
在本文中,我将解释:
- 这种气流是什么样的野兽,它由什么组成,以及它们如何相互作用
- 关于气流的主要实体:称为DAG的管道,操作员等
- 如何在气流方面取得成功
- 我们如何实现管道的生成以及所谓的“管道的声明式编写”
- 关于使用Airflow的优缺点
什么是气流
气流是用于创建,监控和协调管道的平台。这个用Python编写的开源项目于2014年在Airbnb上创建。在2016年,Airflow进入了Apache软件基金会的领导之下,经过了一个孵化器,并在2019年初成为Apache的顶级项目。
在数据处理领域,有人将其称为ETL工具,但这并不是经典意义上的ETL,例如Pentaho,Informatica PowerCenter,Talend等。Airflow是一个协调器,一个“电池驱动的cron”:它不会做繁重的数据传输和处理工作,而是告诉其他系统和框架要做什么,并监视执行状态。我们主要使用它在Hive或Spark作业中运行查询。
扰流板
Airflow, worker ( ), . , , .
通过Airflow解决的任务范围不仅限于在Hadoop集群中运行。它可以运行Python代码,执行Bash命令,在Kubernetes中托管Docker容器和Pod,针对您喜欢的数据库执行查询等等。
气流架构
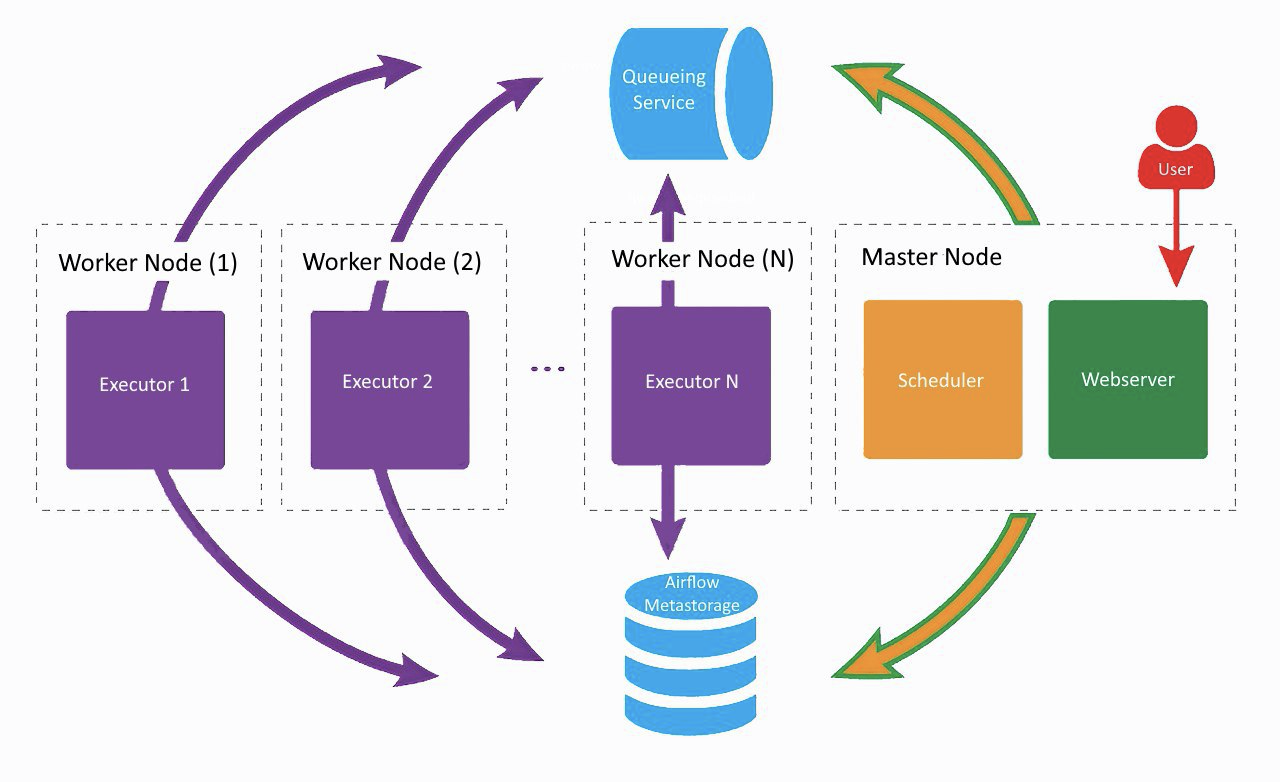
这大致就是我们当前的Airflow设置,只有Lamoda使用两名工人。在单独的机器上,Web服务器和调度程序正在旋转,而工作人员则在相邻的服务器上喘气。一种用于常规任务,另一种用于使用Vowpal Wabbit运行ML模型训练。所有组件都通过任务队列和元数据库相互通信。
在公司进行Airflow开发的初期,所有组件(数据库除外)都在同一台机器上工作,但是在某些时候,这导致服务器上资源不足,并延迟了调度程序的运行。因此,我们决定将服务分发到不同的服务器,并得出上图所示的体系结构。
气流组件
Web服务器
Web服务器是显示的是与管道发生的网络接口。用户
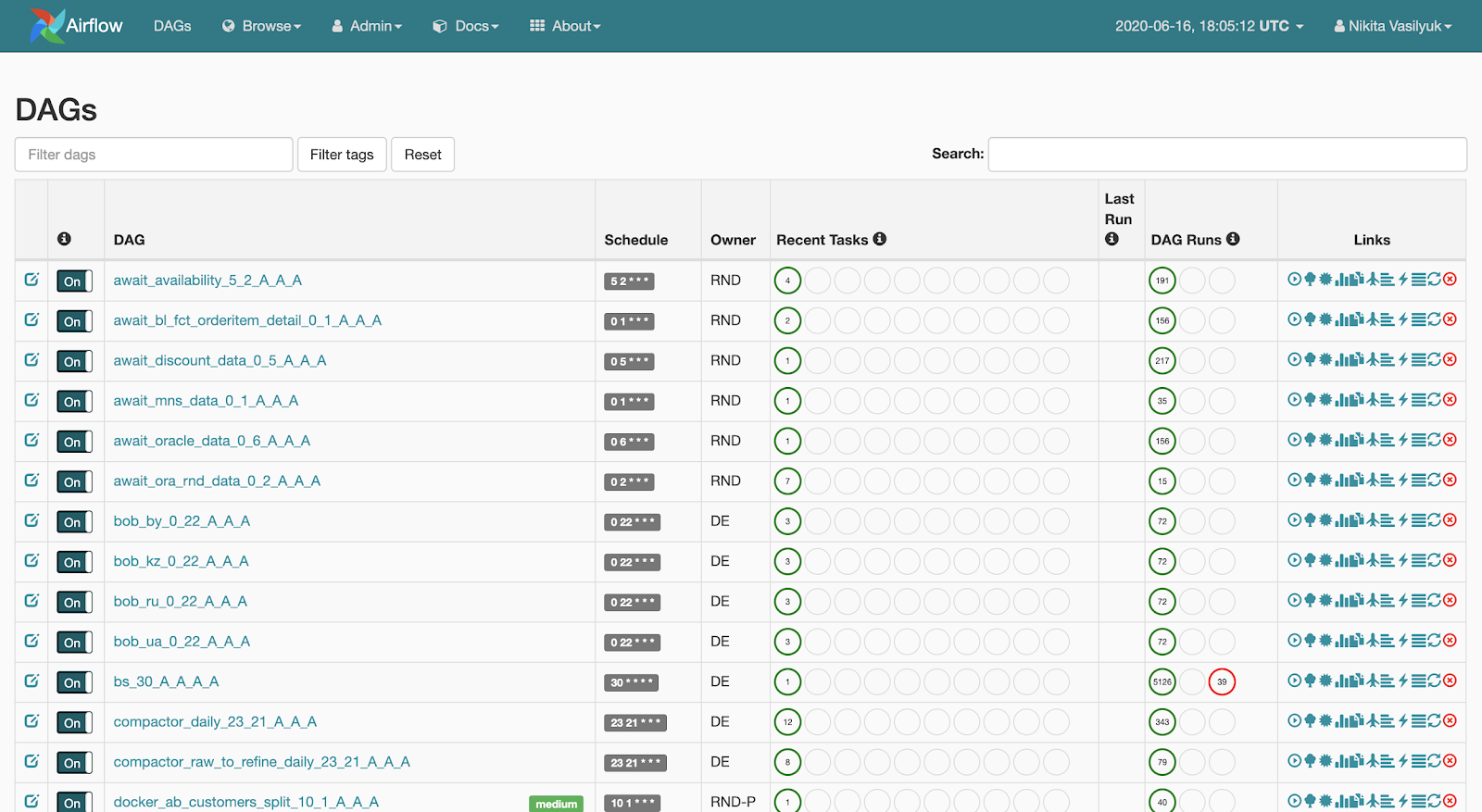
可以看到此页面:Web服务器使查看可用管道列表成为可能。启动的简要统计信息显示在每个管道的旁边。还有几个按钮可以强制启动管道或显示详细信息:启动统计信息,管道的源代码,以图形或表格形式显示的可视化,任务列表以及启动历史。
如果单击管道,将进入“图形视图”菜单。任务和它们之间的链接显示在此处。
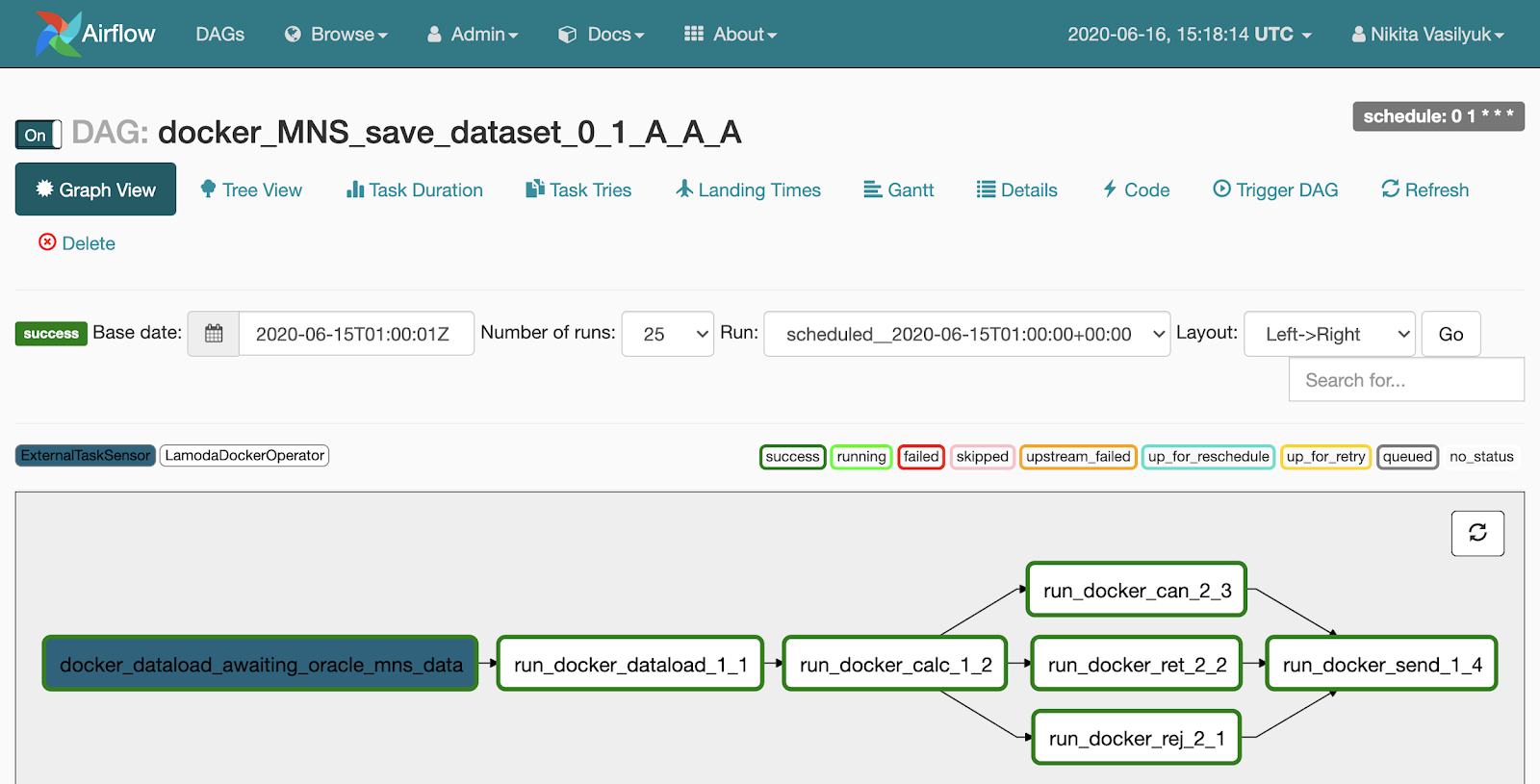
图视图旁边有一个树视图菜单。创建它是为了重新启动任务,查看统计信息和日志。图的树状视图显示在左侧,它的对面是带有任务启动历史记录的表。
该可怕表的每一行都是一项任务,每一列都是管道的起点。在他们的交汇处有一个广场,在特定日期启动了特定任务。如果单击它,将显示一个菜单,您可以在其中查看此任务的详细信息和日志,启动或重新启动它,也可以将其标记为成功或不成功。

调度程序-顾名思义,在时间到时启动管道。这是一个Python进程,它定期使用管道进入目录,从那里获取当前状态,检查状态,然后启动它。通常,Scheduler是最有趣的,同时也是Airflow体系结构的瓶颈。
- 第一个警告是一次只能运行一个Scheduler实例。这意味着目前无法在高可用性中进行操作(开发人员计划将Scheduler HA添加到Airflow 2.0版中)。
- : , - . , - , .
在一段时间之前,该延迟会通过Airflow配置文件的参数进行调整,但启动滞后仍然存在。因此,Airflow与实时数据处理无关。如果您疏忽大意,并指定了过于频繁的启动间隔(每两分钟一次),则可能会延迟管道。经验表明,已经非常频繁地每5分钟运行一次,有些建议不要每10分钟运行一次管道。我们有几个每10分钟启动一次的管道,它们非常简单,到目前为止还没有问题。
工作者
工作者是我们的代码运行和任务完成的地方。Airflow支持多种执行器:
- 第一个,最简单的是SequentialExecutor。它顺序启动进入的任务,并在执行期间暂停计划程序。
- LocalExecutor , , LocalExecutor . : - SQLite, LocalExecutor SequentialExecutor.
- CeleryExecutor , . Celery – , RabbitMQ Redis. , .
- DaskExecutor Dask – .
- KubernetesExecutor pod Kubernetes.
- DebugExecutor IDE.
Apache Airflow实体
管道或DAG
气流的最重要本质是DAG,又名管道,又名有向无环图。为了更清楚地说明如何烹饪以及为什么需要它,我将分析一个小例子。
假设有一位分析师来找我们,要求我们每天一次将数据填写到某个表中。他准备了所有信息:从哪里获得什么,何时开始以及以什么SLA。这是一个如何描述管道的示例。
dag = DAG(
dag_id="load_some_data",
schedule_interval="0 1 * * *",
default_args={
"start_date": datetime(2020, 4, 20),
"owner": "DE",
"depends_on_past": False,
"sla": timedelta(minutes=45),
"email": "<your_email_here>",
"email_on_failure": True,
"retries": 2,
"retry_delay": timedelta(minutes=5)
}
)
dag_id包含管道的唯一名称。接下来,我们使用schedule_interval来指定它应该运行的频率。
非常重要的一点:由于Airflow是由一家国际公司开发的,因此只能在UTC上使用。目前,没有使Airflow在不同时区工作的明智方法,因此您需要不断记住我们的时区与UTC之间的时差。在1.10.10版本中,可以更改UI中的时区,但这仅适用于Web界面,管道仍将以UTC运行。
default_args参数是一个字典,它描述此管道中所有任务的默认参数。大多数参数的名称都很好地描述了自己,我不再赘述。
操作员
运算符是一个Python类,描述了在我们的日常任务中需要执行哪些操作才能使分析师满意。
我们可以使用HiveOperator,这很奇怪,它旨在将执行请求发送到Hive。要启动操作员,您需要指定任务名称,管道,与Hive的连接ID和正在执行的请求。
run_sql = HiveOperator(
dag=dag,
task_id="run_sql",
hive_cli_conn_id="hive",
hql="""
INSERT OVERWRITE TABLE some_table
SELECT * FROM other_table t1
JOIN another_table t2 on ...
WHERE other_table.dt = '{{ ds }}'
"""
)
notify = SlackAPIPostOperator(
dag=dag,
task_id="notify_slack",
slack_conn_id="slack",
token=token,
channel="airflow_alerts",
text="Guys, I'm done for {{ ds }}"
)
run_sql >> notify
请求中有一块Jinja模板,我们将其传递给运算符的构造函数。 Jinja是一个Python模板库。
每个管道启动都存储有关启动日期的信息。它位于一个名为execution_date的变量中。 {{ds}}是一个宏,它将仅以%% Y-%m-%d格式的日期作为日期。在启动操作员之前的某个时刻,Airflow将呈现查询字符串,在其中替换所需的日期,然后发送执行请求。
ds不是唯一的宏,大约有20个(所有可用宏的列表)。它们包括不同的日期格式和一些用于处理日期的功能-增加或减少几天。
当我熟悉Airflow时,我不明白为什么需要各种宏,而您只需要插入datetime.now()即可在那里享受生活。但是在某些情况下,这可能极大地破坏我们和分析师的生命。例如,如果我们想重新计算过去某个日期的值,则Airflow将代替管道启动的日期,而不是实际的执行时间。在某些情况下,我们可能无法达到期望。
例如,如果我们要在上周二重新启动管道,那么在使用datetime.now()时,我们实际上将重新计算今天(而不是所需日期)的管道。另外,今天的数据可能甚至还没有准备好。
成功完成请求后,我们可以向Slack发送有关加载数据的通知。接下来,我们命令Airflow,以启动任务的顺序。由于Airflow中的运算符重载,我可以轻松地使用>>运算符来指定管道中步骤的顺序。在我的示例中,我们说我们将首先开始执行请求,然后将通知发送到slack。
幂等
不谈幂等就不可能谈论气流。以防万一,让我提醒您:幂等是对象的属性,当您对对象重新执行操作时,总是返回相同的结果。
在Airflow的上下文中,这意味着如果今天是星期五,并且我们在上周二重新启动任务,则该任务将像上周二一样开始,仅此而已。也就是说,过去某个日期任务的启动或重新启动不应以任何方式取决于该任务的实际启动时间。幂等性使用上述的execute_date变量实现。
气流被开发为解决数据处理任务的工具。在这个世界上,我们通常仅在准备就绪时(即第二天)才处理大量数据。而Airflow的创造者最初在其产品中提出了这样的概念。
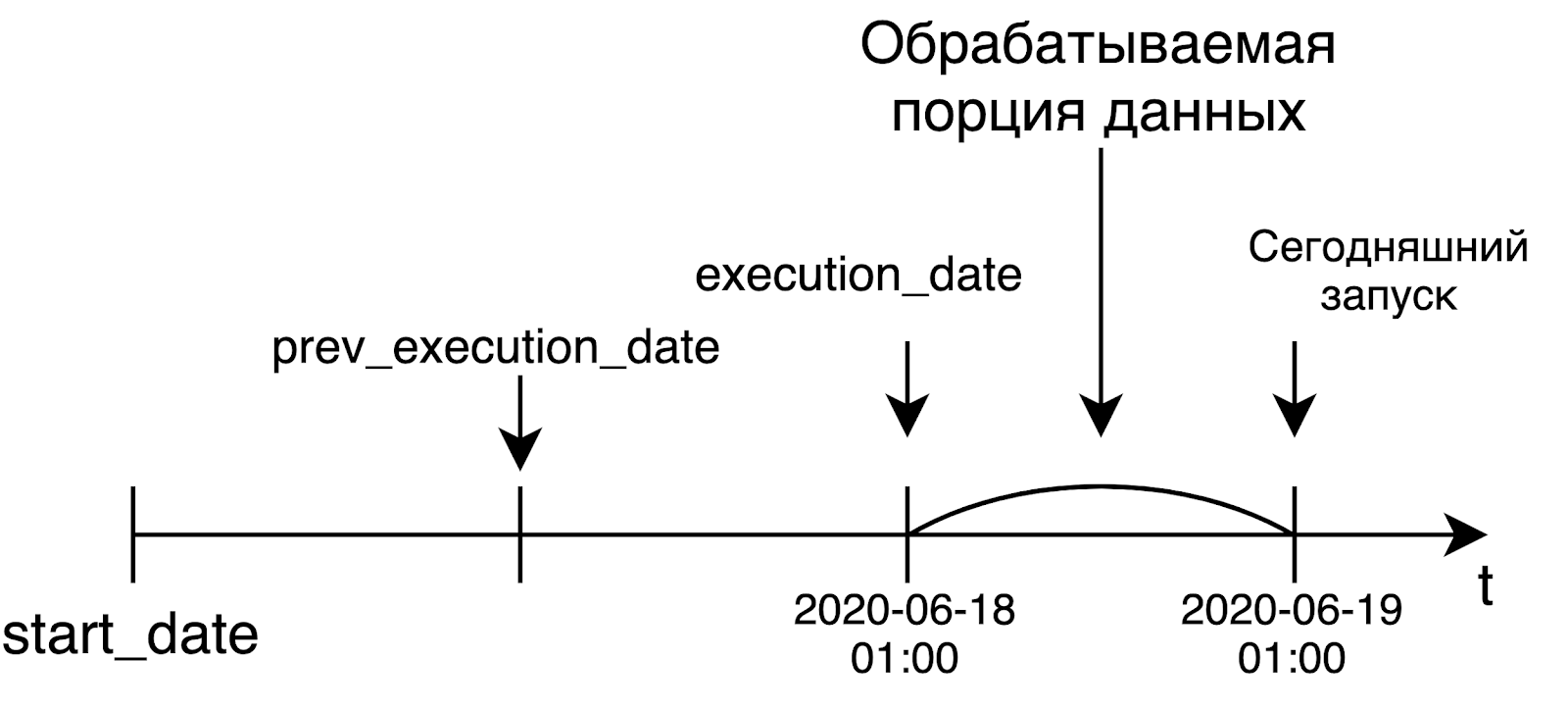
当我们启动每日管道时,我们很可能希望处理昨天的数据。这就是为什么execution_date等于我们处理数据的时间间隔的左边界。例如,今天的发射从世界标准时间凌晨1点开始,将以昨天的日期作为execute_date。对于每小时一次的管道,情况是一样的:要在上午6点启动管道,execution_date中的时间将等于上午5点。起初,这个想法不是很明显,但是它非常有意义和重要。
最常见的气流操作员
在Airflow中,不仅有运营商去Hive并发送一些闲暇。实际上,那里有大量的运营商。在本文中,我介绍了最受欢迎和最有用的。
- BashOpetator和PythonOperator。他们的一切都清楚了:他们分别发送了bash命令和python函数来执行。
- 各种各样的运算符可用于向各种数据库提交查询。支持标准Postgres,MySQL,Oracle,Hive,Presto。如果由于某种原因,您最喜欢的数据库没有运算符,则可以使用更通用的JdbcOperator或编写自己的运算符,Airflow允许这样做。
- Sensor – , . , - . , , . , : 3 , . . , , .
- BranchPythonOperator – , , python , , .
- DockerOpetator Docker- . , Docker- , . , .
- KubernetesPodOperator pod Kubernetes.
- DummyOperator , .
Lamoda
- – LamodaDockerOperator. , : - Hadoop, . LamodaDockerOperator Spark- , python.
- LamodaHiveperator – , . Hive. , - , , . , , HiveCliHook HiveServer2Hook, .
- – ExternalTaskSensor. . , Hadoop . , , , - , , . , - HDFS, Airflow.
- BashOperator, PythonOperator – , bash- python .
- , . - , .
Airflow
- Variables – , , , . , . , Hive, HDFS, . dev- prod-, .
- Connections – , . Airflow : http ftp, .
- Hooks – , .
- SLA -. , . SLA , , - - . - : - , Airflow .
- – XCom, cross-communication. : , json-. – 48 .
- – , . , . , 5, , , , .

此外,您可以看到任务的持续时间在一天中如何变化。在我们的案例中,这是通过数据质量验证将数据从Kafka传输到Hive的过程。另外,您可以跟踪由于某种原因该任务花费的时间比平时更长。

如何成功进行气流开发
以下是一些技巧,可帮助您避免在使用Airflow时脚部受伤:
- 将每个管道(或管道生成器,更多内容在下面)保存在单独的文件中很有用。我立即知道需要查看哪个文件才能查看所需的管道或生成器。
- , , . , -, . , - , . : , , .
- – schedule_interval start_date dag_id. , Airflow , - -. DAGS , Scheduler, . , , dag_id. , .
- catchup. True, Airflow , start_date . , . False Airflow . , Airflow True ( -).
- – . , python , airflow DAG, , DAG. . , , . REST API, requests.get() .
:
自从开始使用Airflow以来,我们一直将管道配置与代码分开。最初,这是由于部署方案的特殊性所致,但逐渐地,这种方法扎根了。现在,只要有样板提示,我们就使用配置。这尤其涉及我们从Docker运行的Spark作业。随之而来的是声明式管道的故事。
方法是我们有一个包含配置的目录。每个配置文件包含一个或几个管道及其说明:它们应如何工作,何时启动,其中包含哪些任务以及应以什么顺序执行。
我将展示调用管道生成器的代码是什么样的。在入口处,他收到一个带有配置的目录,一个前缀和一个类,该类将负责将任务填充到管道中。在后台,生成器转到指定的目录,在该目录中找到配置文件,并在这些文件中为每个管道创建任务并将其连接。
from libs.dag_from_config.dag_generator import DagGenerator
from libs.runners.docker_runner import DockerRunner
generator = DagGenerator(config_dir='dag_configs/docker_runner', prefix='docker')
dags = generator.generate(task_runner=DockerRunner)
for dag in dags:
globals()[dag.dag_id] = dag #
这就是典型的配置文件。为了描述配置,我们使用HOCON格式,它是JSON的超集。它支持导入其他HOCON文件,并可以引用其他变量的值。
在管道级别的配置(归因块)中,您可以指定许多参数,但最重要的是名称,start_date和schedule_interval。
docker_image = "docker_registry/attribution/calculation:1.1.0"
dags {
attribution {
owner = "RND"
name = "attribution"
start_date = "20190601"
emails = [...]
schedule_interval = "0 1 * * *"
depends_on_past = true
concurrency = 4
description = """
- z_log
-
- ,
-
"""
tags = ["critical"]
您可以在此处指定并发性-一次运行将同时运行多少个任务。最近,我们在此处添加了一个带有简短降价描述的块。然后,它将连同有关管道的其余信息一起转到Confluence(我们使用Foliant实现了发送)。事实证明,这非常方便:这样,我们可以为挖掘的开发人员节省在Confluence中创建页面的时间。
接下来是负责任务形成的部分。首先,在连接块中,我们指示需要从Airflow中的哪个连接获取用于连接到外部源的参数-在示例中,这是我们的DWH。
docker {
connections {
LMD_DWH = "dwh"
}
containers {
desktop {
image = ${docker_image}
connections = [LMD_DWH]
environment {
LMD_YARN_QUEUE = "{{ var.value.YARN_QUEUE }}"
LMD_INSTANCES = 60
LMD_MEMORY_PER_INSTANCE = "4g"
LMD_ZLOG_SOURCE = "z_log_db.z_log"
LMD_ATTRIBUTION_TABLE = "{{ var.value.HIVE_DB_DERIVATIVES }}.z_log_attribution"
LMD_ORDERS_TABLE = "rocket_dwh_bl.fct_orderitem_detail"
LMD_PLATFORMS = "desktop"
LMD_RUN_DATE = "{{ ds_nodash }}"
}
}
mobile {...}
iOS {...}
Android {...}
}
tasks = [[desktop, mobile, iOS, Android]]
}
所有必要的信息(例如用户,密码,URL等)将作为环境变量转发到docker容器。在“容器”块中,我们指示要启动的任务。里面有图像的名称,使用的连接列表和环境变量列表。
您可能会注意到Jinja模板出现在某些环境变量的值中。要在YARN中指定队列,我们使用标准的Airflow语法检索变量值。为了指示启动日期,我们使用{{ds_nodash}}宏,该宏表示其执行日期的日期,不带连字符。该配置包含另外3个相似的任务,为清晰起见,它们被隐藏。
接下来,我们使用任务指示如何启动这些任务。您会注意到它们在列表中被列为列表。这意味着所有这四个任务将彼此并行运行。
最后一件事:我们指定当前DAG依赖哪个基本管道。基本dag名称末尾的奇怪数字和字母是我们嵌入管道名称中的时间表。因此,仅在基本dag和其中指定的任务完成后,我们的管道才会开始填充。
awaits {
z_log_compaction {
dag = "compactor_daily_23_21_A_A_A"
task = "compact_z_log_db_z_log"
timedelta = 3hr37m
}
oracle_bl_fct_orderitem_detail {
dag = "await_bl_fct_orderitem_detail_0_1_A_A_A"
}
}
}
}
配置文件的全文
docker_image = "docker_registry/attribution/calculation:1.1.0"
dags {
attribution {
owner = "RND"
name = "attribution"
start_date = "20190601"
emails = [...]
schedule_interval = "0 1 * * *"
depends_on_past = true
concurrency = 4
description = """
- z_log
-
- ,
-
"""
tags = ["critical"]
docker {
connections {
LMD_DWH = "dwh"
}
containers {
desktop {
image = ${docker_image}
connections = [LMD_DWH]
environment {
LMD_YARN_QUEUE = "{{ var.value.YARN_QUEUE }}"
LMD_INSTANCES = 60
LMD_MEMORY_PER_INSTANCE = "4g"
LMD_ZLOG_SOURCE = "z_log_db.z_log"
LMD_ATTRIBUTION_TABLE = "{{ var.value.HIVE_DB_DERIVATIVES }}.z_log_attribution"
LMD_ORDERS_TABLE = "rocket_dwh_bl.fct_orderitem_detail"
LMD_PLATFORMS = "desktop"
LMD_RUN_DATE = "{{ ds_nodash }}"
}
}
mobile {...}
iOS {...}
Android {...}
}
tasks = [[desktop, mobile, iOS, Android]]
}
awaits {
z_log_compaction {
dag = "compactor_daily_23_21_A_A_A"
task = "compact_z_log_db_z_log"
timedelta = 3hr37m
}
oracle_bl_fct_orderitem_detail {
dag = "await_bl_fct_orderitem_detail_0_1_A_A_A"
}
}
}
}
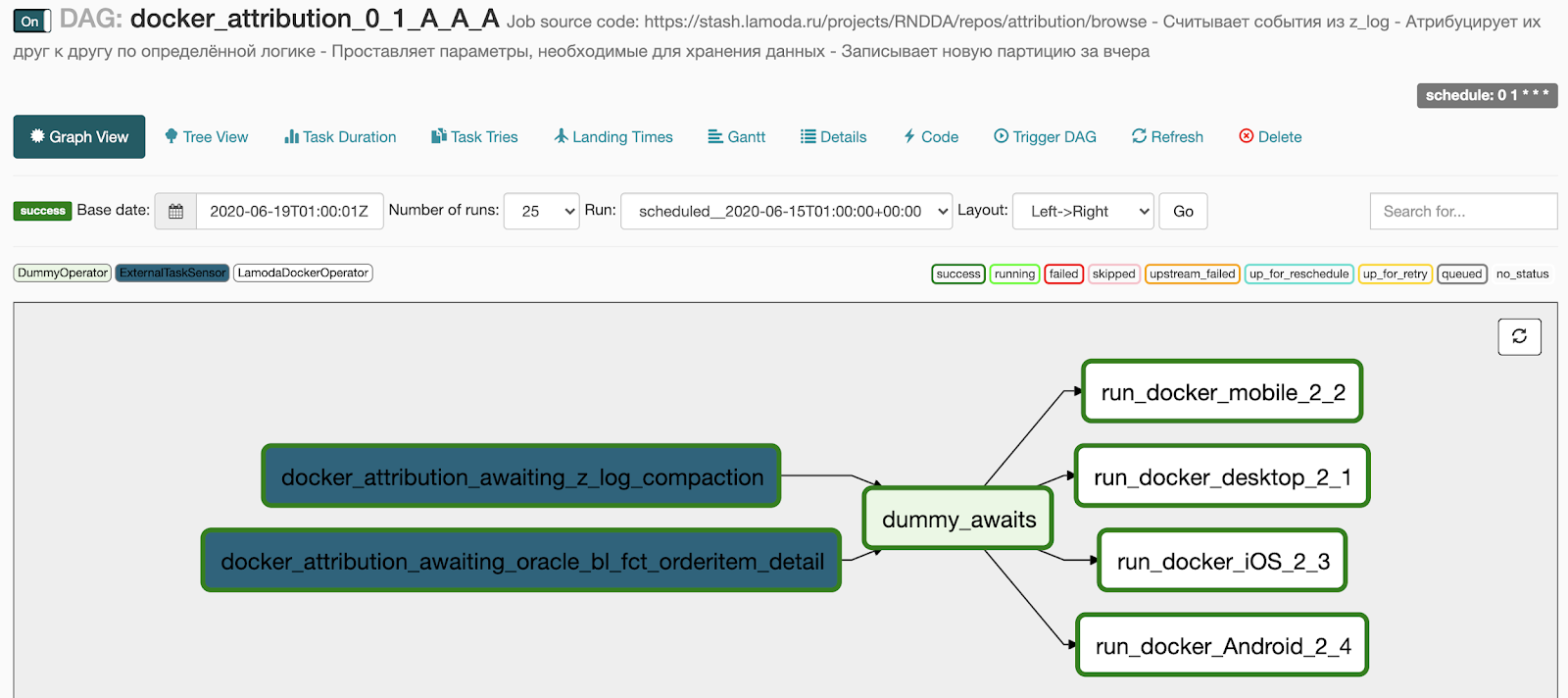
这是我们世代相传的结果:
- 等待块中的2点变成了两个等待基本管道执行的传感器,
- 我们在docker块中指定的4个任务变成了4个并行运行的任务,
- 我们在两个运算符之间添加了一个DummyOperator,以便任务之间没有连接网。
接下来我们要做什么
首先,构建一个完整的Feature环境。现在,我们拥有一个用于测试所有管道的开发平台。在测试之前,您需要确保开发环境现在免费。
最近,我们的团队扩大了,申请人数量增加了。我们已经找到了解决该问题的临时方法,现在当我们接受开发人员时,请在Slack中告知我们。它可以工作,但是仍然是开发和测试的瓶颈。
一种选择是迁移到Kubernetes。例如,在master中创建请求请求时,您可以在Kubernetes中引发一个单独的命名空间,以在其中部署Airflow,部署代码,然后分散变量和连接。部署后,开发人员将来到新创建的Airflow实例并测试其管道。我们在这个主题上有一些基础,但是我们的双手并没有进入战斗Kubernetes集群,我们可以在其中进行所有操作。
实施Feature环境的第二个选项是使用一个公共的dev分支来组织一个存储库,在该分支中,开发人员的代码被合并并自动部署到dev景观中。现在,我们正在积极寻求这一方案。
我们还想尝试实现插件-扩展Web界面功能的东西。插件实现的主要目标是在整个Airflow级别(即所有管道的级别)构建甘特图,以及在不同管道之间建立依赖关系图。
为什么我们选择气流
- 首先,这是Python,在这里,借助两个循环和几个条件,您可以创建一个优雅,正确工作的管道。而且它不需要用大量XML来描述。另外,几乎整个Python生态系统及其整个库动物园都是开箱即用的,可以随意使用。
- 缺少XML极大地简化了代码审查。我们为其编写了管道代码和配置,一切正常,一切正常。实际上,您可以拖动XML或任何其他配置格式,但这只是一个问题。
- unit-, , .
- , «», . Airflow . , , .
- Airflow ( ).
- Active Directory RBAC (role-based access control, )
- Worker Celery Kubernetes.
- open source-, , .
- Airflow , . .
- : statsd , Sentry – , Airflow , . Airflow-exporter Prometheus.
Airflow,
- – : , , execution_date – , .
- - -, , , Apache NiFi. – code-review diff- , .
- Scheduler - .
- – , . – .
- Airflow : . , , . RBAC ( ) , UI (, , ). RBAC – security Flask, .
- : , , -, , . , .
Airflow
- crontab’a cron .
- Python.
- - Docker, , .
- , , real time.
- Airflow , “, , , Z – ”.
Airflow
- –
- Astronomer, hosted- Airflow Kubernetes. –
- Astronomer Airflow –
- Airflow () Slack ().