Lyft决定将我们的服务器基础架构移至分布式容器编排系统Kubernetes,以利用自动化所提供的优势。他们希望有一个坚实可靠的平台,可以成为进一步开发的基础,并在提高效率的同时降低总体成本。
分布式系统可能难以理解和分析,Kubernetes也不例外。尽管有很多好处,但在迁移到CronJob时,我们发现了几个瓶颈,该系统是Kubernetes内置的系统,用于按计划执行重复任务。在这个由两部分组成的系列文章中,我们将讨论Kubernetes CronJob在大型项目中使用时的技术和操作缺陷,并与您分享如何克服它们。
首先,我将描述在Lyft中使用它们时遇到的Kubernetes CronJobs的缺点。然后(在第二部分)-我们将告诉您如何消除Kubernetes堆栈中的这些缺点,提高可用性和提高可靠性。
第1部分。简介
谁将从这些文章中受益?
- Kubernetes CronJob用户。
- , Kubernetes.
- , Kubernetes .
- , Kubernetes , .
- Contributor' Kubernetes.
?
- , Kubernetes ( , CronJob) .
- , Kubernetes Lyft , .
:
- cron'.
- , CronJob, — , CronJob, Job' Pod', . CronJob Unix cron' .
- sidecar- , . Lyft sidecar- , runtime- Envoy, statsd .., sidecar-, , .
- ronjobcontroller — Kubernetes, CronJob'.
- , cron , ( ).
- Lyft Engineering , ( «», « », « ») — Lyft ( «», « », «» «»). , , «-» .
CronJob' Lyft
如今,我们的多租户生产环境拥有近500个cron作业,每小时被称为1500次以上。
Lyft经常将定期计划任务用于各种目的。在转向Kubernetes之前,它们使用常规的Unix cron直接在Linux机器上运行。开发团队负责编写
crontab定义并提供实例,然后使用“基础结构代码”(IaC)管道执行这些实例,而基础结构团队负责维护它们。
作为将工作负载容器化和迁移到我们自己的Kubernetes平台的更大努力的一部分,我们决定迁移到CronJob *,用其Kubernetes替代传统的Unix cron。与许多其他公司一样,选择Kubernetes是因为它具有巨大的优势(至少在理论上如此),包括有效利用资源。
想象一下一个cron任务,每周运行一次,持续15分钟。在我们的旧环境中,专用于此任务的计算机将空闲99.85%的时间。对于Kubernetes,仅在调用期间使用计算资源(CPU,内存)。其余时间,未使用的容量可用于运行其他CronJob,或仅按比例缩小簇。考虑到过去执行cron作业的方式,我们将转向临时性工作模式,这将受益匪浅。

Lyft堆栈中开发人员和平台工程师的职责范围
迁移到Kubernetes平台后,开发团队停止分配和操作自己的计算实例。平台团队现在负责维护和操作Kubernetes堆栈中的计算资源和运行时依赖项。此外,她负责自己创建CronJob对象。开发人员只需要配置任务计划和应用程序代码。
但是,在纸上看起来一切都很好。在实践中,当我们从经过深入研究的传统Unix cron环境迁移到Kubernetes中的分布式临时性CronJob环境时,我们发现了几个瓶颈。
*尽管CronJob处于(并且截至现在)(从Kubernetes v1.18开始)处于测试版状态,但我们发现它当时非常满足我们的需求,并且也与我们拥有的其他Kubernetes基础设施工具包完全匹配...
Kubernetes CronJob与Unix cron有何不同?
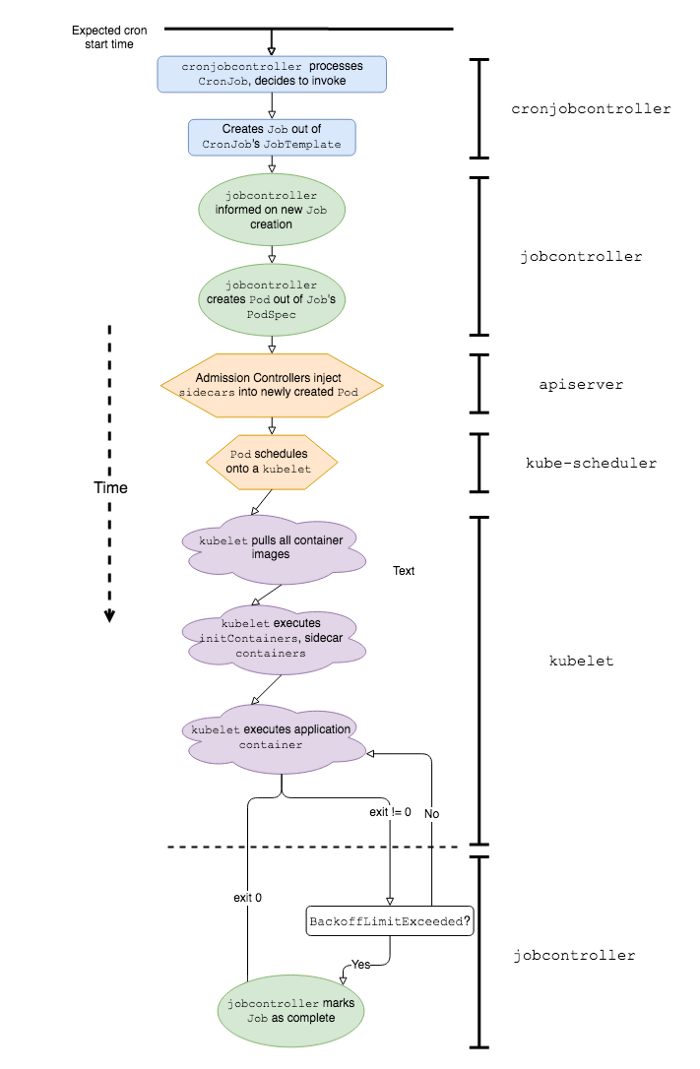
Kubernetes CronJob工作中涉及的事件和K8s软件组件的简化序列
为了更好地解释为什么在生产环境中使用Kubernetes CronJob会带来一定的困难,让我们首先定义它们与经典版本的区别。预期CronJob的工作方式与Linux或Unix上的cron作业相同;但是,它们的行为实际上至少有几个主要区别:启动速度和崩溃处理。
发射速度
延迟启动 (启动延迟)定义为从计划启动cron到应用程序代码实际开始所经过的时间。换句话说,如果cron计划在00:00:00开始,而应用程序在00:00:22开始运行,则启动该特定cron的延迟将为22秒。
对于经典的Unix cron,启动延迟最小。如果时间合适,这些命令将被简单执行。让我们通过以下示例进行确认:
# date
0 0 * * * date >> date-cron.log
使用这样的cron配置,我们很可能会在以下命令中获得以下输出
date-cron.log:
Mon Jun 22 00:00:00 PDT 2020
Tue Jun 23 00:00:00 PDT 2020
…
另一方面,Kubernetes CronJob可能会遇到严重的启动延迟,因为该应用程序之前会发生许多事件。这里是其中的一些:
-
cronjobcontroller处理并决定调用CronJob; -
cronjobcontroller根据CronJob作业规范创建一个Job; -
jobcontroller注意到一个新工作并创建一个Pod; - 准入控制器将Sidecar容器数据插入Pod规范*;
-
kube-scheduler在kubelet上规划一个Pod; -
kubelet启动Pod(获取所有容器图像); -
kubelet启动所有杂物箱*; -
kubelet启动应用程序容器*。
*这些阶段是Lyft Kubernetes堆栈所特有的。
我们发现,一旦在Kubernetes环境中达到一定规模的CronJob,项目1、5和7对延迟的影响最大。
因工作造成的延误 cronjobcontroller'
为了更好地了解延迟来自何处,让我们检查一下内联源代码
cronjobcontroller'。在Kubernetes 1.18中,它cronjobcontroller仅每10秒检查一次所有CronJob的内容,并在每一个上运行一些逻辑。
该实现
cronjobcontroller'通过对每个CronJob进行至少一个额外的API调用来同步执行此操作。当CronJob的数量超过一定数量时,这些API调用开始受到客户端约束的困扰。
10秒的轮询周期和客户端API调用导致CronJob启动延迟的显着增加。
用克朗调度豆荚
由于Cron时间表的性质,它们大多数在分钟的开始运行(XX:YY:00)。例如,
@hourly(每小时)cron在01:00:00、02:00:00等运行。在多租户cron平台的情况下,每小时,每四分之一小时,每5分钟等运行许多cron,这会导致在启动多个cron时出现瓶颈 (热点)同时。 Lyft的我们注意到一个这样的地方是小时的开始时间(XX:00:00)。这些热点创建负载并导致附加的限制参与的cronjob,如执行控制层组件的请求的频率kube-scheduler和kube-apiserver,这导致在启动延迟显着增加。
此外,如果您没有为峰值负载提供计算能力(和/或使用云服务的计算实例),而是使用群集自动缩放机制来动态扩展节点,则启动节点所花费的时间会增加启动延迟。豆荚CronJob。
容器启动:辅助容器
一旦成功计划了CronJob吊舱
kubelet,后者便应获取并运行所有小车和应用程序本身的容器映像。由于在Lyft中启动容器的细节(侧车容器在应用程序容器之前启动),任何侧车的启动延迟都会不可避免地影响结果,导致启动任务的额外延迟。
因此,在执行所需的应用程序代码之前,启动延迟以及多租户环境中的大量CronJob会导致明显且不可预测的启动延迟。稍后我们将看到,在实际条件下,这种延迟可能会对CronJob的行为产生负面影响,并有可能错过发射。
集装箱碰撞处理
通常,建议跟踪cron作业。对于Unix系统,这很容易做到。 Unix crones使用指定的shell解释给定的命令
$SHELL,并且在命令退出(成功与否)之后,该特定调用将被视为完成。您可以使用以下简单脚本来跟踪Unix上cron的执行:
#!/bin/sh
my-cron-command
exitcode=$?
if [[ $exitcode -ne 0 ]]; then
# stat-and-log is pseudocode for emitting metrics and logs
stat-and-log "failure"
else
stat-and-log "success"
fi
exit $exitcode
在Unix中,cron
stat-and-log对于每个cron调用将只运行一次-不管$exitcode。因此,这些度量标准可用于组织有关失败呼叫的最简单通知。
对于Kubernetes CronJob,默认情况下定义了对失败的重试,并且失败本身可能是由各种原因(Job失败或容器失败)引起的,监视并非如此简单明了。
在应用程序容器中使用类似的脚本,并且将Jobs配置为在失败时重新启动,CronJob将尝试在失败时执行任务,生成指标并记录过程,直到达到BackoffLimit(最大重试次数)。因此,试图确定问题原因的开发人员将不得不整理出许多不必要的“垃圾”。此外,由于应用程序容器可以自行恢复并成功完成任务,因此外壳脚本响应第一次失败而发出的警报也可能是普通的噪声,无法根据其发出进一步的操作。
您可以在作业级别而不是在应用程序容器级别实施警报。为此,可以使用作业失败的API级别指标,例如
kube_job_status_failedfrom kube-state-metrics。这种方法的缺点是,值班工程师只有在Job到达“最终故障阶段”并达到极限后才意识到问题BackoffLimit,这可能比应用程序容器的第一次故障晚得多。
CronJob'
大量的启动延迟和重启周期会引入额外的延迟,这可能会阻止Kubernetes CronJob重新执行。对于频繁调用的CronJob或运行时间明显长于空闲时间的CronJob,这种额外的延迟可能导致下一个计划的调用出现问题。如果的cronjob有一个政策
ConcurrencyPolicy: Forbid是禁止并发性,在未来的延迟导致调用没有完成时间和延迟。

时间轴的一个示例(从cronjobcontroller的角度来看),其中特定每小时CronJob超出了startupDeadlineSeconds:它跳过了预定的开始时间,直到下一个预定的时间才会被调用
还有一个更不愉快的情况(我们在Lyft中遇到过这种情况),由于CronJob可以完全跳过调用,因此是在安装CronJob的时候
startingDeadlineSeconds。在这种情况下,如果启动延迟超过startingDeadlineSeconds,则CronJob将完全跳过启动。
此外,如果将
ConcurrencyPolicyCronJob设置为Forbid,则上一个调用的失败后重启周期也会干扰下一个CronJob调用。
在现实生活中操作Kubernetes CronJob的问题
自从我们开始将重复的日历任务迁移到Kubernetes以来,已经发现从开发人员的角度以及从平台团队的角度来看,使用CronJob机制不变都会导致不愉快的时刻。不幸的是,他们开始否认我们最初选择Kubernetes CronJob的好处和好处。我们很快意识到开发人员和平台团队都没有必要的工具来利用CronJob并了解其复杂的生命周期。
开发人员试图利用他们的CronJob并对其进行配置,但是结果他们遇到了许多抱怨和问题,例如:
- 为什么我的cron无法正常工作?
- 看来我的cron已停止工作。您如何确认它实际上正在运行?
- 我不知道cron不能正常工作,我认为一切都很好。
- 如何“修复”丢失的cron?我不能仅通过SSH登录并自己运行命令。
- 您能说出为什么这个Cron似乎错过了X到Y之间的多次跑步吗?
- 我们有X个(大量的)克朗,每个克朗都有自己的通知,要维护所有这些通知变得非常乏味/困难。
- Pod,Job,Sidecar-这是什么胡扯?
作为平台团队,我们无法回答以下问题:
- 如何量化Kubernetes cron平台的性能?
- 启用其他CronJob将如何影响我们的Kubernetes环境?
- Kubernetes CronJob' ( multi-tenant) single-tenant cron' Unix?
- Service-Level-Objectives (SLOs — ) ?
- , , , ?
调试CronJob崩溃并非易事。通常需要凭直觉来了解哪里发生故障以及在哪里寻找证据。有时很难获得这些线索-例如,日志
cronjobcontroller',仅当启用高级别详细信息时才记录这些线索。此外,迹线可在一定的时间段,这使得调试类似于游戏“踢的摩尔”之后简单地消失(约此。 -大约译) -例如,对于CronJob'ov,Job'ov和Pod'ov Kubernetes活动默认情况下只保留一个小时。这些方法都不容易使用,并且随着平台上CronJob数量的增加,它们在支持方面都无法很好地扩展。
另外,有时候Kubernetes只是如果错过了太多运行,则停止尝试执行CronJob。在这种情况下,必须手动重新启动。在现实生活中,这种情况比您想像的要多得多,并且每次都需要手动解决问题变得非常痛苦。
这结束了我对在繁忙的项目中使用Kubernetes CronJob时遇到的技术和操作问题的总结。在第二部分中,我们将讨论如何在堆栈中消除Kubernetes,如何提高可用性以及如何提高CronJob的可靠性。
第2部分。简介
显然,保持不变的Kubernetes CronJob不能成为其Unix同类产品的简单方便的替代品。为了将我们的所有克朗放心地转移到Kubernetes,我们不仅需要消除CronJob的技术缺陷,而且还需要提高与它们合作的可用性。即:
1.听取开发人员的意见,以了解他们最担心的克朗问题的答案。例如:我的cron开始了吗?应用程序代码是否已执行?启动是否成功? cron运行了多长时间? (应用程序代码花了多长时间?)
2.通过使CronJob更加易于理解,其生命周期更加透明以及使平台/应用程序边界更清晰来简化平台维护。
3.用标准指标和警报来补充我们的平台,以减少自定义警报配置的数量,并减少开发人员必须编写和维护的重复cron绑定的数量。
4.开发易于崩溃恢复的工具,并测试新的CronJob配置。
5.修复Kubernetes中长期存在的技术问题,例如TooManyMissedStarts错误,该错误需要手动干预才能解决,并且在一种严重的故障情况下(未设置startupDeadlineSeconds时)导致崩溃而没有引起注意。
决断
我们解决了所有这些问题,如下所示:
- (observability). CronJob', (Service Level Objectives, SLOs) .
- CronJob' « » Kubernetes.
- Kubernetes.
CronJob'

由平台用于监测特定的cronjob生成的仪表板的一个例子
,我们已加入下列指标应用于Kubernetes栈(它们被用于在Lyft所有的cronjob定义):
1.
started.count-这个计数器时当的cronjob被称为第一次启动的应用程序容器递增。它有助于回答以下问题:“应用程序代码是否已运行? ”。
2.
{success, failure}.count-这些计数器当特定的cronjob呼叫到达递增终端状态(即,作业已完成其工作,并jobcontroller不再试图执行它)。他们回答了以下问题:“发射成功了吗? ”。
3.-
scheduling-decision.{invoke, skip}.count这些柜台使您可以了解cronjobcontroller调用CronJob时所做的决策。特别是,它skip.count有助于回答以下问题:“为什么我的cron无法正常工作?”。以下标签用作其参数reason:
-
reason = concurrencyPolicy-cronjobcontroller错过了对CronJob的呼叫,因为否则会打断它ConcurrencyPolicy; -
reason = missedDeadline-cronjobcontroller拒绝调用CronJob,因为它错过了指定的调用窗口.spec.startingDeadlineSeconds; -
reason = error是尝试调用CronJob时发生的所有其他错误的通用参数。
4.-
app-container-duration.seconds此计时器测量应用程序容器的寿命。它有助于回答以下问题:“应用程序代码运行了多长时间? ”。在此计时器中,我们故意不包括播客调度,启动Sidecar容器等所需的时间,因为它们是平台团队的责任,并且包含在启动延迟中。
5.-
start-delay.seconds此计时器测量启动延迟。跨平台汇总时,此度量标准使维护它的工程师不仅可以评估,监视和调整平台性能,还可以作为确定诸如启动延迟和最大cron计划频率之类的参数的SLO的基础。
基于这些指标,我们创建了默认警报。他们在以下情况下通知开发人员:
- 他们的CronJob没有按计划开始(
rate(scheduling-decision.skip.count) > 0); - 他们的CronJob失败(
rate(failure.count) > 0)。
开发人员不再需要为Kubernetes中的克朗定义自己的警报和度量标准-该平台提供了现成的副本。
如果需要的话,可以运行克朗
我们将其调整
kubectl create job test-job --from=cronjob/<your-cronjob>为适用于内部CLI工具。Lyft的工程师在需要时使用它与Kubernetes上的服务进行交互以调用CronJob:
- 从间歇性的CronJob崩溃中恢复;
- runtime- , 3:00 ( , CronJob', Job' Pod' ), — , ;
- runtime- CronJob' Unix cron', , .
TooManyMissedStarts
我们更正了TooManyMissedStarts的一个错误,现在CronJob的连续100次错过启动后不会“挂起”。该补丁不仅消除了手动干预的需要,而且使您可以实际跟踪何时超过时间。感谢Vallery Lancey设计和构建了此补丁,感谢Tom Wanielista帮助设计了算法。我们打开了一个PR,将此补丁带到Kubernetes的主要分支(但是,由于不活动,它从未被采用和关闭-大约是Transl。)。
startingDeadlineSeconds
实施cron监控

在Kubernetes CronJob生命周期的哪个阶段,我们添加了导出指标的机制
不依赖于cron时间表的警报
实施错过的cron呼叫通知的最棘手的部分是处理其计划(crontab.guru可以帮助您解密)。例如,考虑以下时间表:
# 5
*/5 * * * *
您可以在每次cron完成时使该计数器递增(或使用cron binding)。然后,在通知系统中,您可以编写一个条件表达式,例如:“看看前60分钟,让我知道计数器的增加量是否小于12”。问题解决了吧?
但是,如果您的时间表如下所示:
# 9 17
# .
# , (9-17, -)
0 9–17 * * 1–5
在这种情况下,您将不得不修改条件(尽管,也许您的系统仅在营业时间具有通知功能?)。不管怎样,这些示例说明了将通知绑定到cron计划有几个缺点:
- 更改计划时,必须更改通知逻辑。
- 一些cron计划需要相当复杂的查询才能使用时间序列进行复制。
- 克朗需要某种“等待期”,这些克朗不能完全及时地开始工作,以最大程度地减少误报。
默认情况下,仅第2步就使得在平台上为所有crone生成通知都是一项非常艰巨的任务,而第3步对于像Kubernetes CronJob这样的分布式平台尤为重要,其中启动延迟是一个重要因素。此外,有些解决方案使用“死人开关”,这又使我们回到将通知绑定到cron的时间表的需要,和/或异常检测算法需要进行一些培训并且不能立即用于新的CronJob或更改它们。时间表。
解决该问题的另一种方法是问自己:cron应该已经启动但是没有启动意味着什么?
在Kubernetes中,如果您忘记了bug
cronjobcontroller'或控制平面本身掉落的可能性(尽管如果您正确跟踪集群的状态,您应该立即看到此情况)-这意味着cronjobcontrollerCronJob评估并决定(根据cron的时间表),但是由于某种原因由于这个原因我故意决定不做。
听起来很熟悉?这正是我们的指标
scheduling-decision.skip.count!现在,我们只需要跟踪更改rate(scheduling-decision.skip.count)以通知用户他的CronJob应该已经被触发,但是没有被触发。
此解决方案使cron计划与通知本身脱钩,从而提供了许多好处:
- 现在,您在更改计划时无需重新配置警报。
- 无需复杂的时间要求和条件。
- 您可以轻松地为平台上的所有CronJob生成默认警报。
这与前面提到的其他时间序列和警报相结合,有助于创建更完整,更易理解的CronJob状态图。
实现启动延迟计时器
由于CronJob生命周期的复杂性,我们需要仔细考虑工具包在堆栈上的放置位置,以便可靠,准确地测量该指标。结果,一切归结为确定了两个时间点:
- T1:何时应启动cron(根据其时间表)。
- T2:应用程序代码实际开始执行的时间。
在这种情况下
start delay(启动延迟)= 2 — 1。为了修正时刻T1,我们将代码包含在的cron调用逻辑中cronjobcontroller'。它像记录CronJob时创建.metadata.Annotation的Job对象一样记录预期的开始时间cronjobcontroller。现在可以使用任何具有正常请求的API客户端来检索它GET Job。
使用T2,一切变得更加复杂。由于我们需要使值尽可能接近实数,因此T2必须与首次启动具有应用程序的容器的时刻一致。如果您在任何时候拍摄T2当容器启动(包括重新启动)时,在这种情况下延迟启动将包括应用程序本身的运行时间。因此,
.metadata.Annotation只要我们发现给定Job的应用程序容器首先收到status ,便决定分配另一个Job对象Running。因此,从本质上讲,已创建了分布式锁,并且忽略了该Job的应用程序容器的将来启动(仅保存了第一次启动的时间)。
结果
在推出新功能并修复错误之后,我们从开发人员那里收到了很多积极的反馈。现在,开发人员使用我们的Kubernetes CronJob平台:
- 不再需要为自己的监视工具和警报感到困惑;
- , CronJob' , .. alert' , ;
- CronJob' , CronJob' « »;
- (
app-container-duration.seconds).
此外,平台维护工程师现在拥有一个新参数(启动延迟)来衡量用户体验和平台性能。
最后(也许是我们最大的胜利),通过使CronJob(及其状态)更加透明和可追踪,我们为开发人员和平台工程师大大简化了调试过程。他们现在可以使用相同的数据一起进行调试,因此开发人员经常会自行发现问题并使用平台提供的工具解决问题。
结论
编排分布式计划任务并不容易。CronJob Kubernetes只是组织它的一种方法。尽管CronJob并非理想之选,但如果您准备投入时间和精力来改善它们,则CronJob的能力相当强大,当然,您愿意花时间和精力来改善它们:提高可观察性,了解故障的原因和细节以及使用易于使用的工具进行补充。
注意:有一个开放的Kubernetes增强提案(KEP),可解决CronJob的缺点并将其更新版本转换为GA。
感谢Rithu John,Scott Lau,Scarlett Perry,Julien Silland和Tom Wanielista在审阅这一系列文章方面的帮助。
译者的PS
另请参阅我们的博客: