
什么是短期和长期指标?
排名模型试图估计用户与新闻(帖子)互动的可能性:他将关注该新闻,并在其上标记“赞”,并发表评论。然后,模型以该概率的降序分布记录。因此,通过提高排名,我们可以提高用户操作(顶,评论和其他操作)的点击率(点击率)。这些指标对排名模型的变化非常敏感。我将它们简称。
但是还有另一种指标。可以相信,例如,在应用程序中花费的时间或用户会话的次数更好地反映了他对服务的态度。我们称此类指标为长。
直接通过排名算法优化长指标并不是一件容易的事。如果采用简短的指标,这会容易得多:例如,点赞的点击率直接与我们估算其可能性的程度直接相关。但是,如果我们知道短期和长期指标之间的因果关系(或因果关系),那么我们可以集中精力仅优化那些应该可预测地影响长期指标的短期指标。我试图提取这种因果关系-并在我的工作中写到了因果关系,并以ITMO的理学学士(CT)的文凭毕业了。我们与VKontakte在ITMO的机器学习实验室中进行了研究。
链接到代码,数据集和沙箱
您可以在这里找到所有代码:AnverK。
为了分析指标之间的关系,我们使用了一个数据集,其中包含VK团队在不同时间进行的6,000多次实际A / B测试的结果。该数据集也可在存储库中使用。
在沙盒中,您可以看到如何在合成数据上使用建议的包装器。
此处-如何将算法应用于数据集:在建议的数据集上。
处理错误的相关性
看来要解决我们的问题,足够计算指标之间的相关性。但这并非完全正确:关联并不总是因果关系。假设我们仅测量四个指标,它们之间的因果关系如下所示:

在不失一般性的前提下,我们假设对箭头方向有积极影响:喜欢的人越多,SPU越多。在这种情况下,可以确定照片上的评论对SPU产生积极影响。并确定如果您“增加”此指标,则SPU将增加。这种现象称为虚假相关。:相关系数很高,但是没有因果关系。错误相关不限于相同原因的两种影响。在同一列中,可能会得出一个错误的结论,即喜欢对照片张数有正面影响。
即使有这样一个简单的示例,对相关性的简单分析也将导致许多错误的结论,这是显而易见的。因果推理(关系的推理方法)允许从数据恢复因果关系。为了将它们应用到任务中,我们选择了最合适的因果推理算法,为它们实现了python接口,还添加了对已知算法的修改,这些修改在我们的条件下效果更好。
推理链接的经典算法
我们考虑了几种因果推理方法:PC(彼得和克拉克),FCI(快速因果推理)和FCI +(从理论上讲与FCI相似,但速度要快得多)。您可以在以下来源中详细了解它们:
- 因果关系(J. Pearl,2009),
- 因果关系,预测和搜索(P. Spirtes等,2000),
- 学习稀疏因果模型并非难事(T. Claassen et al。,2013)。
但重要的是要了解,第一种方法(PC)假设我们观察到影响两个或多个度量的所有数量-此假设称为因果充分性。其他两种算法考虑到可能存在影响监视指标的不可观察因素。也就是说,在第二种情况下,因果表示被认为更自然,并且允许存在不可观察的因素:pcalg

库中提供了这些算法的所有实现。它既美观又灵活,但是有一个“缺点”-用R编写(开发计算量最大的函数时,将使用RCPP包)。因此,对于上述方法,我在CausalGraphBuilder类中编写了包装器,并添加了其用法示例。 我将描述链接推断功能的约定,即接口和可以在输出中获得的结果。您可以通过测试函数以获得条件独立性。这样的测试会返回
在零假设下,数量 和 有条件地独立于一组已知量 ...默认为部分相关测试。我选择此测试的功能是因为它是pcalg中的默认功能,并且是在RCPP中实现的-这使其在实践中速度很快。您也可以转移,从此开始,顶点将被视为从属。对于PC和FCI算法,如果不需要编写库操作日志,则还可以设置CPU内核数。FCI +没有这样的选项,但是我建议使用这种特殊算法-它可以提高速度。另一个警告:FCI +当前不支持所提出的边缘定位算法-关键在于pcalg库的局限性。
根据所有算法的工作结果,以边列表的形式构建了PAG(部分祖先图)。使用PC算法时,应将其解释为经典意义上的因果图(或贝叶斯网络):从 在 ,意味着影响 上 ... 如果边缘是非方向性或双向的,那么我们就无法唯一地定向它,这意味着:
- 或可用数据不足以建立方向,
- 还是不可能,因为仅使用可观察的数据才能建立真正的因果图,直到最高等价类。
FCI算法也将产生PAG,但是其中会出现一种新型的边缘-末尾带有“ o”。这意味着箭头可能存在或可能不存在。在这种情况下,FCI算法与PC之间最重要的区别在于,双向(带有两个箭头)的边缘清楚地表明,与其相连的顶点是某些无法观察到的顶点的结果。因此,PC算法中的双边缘现在看起来像带有两个“ o”端的边缘。带有综合示例的沙盒中就是这种情况的说明。
修改边缘方向算法
经典方法具有一个明显的缺点。他们承认可能存在未知因素,但同时又依赖于另一个过于严肃的假设。其本质是条件独立性测试的功能应该是完善的。否则,该算法不对自身负责,也不保证图形的正确性或完整性(事实上,如果不违反正确性,就无法定向更多的边)。您知道许多理想的有限样本条件独立性测试吗?我不是
尽管存在此缺点,但图框架的构建颇具说服力,但其方向过于激进。因此,我建议对边缘定位算法进行修改。奖励:它允许您隐式调整定向边的数量。为了清楚地说明其本质,在这里有必要详细讲解因果联系的算法。因此,我将分别附上该算法的理论和建议的修改-文章的链接将在文章结尾处。
比较模型-1:图似然估计
奇怪的是,推导因果关系的最大困难之一就是模型的比较和评估。这是怎么发生的?关键是通常不知道真实数据的真正因果关系。而且,我们不能准确地知道它的分布以至于不能从中产生真实的数据。也就是说,对于大多数数据集而言,基本事实是未知的。因此,出现了一个难题:使用具有已知基础事实的(半)合成数据,或尝试在没有基础事实的情况下进行操作,而是对真实数据进行测试。在我的工作中,我尝试实现两种测试方法。
第一个是图形似然估计:

这里 -许多顶点父母 , -数量的联合信息 和 和 是数量的熵 ...实际上,第二项不依赖于图的结构,因此通常只考虑第一项。但是您会看到,添加新边缘不会降低可能性-比较时必须考虑到这一点。
重要的是要理解,这种评估仅适用于比较贝叶斯网络(PC算法的输出),因为在实际的PAG(FCI,FCI +算法的输出)中,双边语义完全不同。
因此,我将边缘的方向与我的算法和经典PC
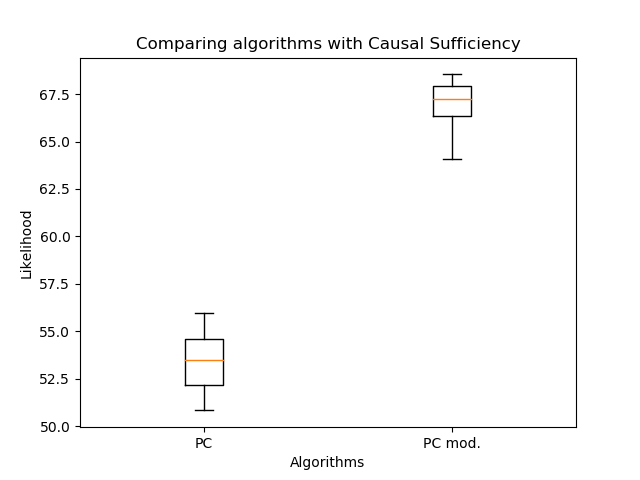
进行了比较:与经典算法相比,修改后的边缘方向极大地提高了可能性。但是现在比较边缘的数量很重要:
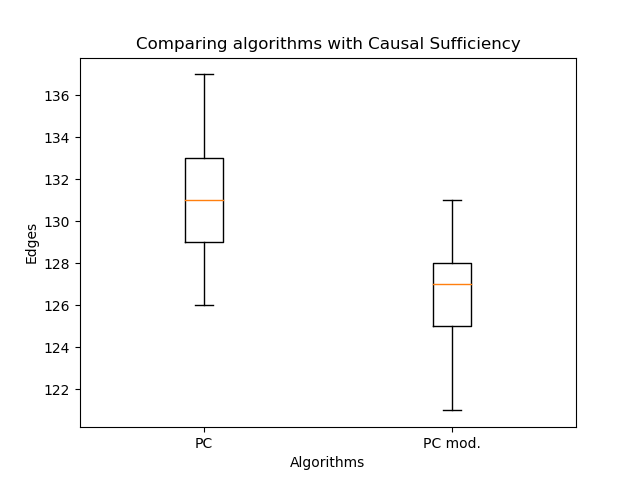
它们甚至更少-这是预期的。因此,即使边缘较少,也可以恢复更合理的图形结构!在这里您可能会说,可能性不会随着边的数量而减少。关键是,通常情况下所得的图不是通过经典PC算法获得的图的子图。可能会出现双边缘而不是单边缘,并且单边缘可能会改变方向。所以没有手工艺品!
比较模型-2:使用分类方法
让我们继续第二种比较方法。我们将使用PC算法构造因果图,并从中选择随机无环图。之后,我们将每个顶点处的数据生成为父顶点处的值与系数的线性组合加上高斯噪声。我从“迈向业务应用程序的稳健而全面的因果发现”一文(Borboudakis等,2016)中汲取了这一代的想法。没有父级的顶点是从正态分布生成的-参数与相应顶点的数据集中相同。
接收到数据后,我们将应用要评估的算法。而且,我们已经有了一个真正的因果图。剩下的只是了解如何将结果图与真实图进行比较。在“基于条件两点和三点信息的因果图形模型的稳健重构”(Affeldt等人,2015)中,建议使用分类术语。我们将假定绘制的边为正类,未绘制的边为负。然后是真正的积极()是当我们绘制与真实因果图相同的边缘并且False Positive()-如果绘制的边缘不在真正的因果图中。我们将从骨骼的角度评估这些值。
考虑到方向,我们介绍用于正确显示但方向错误的边缘。之后,我们将这样考虑:
那你就可以读 -调整骨架的尺寸并考虑到方向(显然,在这种情况下,它的高度不会高于骨架的尺寸)。但是,在PC算法的情况下,双重优势增加了 只要 , 但不是 ,因为仍然可以推断出真实边缘之一(没有因果关系,这是错误的)。
最后,让我们比较一下算法:

前两张图比较了PC算法的骨架:经典算法和新的边缘方向。它们需要显示上边界措施。后两者正在比较这些算法的方向。如您所见,没有胜利。
比较模型-3:关闭因果关系
现在,让我们在生成后“关闭”真实图形和综合数据中的一些变量。这将关闭因果关系。但是有必要将结果与真实图形进行比较,而不是与真实图形进行比较:
- 隐藏顶点的父代的边缘将被其子代吸引,
- 用双边缘连接隐藏顶点的所有子代。
我们已经比较了FCI +算法(具有改进的边缘方向和经典方法):

现在,当不满足因果关系时,新方向的结果会更好。
出现了另一个重要的观察结果-PC和FCI算法实际上建立了几乎相同的框架。因此,我将它们的输出与我在工作中提出的边缘方向进行了比较。
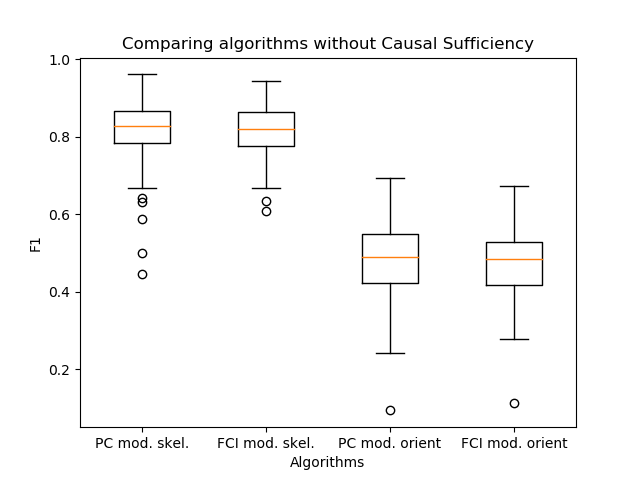
事实证明,这些算法实际上在质量上没有区别。在这种情况下,PC是FCI内部骨架构造算法的一个步骤。因此,与FCI算法一样,使用定向PC算法是提高链接推理速度的好方法。
输出量
我将简要总结一下我们在本文中讨论的内容:
- 大型IT公司中如何产生因果关系的任务。
- 什么是虚假关联以及它们如何干扰特征选择。
- 存在哪些推理链接算法,并且使用最频繁。
- 导出因果图时会遇到什么困难?
- 因果图的比较是什么以及如何处理。
如果您对因果推理主题感兴趣,请参阅我的另一篇文章-其中有更多理论。在这里,我详细介绍了链接推断中使用的基本术语,以及经典算法的工作原理以及我提出的边缘方向。