在Surf中,我们编写了自己的解释器,并在移动应用程序的客户端上使用了它-尽管最初看来,这通常与移动开发无关。实际上,解释器和编译器是解决任何地方都可以找到的问题的工具。因此,了解它的工作原理并能够自己编写将很有用。
今天,以将遮罩从一种格式转换为另一种格式的示例为例,我们将了解构造解释器的基础知识,并了解如何使用形式语法,抽象语法树,翻译规则-包括解决业务问题的方法。

关于口罩的一些知识:它们是什么以及为什么需要它们
. , , - — , . -: , , .
, . , . , API - , : 9161234567 — 8, .
, , :
, , . , , , — . ? — .
— , . , .
, :

, , : . .
, . , . , API - , : 9161234567 — 8, .
, , :
- , , .
- : , , , .
- , .
, , . , , , — . ? — .
— , . , .
, :
- . , , .
- « »: -, .
- .
, , : . .
— UX-
你为什么不能拿起面具来形容
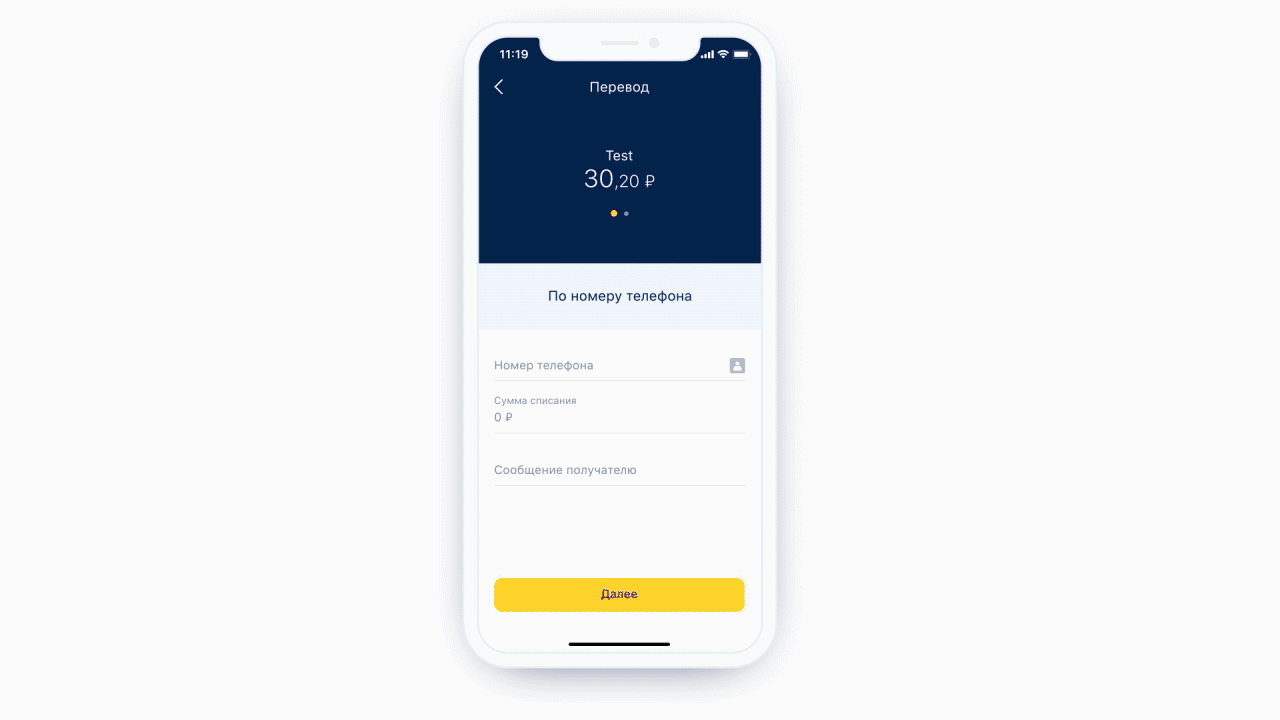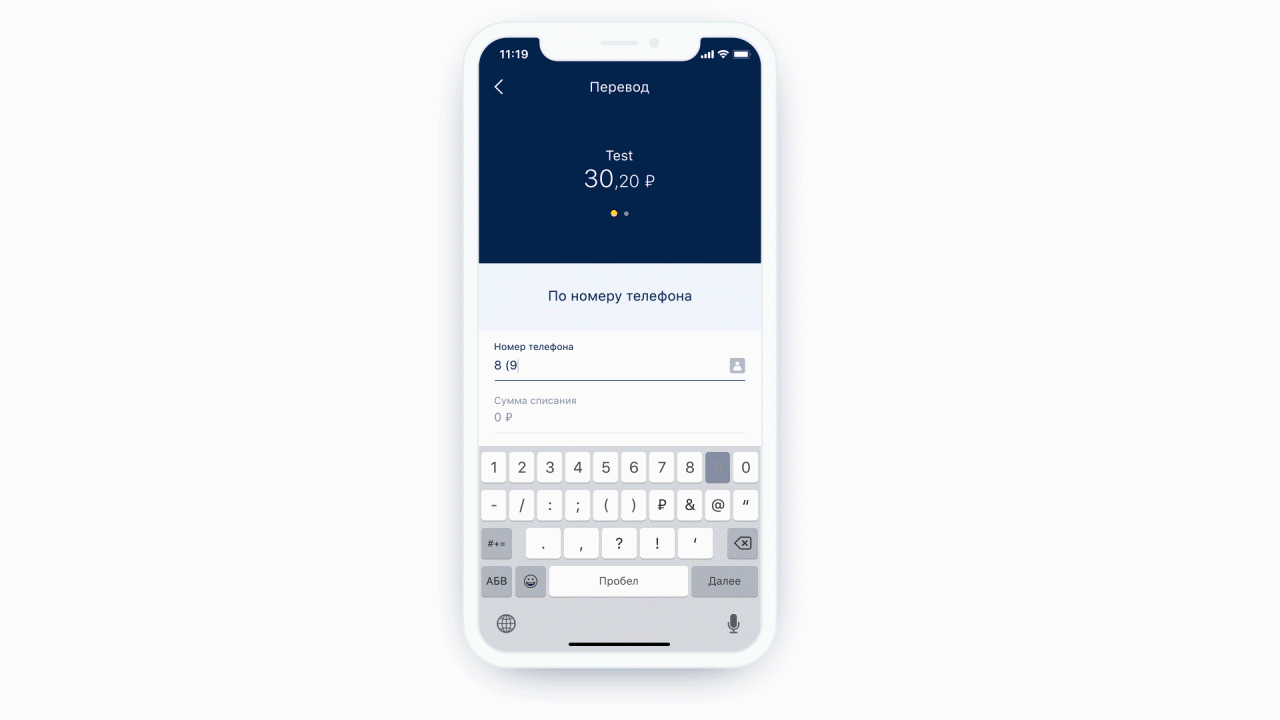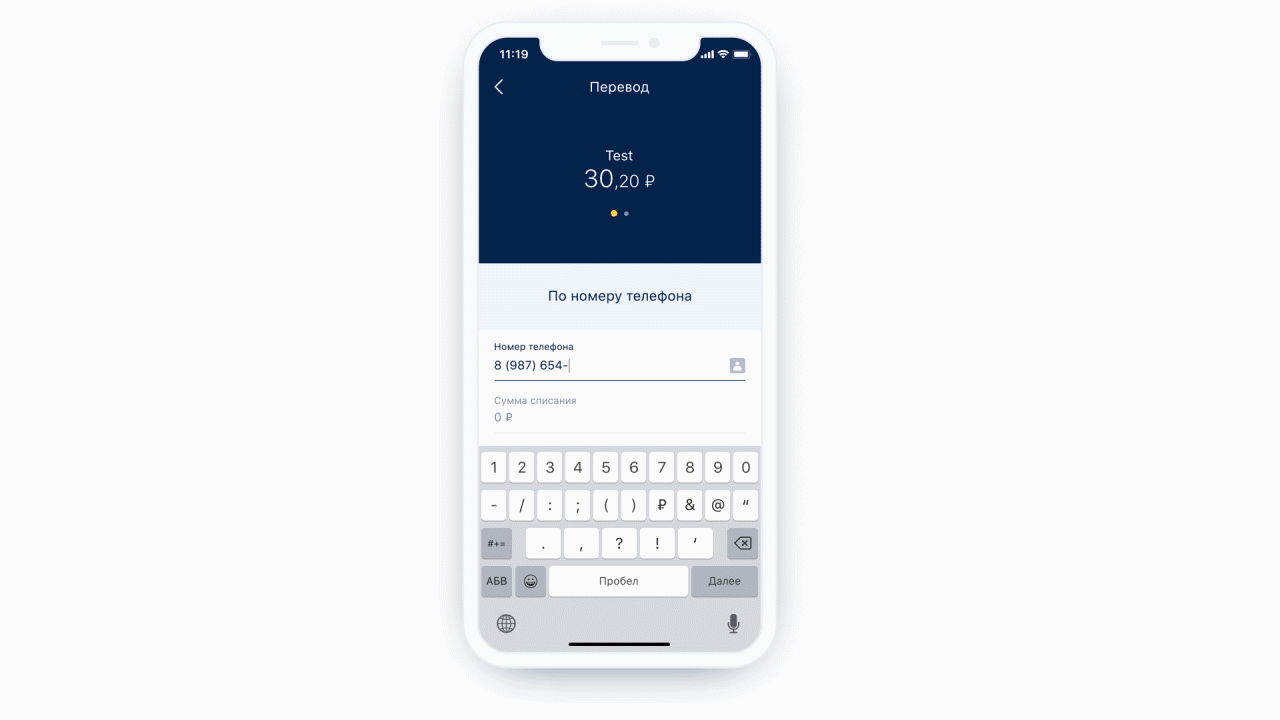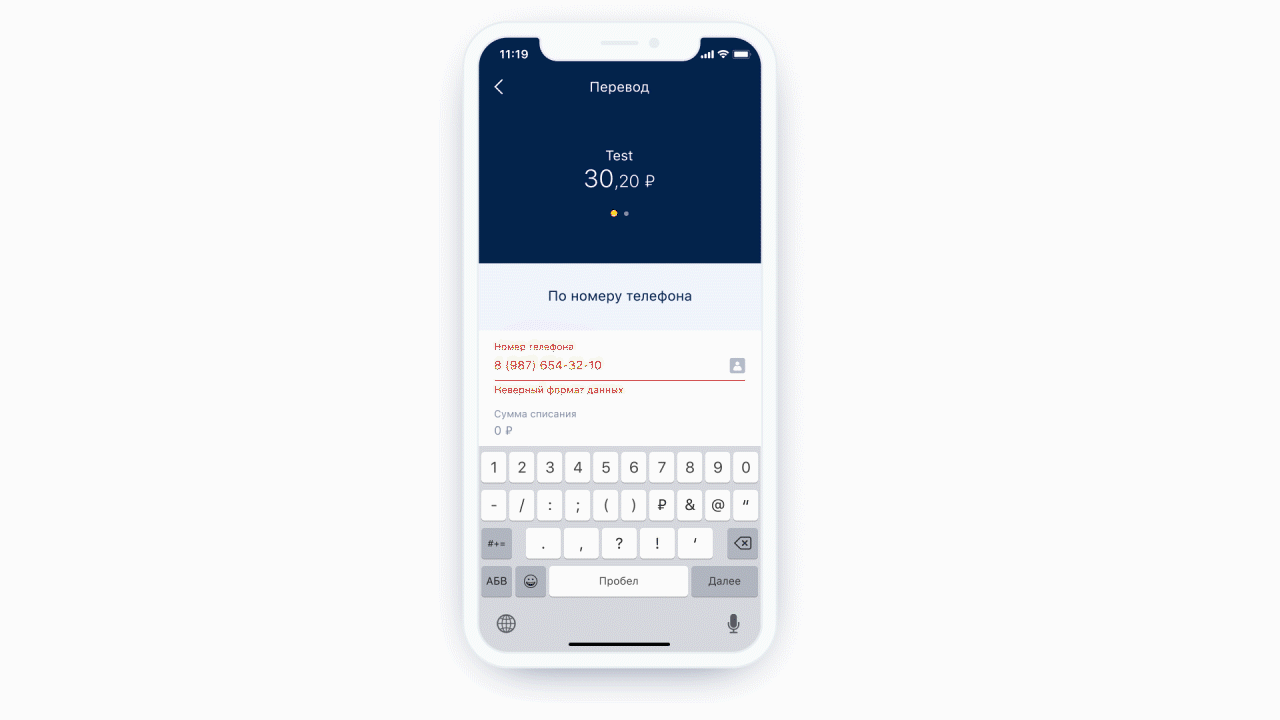
口罩凉爽舒适。但是在某些情况下存在一个不可避免的问题:当客户端使用一种掩码格式,而服务器使用许多不同的数据提供程序并且每种都有自己的格式时。我们不能指望会有相同的格式。向服务器询问:“根据需要为我们安装面具”-也是。您需要能够忍受它。
问题出现了:有一个后端规范,您需要编写一个前端-移动应用程序。您可以手动编写应用程序的所有掩码-当只有一个提供程序且掩码很少时,这是一个不错的选择。当然,程序员必须花时间来了解至少两个蒙版规范:后端和前端。然后,他需要将特定的后端掩码转换为相应的前端掩码。这还需要时间,这是人为因素-您可能会错。这不是一件容易的事,翻译很难:有些遮罩语言主要是为计算机而不是人类编写的。
如果服务器上的掩码突然更改或出现了新的掩码,则该应用程序可能首先停止工作。其次,需要再次进行艰苦的翻译工作,必须发布新的应用程序,这需要时间,精力和金钱。问题出现了:如何减少程序员的工作量?似乎所有这一切都应该由机器完成,但是由于某种原因,有人正在这样做。
答案是肯定的,我们有解决方案。面具是用计算机语言编写的-这就是为什么一个人很难与他合作并从一种语言翻译成另一种语言的原因之一。我们需要将这项工作转移到计算机上。由于掩码似乎是形式语法,将一种语法翻译成另一种语法的最可靠方法是:
- 了解构建原始语法的规则,
- 了解构建目标语法的规则,
- 将翻译规则从源语法写到目标,
- 在代码中实现所有这些。
这就是编写编译器和翻译器的目的。
现在,让我们仔细看一下基于形式语法的解决方案。
背景
在我们的应用程序中,根据后端驱动原理形成了许多不同的屏幕:屏幕的完整说明以及数据均来自服务器。

大多数屏幕包含各种输入形式。服务器确定表单上的哪些字段以及应如何设置它们的格式。掩模也用于描述这些要求。
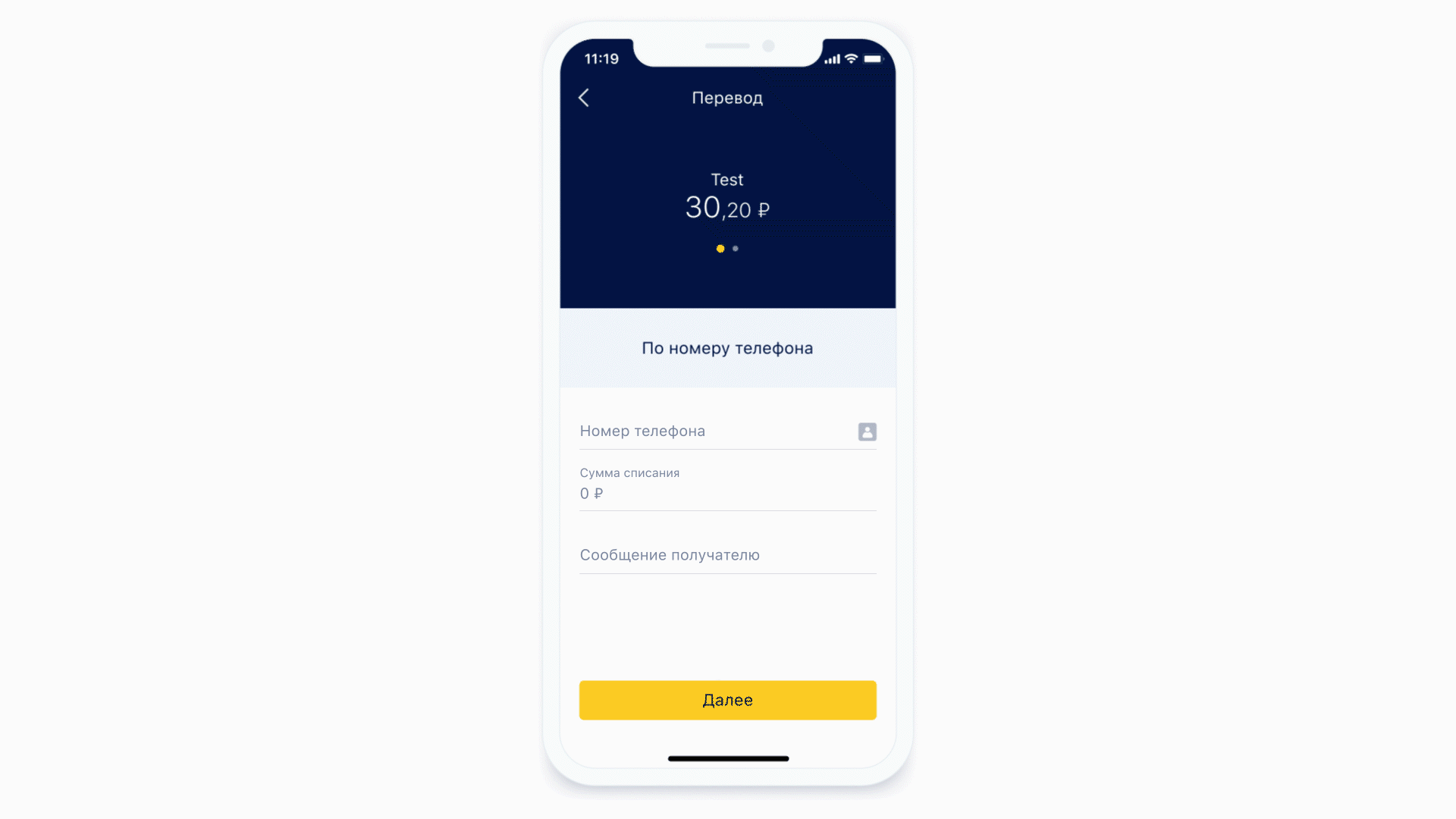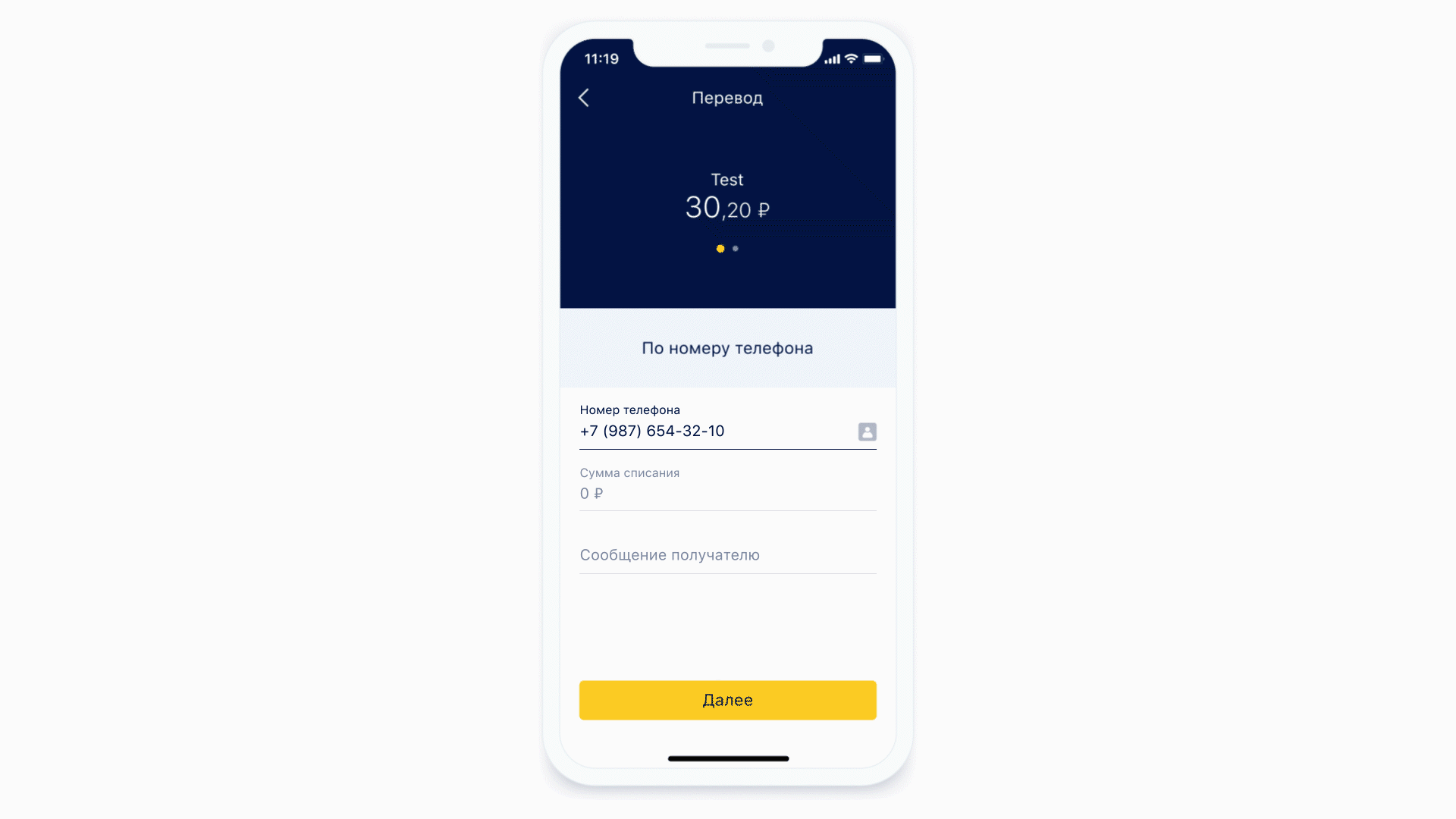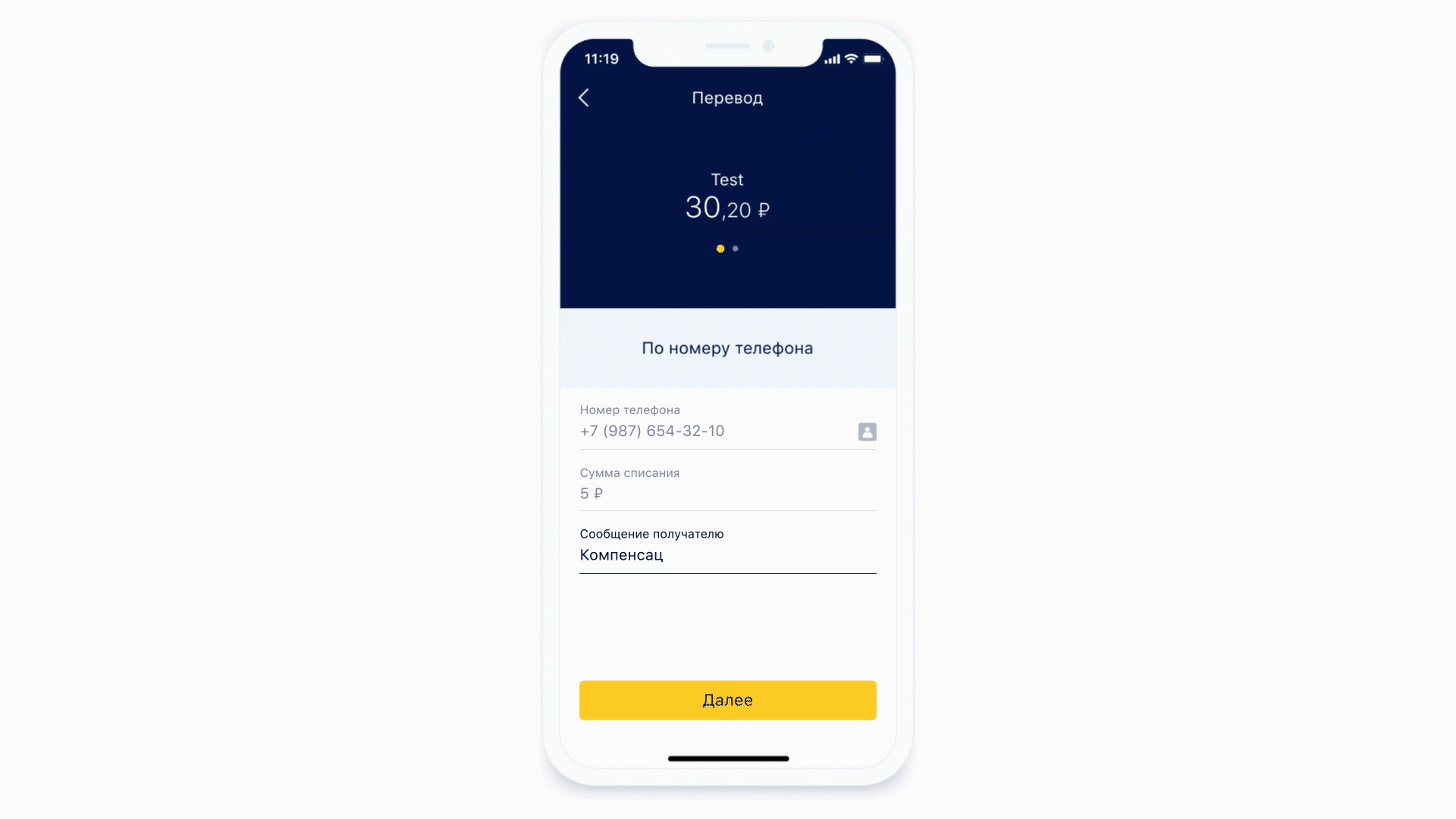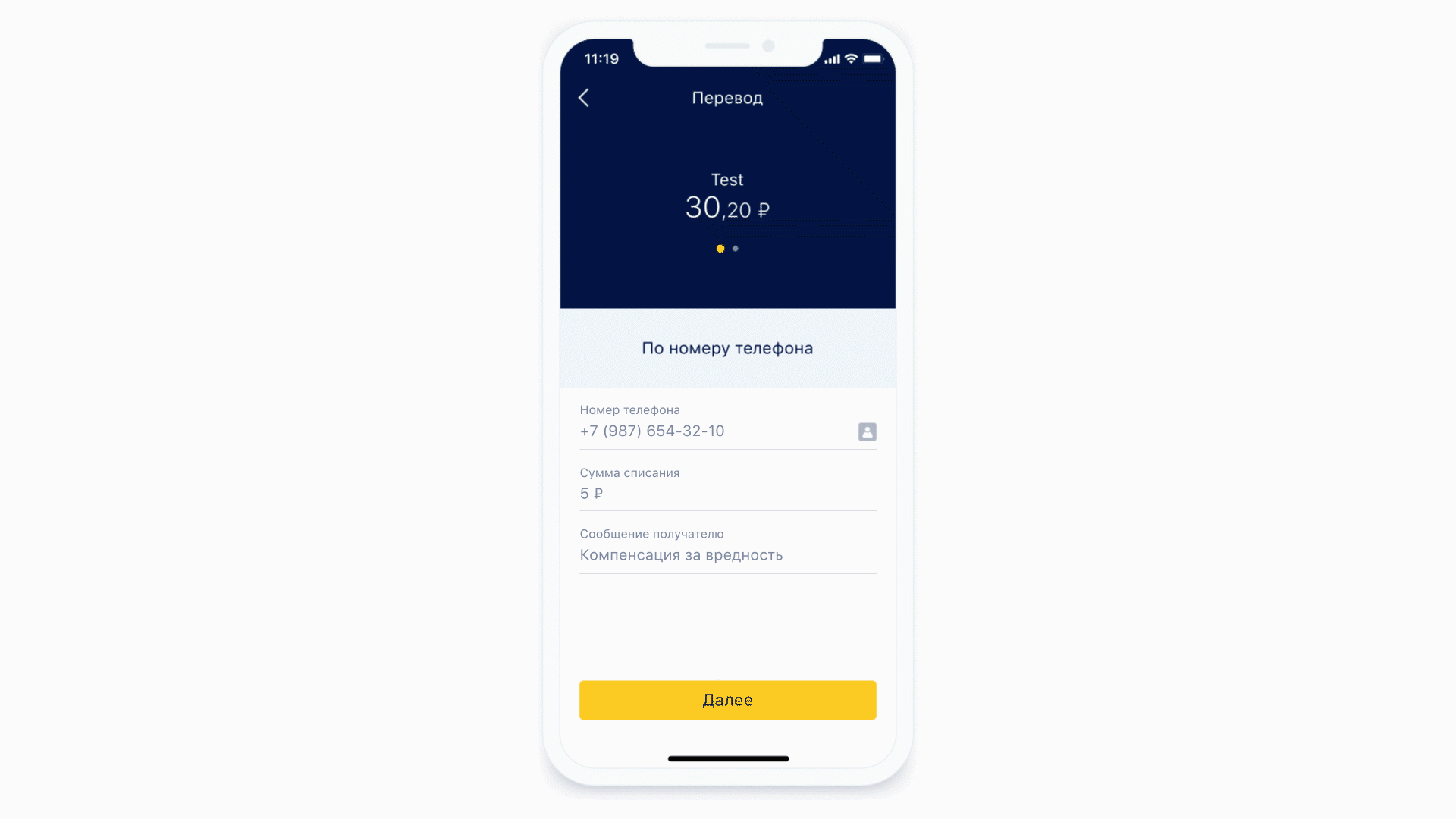
让我们看看口罩是如何工作的。
不同格式的蒙版示例
作为第一个示例,让我们采用输入电话号码的相同形式。这种形状的遮罩可能看起来像这样。

一方面,掩码本身会添加定界符,括号并禁止输入错误的字符。另一方面,相同的掩码从格式化的输入中提取有用的信息,以发送到服务器。
称为常数的部分以红色突出显示。这些是将自动显示的符号-用户不应输入它们:

接下来是动态部件-它总是括在尖括号中:

在本文中,我进一步将此表达式称为“动态表达式”-或简称为DW
这是一个表达式,我们将通过该表达式来格式化输入:

负责动态部件内容的部件以红色突出显示。
\\ d-任何数字。
+-常规中继器:至少重复一次。
$ {3}是一个元信息符号,它指定重复次数。在这种情况下,应该有三个字符。
然后,表达式\\ d + $ {3}表示必须有三个数字。
在这种格式的蒙版中,动态部分内只能有一个中继器:

出现此限制是有原因的-现在我将解释原因。
假设我们有一个DW,其中的大小是硬编码的:4个元素。我们用中继器给它2个元素:`<!^ \\ d + \\ v + $ {4}>。以下组合归入此类DV:
- 1abc
- 12ab
- 123a
事实证明,这样的DV并不能给我们明确的答案,而是第二个字符(数字或字母)的期望。
戴上面具,并在用户输入下添加它。我们得到格式化的电话号码:

在客户端上,掩码的格式可能看起来不同。例如,在Redmadrobot的“输入掩码”库中,电话号码的掩码如下所示:

看起来更好,更易于理解。
事实证明,服务器的掩码和客户端的掩码写的不同,但是它们做的是相同的。

让我们重新表述这个问题:如何组合不同格式的遮罩
我们需要将这些蒙版相互结合-或以某种方式获得其中的第二个。
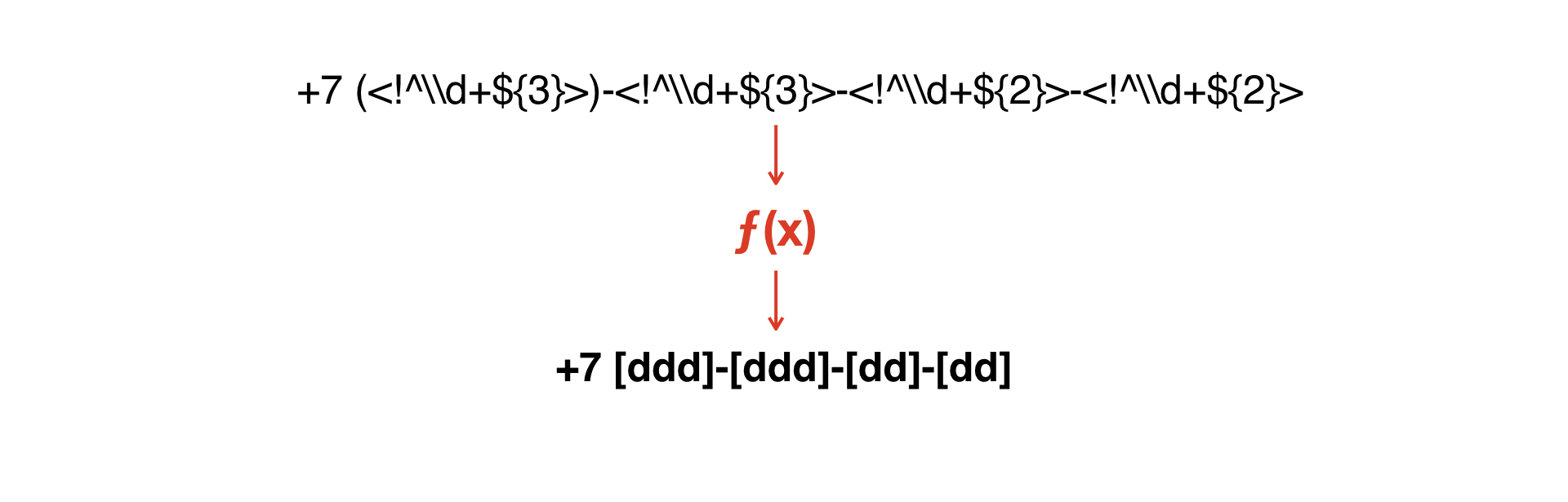
我们需要构建一个将一个蒙版转换为另一个蒙版的函数。
这里的想法是编写一个非常简单的解释器,该解释器允许从一个语法中获得第二个语法。
自从我们到达口译员之后,让我们来谈谈语法。
解析如何完成
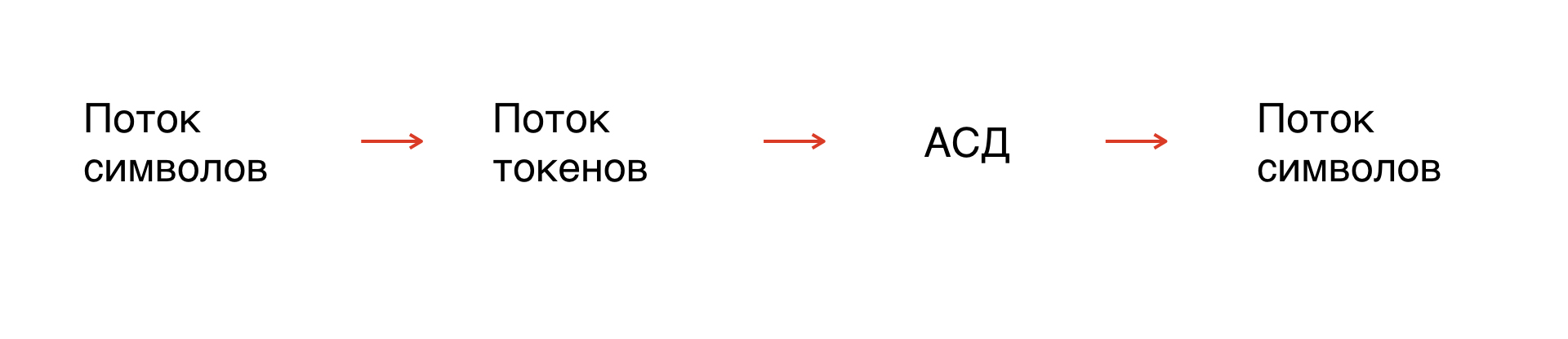
首先,我们有一串角色-面具。实际上,这就是我们要处理的字符串。但是由于符号没有形式化,所以您需要形式化字符串:将其分解为解释器可以理解的元素。
这个过程称为令牌化:符号流变成令牌流。令牌的数量有限,已被形式化,因此可以对其进行分析。
此外,基于语法规则,我们沿着令牌流构建了一个抽象语法树。从树中,我们得到了所需语法中的符号流。
有一个表达。我们看一下它,然后看到我们有一个上面提到的

常量:我们将所有常量表示为CS令牌,其参数是常量本身:

下一种令牌类型是DW的开头:

此外,所有这些标记将被解释为特殊字符。在我们的示例中,它们不多,在真实的蒙版中可以有更多。

然后我们有一个中继器。
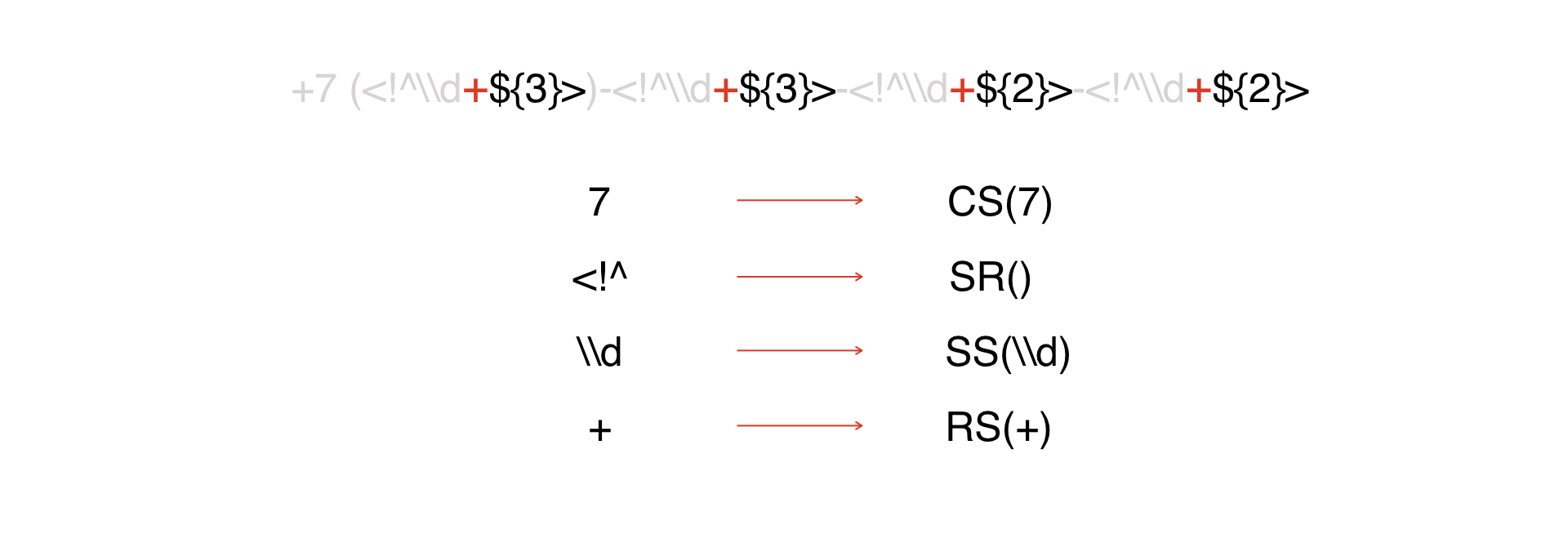
然后-一些被认为是元数据的字符。我们将作弊并为他们提供一个令牌,因为这样更容易。

远东的尽头。因此,我们已将所有内容分解为令牌。

标记化电话号码掩码的示例
为了从原则上了解令牌化过程是如何进行的以及解释器将如何工作,我们为电话号码设置了一个掩码并将其转换为令牌流。

首先,+号。转换为常数+。然后,我们对七个符号和所有其他符号执行相同的操作。我们得到了一系列令牌。这还不是一个结构-我们将进一步分析该数组。
Lexer和构建ASD
现在最棘手的部分是词法分析器。

左侧描述了图例-用于描述词汇规则的特殊字符。右边是规则本身。
symbolRule描述符号。如果该规则适用,则为真,表示我们遇到了特殊字符或常量字符。可以说这是一个功能。
接下来是repeaterRule。该规则描述了遇到字符并带有中继器令牌的情况。
然后,一切看起来都相似。如果是LW,则它是符号或中继器。在我们的情况下,该规则更广泛。最后,必须有一个带有元数据的令牌。
最后一条规则是maskRule。这是符号和DV的序列。
现在让我们建立标记数组中的抽象语法树(AST)。
这是令牌列表。树的第一个节点是根节点,我们将从该根节点开始构建。这没有任何意义,只需要一个根即可。

我们有第一个标记+,所以我们只添加一个子节点即可。

我们对所有其他常量符号都执行相同的操作,但是更加复杂。我们遇到了DV令牌。

这不仅是一个常规网站-我们知道它必须具有某种内容。

内容节点只是我们将来可以导航到的技术节点。它有自己的子节点,下一个是哪个节点?流中的下一个标记是特殊字符。会是子节点吗?

实际上,在这种情况下,不会。我们将有一个中继器作为子节点。

为什么?因为将来使用木材会更方便。假设我们要解析这棵树并基于它构建某种语法。解析树时,我们查看节点的类型。如果我们有一个CS节点,则将其解析为相同的CS节点,但语法不同。按照约定,我们遍历树的顶部并运行某种逻辑。
逻辑取决于节点的类型-或位于节点中的令牌的类型。对于解析,立即了解哪个令牌在您面前更加方便:复合(如中继器)或简单(如CS)。这是必要的,这样就不会对子节点进行双重解释或不断搜索。
这在字符组上尤其明显:例如[abcde]。显然,在那种情况下,必须有某种父GROUP节点,该父GROUP节点将具有子节点CS(a)CS(b)等的列表。
返回带有元数据的令牌。它不包含在内容中,而是在侧面。

为了使使用树变得更容易,这是必需的,因此我们不将这个节点视为内容-因为实际上它不属于它。
DV结束了,我们不认为它是某种节点:它是现在可以丢弃的令牌。我们不会将其变成树节点。
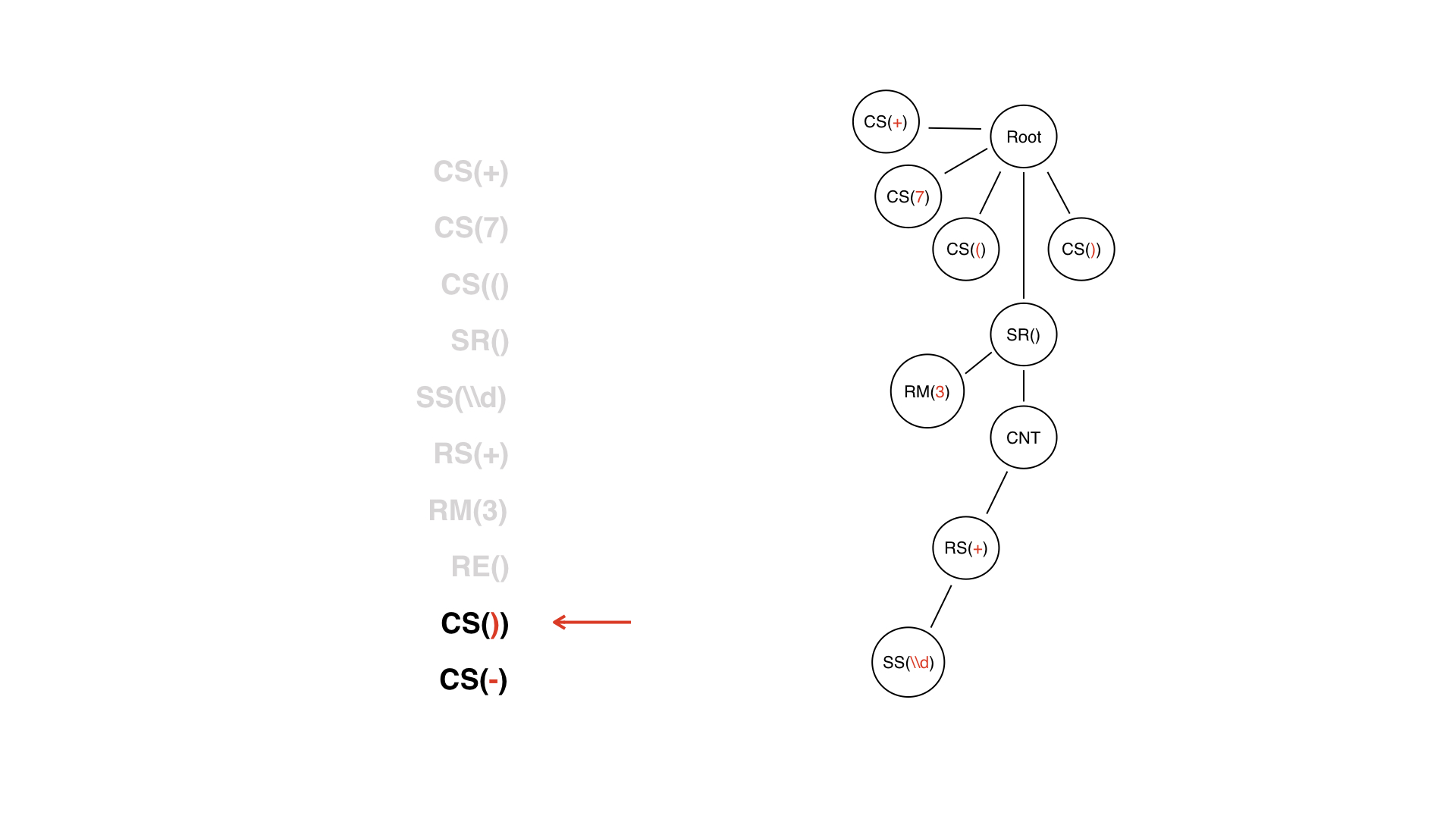
我们已经有一个子树,其根是SR节点-也就是非常动态的部分。LW令牌的结尾在树的构建过程中为我们提供了很多帮助-我们可以了解LW的子树何时完成。但这令牌没有逻辑价值:看着一行一行的树,我们已经知道DW何时结束,因为它实际上已经被SR节点关闭了。
此外-只是普通的常量符号。

我们有一棵树。现在让我们深入研究这棵树,并在其基础上构建其他语法:您需要进入一个节点,查看其类型,然后从该节点生成另一个语法的元素。
Redmadrobot的InputMask库的语法
让我们看一下Redmadrobot库的语法。

这是相同的表达。+7是将自动添加的常数。在花括号内,描述了DV-动态部分。DV内有一个特殊字符d。Redmadrobot具有表示数字的默认表示法。
表示法如下所示:

表示法由三部分组成:
- 字符是我们将用来写掩码的字符。遮罩字母由什么组成。例如,d。
- characterSet-用此符号匹配用户键入的字符。例如0、1、2、3、4,依此类推。
- isOptional-用户是否必须输入characterSet字符之一或不输入任何字符。
看,我们现在有这样的面具了。

- “ b”字符具有特殊的数字符号,并且不是可选的。
- 字符“ c”具有不同的表示法-CharacterSet是不同的。这也不是可选的。
- 字符“ C”与“ c”相同,只是它是可选的。这是必要的,因此在掩码中,我们查看元数据并看到没有硬限制,而是一个弱限制。
如果您需要编写一个可以包含1到10个字符的规则,那么一个字符将不是可选的。并且九个字符将是可选的。也就是说,在示例的注释中,它们将以大写字母书写。结果,此规则将如下所示:[cCCCCCCCCC]
示例:将电话号码掩码从后端格式转换为InputMask格式
这是我们在最后一步中得到的树。我们需要继续前进。我们要做的第一件事是扎根。

从根开始,我们发现自己处于常数符号+中,我们立即生成+。在右侧,以InputMask格式编写了一个掩码。

下一个字符是可以理解的-仅7个字符,后跟一个空心括号。
然后生成了一部分动态零件,但尚未填充。

我们进去,我们有内容,这是一个技术节点。我们什么都不写。

在这里,我们有一个中继器,我们也不会在任何地方写任何东西,因为掩码中没有这样的符号。这样的规则不能写下来。

最后,我们来介绍某种内容符号。
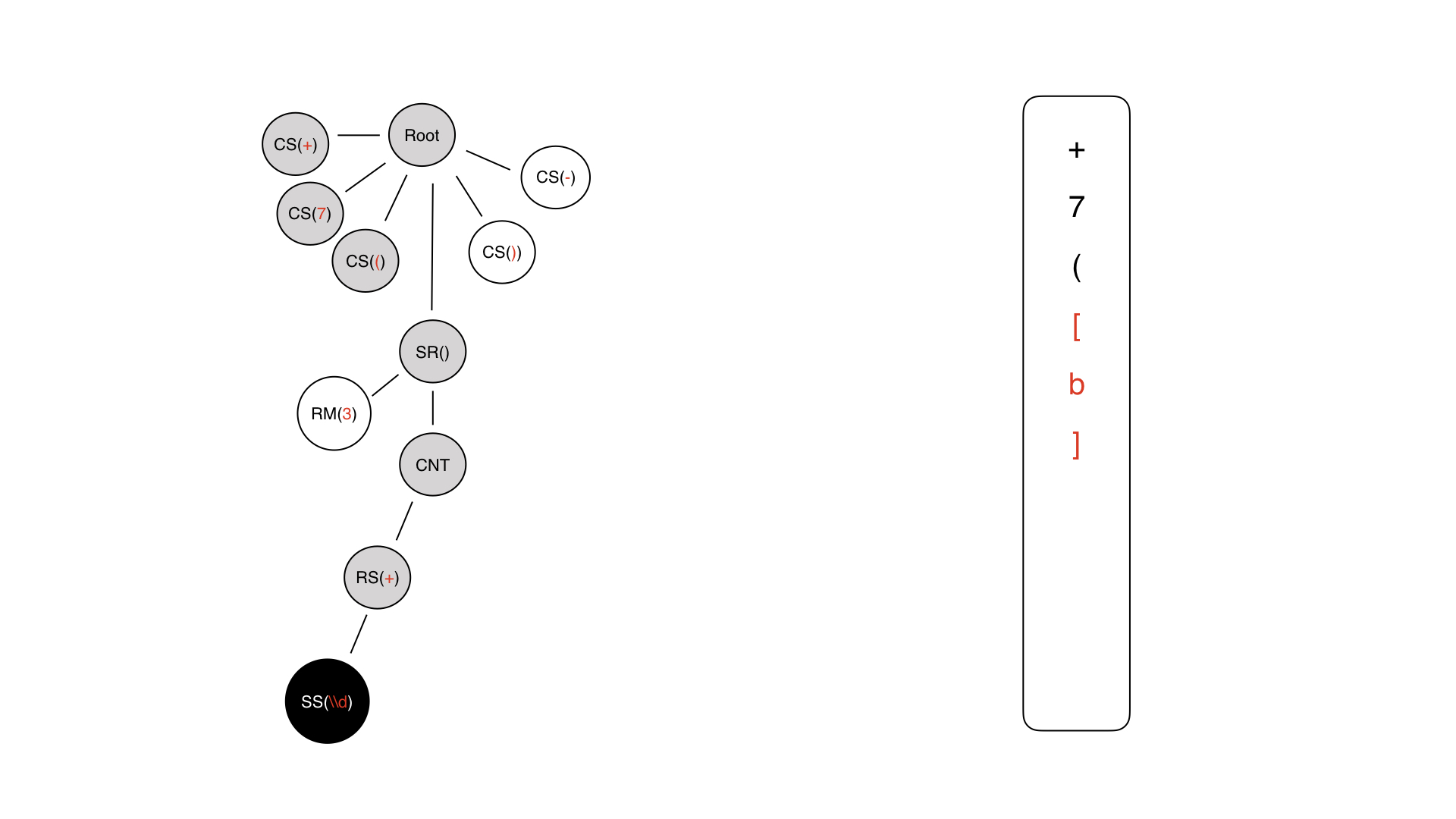
内容符号可以是常量符号或特殊符号。在这种情况下,将使用一种特殊的语言,因为只有这种语言会承载某种语义上的输入负载。
所以我们写了它,我们回过头去只是为了获取元信息。

让我们看看那里有一个中继器,这里有3个-硬限制。因此,我们将其重复三遍,我们得到了如此动态的作品。然后我们添加常量符号。

结果,我们得到的蒙版看起来像机器人格式的蒙版。
在实践中,我们采用一种语法,然后从中生成另一种语法。
从服务器端生成客户端语法的规则
现在介绍一下生成规则。这很重要。
可能会有这样的困难情况:动态部分中有几个不同的DW。大括号内:与DV中的大括号相同。让我们看看解释器如何处理这种情况。

首先是字符集,我们必须根据InputMask将其转换为某种符号。为什么?因为这是我们需要匹配的一组有限字符。我们需要结合用户输入和字符,因此我们将在此处编写一些特定的符号。
接下来,我们有\\ d字符。
下一步-具有可选尺寸的DV。

事实证明,第一个是字符b。它将具有一个包含abcd的字符集。
此外,很明显已经存在一个不同的符号,因为您不能以其他方式匹配它,否则将无法正确匹配它。然后,我们将这种表达变成这样。
最后一部分必须包含至少一个符号。让我们将此要求指定为d。而且用户也可以输入两个附加字符,然后将它们指定为DD。
全部放在一起。

这是生成的字符集的示例。可以看出b对应于字符集abcd,对于数字-对应的预设字符集。对于d和D,相应的字符集包含12vf。
结果
我们已经学会了自动将一种语法转换为另一种语法:现在,根据服务器规范在应用程序中使用掩码。
我们免费获得的另一个功能是能够对来到我们的面罩进行静态分析。也就是说,我们可以了解此掩码需要哪种类型的键盘以及该掩码中可以容纳的最大字符数。而且它甚至更酷,因为现在我们不会一直为每个表单元素显示相同的键盘-我们在所需的表单元素下显示所需的键盘。而且,我们可以有条件地准确定义某个字段是电话输入字段。
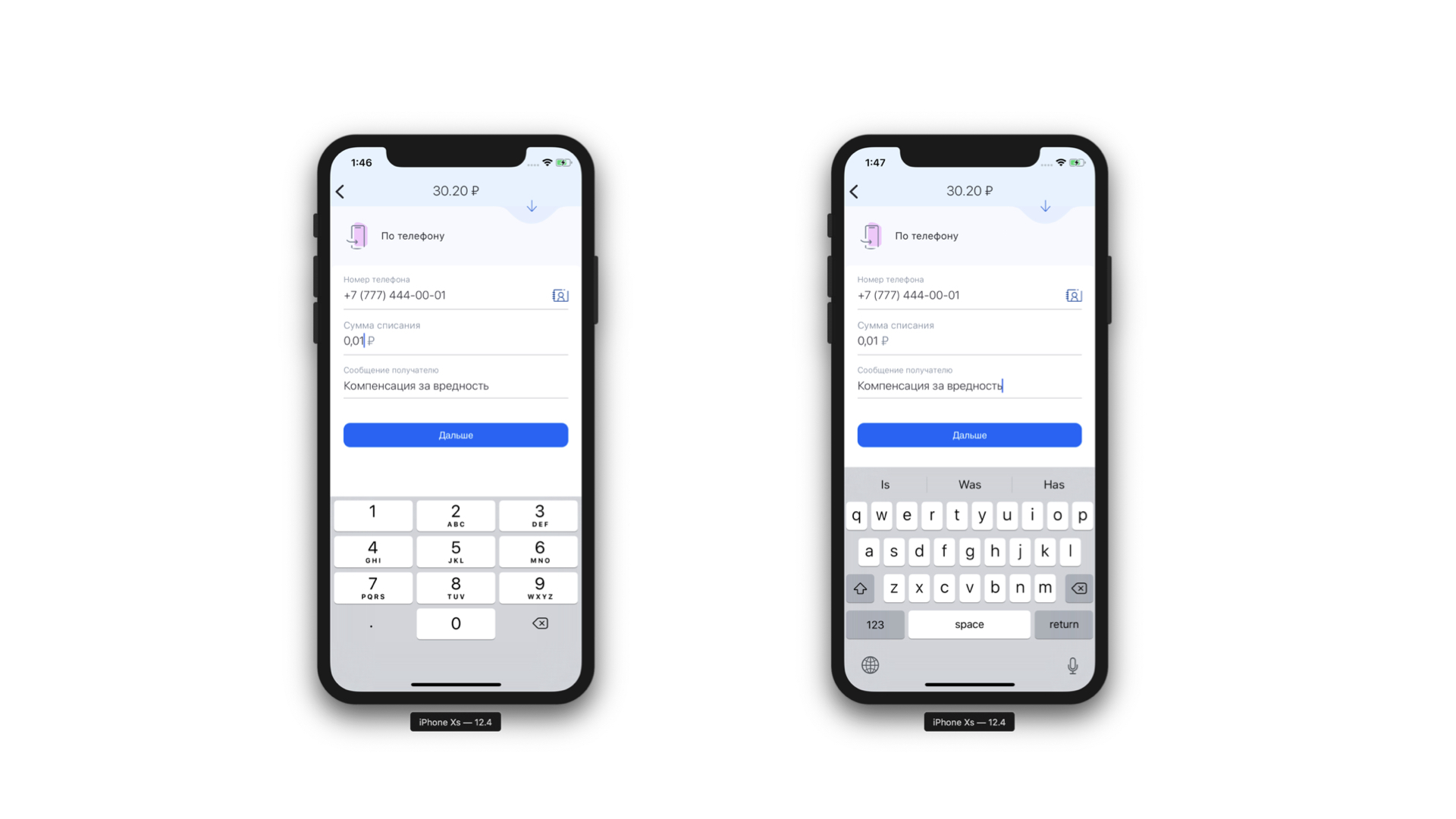
左:电话输入字段的顶部有一个图标(实际上是一个按钮),它将把用户发送到联系人列表。右:用于常规短信的键盘示例。
用于翻译遮罩的工作库
您可以看一下我们如何实现上述方法。该图书馆位于Github上。
翻译不同遮罩的示例
这是我们一开始就研究的第一个面具。它被解释为该RedMadRobot表示形式。

这是第二个掩码-只是某些内容的输入掩码。它被转换为这样的表示。
