假设我们有一个操作员或会计师在VLSI中使用的文档记录,如下所示: 传统上,这种显示使用按日期(在创建文档时分配的日期和顺序标识符)排序的直接(新底部)或反向(新顶部)排序-或者... 我已经在文章PostgreSQL反模式:浏览注册表中讨论了在这种情况下出现的典型问题。但是,如果用户出于某种原因想要“非典型”怎么办?例如,将一个字段“像这样”排序,而另一个“像那样”排序-

ORDER BY dt, idORDER BY dt DESC, id DESC
ORDER BY dt, id DESC?但是我们不想创建第二个索引,因为它会减慢数据库中的插入和额外的卷。
是否可以仅使用索引来有效解决此问题
(dt, id)?
首先,让我们概述一下索引的排序方式:
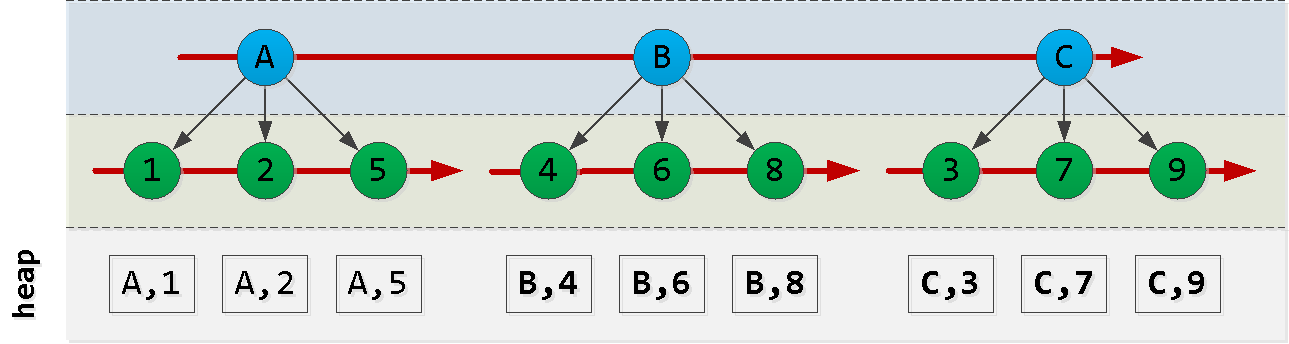
请注意,id记录的创建顺序不一定与dt的顺序匹配,因此我们不能依靠它,因此我们必须发明一些东西。
现在,假设我们位于(A,2)点,并且想要读取排序中的“ next” 6个条目: 啊哈!我们从第一个节点中选择了一个“片断”,从最后一个节点中选择了另一个“片断”,并从它们之间的节点中选择了所有记录()。尽管顺序不太合适,但每个这样的块都可以通过索引成功读取。 让我们尝试构建如下查询:
ORDER BY dt, id DESC
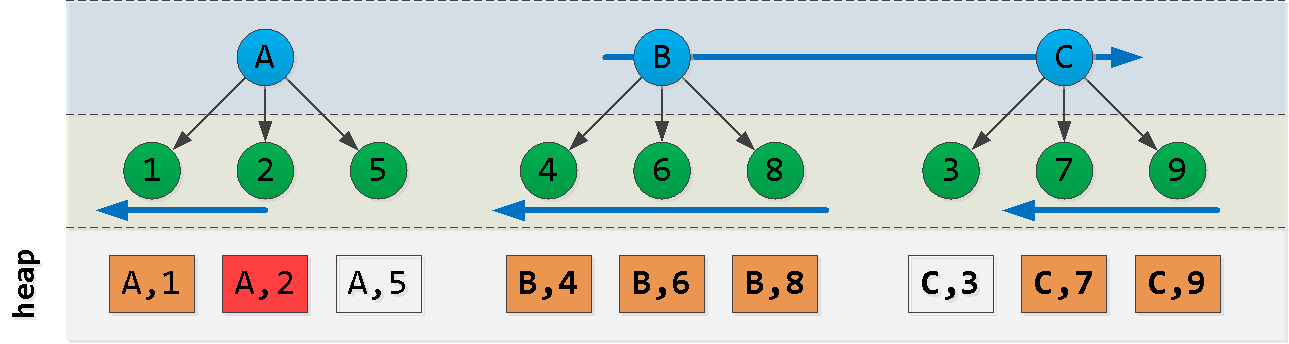
ACB(dt, id)
- 首先,我们从起始记录“左”的块A中读取-我们得到
N记录 - 此外,我们读取
L - N值A的“右侧” - 我们在最后一块找到最大密钥C
- 用此键过滤掉先前选择的所有记录,并在“右边”减去它
现在,让我们尝试在代码中进行描述并检查模型:
CREATE TABLE doc(
id
serial
, dt
date
);
CREATE INDEX ON doc(dt, id); --
-- ""
INSERT INTO doc(dt)
SELECT
now()::date - (random() * 365)::integer
FROM
generate_series(1, 10000);为了不计算已读记录的数量以及它与目标数量之间的差,我们将强制PostgreSQL使用“ hack”
UNION ALL和LIMIT:
(
... LIMIT 100
)
UNION ALL
(
... LIMIT 100
)
LIMIT 100现在,让我们从最近的已知值中收集目标排序的以下100条记录:
(dt, id DESC)
WITH src AS (
SELECT
'{"dt" : "2019-09-07", "id" : 2331}'::json -- ""
)
, pre AS (
(
( -- 100 "" "" A
SELECT
*
FROM
doc
WHERE
dt = ((TABLE src) ->> 'dt')::date AND
id < ((TABLE src) ->> 'id')::integer
ORDER BY
dt DESC, id DESC
LIMIT 100
)
UNION ALL
( -- 100 "" "" A -> B, C
SELECT
*
FROM
doc
WHERE
dt > ((TABLE src) ->> 'dt')::date
ORDER BY
dt, id
LIMIT 100
)
)
LIMIT 100
)
-- C ,
, maxdt AS (
SELECT
max(dt)
FROM
pre
WHERE
dt > ((TABLE src) ->> 'dt')::date
)
( -- "" C
SELECT
*
FROM
pre
WHERE
dt <> (TABLE maxdt)
ORDER BY
dt, id DESC -- , B
LIMIT 100
)
UNION ALL
( -- "" C 100
SELECT
*
FROM
doc
WHERE
dt = (TABLE maxdt)
ORDER BY
dt, id DESC
LIMIT 100
)
LIMIT 100;让我们来看一下发生了什么:

[查看explain.tensor.ru]
- 因此,
A = '2019-09-07'我们使用第一个键读取了3条记录。 - 他们完成阅读另一个97
B,并C因准确命中Index Scan。 - 在所有记录中,有18条被最大键过滤
C。 - 我们
Bitmap Scan使用最大键读取了23条记录(而不是18条记录)。 - 全部重新排序并削减了目标100条记录。
- ...花费的时间不到一毫秒!
该方法当然不是通用的,并且在大量字段上使用索引会变成非常糟糕的事情,但是如果您真的想为用户提供一种``非标准''排序而又不将基础``折叠''到
Seq Scan一个大表中,则可以谨慎地使用它。