-我将从在线电影院的来源开始。

在Internet的发展过程中,出现了OTT媒体服务,与使用电缆,卫星和其他通信渠道的传统媒体服务相反,OTT媒体服务开始用于通过Internet传输媒体内容。
此类媒体服务基于OVP(在线视频平台),该平台包括内容管理系统,Web播放器和CDN。这种系统的单独类别是OTT-TV,这是一种在线电影院,除OVP之外,它还实现了用于访问内容的控制和管理系统,数字内容版权保护系统,订阅,购买以及各种产品和技术指标的管理。而且,这些系统对正常运行时间和延迟的要求也越来越高。
我将讨论后端,该后端负责内容管理系统,在线电影院的用户功能以及内容管理和控制系统的一部分。
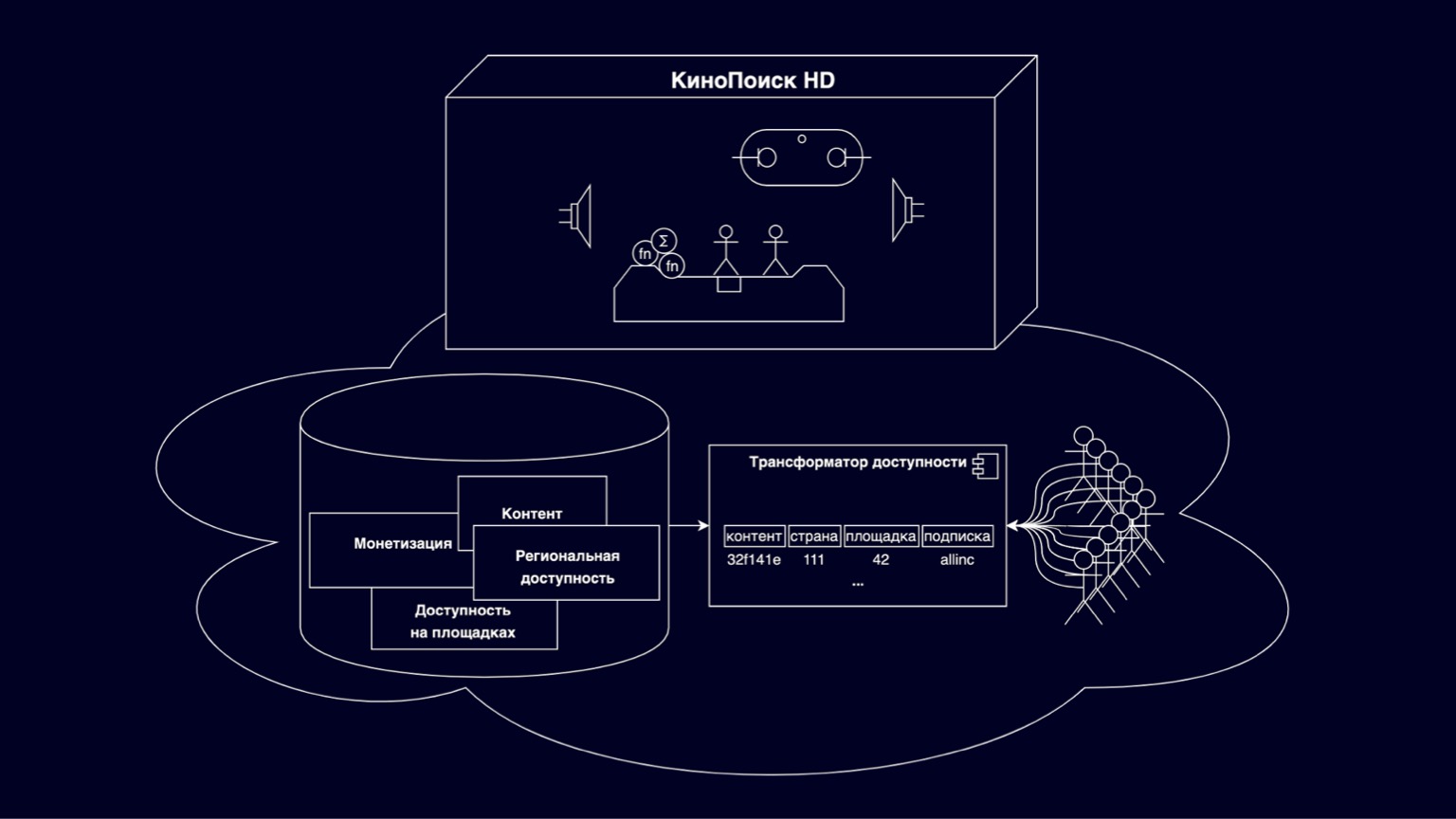
让我们看看在线电影院是由什么组成的。在KinoPoisk HD框中,实现了各种酷炫的事物和观看模式。成千上万的RPS用户在店面中选择可用内容,进行订阅和购买。保存浏览进度,用户设置。成千上万的RPS生成各种指标。这是一组相当大且有趣的组件,我们今天不再赘述。但是值得一提的是,由于它们是由用户分片的,因此通常它们是良好且可理解的可扩展服务。
今天,我们将重点关注框下的云。该平台负责存储电影,系列作品以及版权所有者的各种限制。在几个部门的努力下得到了支持。该平台的一部分是可访问性转换器,它可以回答我现在在此位置可以观看的问题。如果没有辅助功能转换器,则KinoPoisk HD上不会出现任何内容。
转换器面临的挑战是将灵活的分层可访问性模型转换为有效的模型,该模型可以很好地扩展到尽可能多的内容消费者。
为什么它具有灵活性和可扩展性?主要是因为它包括描述内容,获利,关系可用性和站点可用性的各种实体。所有这一切都处于革命关系中,具有复杂的等级制度。为了满足数十个版权持有者的需求和各种灵活的定价选项,需要这种灵活性。
对于平台,我们的意思是,例如,网络上的在线电影院,设备上的在线电影院以及其他也可以播放我们内容的合作伙伴OTT服务。
显然,要有效地计算这种多级模型的可用性,您需要构建复杂的联接,并且此类查询无法扩展到任何负载,它们的解释非常复杂,因此无法快速,清晰地构建某些功能。为了解决这些问题,出现了一个可访问性转换器,将幻灯片上显示的模型归一化为复合密钥,其中包括内容ID,国家/地区,站点,订阅以及一些不可见的非密钥残留物,这些残留物构成了内存的大部分。今天,我们将讨论扩展无障碍转换器的困难。
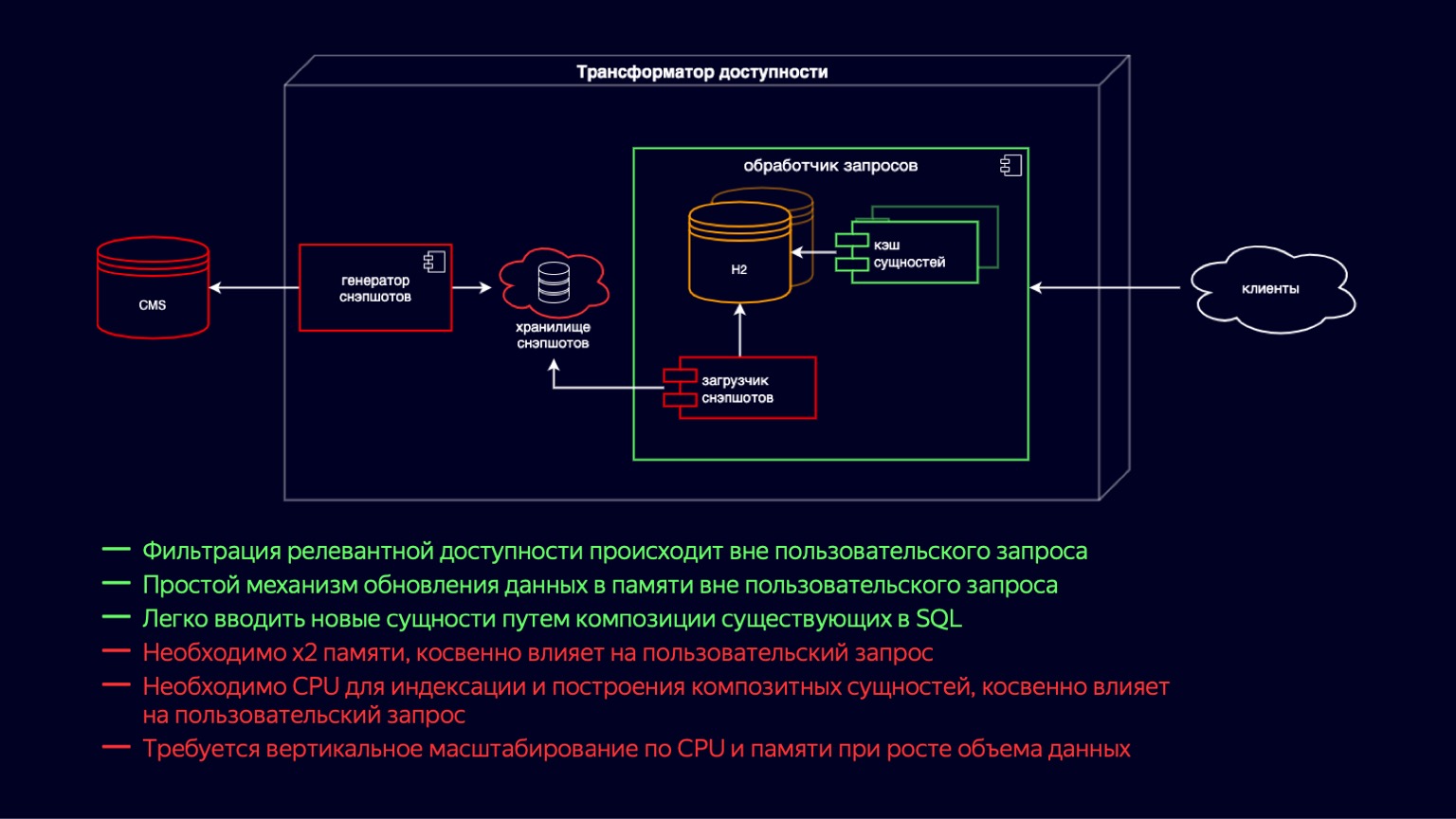
让我们更深入地研究此组件,并查看其组成。在这里,我们可以看到问题开始之前系统的状态。一直以来,可访问性变压器一直在沿着在线电影的迅猛发展之路前进。快速启动新功能非常重要,首先,要确保提供成千上万部电影和电视剧。
如果从左到右走,则有一个CMS,一个关系数据库,该数据库以第三范式和EAV形式存在我们的主要实体都已存储。接下来是快照加载器。此外,定期接收相关数据的快照生成器对其进行过滤,然后将其添加到快照存储中。这实际上是一个SQL转储。在请求处理器实例内部,快照加载程序会定期接收新数据并将其导入到H2中。 H2是用Java编写的内存数据库,实现了DBMS的基本功能,即有一个查询解释器,一个查询优化器和索引。
实际上,由于您可以轻松快速地编写SQL查询并加入非规范化实体,因此,这正是为在线电影创建新功能提供灵活性的组件。
H2在写时复制模型上更新。快照加载程序将拾取一个新的数据库实例并进行填充。然后,在填充后,它使用垃圾收集器处理旧的垃圾。
与H2同时,将提高实体缓存,其中包括复合实体及其上方的索引。复合实体本质上是H2中非规范化的延续,以适应来自客户端的更苛刻的延迟请求。使用写时复制模型以相同的方式更新高速缓存实体,同时增加新的H2实例。
该系统的主要优点:您可以使用联接轻松灵活地添加新功能。通过写时复制来更新数据的相对简单的方案。当然,不利的一面是要花费x2的内存来存储和更新这些实体。由于垃圾收集器处理了用户请求,因此间接影响了用户请求。
同样,在建立实体缓存时,需要CPU资源来建立索引。这也间接影响用户请求,但以争夺CPU资源为代价。这两个观点共同导致了这样一个事实,即随着我们主要实体的数据量的增长,查询处理器需要在CPU和内存方面进行垂直扩展。
但是,该系统依赖于在线提供的成千上万部电影和电视连续剧。因此,长期以来,这些缺点是可以接受的,它们使得可以利用灵活性和易于引入在线电影的新功能方面的主要优点。
显然,所有这些都达到了一定程度。想象一下,这辆黄色的公共汽车是我们的辅助功能变压器。

它包含通过非规范化复制的电影和连续剧,即有成千上万的电影和连续剧。在其中一站,需要将数十万个音乐视频和预告片抬起并以某种方式放置。一旦登上船,它们也会由于非规范化而繁殖。内在的人需要收缩,而外在的人则需要跳进去。您可以想象这是怎么发生的。从技术上讲,此刻,我们在实例上的内存容量已增加到数十GB。使用垃圾收集器构建缓存并处理旧实例需要几个虚拟核心。而且由于数据量急剧增长,整个过程导致了这样一个事实,即发布新内容要花费数十分钟。
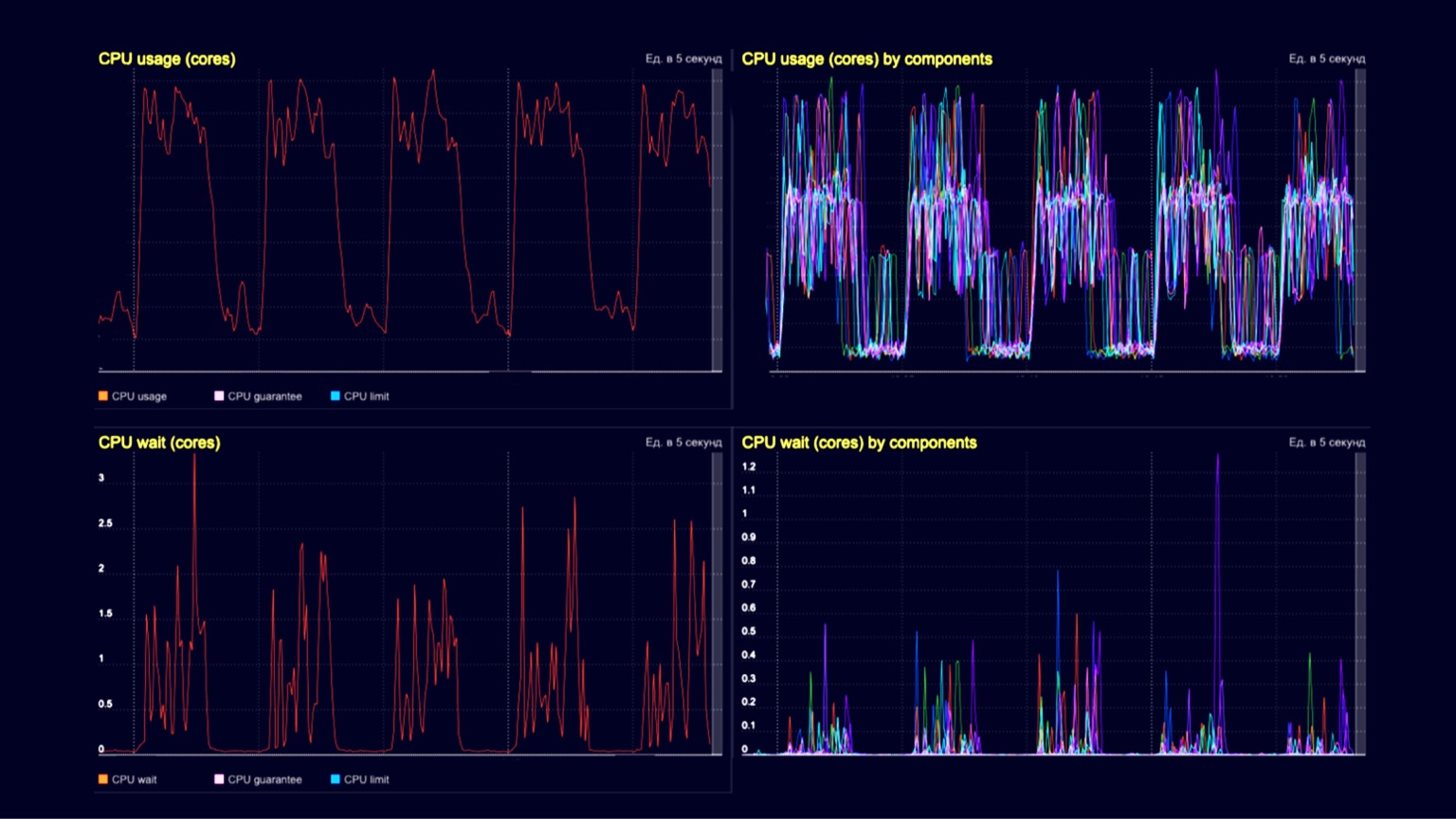
从技术上讲,我们在查询处理器群集上看到的是CPU利用率。在战-中-处理几千个RPS的客户请求,在山丘中-相同几千个RPS,再加上相同的快照加载以及使用垃圾收集器对其进行处理。最下面的两个图是容器上的CPU等待。我们看到它们在下载快照和处置时也开始显现出来。
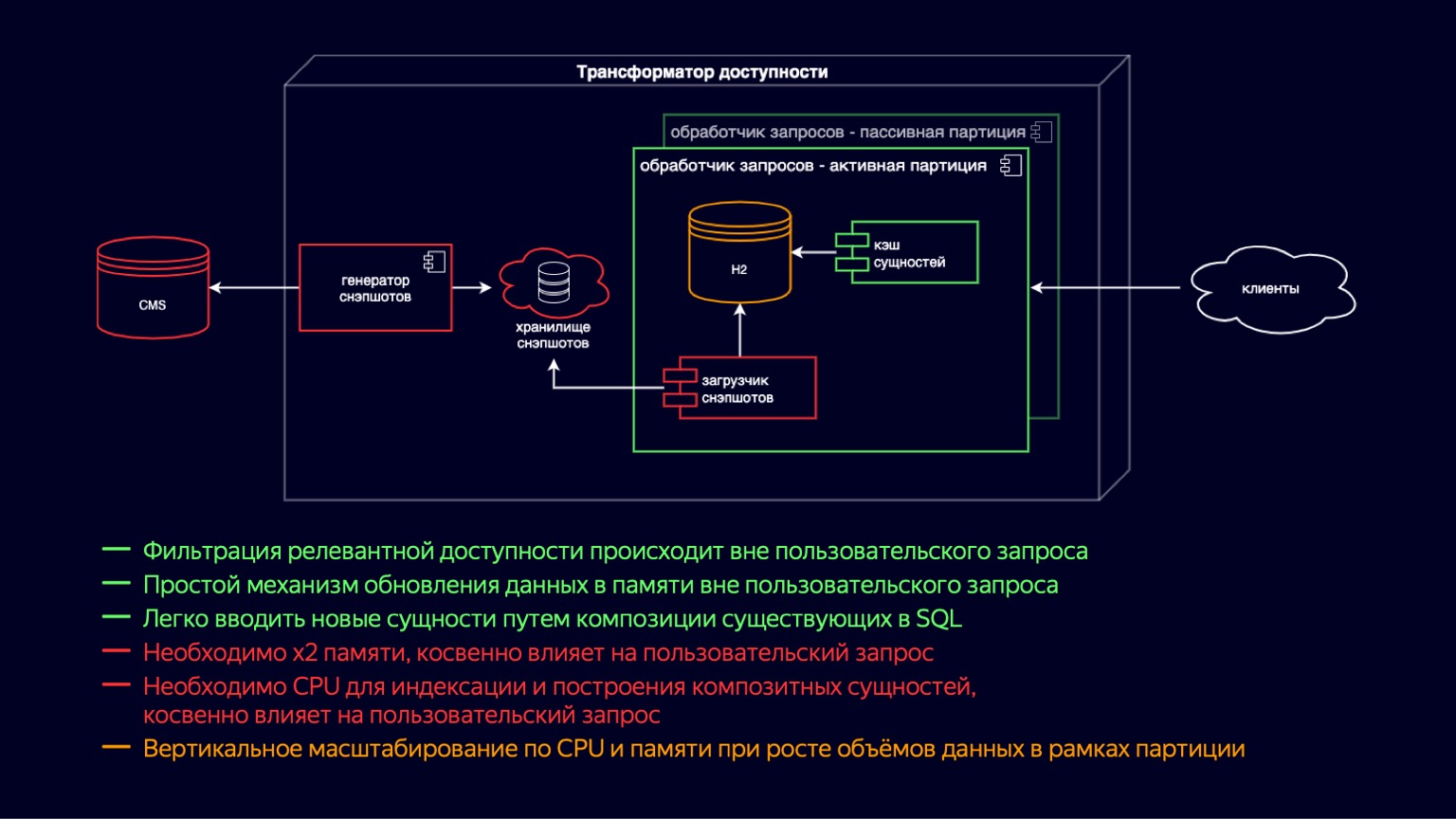
为了容纳这些音乐视频和预告片并继续扩展,我们引入了主动和被动请求处理器实例。实际上,这是一次写时复制的转移。现在,我们在容器中同时具有主动和被动实例。被动服务器准备新的H2和实体缓存,而主动服务器仅处理用户请求。因此,我们减少了垃圾回收及其暂停对用户请求处理的影响。但是同时,由于它们仍生活在同一个容器中,因此加载快照和构建缓存仍在争夺CPU资源,并且对用户请求的影响仍然存在。
我们还引入了按站点分区。这使我们减少了不需要所有这些新类型内容的站点上的内存。例如,这允许在线电影院不下载音乐视频和预告片,并减少影响。但是,与此同时,对于需要为所有内容提供可访问性的网站,没有任何变化。
因此,该计划的利弊与以前大致相同。但是由于分区,将CPU和内存方面的垂直扩展转移到了站点,这使某些站点得以继续扩展。与以前的内容发布方案相比,这没有任何改变。通常需要花费同样的数十分钟,因此我们一直在寻找优化方法。

到那时我们了解了什么?在线电影查询仅使用DBMS功能的一小部分。随着时间的推移,查询解释器和优化器已退化到实体缓存中。我们意识到对可访问性的定义是普遍的。查询的不同之处在于,您需要了解内容单元或列表的可用性,并为此可用性添加其他属性。通常,这可以在没有成熟的DBMS的情况下完成。
其次,组合键的一部分是低基数参数。有几十个国家/地区,最多只能有数百个站点,而且订阅数很少。最有可能的是,不需要完全的非规范化。这两个发现促使我们朝着更紧凑,更规范化的内存中表示迈进,但是它仍然可以快速响应用户请求。

在幻灯片上,我们看到了从可用性转换器v1到v2的过渡。这是新的可访问性方案的示意图,其中组合键实际上可以归结为只是一个内容ID密钥。可访问性从物理上或逻辑上归结为根据国家,站点和订阅列表确定可用性。
因此,我们减少了构成存储器大部分的不可见的非关键剩余量,并且同时减少了内存量。
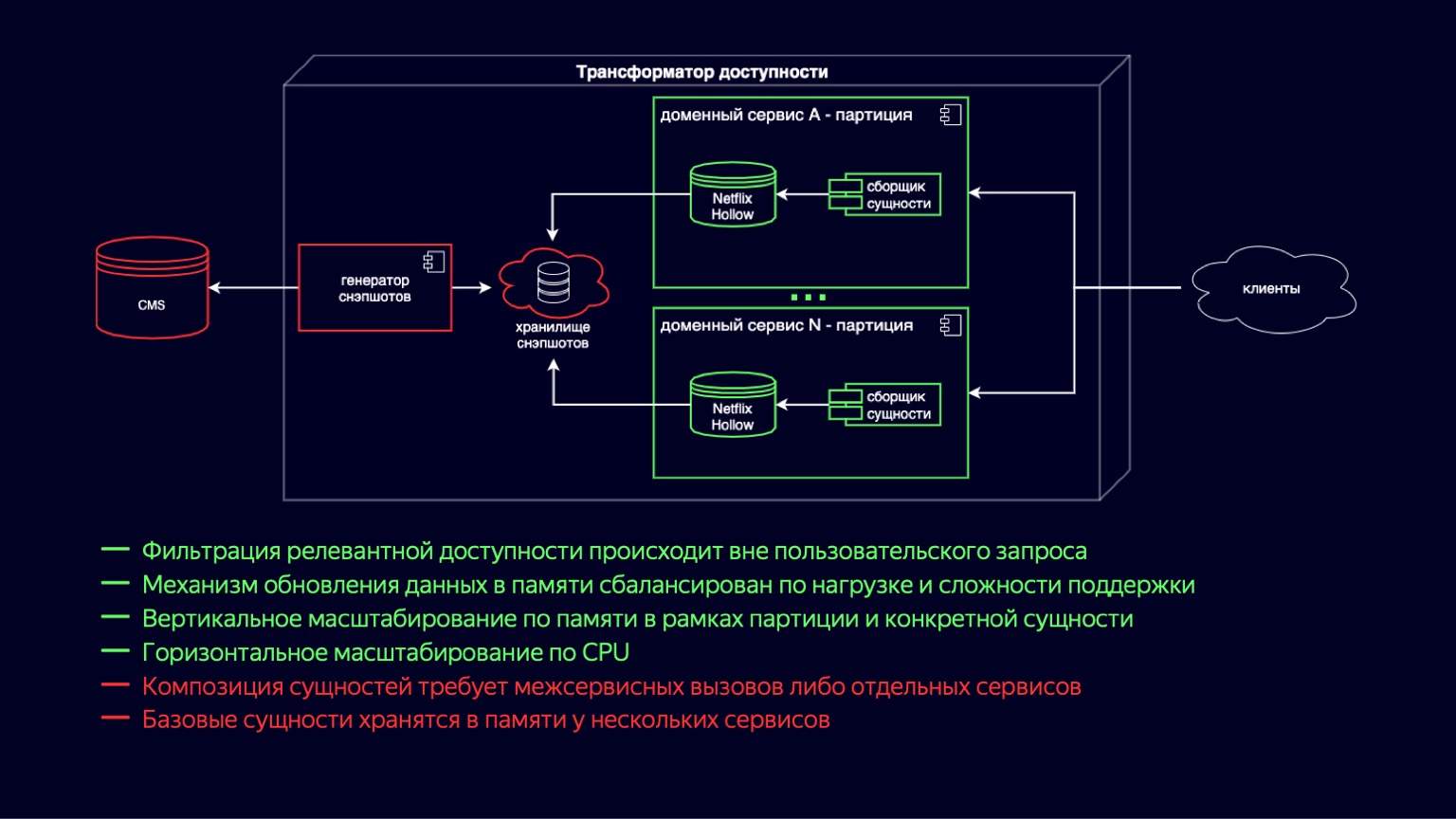
在这里,我们看到了过渡到新的辅助功能变压器电路的过程。 Netflix Hollow扮演着基本实体的提供者和索引者的角色,在该基础上,域服务会即时收集各种大小的复合实体的集合。之所以可行,是因为基础实体仍处于非规范化状态,并且在构建时联接的数量最少。另一方面,确定可用性可归结为简单而廉价的周期,应该不难。
同时,Netflix Hollow在数据更新和访问它们的过程中会存储并相当谨慎地处理CPU和垃圾收集上的负载。这使我们能够减少在CPU利用率图中看到的峰值,并将其保持在可接受的最小值。此外,由于它以快照和差异形式实施混合交付方案,因此可以将发布新内容的速度提高到几分钟。
显然,先前方案的大多数优点已保留。就资源利用率而言,用于更新内存中数据的机制变得更加简单和便宜。按分区,按站点的垂直扩展还补充了针对特定实体的扩展,现在更便宜了。而且,由于我们减少了更新Snapshot副本的开销,因此在CPU上实现了真正的水平扩展。
该方案的缺点是实体组成需要服务间调用或单独的服务。而且,由于现在将数据存储在使用它的每个域服务中,因此在基本实体级别仍然存在重复数据。但是Netflix Hollow比H2更加紧凑地存储数据,并且H2比带有对象的HashMap更加紧凑地存储数据。因此,这个负数也绝对可以接受,并且可以让您乐观地展望未来。

这张幻灯片甚至可以使自来水充盈。因为扩展到新的国家/地区不再是存储的倍增因素-扩展到新的站点也不再是。由于分区,它将转换为水平缩放。
好吧,新用户的扩展和在线电影功能的扩展归结为负载的增加。为了提供它,我们准备根据需要提供尽可能多的轻量级CPU绑定服务。另一方面,我们在可访问性领域积累了足够的知识,充满信心地期待新的挑战。希望我能够与您分享一些知识。感谢您的关注。