
近年来的深度学习取得了一系列连续的成就:从在Go游戏中击败人们到在图像识别,语音识别,文本翻译和其他任务方面处于世界领先地位。但是,随着这种进步,对计算能力的需求也不断提高。麻省理工学院,韩国永濑大学和巴西利亚大学的一组科学家发表了对1,058篇有关机器学习的科学论文的荟萃分析。它清楚地表明,机器学习(ML)的进步是系统计算能力的衍生。计算机性能一直限制着ML的功能,但是现在新ML模型的需求增长比计算机性能快得多。
该研究表明,机器学习的进步实际上只是摩尔定律的结果。因此,由于计算机的物理限制,许多机器学习问题将永远无法解决。
研究人员分析了有关图像分类(ImageNet),对象识别(MS COCO),问答(SQuAD 1.1),命名实体识别(COLLN 2003)和机器翻译(WMT 2014 En-to-Fr)的科学论文。

计算查询ML,日志规模
在所有五个领域中的进步已显示出高度依赖于计算能力的提高。通过这种关系推断,很明显,这些领域的进步在经济,技术和环境上正变得不可持续。因此,这些应用程序的进一步发展将需要显着提高计算效率的方法。
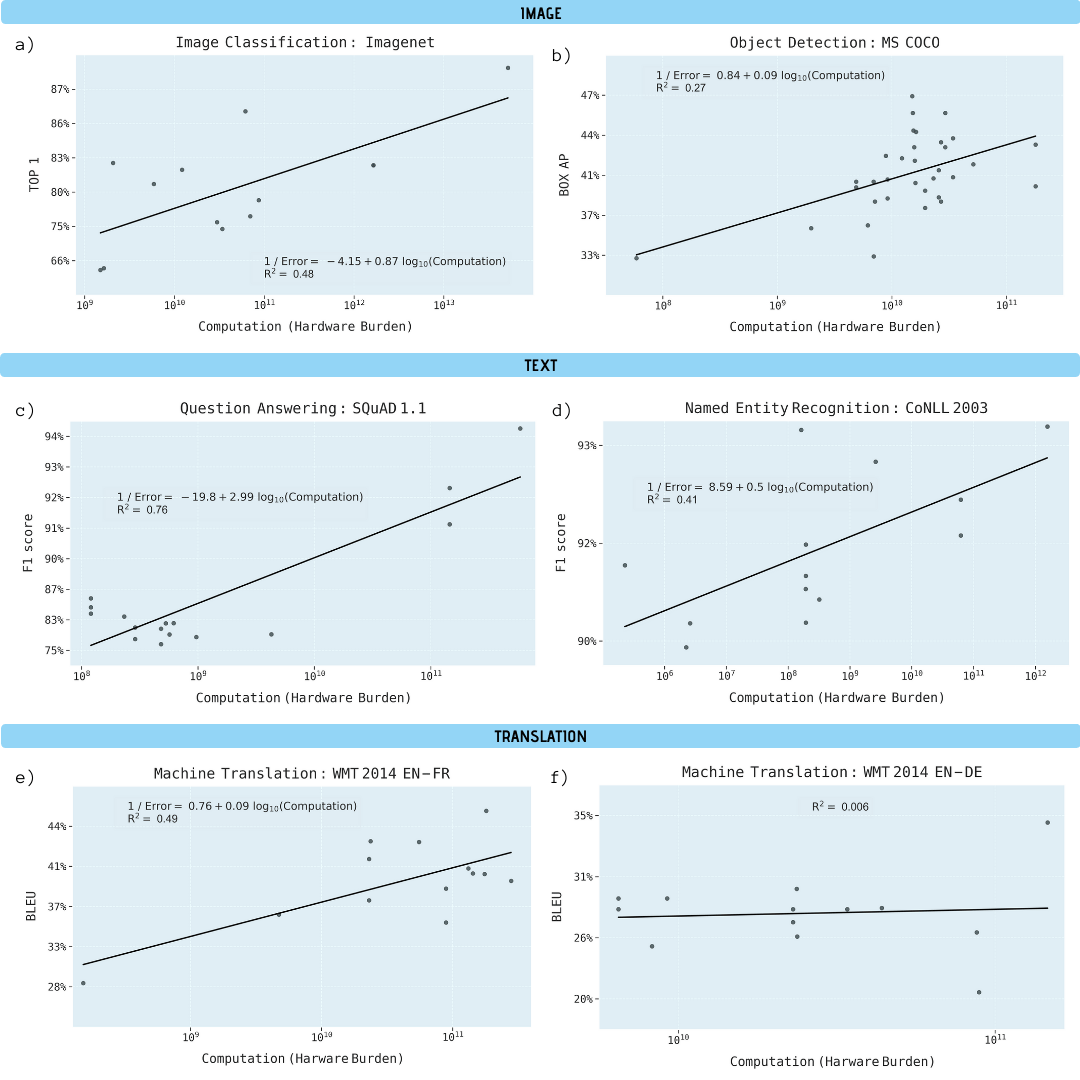
与学习模型的计算能力有关的各种机器学习任务的性能改进(以千兆字节为单位)
为什么机器学习如此依赖计算能力
有重要的理由认为,深度学习本质上比其他方法更依赖于计算。特别是,由于超参数化的作用以及系统的扩展规模,在使用其他训练数据来提高结果质量时(例如,减少分类错误的频率,回归的均方根误差等)
业已证明,超参数化具有显着的优势,即,与可用于训练的数据点数量相比,具有更多参数的神经网络的实现。传统上,这将导致过度拟合。但是随机梯度优化技术以牺牲早期停止为代价提供了正则化效果,将神经网络置于插值模式,在该模式下训练数据几乎完全适合,同时仍在中间点保持合理的预测。具有超参数化的大规模网络的一个示例是最佳的模式识别系统NoisyStudent之一,该系统具有4.8亿个参数,可处理120万个ImageNet数据点。
超参数化的问题在于,深度学习参数的数量必须随着数据点数量的增长而增长。由于训练深度学习模型的成本与参数数量和数据点数量的乘积成比例,因此这意味着在超参数化系统中,计算需求至少增长了数据点数量的平方。二次缩放尚未充分估计深度学习网络需要增长的速度,因为训练数据的数量必须比线性缩放快得多,才能获得线性性能改进。
考虑一个生成模型,该模型在可能的1000个值中具有10个非零值,并考虑使用四个模型来尝试发现这些参数:
- : 10
- : 9 1
- : 1000 ,
- : , 1000 , ()
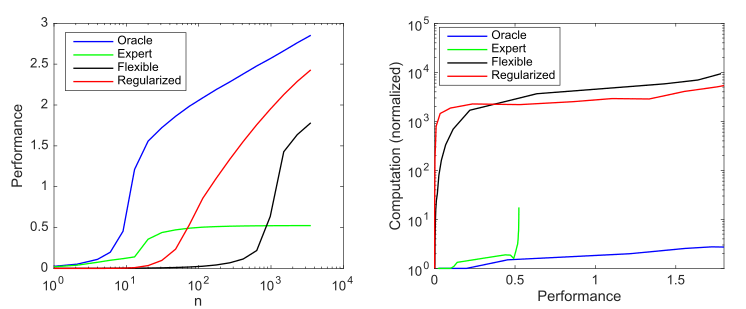
模型复杂度和正则化对模型性能的影响(以对数10归一化均方根误差与最佳预测变量的对数进行衡量)以及对每个案例平均超过1000次仿真的计算需求; a)随着样本数量的增加,平均生产率; b)提高性能所需的平均计算
该图总结了Andrew Ng概述的原理:传统的机器学习方法在小数据上更有效,而灵活的ML模型在大数据上更有效。敏捷模型的常见现象是它们具有更高的潜力,但同时也具有更多的数据和计算需求。
我们可以看到深度学习之所以行之有效,是因为它使用超参数化来创建非常灵活的模型,并使用(隐式)正则化将样本复杂度降低到可接受的水平。但是,与此同时,深度学习比更有效的模型在计算上的消耗要大得多。因此,增加ML的灵活性意味着要依赖大量数据和计算。
计算极限
计算机性能始终限制了ML系统的功能。
例如,弗兰克·罗森布拉特(Frank Rosenblatt)在1960年描述了第一个三层神经网络。希望她能够“展示使用感知器作为模式识别设备的可能性”。但是罗森布拉特发现“随着网络连接数量的增加,典型的数字计算机上的负载很快就会变得过大。” 1969年晚些时候,Minsky和Papert解释了三层网络的局限性,包括无法学习简单的XOR函数。但是他们指出了一个潜在的解决方案:“实验人员找到了一种有趣的方法,可以通过引入更长的中间单元链来解决这一难题”(即通过构建更深的神经网络)。尽管有这种潜在的解决方法,但该领域的许多学术工作已被放弃。因为那时根本没有足够的计算能力。
在随后的几十年中,硬件的改进导致性能提高了大约50,000倍,并且神经网络按比例增加了其计算需求,如KDPV中所示。由于计算能力每增加1美元,大约与每个芯片的计算能力相匹配,因此运行这些模型的经济成本在很大程度上一直保持稳定。
尽管CPU有了如此显着的加速,但对于2009年的大规模应用而言,深度学习模型仍然太慢。这迫使研究人员专注于较小规模的模型或使用较少的训练示例。
转折点是深度学习向GPU的转移,这立即加速了GPU的发展。5-15倍,到2012年已增长到35倍,这为AlexNet在2012年Imagenet竞赛中赢得了重要胜利。但是图像识别只是深度学习系统获胜的第一个基准。他们很快在对象检测,命名实体识别,机器翻译,问题回答和语音识别方面取得了成功。
在GPU(然后是ASIC)上引入深度学习导致了这些系统的广泛采用。但是现代ML系统中的计算能力增长速度甚至更快,从2012年到2019年每年大约增长10倍。这一速度远高于迁移到GPU的总体速度,摩尔定律最后一次喘息的适度收益或神经网络训练效率的提高。
取而代之的是,机器学习效率的主要提高来自更长的时间在更多机器上运行模型。例如,2012年AlexNet在两个GPU上进行了5-6天的培训,2017年ResNeXt-101在八个GPU上进行了10天以上的培训,2019年NoisyStudent在大约一千个TPU上进行了6天的培训。另一个极端的例子是Evolved Transformer机器翻译系统,该系统在培训中使用了超过200万个GPU小时,花费了数百万美元。
从长远来看,通过增加硬件时钟或更多芯片来扩展深度学习计算是有问题的。因为这意味着成本的增长速度与计算能力的增长速度大致相同,并且很快就无法实现进一步的增长。
未来
从上面可悲的结论。
下表显示了如果我们从当前模型中推断出,系统将在ML问题中实现某些目标的系统计算能力和成本。 机器学习任务将在功能最强大的超级计算机上运行。 科学工作的作者认为设定目标的要求将无法满足。尽管他们正在考虑实现这些目标的理论上可行的选择:在不提高性能的情况下提高效率,诸如TPU和FPGA的硬件加速器,神经形态计算,量子计算等,但这些技术(尚未)都无法让您克服ML的计算限制。

. .
