强化学习是不好的,或者说,在高维度上根本不起作用。并且还面临着物理模拟器相当慢的问题。因此,最近,通过训练模拟物理引擎的独立神经网络,解决这些局限性的方法已变得流行。事实证明,这类似于想象力的模拟,在其中进行了进一步的基础学习。
让我们看看在这方面取得了什么进展,并看一下主要架构。
使用神经网络代替物理模拟器的想法并不是什么新鲜事,因为现代CPU上的简单模拟器(例如MuJoCo或Bullet)能够提供至少100-200 FPS(更多时候是60),并且并行运行神经网络模拟器可以轻松产生2000-10000 FPS。可比的质量。的确,在10到100步的小范围内,但是对于强化学习而言,这通常就足够了。
但更重要的是,训练神经网络以模仿物理引擎的过程通常涉及降维。由于训练这种神经网络的最简单方法是使用自动编码器,因此它会自动发生。
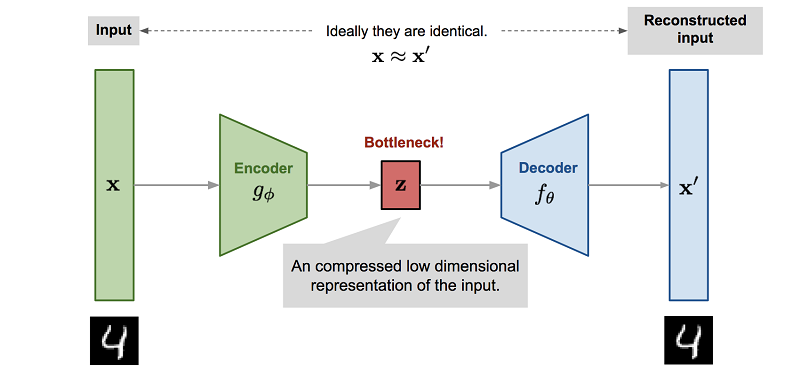
, , . , . - , , , , Z.
Z Reinforcement Learning. , , ( , , ). , .
, — , , . . , Z , model-based , , .
, Reinforcement Learning. "" : , , , .
World Models
( ), 2018 World Models.
: - "" , Z. ( ).
VAE:
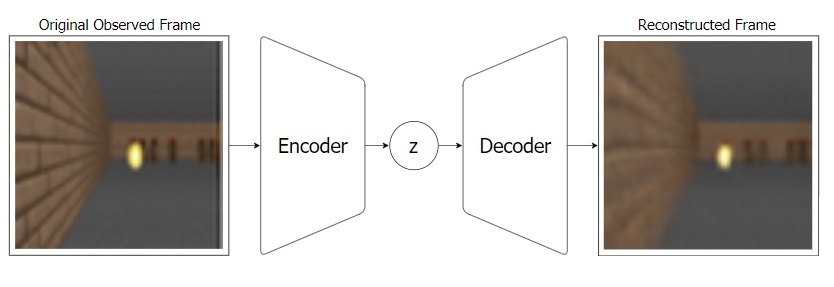
, VAE ( MDN-RNN), . VAE , . , RNN Z . .
:

, : VAE(V) Z MDN-RNN(M) . Z, . MDN-RNN , Z , .
, "" ( - MDN-RNN), . ( ), .
, "" (. ) MDN-RNN (Controller — "", ). , , environment. , C , . VAE(V).
Controller ©, ? ! , -"", Controller. , . , CMA-ES. , Z , . . , , , .
, , .
PlaNet
PlaNet. (, , Controller reinforcement learning), PlaNet Model-Based .
, Model-Based RL — . . , . , , RL , .
Model-Based , , , . (CEM PDDM).
- , ! , .
, . , . .
, . . . (.. state, Reinforcement Learning) , , . Model-Based .
PlaNet, World Models , , Z ( S — state).

Z (, S) , , . , - .
S (, Z) . , , . , .
S , . Model-Based ( ""). .
, , .. -"", A. Model-Based — . , state S . R , state S , ( ). , , ! ( ). Model-Based , .. , , , S R. , World Models, .
Model-Based , PlaNet . 50 . , , , , Model-Free .

Model-Based , (-), . , . . , Model-Based, PlaNet . ( ), .
Dreamer
PlaNet Dreamer. .
PlaNet, Dreamer S, , . Dreamer Value , . Reinforcement Learning. . , . Model-Based ( PlaNet) .

, , Dreamer Actor , . Model-Free , actor-critic.
actor-critic Model-Free , actor , critic ( value, advantage), Dreamer actor . Model-Free .
Dreamer' , . Actor , (. ). Value , , value reward .

, Dreamer Model-Based . Model-Free. model-based ( , ) Actor . Dreamer . , PlaNet Model-Based .
, Dreamer 20 , , Model-Free . , Dreamer 20 , ( ) .

Dreamer Reinforcement Learning . MuJoCo, , .
Plan2Explore
. Reinforcement Learning , .
, - , . , - , , . , , ! Plan2Explore .
Reinforcement Learning , , . , .
, . . , -, . -, , - , .
, . , , Plan2Explore , . , .
Plan2Explore : , . , - , . . . zero-shot . ( , . World Models ), few-shot .
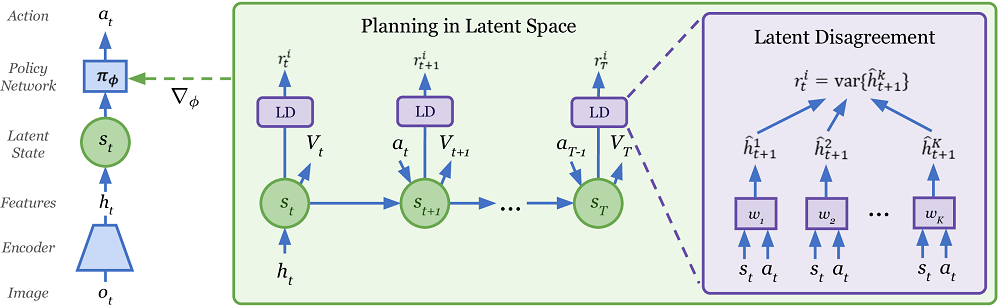
Plan2Explore , Dreamer Model-Free , , . , .
有趣的是,Plan2Explore使用一种不寻常的方式在探索世界的同时评估新地点的新颖性。为此,训练了仅在世界模型上训练并且仅预测前进的一组模型。有人认为,对于高度新颖的状态,它们的预测是不同的,但随着数据集(频繁访问该站点),即使在随机随机环境中,它们的预测也开始达成共识。由于一步一步的预测最终会在这种随机环境中收敛到一些平均值。如果您什么都不懂,那么您并不孤单。在本文中,这不是很清楚。但是它似乎可以工作。