的机器学习数据集:泰坦尼克号灾难数据集。这是一个相当简单的集合,虽然不是很大,但是包含几种不同的数据类型和缺失值,尽管不是很琐碎。另外,它是人类可以理解的,并且许多人已经在使用它。数据如下所示:

您可以看到存在各种属性。数值,分类,整数类型甚至缺失值(请参见Cabin列)。面临的挑战是根据可用的乘客信息来预测乘客是否在泰坦尼克号灾难中幸免。您可以在此处找到价值属性的描述。通过研究ML教程并应用此数据集,您可以进行各种进行预处理以能够与常见的机器学习模型一起使用,例如,
NaN通过替换值[12]来删除缺失值,删除行/列,统一编码[13]分类数据(例如Embarked和和Sex或分组数据以获得有效数据集) HDTree在技术上并不是必须进行这种清理的,您可以按原样提供数据,而模型会很乐意接受。仅在设计真实对象时才更改数据。
在Titanic数据上训练第一个HDTree
让我们按原样获取数据并将其输入模型。基本代码与上面的代码相似,但是,在此示例中,将允许更多数据拆分。
hdtree_titanic = HDTreeClassifier(allowed_splits=[FixedValueSplit.build(), # e.g., Embarked = 'C'
SingleCategorySplit.build(), # e.g., Embarked -> ['C', 'Q', 'S']
TwentyQuantileRangeSplit.build(), # e.g., IN Quantile 3-5
TwentyQuantileSplit.build()], # e.g., BELOW Quantile 7
information_measure=EntropyMeasure(),
attribute_names=col_names,
max_levels=3) # restrict to grow to a max of 3 levels
hdtree_titanic.fit(X_titanic_train.values, y_titanic_train.values)
hdtree_titanic.generate_dot_graph()
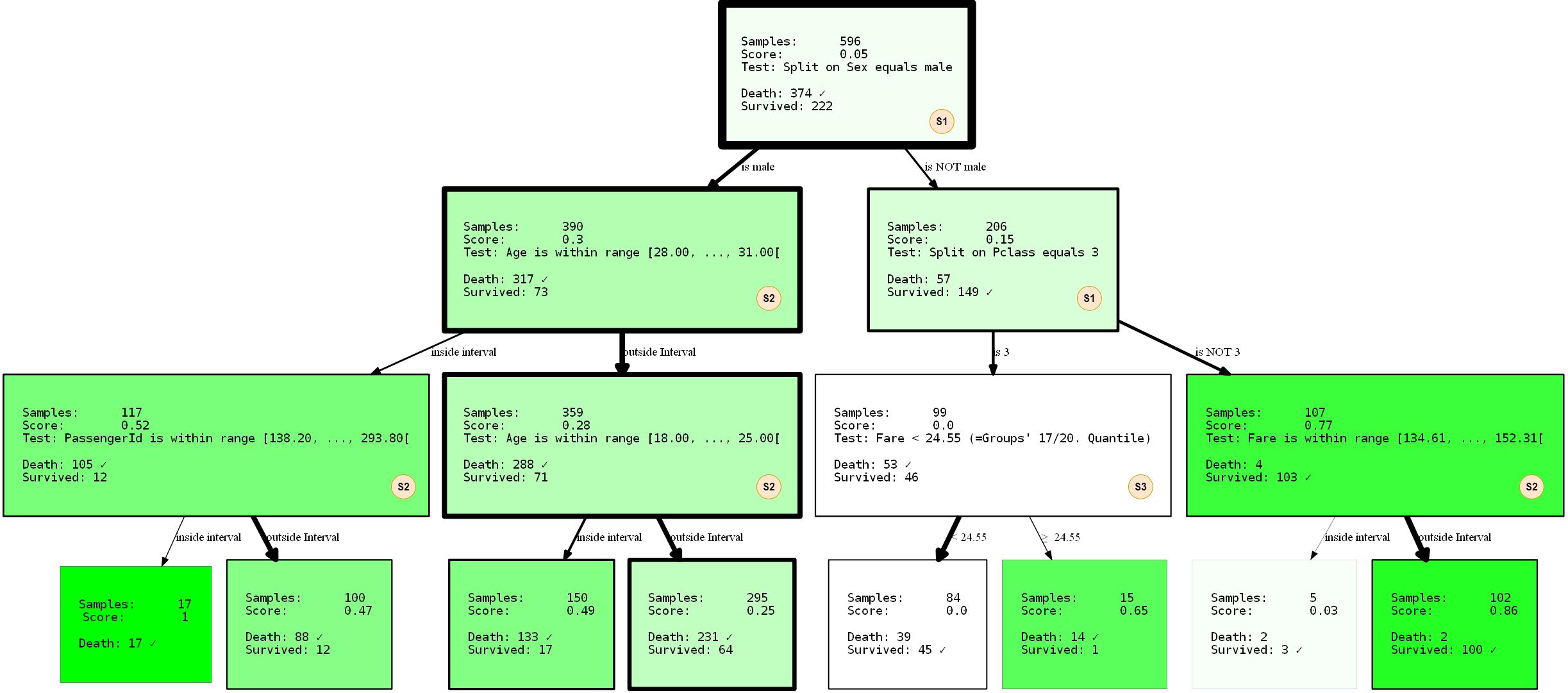
让我们仔细看看正在发生的事情。我们创建了一个具有三个级别的决策树,我们选择使用4种可能的SplitRules中的3种。它们用字母S1,S2,S3标记。我将简要解释它们的作用。
- S1 :
FixedValueSplit。该除法处理分类数据,并选择可能的值之一。然后将数据分为具有该值的一个部分和没有设置值的另一部分。例如,PClass = 1且Pclass≠1。 - S2: ()
QuantileRangeSplit. . , . 1 5 . ( ) (measure_information). (i) (ii) — . . - S3 :(二十岁)
QuantileSplit。与分割范围(S2)相似,但按阈值分割数据。基本上,这是常规决策树所做的工作,只是它们通常尝试所有可能的阈值而不是固定的阈值。
您可能已经注意到您
SingleCategorySplit没有参与其中。无论如何,我将有机会澄清一下,因为稍后会出现对该部门的遗漏:
- S4:
SingleCategorySplit将类似地工作FixedValueSplit,但是将为每个可能的值创建一个子节点,例如:对于PClass属性,它将是3个子节点(每个用于1类,2类和3类)。请注意,如果只有两个可能的类别,FixedValueSplit则相同SingleValueSplit。
就``接受''的数据类型/值而言,个别部门在某种程度上是``明智的''。在进行某种扩展之前,他们知道在什么情况下适用,哪些情况不适用。该树还接受了训练数据和测试数据的2比1训练,性能-训练数据的准确度为80.37%,测试数据的准确度为81.69。还不错
限制分割
假设由于某种原因您对找到的解决方案不太满意。也许您认为树顶部的第一个拆分过于琐碎(由attribute拆分
sex)。HDTree解决了这个问题。最简单的解决方案是防止FixedValueSplit(就此而言,等价的SingleCategorySplit)出现在顶部。这很简单。如下更改拆分的初始化:
- SNIP -
...allowed_splits=[FixedValueSplit.build_with_restrictions(min_level=1),
SingleCategorySplit.build_with_restrictions(min_level=1),...],
- SNIP -
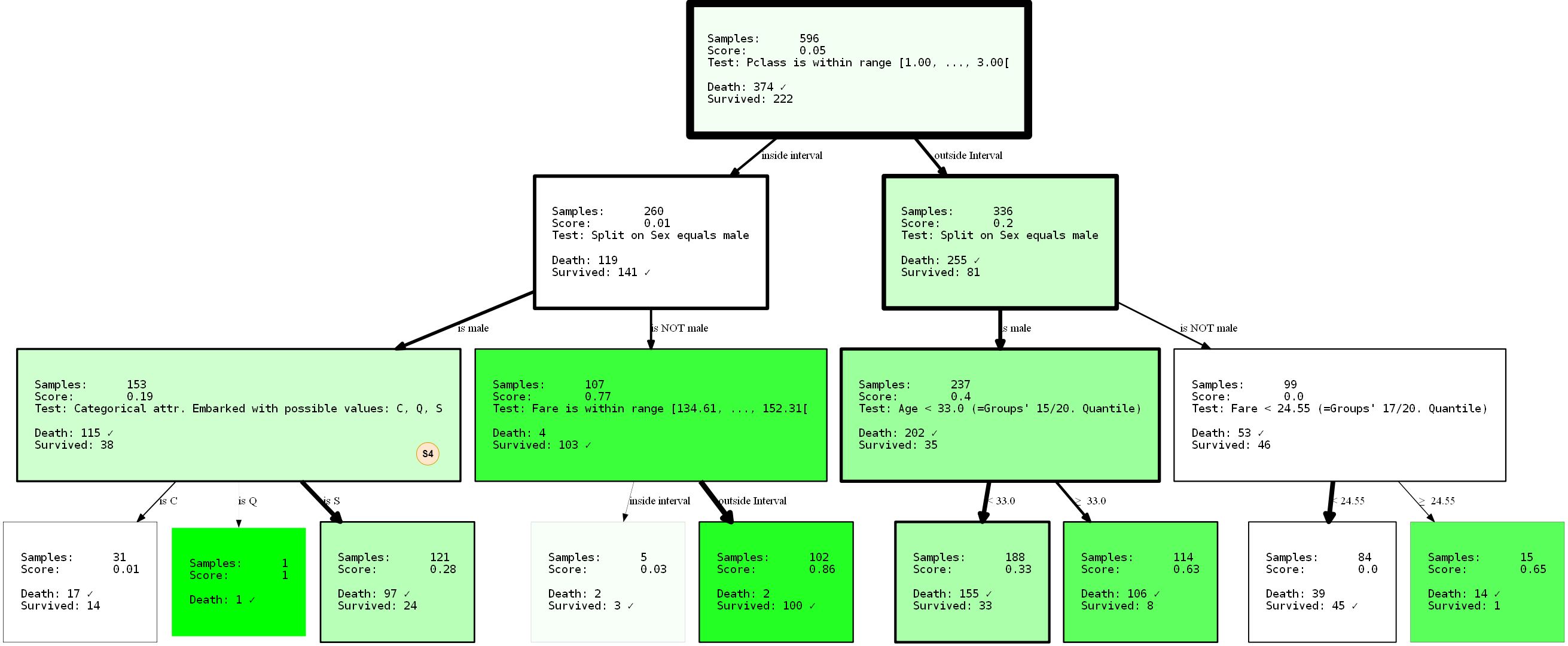
我将完整地展示生成的HDTree,因为我们可以观察到新生成的树中缺少的拆分(S4)。
通过
sex使用参数min_level=1(提示:当然您也可以提供max_level)防止拆分出现在根目录中 ,我们已经完全重构了树。现在,其性能分别为80.37%和81.69%(培训/测试)。即使我们在根节点进行了更好的分离,它也根本没有改变。
由于决策树贪婪,因此它们只会为每个节点找到本地_最佳分区,而这根本不一定是_最佳_选项。实际上,找到决策树问题的理想解决方案是一个NP完全问题,如[15]所证明的。因此,我们所要求的最好的方法是启发式。让我们回到示例:注意,我们已经获得了数据的简单表示?不过这很简单。如果说男人的生存机会较低,那么在较低程度上,可以得出结论,
PClass从切尔堡(Embarked=C)飞出的一年级或二年级学生可能会增加您的生存机会。或者,如果您是PClass 333岁以下的男性 ,您的机会也会增加?记住:妇女和儿童优先。通过解释可视化效果自己得出这些结论是一个很好的练习。这些结论仅由于树的限制才有可能。谁知道通过应用其他限制还能揭示什么?试试吧!
作为此类的最后一个示例,我想向您展示如何将分区限制为特定的属性。这不仅适用于防止在不需要的相关性或强制选择上进行树学习,而且可以缩小搜索空间。该方法可以大大减少执行时间,尤其是在使用多元分区时。如果返回上一个示例,则可能会找到一个检查attribute的节点
PassengerId。也许我们不想对其建模,因为至少它不应该对生存信息有所帮助。检查乘客ID可能是重新培训的信号。让我们用一个参数来改变情况blacklist_attribute_indices。
- SNIP -
...allowed_splits=[TwentyQuantileRangeSplit.build_with_restrictions(blacklist_attribute_indices=['PassengerId']),
FixedValueSplit.build_with_restrictions(blacklist_attribute_indices=['Name Length']),
...],
- SNIP -
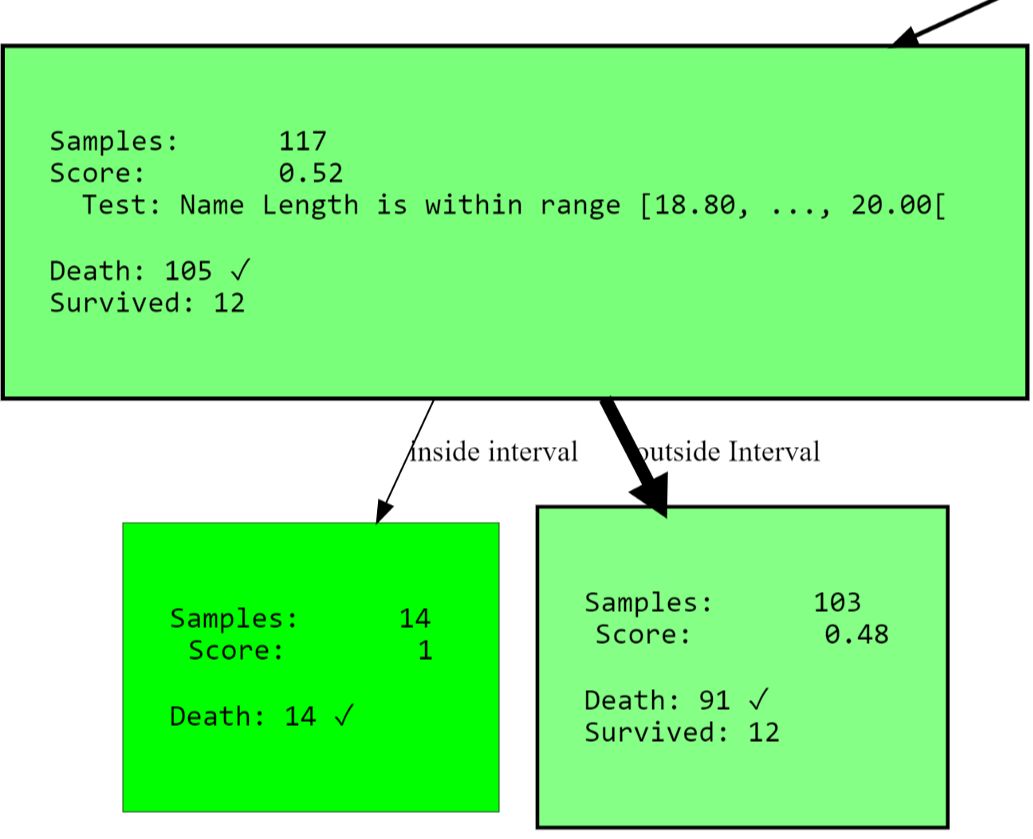
您可能会问为什么
name length它会出现。请注意,长名(双名或[贵族]头衔)可以表示过去的辉煌,从而增加您生存的机会。
附加提示:您始终可以将同一事物添加SplitRule两次。如果只想将某些HDTree级别的属性列入黑名单,则不添加SplitRule任何级别限制。
数据点预测
您可能已经注意到,scikit-learn通用接口可用于预测。这
predict(),predict_proba()以及 score()。但是您可以走得更远。有explain_decision()一个将显示解决方案的文本表示。
print(hdtree_titanic_3.explain_decision(X_titanic_train[42]))
假定这是对树的最后更改。该代码将输出以下内容:
Query:
Query:
{'PassengerId': 273, 'Pclass': 2, 'Sex': 'female', 'Age': 41.0, 'SibSp': 0, 'Parch': 1, 'Fare': 19.5, 'Cabin': nan, 'Embarked': 'S', 'Name Length': 41}
Predicted sample as "Survived" because of:
Explanation 1:
Step 1: Sex doesn't match value male
Step 2: Pclass doesn't match value 3
Step 3: Fare is OUTSIDE range [134.61, ..., 152.31[(19.50 is below range)
Step 4: Leaf. Vote for {'Survived'}
即使丢失数据也可以使用。让我们将属性索引2(
Sex)设置为missing (None):
passenger_42 = X_titanic_train[42].copy()
passenger_42[2] = None
print(hdtree_titanic_3.explain_decision(passenger_42))
Query:
{'PassengerId': 273, 'Pclass': 2, 'Sex': None, 'Age': 41.0, 'SibSp': 0, 'Parch': 1, 'Fare': 19.5, 'Cabin': nan, 'Embarked': 'S', 'Name Length': 41}
Predicted sample as "Death" because of:
Explanation 1:
Step 1: Sex has no value available
Step 2: Age is OUTSIDE range [28.00, ..., 31.00[(41.00 is above range)
Step 3: Age is OUTSIDE range [18.00, ..., 25.00[(41.00 is above range)
Step 4: Leaf. Vote for {'Death'}
---------------------------------
Explanation 2:
Step 1: Sex has no value available
Step 2: Pclass doesn't match value 3
Step 3: Fare is OUTSIDE range [134.61, ..., 152.31[(19.50 is below range)
Step 4: Leaf. Vote for {'Survived'}
---------------------------------
这将打印所有决策路径(不止一个,因为在某些节点上无法做出决策!)。最终结果将是所有叶子中最常见的类别。
...其他有用的东西
您可以继续获取树视图作为文本:
Level 0, ROOT: Node having 596 samples and 2 children with split rule "Split on Sex equals male" (Split Score:
0.251)
-Level 1, Child #1: Node having 390 samples and 2 children with split rule "Age is within range [28.00, ..., 31.00["
(Split Score: 0.342)
--Level 2, Child #1: Node having 117 samples and 2 children with split rule "Name Length is within range [18.80,
..., 20.00[" (Split Score: 0.543)
---Level 3, Child #1: Node having 14 samples and no children with
- SNIP -
或访问所有干净的节点(得分高):
[str(node) for node in hdtree_titanic_3.get_clean_nodes(min_score=0.5)]
['Node having 117 samples and 2 children with split rule "Name Length is within range [18.80, ..., 20.00[" (Split
Score: 0.543)',
'Node having 14 samples and no children with split rule "no split rule" (Node Score: 1)',
'Node having 15 samples and no children with split rule "no split rule" (Node Score: 0.647)',
'Node having 107 samples and 2 children with split rule "Fare is within range [134.61, ..., 152.31[" (Split Score:
0.822)',
'Node having 102 samples and no children with split rule "no split rule" (Node Score: 0.861)']
HDTree扩展
您可能要添加到系统中的最重要的事情是您自己的
SplitRule。分离规则真的可以为所欲为分离......实现SplitRule通过实施AbstractSplitRule。这有点棘手,因为您必须处理数据提取,性能评估以及所有这些工作。由于这些原因,您可以根据拆分类型将包中的mixin添加到实现中。mixins为您完成大部分困难的工作。
参考书目
- [1] Wikipedia article on Decision Trees
- [2] Medium 101 article on Decision Trees
- [3] Breiman, Leo, Joseph H Friedman, R. A. Olshen and C. J. Stone. “Classification and Regression Trees.” (1983).
- [4] scikit-learn documentation: Decision Tree Classifier
- [5] Cython project page
- [6] Wikipedia article on pruning
- [7] sklearn documentation: plot a Decision Tree
- [8] Wikipedia article Support Vector Machine
- [9] MLExtend Python library
- [10] Wikipedia Article Entropy in context of Decision Trees
- [12] Wikipedia Article on imputing
- [13] Hackernoon article about one-hot-encoding
- [14] Wikipedia Article about Quantiles
- [15] Hyafil, Laurent; Rivest, Ronald L. “Constructing optimal binary decision trees is NP-complete” (1976)
- [16] Hackernoon Article on Decision Trees
通过在线SkillFactory课程,了解如何从头开始或在技能和薪资水平上获得高知名度的职业的详细信息:
- 机器学习课程(12周)
- 高级课程“机器学习专业版+深度学习”(20周)
- « Machine Learning Data Science» (20 )
- «Python -» (9 )
E
