
随着今年3月向自我隔离的过渡,我们像许多公司一样,已将所有杂货活动在线上转移。好吧,您还记得这张关于猴子网络研讨会的精彩照片。在过去的六个月中,仅在我的团队负责的数据中心这一主题上,我们累积了大约25个小时的2小时在线讲座,总共50个小时的视频。全面增长的问题是如何理解在哪个视频中寻找某些问题的答案。目录,标签,简短描述都很好,好了,我们最终发现有4个关于主题的两个小时的视频,然后呢?观看倒带吗?可能会有所不同吗?如果您以时髦的方式行事并尝试破坏AI?
不耐烦的破坏者:我找不到完整的奇迹系统或无法将其组装在膝盖上,因此本文没有意义。但是经过几天(或更晚)的研究,我得到了一个有效的MVP,我想向您介绍一下。本文的目的是查看对该问题的关注程度,从有知识的人那里获得建议,也许还可以找到遇到相同问题的其他人。
我想做的事
乍一看,一切看起来都很简单-拍摄视频,通过神经网络运行,获取文本,然后在文本中查找描述感兴趣主题的片段。一次搜索目录中的所有视频将更加方便。实际上,很早以前就发明了将文本的文字记录与视频一起上传的方法,尽管很显然那里的人们可以编辑这些文本,但Youtube和大多数教育平台都可以做到这一点。您可以用眼睛快速扫描文本,了解是否有所需问题的答案。从便利的功能来看,也许可以在文本感兴趣的地方p一口并聆听讲师所说的话并在此处显示,这也不会有什么坏处,如果在文本中按时标出单词的话,这也不难。好吧,我梦到了可能的发展方向,让我们最后谈一谈,现在让我们尝试简单地尽可能高效地实施该链
视频文件->文本片段->模糊文本搜索。
起初我以为,因为一切都如此简单,并且这种情况已经在所有AI会议上讨论了4年,所以这种系统应该已经存在。几个小时的搜索和阅读文章表明情况并非如此。视频是呼叫中心解决方案的一部分,主要用于搜索人脸,汽车和其他视觉对象(面具/头盔)以及音频-歌曲,曲目以及扬声器的语调/语调。只能找到对Deepgram系统的提及。但是,不幸的是,她不支持俄语。另外,Microsoft在Streams中具有非常相似的功能,但是我从没发现过对俄语的支持,显然,它也不存在。
好吧,让我们重新发明。我不是专业程序员(顺便说一句,我会很乐意接受对代码的建设性批评),但是我有时会“为自己”写一些东西。可以将语音转换为文本的神经网络称为(惊讶),即语音转换为文本。如果可以找到公共语音转文本服务,则可以使用它来对所有网络研讨会中的语音进行“数字化”,然后在文本中进行模糊搜索-这是一项轻松的任务。我承认,起初我不认为要“爬到云中”,而是想在本地收集所有信息,但是在阅读了Habré上的这篇文章之后,我认为语音识别在云中确实更好。
寻找用于语音转文字的云服务
对能够进行语音转文本的服务的搜索显示,有很多这样的系统,包括在俄罗斯开发的系统,其中还包括Google,Amazon,MS Azure等全球云提供商。此处提供了几种服务的描述,包括俄语服务。通常,搜索引擎结果中的前20行将是唯一的。但是还有另一个障碍-我想将来将该系统投入生产,这是一个成本,我为思科工作,思科在全球范围内与领先的云有合同。因此,从整个清单来看,我决定现在只考虑它们。
因此,我的清单已减少到Google,Amazon,Azure,IBM Watson(标题的链接与下表相同)。所有服务都有可以使用它们的API。在分析了其余的可能性之后,我编译了一张小表:

IBM Watson在此阶段退出了比赛,由于我用俄语录制的所有唱片,因此决定在网络研讨会的简短摘录中测试其余提供商。我在AWS和Azure中设置了帐户。展望未来,我要说的是,微软在设置帐户方面确实是一个棘手的难题。我是从一个“登陆”阿姆斯特丹互联网上的公司网络工作的,在注册过程中,系统曾两次询问我是否确定我的地址是俄罗斯,此后系统显示一条消息,指出该帐户正在管理中,正在“待澄清” ... 5天后,当我写这篇文章时,情况没有改变,所以我还没有能够测试Azure,这很遗憾!我了解-安全性,但这还不允许我尝试该服务。问题解决后,我将稍后尝试进行此操作。
另外,我想在Yandex.Cloud中测试此功能,从理论上讲,他们对俄语语音的认可应该是最好的。但是,不幸的是,在该服务的测试访问页面上,仅具有“说”文本的功能,而未提供文件下载。因此,我们将与Azure一起推迟。
因此,有Google和Amazon,让我们尽快对其进行测试!在编写任何代码之前,您可以手动检查和比较所有内容,这两个提供程序除了API外,还具有管理界面。为了进行测试,我首先准备了一个10分钟的通用片段,如果可能的话,使用最少的专业术语。但是后来发现Google在测试模式下最多支持1分钟的片段,因此为了比较服务,我使用了57秒的片段。
根据工作结果,两个服务都将发布识别的文本,您可以在一分钟的间隔内比较其工作结果。
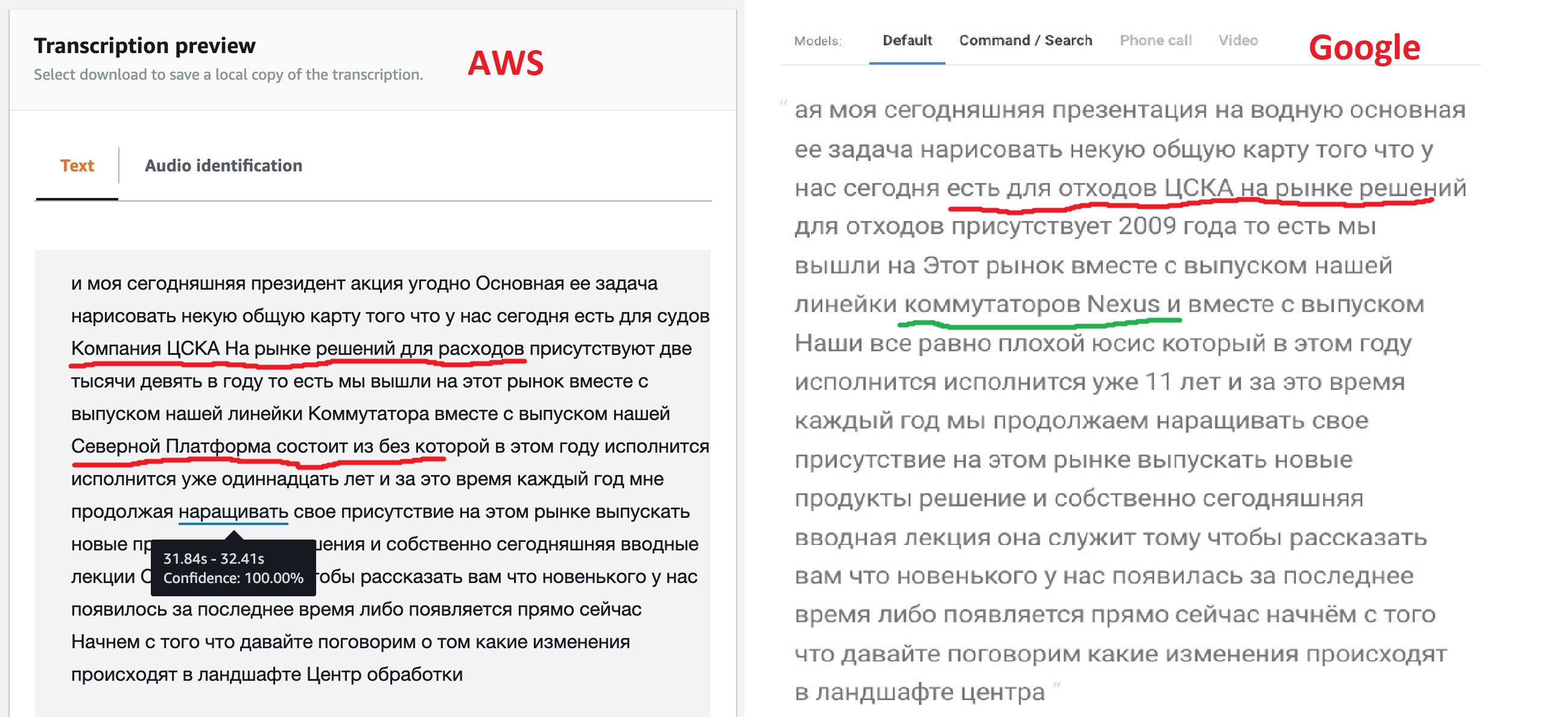
坦率地说,结果与预期不符,但是模型为定制提供不同的选择并不是没有道理的。我们可以看到,“开箱即用”的Google引擎可以更清晰地识别大部分文本,它还可以查看某些产品的名称,尽管不是全部。这表明他们的模型允许使用多语言文本。亚马逊(后来被证实)没有这样的机会-他们说俄语,这意味着我们会唱歌:“ Kin babe lom”和句号!
但是,获得Amazon提供的带标签JSON的功能对我来说非常有趣。毕竟,这将使将来可以实现直接过渡到找到所需片段的文件部分。也许Google也具有这样的功能,因为所有的语音识别神经网络都以这种方式工作,但是文档中的粗略搜索未能找到该功能。

如果查看此JSON,则可以看到它由三个部分组成:翻译后的文本(脚本),单词数组(项目)和一组片段(段)。对于每个元素的单词和句段数组,将指示其开始和结束时间,以及神经网络正确识别该元素的置信度(置信度)。
教一个神经网络来理解数据中心
因此,在此阶段结束时,我决定选择Amazon Transcribe进行进一步的实验,并尝试建立学习模型。如果您无法获得稳定的认可,请与Google联络。在10分钟的片段上进行了进一步的测试。
AWS Transcribe有两个选项可用于调整神经网络识别的内容,还有多个用于后处理文本的功能:
- Custom Vocabularies – «» , , «» , . : «, , » Word 97- . , , .. .
- Custom Language Models – «» 10 . , . , , , .
- , , -. , – , .. -, .
因此,我决定对文字说我自己的话。显然,它将包含诸如“网络,服务器,配置文件,数据中心,设备,控制器,基础结构”之类的词。经过2-3次测试,我的词汇量增长到60个单词。必须在常规文本文件中创建此字典,每行一个单词,均以大写字母表示。还有一个更复杂的选项(在此描述),可以指定单词的发音方式,但是在起步阶段,我决定使用一个简单的列表。
在使用字典之前,您需要创建它。在Amazon Transcribe的“自定义词汇”选项卡上,单击“创建词汇”,加载文件文本,指定俄语,回答其余问题,然后开始创建词典。一旦他出去处理变为就绪-可以使用字典。
问题仍然存在-如何识别“英语”术语?让我提醒您,该词典仅支持一种语言。最初,我想用英语术语创建一个单独的字典,并在其中运行相同的文本。当检测到诸如Cisco,VLAN,UCS之类的术语时等等c机率100%-在给定的时间段内使用它们。但是我马上要说这是行不通的,英语分析器不能识别文本中超过一半的术语。经过思考,我认为这是合乎逻辑的,因为我们用“俄罗斯口音”发音所有这些术语,即使是英裔美国人也不是第一次理解我们。这促使人们想到按照“听见即写”的原则将这些术语简单地添加到俄语词典中。思科,usies,eisiai,vilan,viikslan-毕竟,老实说,当我们彼此通信时,我们会这样说。这使字典增加了几十个单词,但放眼未来,它将识别质量提高了一个数量级!
俗话说“先有好思想”,已经创建了第一本词典,所以我决定创建另一本词典,在其中添加所有缩写,然后比较发生的情况。
使用字典开始识别同样容易,在“转录作业”选项卡上的“转录”服务中,选择“创建作业”,指定俄语,不要忘记指定我们需要的字典。另一个有用的操作-您可以要求神经网络为我们提供多个替代搜索结果,“替代结果-是”项目,我设置了3个替代选项。稍后,当我进行模糊文本搜索时,这将派上用场。
广播10分钟的文本需要4-5分钟,为了不浪费时间,我决定编写一个小型工具,以方便比较结果。我将在浏览器中显示JSON文件中的最终文本,同时突出显示通过神经网络(相同的置信度参数)检测单个单词的“可靠性” 。对于结果文本,我有三个选项-默认翻译,不带术语的词典和带术语的词典。让所有三个文本同时显示在三列中。我突出显示了绿色的可靠性高于95%,黄色的可靠性从95%到70%,红色低于70%的单词。生成的HTML页面的匆忙编译代码如下,JSON文件应与该文件位于同一目录中。在FILENAME1变量等中指定文件名。
HTML页面代码以查看结果
<!DOCTYPE html>
<html lang="en">
<head> <meta charset="UTF-8"> <title>Title</title> </head>
<body onload="initText()">
<hr> <table> <tr valign="top">
<td width="400"> <h2 >- </h2><div id="text-area-1"></div></td>
<td width="400"> <h2 > 1: / </h2><div id="text-area-2"></div></td>
<td width="400"> <h2 > 2: / </h2><div id="text-area-3"></div></td>
</tr> </table> <hr>
<style>
.known { background-image: linear-gradient(90deg, #f1fff4, #c4ffdb, #f1fff4); }
.unknown { background-image: linear-gradient(90deg, #ffffff, #ffe5f1, #ffffff); }
.badknown { background-image: linear-gradient(90deg, #feffeb, #ffffc2, #feffeb); }
</style>
<script>
// File names
const FILENAME1 = "1-My_CiscoClub_transcription_10min-1-default.json";
const FILENAME2 = '2-My_CiscoClub_transcription_10min-2-Russian_only.json';
const FILENAME3 = '3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json';
// Read file from disk and call callback if success
function readTextFile(file, textBlockName, callback) {
let rawFile = new XMLHttpRequest();
rawFile.overrideMimeType("application/json");
rawFile.open("GET", file, true);
rawFile.onreadystatechange = function() {
if (rawFile.readyState === 4 && rawFile.status == "200") {
callback(textBlockName, rawFile.responseText);
}
};
rawFile.send(null);
}
// Insert text to text block and color words confidence level
function updateTextBlock(textBlockName, text) {
var data = JSON.parse(text);
let translatedTextList = data['results']['items'];
const listLen = translatedTextList.length;
const textBlock = document.getElementById(textBlockName);
for (let i=0; i<listLen; i++) {
let addWord = translatedTextList[i]['alternatives'][0];
// load word probability and setup color depends on it
let wordProbability = parseFloat(addWord['confidence']);
let wordClass = 'unknown';
// setup the color
if (wordProbability > 0.95) {
wordClass = 'known';
} else if (wordProbability > 0.7) {
wordClass = 'badknown';
}
// insert colored word to the end of block
let insText = '<span class="' + wordClass+ '">' + addWord['content'] + ' </span>';
textBlock.insertAdjacentHTML('beforeEnd', insText)
}
}
function initText() {
// read three files each to it's area
readTextFile(FILENAME1, "text-area-1", function(textBlockName, text){
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME2, "text-area-2", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME3, "text-area-3", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
}
</script>
</body></html>
我下载了所有三个任务的asrOutput.json文件,将它们重命名为HTML脚本中的编写,这就是发生的情况。

可以清楚地看到,俄语术语的添加使神经网络可以更准确地识别特定术语,例如“服务配置文件”等。第二步中增加了俄文转录,使CSKA变成了思科。文本仍然相当“脏”,但是对于我的上下文搜索任务来说,它应该已经合适了。随着新的网络研讨会的增加和阅读,词汇量将逐渐扩大,这是维护这样一个不应忘记的系统的过程。
在识别的文本中进行模糊搜索
解决模糊搜索问题的方法大概有十二种,其中大部分是基于一小套数学算法,例如Levenshtein距离。这个好文章,多了一个和多一个。但是我想找到一些准备就绪的东西,例如发布和工作。
从本地文件搜索现成的解决方案,一个小小的研究之后,我发现了一个比较老的项目狮身人面像也全文搜索的可能性,似乎是在PostgreSQL里,它是写关于这个这里。但是大多数材料(包括俄语)都是关于Elasticsearch的。阅读了良好的启动和设置指南后,我决定使用本文或本课程,这是另一篇文章,以及Python的文档和API指南。
对于所有本地实验,我使用Docker已有很长时间了,我强烈建议每个出于某种原因尚未弄清Docker的人都这样做。实际上,我尽量不要在本地操作系统中运行开发环境,浏览器和“查看器”以外的任何程序。除了没有兼容性问题,等等。这使您可以快速尝试新产品,并查看其效果如何。
我们使用Elasticsearch下载该容器并使用两个命令运行它:
$ docker pull elasticsearch:7.9.1
$ docker run -d --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" elasticsearch:7.9.1
启动容器后,
http://localhost:9200弹性接口出现在address ,可以使用浏览器或POSTMAN工具的REST API对其进行访问。但是我找到了一个方便的Chrome插件。
这就是上面的指南之一中介绍的有关有趣小猫的示例的插件窗口。
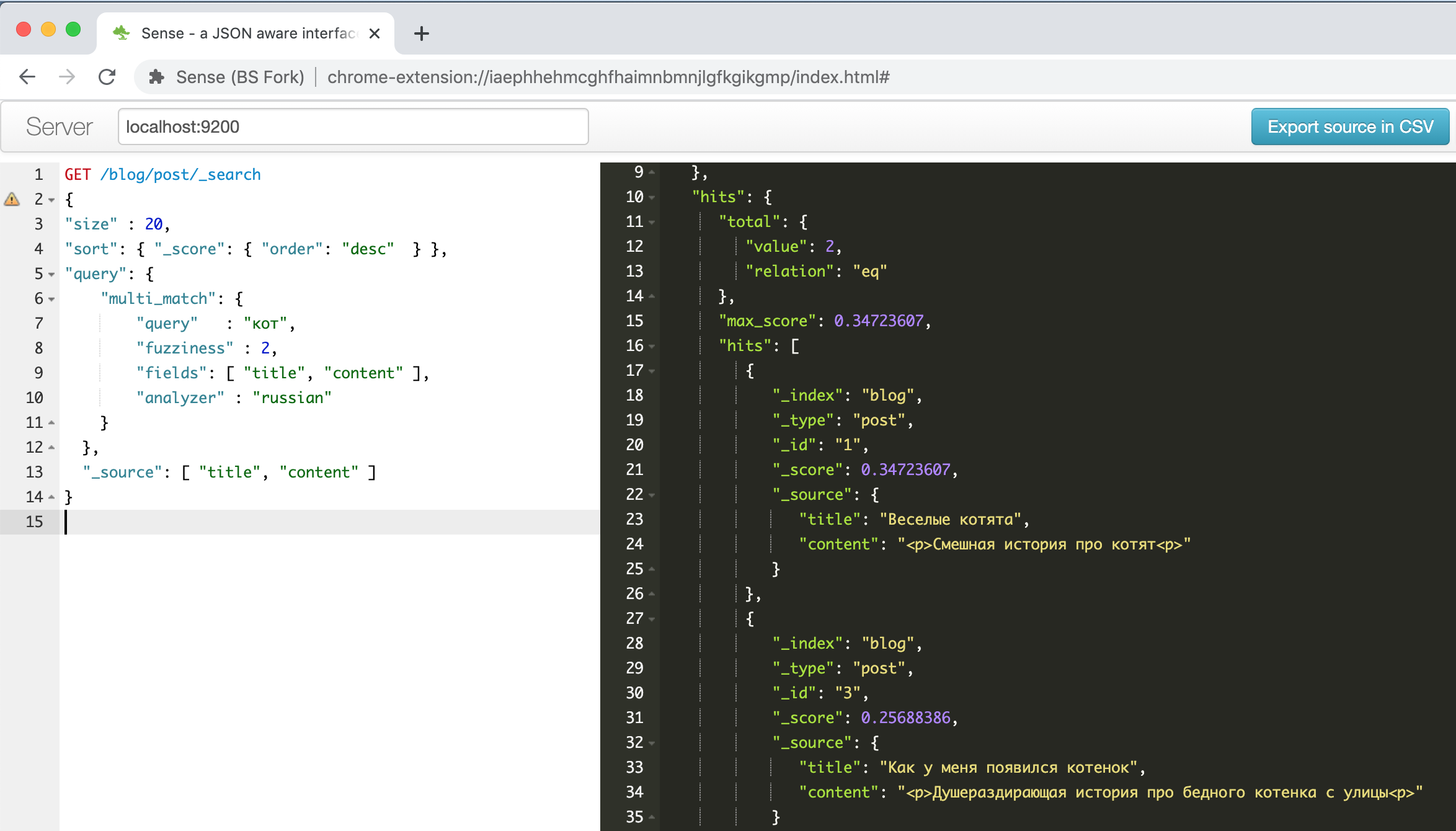
左边是请求-右边是答案,自动完成,语法突出显示,自动格式化-要提高工作效率还需要做什么!另外,此插件可以识别从剪贴板粘贴的文本中的CURL命令行格式,并正确设置其格式,例如,尝试粘贴
“ curl -X GET $ ES_URL ”行,看看会发生什么。总的来说,这很方便。
我将存储什么以及如何搜索?Elasticsearch接收所有JSON文档并将它们存储在称为索引的结构中。可以有任意多个不同的索引,但是一个索引可以包含同类数据和文档,具有相似的字段结构和相同的搜索方法。
为了研究模糊搜索的可能性,我决定下载并搜索在上一步中获得的转录文件的短语(段)部分。在JSON文件的segments部分中,数据以以下格式存储:
- 1 (segment)
-> /
->
--> 1
---->
----> , (confidence)
--> 2
---->
----> , (confidence)
我想增加成功搜索的可能性,因此我将所有其他选项上传到数据库中进行搜索,然后从找到的片段中选择总置信度更高的片段。
要将JSON文档重新格式化并加载到Elasticsearch中,我使用了一个小的Python脚本,脚本逻辑如下:
- 首先,我们遍历细分部分的所有元素以及所有其他转录选项
- 对于每个转录选项,我们考虑其总的识别置信度,我只是对单个单词取算术平均值,尽管可能在将来需要更仔细地进行处理。
- 对于每个替代转录选项,将表单记录加载到Elasticsearch中
{ "recording_id" : < >, "seg_id" : <id >, "alt_id" : <id >, "start_time" : < >, "end_time" : < >, "transcribe_score" : < (confidence) >, "transcript" : < > }
将记录从JSON文件加载到Elasticsearch的Python脚本
from elasticsearch import Elasticsearch
import json
from statistics import mean
#
TRANCRIBE_FILE_NAME = "3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json"
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
es.indices.create(index=INDEX_NAME) # Create index for our recordings
# Open and load file
res = None
with open(TRANCRIBE_FILE_NAME) as json_file:
data = json.load(json_file)
res = data['results']
#
index = 1
for idx, seq in enumerate(res['segments']):
# enumerate fragments
for jdx, alt in enumerate(seq['alternatives']):
# enumerate alternatives for each segments
score_list = []
for item in alt['items']:
score_list.append( float(item['confidence']))
score = mean(score_list)
obj = {
"recording_id" : "rec_1",
"seg_id" : idx,
"alt_id" : jdx,
"start_time" : seq["start_time"],
"end_time" : seq ["end_time"],
"transcribe_score" : score,
"transcript" : alt["transcript"]
}
es.index( index=INDEX_NAME, id = index, body = obj )
index += 1
如果您没有Python,也不要灰心,Docker会再次帮助我们。我通常将容器与Jupyter笔记本一起使用-您可以使用常规浏览器连接到该容器,并执行所需的操作,这是保存结果的唯一考虑,因为容器被破坏时,所有信息都会丢失。如果您以前从未使用过此工具,那么对于初学者来说,这是一篇不错的文章,顺便说一句,您可以安全地跳过有关安装的部分。我们
使用以下命令通过Python笔记本启动一个容器:
$ docker run -p 8888:8888 jupyter/base-notebook sh -c 'jupyter notebook --allow-root --no-browser --ip=0.0.0.0 --port=8888'
成功启动脚本后,我们将使用任何浏览器在屏幕上显示的地址处连接该浏览器,这是
http://127.0.0.1:8888使用指定的安全密钥。
我们在编写的第一个单元格中创建一个新的笔记本:
!pip install elasticsearch
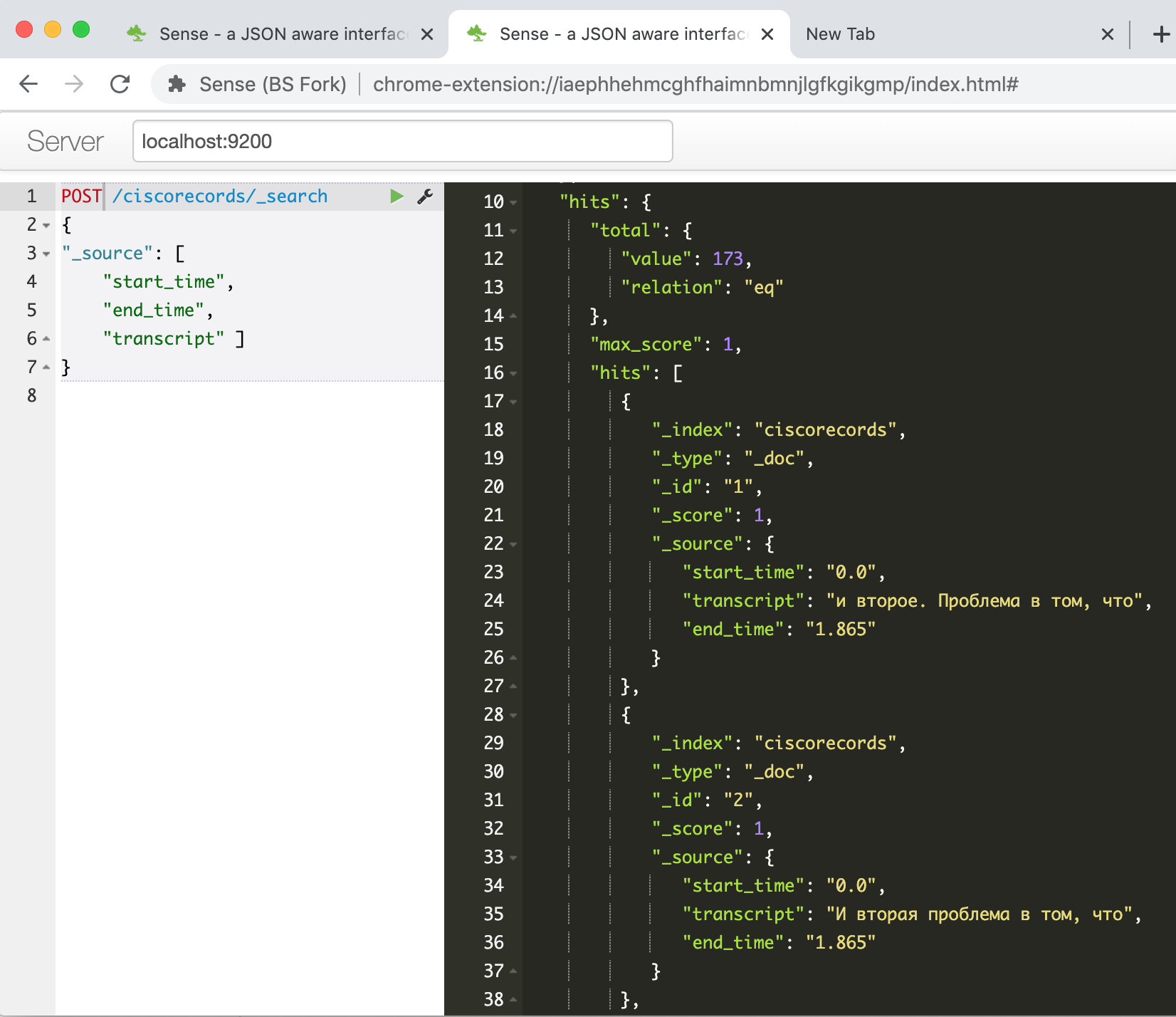
运行,等待直到安装了通过API使用ES的软件包,然后将脚本复制到第二个单元格中并运行它。工作完成后,如果一切都成功,我们可以在Elasticsearch控制台中检查是否已成功加载我们的数据。
GET /ciscorecords/_search根据hits.total.value字段告诉我们,我们输入命令并在响应窗口中看到已加载的记录,总共173条。
现在是尝试模糊搜索的时候了-这就是全部。例如,要搜索短语“数据中心网络的核心”,您需要提供以下命令:
POST /ciscorecords/_search
{
"size" : 20,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : " ",
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
"_source": [ "transcript", "transcribe_score" ]
}
我们得到多达47个结果!

毫不奇怪,因为它们大多数是同一片段的不同变体。让我们编写另一个脚本,以从每个段中选择一条具有最高置信度值的记录。
用于查询Elasticsearch数据库的Python脚本
#####
#
# PHRASE = " "
# PHRASE = " "
PHRASE = " "
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
#
elastic_queary = {
"size" : 40,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : PHRASE,
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
}
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
#
res = es.search(index=INDEX_NAME, body = elastic_queary)
print ("Got %d Hits:" % res['hits']['total']['value'])
#
search_results = {}
for hit in res['hits']['hits']:
seg_id = hit["_source"]['seg_id']
if seg_id not in search_results or search_results[seg_id]['score'] < hit["_score"]:
_res = hit["_source"]
_res["score"] = hit["_score"]
search_results[seg_id] = _res
print ("%s unique results \n-----" % len(search_results))
for rec in search_results:
print ("seg %(seg_id)s: %(score).4f : start(%(start_time)s)-end(%(end_time)s) -- %(transcript)s" % \
(search_results[rec]))
输出示例:
Got 47 Hits:
16 unique results
-----
seg 39: 7.2885 : start(374.24)-end(377.165) -- , ..
seg 49: 7.0923 : start(464.44)-end(468.065) -- , ...
seg 41: 4.5401 : start(385.14)-end(405.065) -- . , , , , , ...
seg 30: 4.3556 : start(292.74)-end(298.265) -- , , ,
seg 44: 2.1968 : start(415.34)-end(426.765) -- , , , . -
seg 48: 2.0587 : start(449.64)-end(464.065) -- , , , , , .
seg 26: 1.8621 : start(243.24)-end(259.065) -- . . , . ...
我们看到结果变得越来越小,现在我们可以查看结果并选择最感兴趣的结果。
另外,由于我们具有视频片段的开始和结束时间,因此我们可以使用视频播放器制作一个页面,并以编程方式将其“倒带”到感兴趣的片段。
但是,如果对此主题的进一步出版物感兴趣,我将把该任务放在单独的文章中。
而不是结论
因此,在本文的框架内,我展示了如何解决使用视频工具构建文本搜索系统的问题,该工具带有有关技术主题的网络研讨会录像。结果就是通常所说的MVP,即 最小的工作算法,可让您获得结果,并证明该结果在原则上可以使用现有技术实现。
从可以在不久的将来实现的想法到最终产品还有很长的路要走:
- 拧上视频播放器,以便您可以收听,查看找到的片段
- 考虑一下文本编辑的可能性,虽然您可以保留100%识别的单词文本的锚点,但仅编辑识别质量下降的片段。
- elasticsearch, -
- speech-to-text, Google, Yandex, Azure. –
- , «»
- BERT (Bi-directional Encoder Representation from Transformer), . – « xx yy».
- , - - . Youtube , 15-20 , ,
- – , , ,
如果您有任何问题/意见,我将很乐意回答,也将听到关于改进或简化整个流程的任何建议。这是我为Habr撰写的第一篇技术文章,我真的希望它能对您有用且有趣。
在您进行创造性搜索时,祝大家好运,也许原力与您同在!