
你好!
我叫Nikita,负责DomClick几个项目的开发。今天,我想在RabbitMQ世界中继续“有趣的图片”主题。阿列克谢·卡扎科夫( Alexey Kazakov)在他的文章中考虑了诸如延迟队列和重试策略的不同实现之类的强大工具。今天我们将讨论如何使用RabbitMQ安排定期任务。
为什么我们需要创建自己的自行车,为什么我们放弃Celery和其他任务管理工具?事实是,它们不符合我们的容错任务和要求,这在我们公司中非常严格。
当切换到Docker和Kubernetes时,许多开发人员都面临组织定期任务的问题,用铃鼓来启动王冠,并且对过程的控制还有很多不足之处。然后在白天出现高峰负荷问题。
我的任务是在项目中实现一个可靠的系统来处理定期任务,同时又易于扩展和容错。我们的项目使用Python,因此看Celery如何适合我们是合乎逻辑的。这是一个很好的工具,但是使用它我们经常遇到可靠性,可伸缩性和无缝发布问题。一个吊舱-一个过程组。扩展Celery时,您必须增加一个Pod的资源,因为Pod之间没有同步,这意味着尽管暂时停止了任务的处理。而且,如果任务也是长期的,那么您已经猜到了管理的难度。第二个明显的缺点:开箱即用,不支持异步,但是对我们来说这很重要,因为任务主要包含I / O操作,而Celery在线程上运行。
当时(2018年),我们没有找到合适的现成工具,因此开始开发自己的工具。以延迟执行任务和死信交换的功能为基础,我们决定创建一个用于处理周期性任务的系统。这个概念看起来像这样:
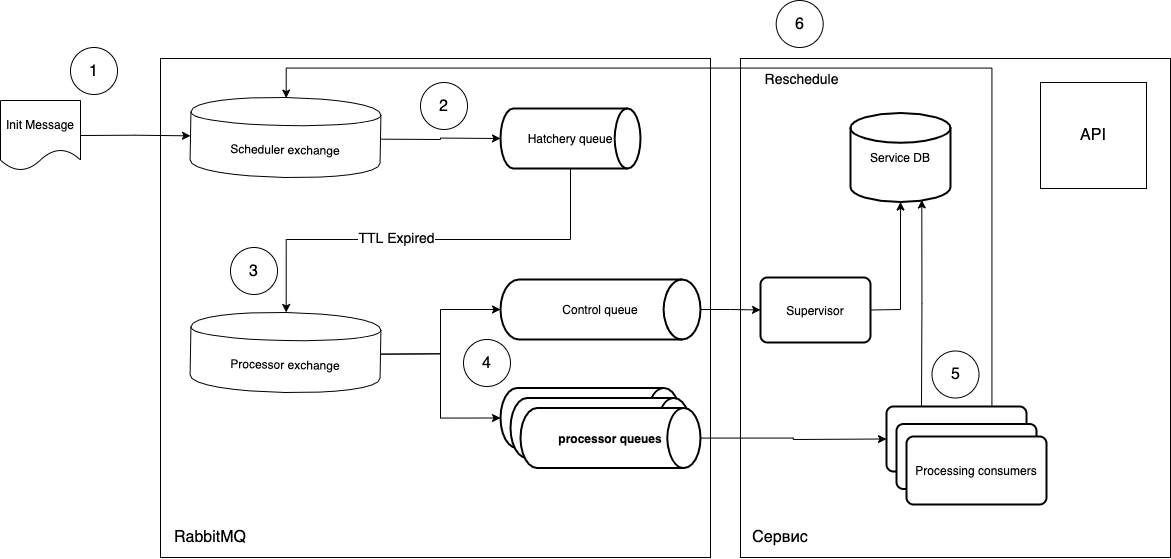
我将尽力解释什么是什么。
- 任务作为消息发送到调度程序交换。
- 该
routing_key软件进入所需的Hatchery队列,该队列具有一个参数message_ttl,以及与作为交易信交换的Processor交换的连接。“到期”队列与任务类型无关,它仅充当“计时器”的角色,也就是说,您可以根据需要创建任意数量的队列并进行管理routing_key。 - 由于队列中没有侦听器,因此队列中“成熟”之后的消息将进入处理器交换。
- 然后,自由使用者(正在处理的使用者)接收消息并执行。执行后,如有必要,重复该循环。
这样的计划有什么好处?
- 分阶段执行,即如果前一个任务尚未完成,则不会处理新任务。
- 单个侦听器(消费者),即可以创建通用工作程序和专用工作程序。只需增加所需豆荚的数量即可进行扩展。
- 在不中断当前任务的情况下部署新任务。轻柔地更新侦听器pod并将适当的消息发送到队列就足够了。就是说,您可以使用新代码引发Pod,该新代码将处理新消息,并且当前过程将保留在旧Pod中。这为我们提供了无缝的更新。
- 在独立于堆栈的同时,您可以使用异步代码和任何基础结构。
- 您可以在本机
ack/级别控制任务的执行reject,还可以获得一个附加的可选队列(控制队列),该队列可以跟踪任务的生命周期。
电路实际上非常简单,我们迅速创建了一个工作原型。而且代码很漂亮。用控制消息生命周期的简单装饰器标记回调函数就足够了。
def rmq_scheduler(routing_key_for_delay_queue, routing_key_for_processing_queue):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
log_error(e)
redelivered_count = get_count_of_redelivery_attempts(properties)
if redelivered_count <= 3:
await resend_msg(
channel=channel,
body=body,
properties=properties,
routing_key=routing_key_for_processing_queue)
else:
async with app.natalya_db_engine.acquire() as conn:
async with conn.begin():
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return wrapper
return decorator
现在,我们使用此方案仅执行周期性的顺序任务,但是在重要的是在特定时间开始执行任务而不将时间转移到执行本身上时,也可以使用该方案。为此,在消息到达主管后重新安排任务就足够了。
的确,此方法具有额外的管理费用。您需要了解,如果发生错误,消息将返回队列,另一个工作人员将其拾取并立即开始执行。因此,您需要根据关键程度分开错误处理,并事先考虑在出现此或该错误的情况下如何处理消息。
可能的选择:
- 该错误将自行修复(例如,这是系统错误):发送
noack并重复错误处理。 - 业务逻辑错误:您需要中断发送周期
ack。 - 来自第1点的错误屡屡发生:我们毒死并发
reject信号给开发人员。这里有选项。您可以为要存入的消息创建交易信队列,以便在解析后返回消息,或者可以使用重试技术(请指定message_ttl)。
装饰器示例:
def auto_ack_or_nack(log_message):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
await channel.basic_client_nack(envelope.delivery_tag, requeue=False)
log_error(log_message, exception=e)
return wrapper
return decorator
该方案已经与我们合作了半年,它非常可靠,几乎不需要关注。应用程序崩溃不会破坏调度程序,只会稍微延迟任务的执行。
没有缺点就没有优点。此方案还具有严重漏洞。如果RabbitMQ出了点问题并且消息消失了,那么您需要手动查看丢失的内容并重新开始循环。但这是一种极不可能的情况,您将不得不最后考虑此服务:)
PS如果安排定期任务的主题对您来说很有趣,那么在下一篇文章中,我将更详细地告诉您我们如何自动创建队列以及关于Supervisor。
链接: