介绍
本文是另一篇文章的汇编。在本文中,我打算重点研究用于处理数据的大数据的工具。
因此,假设您接受了原始数据,对其进行了处理,现在就可以将其进一步使用了。
有许多用于处理数据的工具,每种工具都有其自身的优点和缺点。大多数都是面向OLAP的,但是有些也是OLTP优化的。其中一些使用标准格式,仅专注于查询的执行,另一些使用其自己的格式或存储将处理后的数据传输到源,以提高性能。有些经过优化,可以使用某些模式(例如星型或雪花)存储数据,而其他一些则更灵活。总结起来,我们有以下反对意见:
- 数据仓库与湖
- Hadoop与离线存储
- OLAP与OLTP
- 查询引擎与OLAP机制
我们还将研究具有执行查询功能的数据处理工具。
数据处理工具
提到的大多数工具都可以连接到Hive等元数据服务器并运行查询,创建视图等。这通常用于创建其他(改进的)报告级别。
Spark SQL提供了一种将SQL查询与Spark程序无缝混合的方法,因此您可以将DataFrame API与SQL混合。它具有Hive集成和标准的JDBC或ODBC连接,因此您可以通过Spark将Tableau,Looker或任何BI工具连接到数据。

Apache Flink还提供了SQL API。Flink的SQL支持基于Apache Calcite,该实现了SQL标准。它还通过HiveCatalog与Hive集成。例如,用户可以使用HiveCatalog将其Kafka或ElasticSearch表存储在Hive Metastore中,并稍后在SQL查询中重新使用它们。
Kafka还提供SQL功能。通常,大多数数据处理工具都提供SQL接口。
查询工具
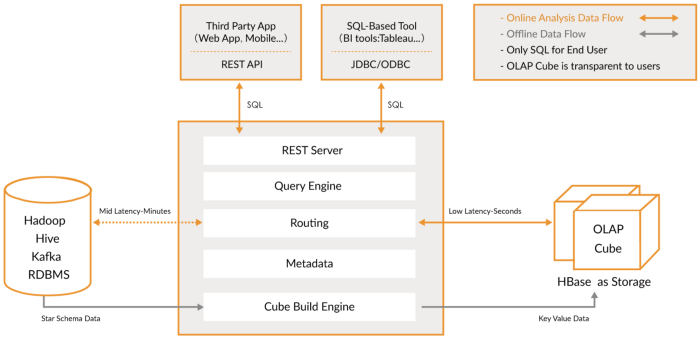
这类工具专注于统一查询不同格式的不同数据源。这个想法是使用SQL将查询路由到您的数据湖,就好像它是常规的关系数据库一样,尽管它有一些限制。其中一些工具还可以查询NoSQL数据库等等。这些工具为外部工具(如Tableau或Looker)提供JDBC接口,以安全地连接到您的数据湖。查询工具是最慢的选项,但提供了最大的灵活性。
阿帕奇猪:与Hive一起使用的最早工具之一。除了SQL之外,还有自己的语言。 Pig创建的程序的一个显着特征是它们的结构有助于显着的并行化,这反过来又使它们可以处理非常大的数据集。因此,与现代基于SQL的系统相比,它仍然不落伍。
普雷斯托:来自Facebook的开源平台。它是一个分布式SQL查询引擎,用于对任何大小的数据源执行交互式分析查询。 Presto允许您查询任何位置的数据,包括Hive,Cassandra,关系数据库和文件系统。它可以在几秒钟内查询大型数据集。 Presto独立于Hadoop,但与大多数工具(尤其是Hive)集成在一起以执行SQL查询。
阿帕奇钻:为Hadoop,NoSQL甚至云存储提供无模式的SQL查询引擎。它不依赖Hadoop,但与Hive等生态系统工具集成了许多功能。单个查询可以合并来自多个存储的数据,执行针对每个存储的特定优化。这很好,因为允许分析人员将任何数据视为表,即使他们实际上正在读取文件也是如此。 Drill完全支持标准SQL。业务用户,分析师和数据科学家可以使用Tableau,Qlik和Excel等标准商业智能工具,通过Drill JDBC和ODBC驱动程序与非关系数据存储进行交互。除了,开发人员可以在其自定义应用程序中使用简单的REST API Drill来创建精美的可视化效果。
OLTP数据库
尽管Hadoop已针对OLAP进行了优化,但仍然有一些情况需要针对交互式应用程序运行OLTP查询。
HBase在设计上具有非常有限的ACID属性,因为它是按比例构建的,并且不提供现成的ACID功能,但是它可用于某些OLTP场景。
Apache Phoenix建立在HBase之上,并提供了一种在整个Hadoop生态系统中进行OTLP查询的方法。Apache Phoenix已与Spark,Hive,Pig,Flume和Map Reduce等其他Hadoop产品完全集成。它还可以使用DDL命令存储元数据,支持表创建和增量版本控制。它的工作速度比使用Drill或其他工具快得多
请求机制。
您可以使用Hadoop生态系统之外的任何大型数据库,例如Cassandra,YugaByteDB,ScyllaDB for OTLP。
最后,很常见的是,任何类型的快速数据库(例如MongoDB或MySQL)都具有较慢的数据子集,通常是最新的。上面提到的查询引擎可以在单个查询中组合慢速存储和快速存储之间的数据。
分布式索引
这些工具提供了存储和检索非结构化文本数据的方法,并且由于需要专门的结构来存储数据,因此它们位于Hadoop生态系统之外。想法是使用倒排索引进行快速搜索。除文本搜索外,该技术还可用于多种目的,例如存储日志,事件等。有两个主要选项:
Solr:这是一个基于Apache Lucene的流行,非常快速的开源企业搜索平台。 Solr是一个健壮,可伸缩且具有弹性的工具,可提供分布式索引,复制和负载平衡查询,自动故障转移和恢复,集中式配置等。它非常适合于文本搜索,但是与ElasticSearch相比,它的用例有限。
弹性搜索:它也是一个非常受欢迎的分布式索引,但是已经发展成为一个自己的生态系统,它涵盖了许多用例,例如APM,搜索,文本存储,分析,仪表板,机器学习等。它非常有用,因此绝对是可用于DevOps或数据管道的工具箱中的工具。它还可以存储和搜索视频和图像。
弹性搜索可以用作数据湖的快速存储层,以提供高级搜索功能。如果您将数据存储在大型键值数据库(例如HBase或Cassandra)中,由于缺少连接,它们提供的搜索功能非常有限,则可以将ElasticSearch放在它们前面以运行查询,返回ID,然后在数据库中执行快速搜索。
它也可以用于分析。您可以导出数据,对其进行索引,然后使用Kibana进行查询通过创建仪表板,报告等,您可以添加直方图,复杂的聚合,甚至在数据之上运行机器学习算法。ElasticSearch生态系统非常庞大,非常值得探索。
OLAP数据库
在这里,我们看一下还可以为查询模式提供元数据存储的数据库。与查询执行系统相比,这些工具还提供数据存储,并且可以应用于特定的存储方案(星型架构)。这些工具使用SQL语法。Spark或其他平台可以与它们进行交互。
阿帕奇蜂巢:我们已经讨论过Hive作为Spark和其他工具的中央架构存储库,以便它们可以使用SQL,但是Hive也可以存储数据,因此您可以将其用作存储库。他可以访问HDFS或HBase。当Hive要求时,它使用Apache Tez,Apache Spark或MapReduce,比Tez或Spark快得多。它还具有一种称为HPL-SQL的过程语言。 Hive是Spark SQL的一种非常流行的元数据存储。
Apache Impala:这是Hadoop的本地分析数据库,您可以用来存储数据并有效地查询它。她可以使用Hcatalog连接到Hive以获取元数据。 Impala为Hadoop中的商业智能和分析查询提供了低延迟和高并发性(Apache Hive等打包平台未提供)。即使在多用户环境中,Impala也会线性扩展,这是比Hive更好的查询替代方案。 Impala与专有的Hadoop和Kerberos安全性集成在一起以进行身份验证,因此您可以安全地管理数据访问。它使用HBase和HDFS进行数据存储。

阿帕奇·塔霍(Apache Tajo):这是Hadoop的另一个数据仓库。 Tajo旨在针对HDFS和其他数据源中存储的大型数据集以低延迟和可伸缩性,在线聚合和ETL运行临时查询。它支持与Hive Metastore集成以访问常见的架构。它还具有许多查询优化功能,具有可伸缩性,容错性,并提供JDBC接口。
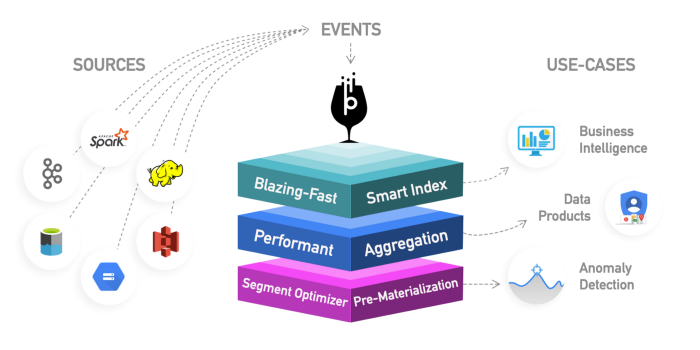
阿帕奇·基林:这是一个新的分布式分析数据仓库。Kylin的速度非常快,因此可以用于补充一些其他数据库,例如Hive,以应对性能至关重要的用例,例如仪表板或交互式报表。这可能是最好的OLAP数据仓库,但是很难使用。另一个问题是由于高拉伸而需要更多的存储空间。这个想法是,如果查询引擎或Hive不够快,则可以在Kylin中创建“多维数据集”,这是OLAP优化的多维表,具有预先计算的
您可以从仪表板或交互式报告中查询的值。它可以直接从Spark创建多维数据集,甚至可以从Kafka实时创建多维数据集。
OLAP工具
在此类别中,我包括较新的引擎,它们是以前OLAP数据库的演变,提供了更多功能,并创建了一个全面的分析平台。实际上,它们是前两种类别的混合体,它们为OLAP数据库添加了索引。它们位于Hadoop平台之外,但紧密集成。在这种情况下,您通常会跳过处理步骤并直接使用这些工具。
他们试图解决以统一方式查询实时数据和历史数据的问题,因此您可以在数据可用时立即立即查询实时数据,以及低延迟的历史数据,从而可以构建交互式应用程序和仪表板。在许多情况下,这些工具允许查询原始数据,而几乎不需要进行ELT样式的转换,但具有高性能,比传统的OLAP数据库要好。
它们的共同之处在于它们提供了数据,活泼和批处理数据摄取,分布式索引,本机数据格式,SQL支持,JDBC接口,热数据和冷数据支持,多种集成以及元数据存储的统一视图。
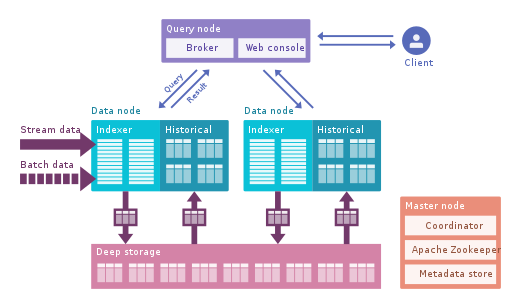
Apache Druid:这是最著名的实时OLAP引擎。它专注于时间序列数据,但可用于任何数据。它使用自己的列格式可以压缩大量数据,并且具有许多内置的优化功能,例如倒排索引,文本编码,自动折叠数据等等。数据使用时延非常低的Tranquility或Kafka实时加载,并以写优化字符串格式存储在内存中,但是一旦到达,它就可以像以前下载的数据一样用于查询。后台进程负责将数据异步移动到深度存储系统(例如HDFS)。当数据移至深度存储时,它会分成较小的块,时间隔离,称为段,为低延迟查询进行了优化。该细分市场具有多个维度的时间戳记,可用于过滤和汇总以及指标(这些指标是预先计算的状态)。在突发接收中,数据直接保存到段中。 Apache Druid支持推入和拉入吞咽,与Hive,Spark甚至NiFi集成。它可以使用Hive元数据存储并支持Hive SQL查询,然后将其转换为Druid使用的JSON查询。 Hive集成支持JDBC,因此您可以插入任何BI工具。它还有自己的元数据存储库,通常使用MySQL。它可以接受大量数据,并且可以很好地扩展。主要问题是它具有许多组件,并且难以管理和部署。
Apache Pinot:这是LinkedIn上更新的开源Druid替代产品。与Druid相比,得益于Startree索引,该索引提供了较低的延迟,该索引可以进行部分预计算,因此可以用于以用户为中心的应用程序(用于获取LinkedIn提要)。它使用排序索引,而不是倒排索引,索引速度更快。它具有可扩展的插件体系结构,并且具有很多集成,但不支持Hive。它还集成了批处理和实时处理,提供快速加载,智能索引以及将数据存储在段中的功能。与Druid相比,它部署起来更容易,更快,但是目前看来还不成熟。
ClickHouse:此引擎使用C ++编写,为OLAP查询(尤其是聚合)提供了令人难以置信的性能。它就像一个关系数据库,因此您可以轻松地对数据建模。它非常容易设置,并且具有许多集成。
阅读这篇文章,详细比较这三个引擎。
在做出决定之前,请先检查数据,从小处着手。这些新机制非常强大,但难以使用。如果您可以等待几个小时,请使用批处理和Hive或Tajo之类的数据库。然后使用Kylin加快OLAP查询并使其更具交互性。如果这还不够,并且您需要更少的延迟和实时数据,请考虑使用OLAP引擎。德鲁伊更适合实时分析。Kaileen更专注于OLAP案件。Druid与Kafka的实时流媒体集成良好。尽管计划进行实时接收,但Kylin正在从Hive或Kafka批量接收数据。
最后,Greenplum 是另一个OLAP引擎,更专注于人工智能。
数据可视化
有几种用于可视化的商业工具,例如Qlik,Looker或Tableau。
如果您喜欢开源,请看一下SuperSet。它是一个出色的工具,可支持我们提到的所有工具,具有出色的编辑器,而且速度非常快,它使用SQLAlchemy为许多数据库提供支持。
其他有趣的工具是Metabase或Falcon。
结论
从灵活的查询引擎(如Presto)到高性能存储(如Kylin),可以使用多种工具来处理数据。没有万能的解决方案,我建议您研究数据并从小做起。查询引擎因其灵活性而成为一个很好的起点。然后,对于不同的用例,您可能需要添加其他工具以达到所需的服务级别。
要特别注意像Druid或Pinot这样的新工具,它们提供了一种以极低的延迟来分析大量数据的简便方法,从而在性能方面弥合了OLTP和OLAP之间的鸿沟。您可能很想考虑处理,预先计算聚合之类的问题,但是如果您想简化工作,请考虑使用这些工具。