
我们重新开始讨论数据科学家系列的笔记,今天,我介绍我绝对主观的清单,以选择机器学习模型。
这些是问题的前10个属性,仅是要点(没有顺序),从我的角度出发,我开始选择模型,并且通常对数据分析任务进行建模。
您完全不必拥有相同的功能-这里的一切都是主观的,但是我分享我的生活经验。
我们的总体目标是什么?可解释性和准确性-频谱

来源
也许数据科学家在开始建模之前面临的最重要的问题是:
确切地说,业务任务是什么?
或研究,如果我们谈论的是学院等。
例如,我们需要基于数据模型的分析,反之亦然,我们只对电子邮件是否为垃圾邮件的定性预测感兴趣。
我看到的经典平衡是方法的可解释性与其准确性之间的频谱(如上图所示)。
但是实际上,您不仅需要驱动Catboost / Xgboost / Random Forest并选择一个模型,还需要了解企业的需求,我们拥有的数据以及如何应用它们。
在我的实践中,这将立即在可解释性和准确性(无论在这里是什么意思)的范围内设定一个要点。基于此,人们已经可以考虑对问题进行建模的方法。
任务本身的类型
此外,在了解了业务需求之后-例如,我们需要了解我们属于什么数学类型的机器学习问题
- 探索性分析-纯粹分析可用数据并坚持到底
- 群集-根据一些常用属性将数据收集到组中
- 回归-您需要返回整数结果,否则有可能发生事件
- 分类-您需要返回一个类别标签
- 多标签-您需要为每个条目返回一个或多个类标签
示例
数据:有两个类和一个未标记的记录集:

您需要建立一个模型来标记这些数据:

或者,作为一种选择,没有标签,您需要选择组:

像这里:来自这里的
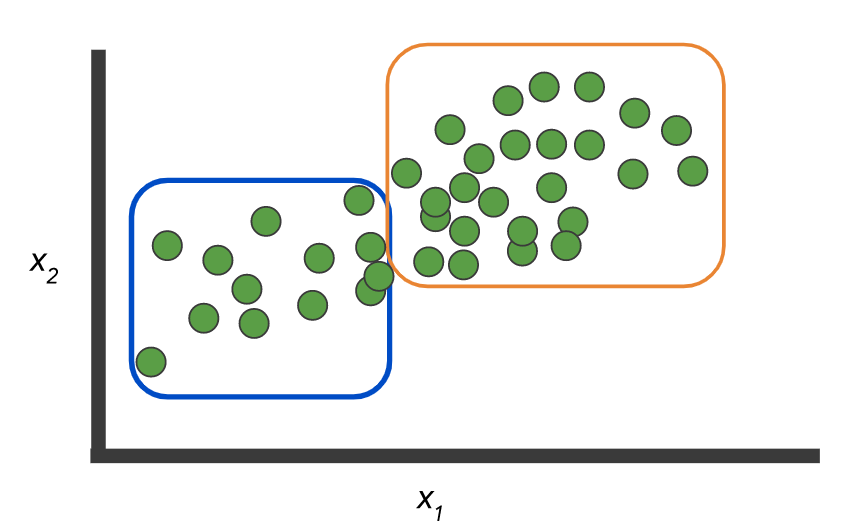
图片。 但是示例本身说明了这两个概念之间的区别:分类,当N> 2类时-多类vs. 多标签 两者从这里 你会惊讶,但很多时候这点也值得直接对话的业务-这真的可以节省你大量的时间和精力。随意绘制图片并给出简单的示例(但不要过于简单)。
准确性及其确定方式
我从一个简单的例子开始,如果您是一家银行并发放贷款,那么在不成功的贷款上,我们的损失是成功贷款的五倍。
因此,衡量工作质量的问题是首要的!或假设您的数据存在严重失衡,A类= 10%,B类= 90%,那么仅返回B的分类器的准确率始终为90%!训练模型时,这很可能不是您想要看到的。
因此,定义模型评分指标至关重要,包括:
- 体重等级-如上例所示,不良信用为5,良好信用为1
- 成本矩阵-有可能混淆中低风险-没关系,但是低风险和高风险已经成为问题
- 指标应该反映平衡吗?例如ROC AUC
- 我们通常计算概率还是类标签是直的?
- 或者,也许班级通常是“一个”,而我们有精度/召回率和其他游戏规则?
通常,度量标准的选择由任务及其制定方式决定-对于设置此任务的人员(通常是商人),所有这些细节都需要澄清和阐明,否则输出中将出现接缝。
模型后期分析
通常有必要基于模型本身进行分析。例如,不同功能对原始结果的贡献是:通常,大多数方法可以产生类似于以下内容的结果:
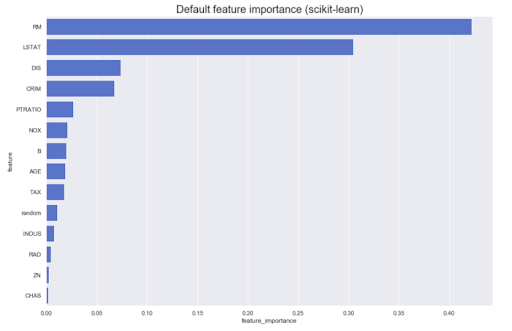
但是,如果我们需要知道方向-属性A的较大值会增加对类Z的归属,反之亦然呢?让我们称它们为有向特征的重要性-它们可以从某些模型中获得,例如线性模型(通过归一化数据上的系数);
对于许多基于树和增强的模型,例如,SHapley Additive exPlanations方法是合适的。
夏普
这是一种模型分析方法,可让您查看模型的内部。
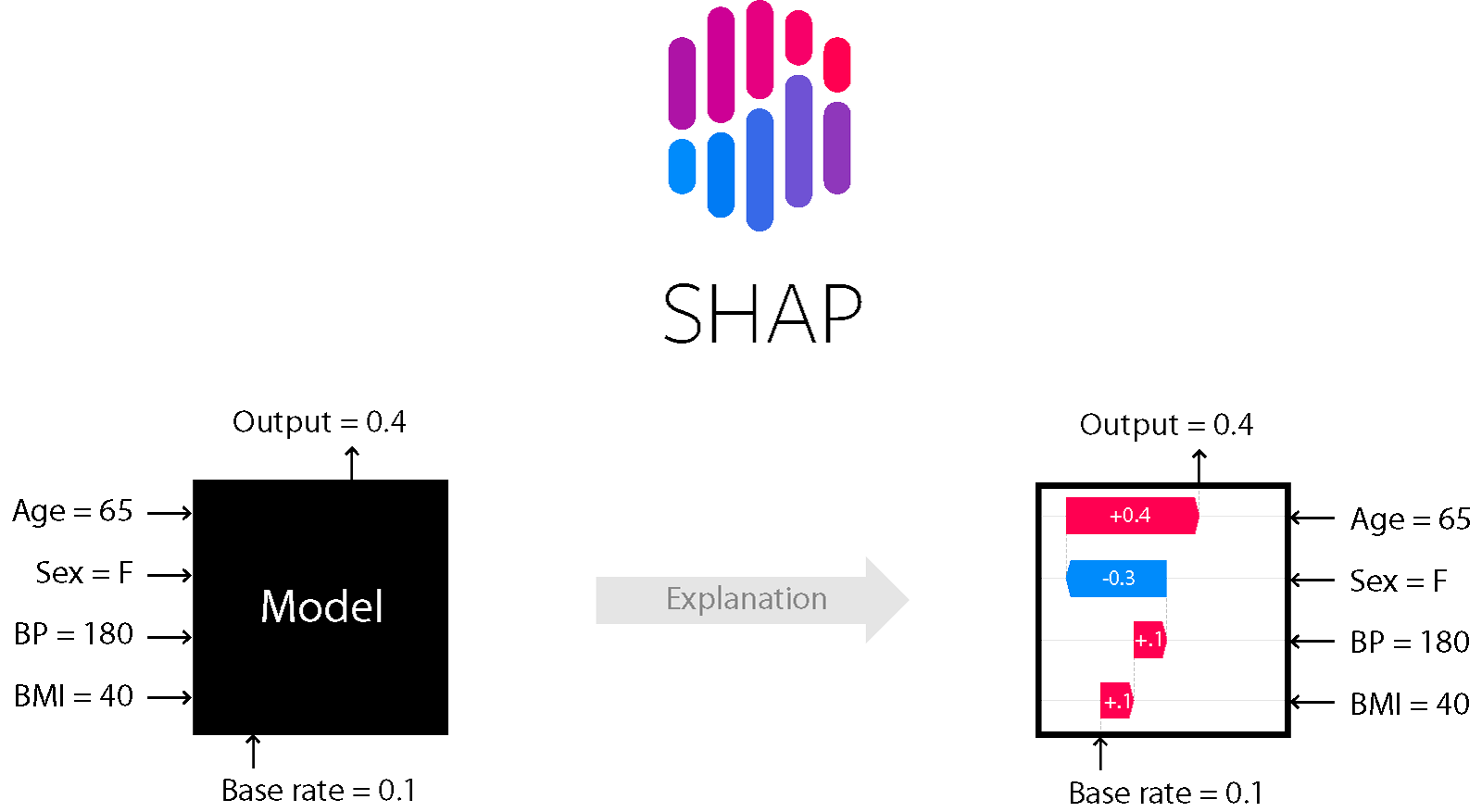
它允许您评估效果的方向:

此外,对于树木(以及基于树木的方法)来说是准确的。在此处了解更多信息。
噪声水平-稳定性,线性相关性,离群值检测等
耐噪音和所有这些生活乐趣是一个单独的主题,您需要仔细分析噪音水平,并选择适当的方法。如果您确定数据中会有异常值,则需要正确清理它们并应用抗噪声的方法(高偏差,正则化等)。
同样,符号可能是共线的,并且可能出现无意义的符号-不同的模型对此反应不同。这是经典的德国信用数据(UCI)数据集和三个简单的(相对)学习模型的示例:
- Ridge回归分类器:使用Tikhonov正则化器进行经典回归
- 装饰树
- Yandex的CatBoost
岭回归
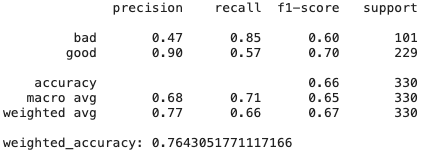
# Create Ridge regression classifier
ridge_clf = RidgeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
ridge_model = ridge_clf.fit(X_train, y_train)
y_pred = ridge_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
决策树
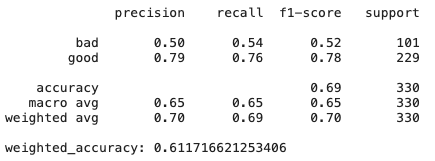
# Create Ridge regression classifier
dt_clf = DecisionTreeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
dt_model = dt_clf.fit(X_train, y_train)
y_pred = dt_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:", weighted_accuracy(y_test,y_pred))
猫助推器

# Create boosting classifier
catboost_clf = CatBoostClassifier(class_weights=class_weight, random_state=42, cat_features = X.select_dtypes(include=['category', object]).columns)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
# Train model
catboost_model = catboost_clf.fit(X_train, y_train, verbose=False)
y_pred = catboost_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
正如我们所看到的,仅具有高偏差和正则化的岭回归模型显示的结果甚至比CatBoost还要好-许多功能不是非常有用且共线,因此可以抵抗它们的方法显示出良好的结果。
有关DT的更多信息-如果稍微更改数据集怎么办?特征重要性可能会有所不同,因为决策树通常是敏感方法,甚至对于数据混洗也是如此。
结论:有时候越轻松越好,越有效。
可扩展性
您是否真的需要具有数十亿个参数的Spark或神经网络?
首先,您需要明智地评估数据量,我们已经看到Spark大量使用在容易适应一台机器内存的任务上。
Spark使调试复杂,增加了开销并使开发复杂化-您不应在不需要的地方使用它。经典。
其次,当然,您需要评估模型的复杂性并将其与任务相关联。如果您的竞争对手表现出色,并且他们正在运行RandomForest,那么如果您需要一个具有数十亿个参数的神经网络,则可能需要三思而后行。
当然,您需要考虑到,如果您确实有大量数据,那么该模型必须能够处理这些数据-如何从批处理中学习,或者具有某种分布式学习机制(等等)。并且在同一地方,当数据量增加时,速度不要损失太多。例如,我们知道内核方法在双空间中需要一个平方的内存来进行计算-如果您希望数据大小增加10倍,那么您应该三思而后行,确定是否适合可用资源。
现成模型的可用性
另一个重要的细节是搜索可以预先训练的已经训练好的模型,如果满足以下条件,则是理想选择:
- 没有很多数据,但是它们非常适合我们的任务-例如医学文本。
- 通常,主题相对比较流行-例如,突出显示文本主题-NLP中的许多作品。
- 您的方法原则上可以进行预学习-例如使用某种类型的神经网络。
像GPT-2和BERT这样的经过预训练的模型可以大大简化问题的解决方案,并且如果已经存在经过训练的模型,我强烈建议您不要忽略并抓住这次机会。
特征相互作用和线性模型
当要素之间没有复杂的交互时,某些模型会更好地工作-例如,整个线性模型-广义加性模型。这些模型的扩展适用于称为GA2M的两个功能-具有成对相互作用的通用加性模型的相互作用。
通常,此类模型在此类数据上显示出良好的结果,具有出色的正则化,可解释性和对噪声的鲁棒性。因此,绝对值得关注它们。
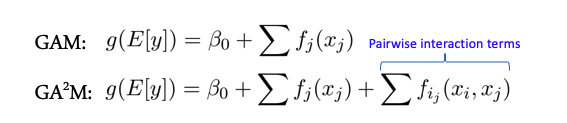
但是,如果符号主动地以大于2的组进行交互,则这些方法将不再显示出如此好的效果。
包装和型号支持
本文中许多很酷的算法和模型都被设计为python,R等的模块或包。从长远来看,在使用和依赖这种解决方案之前,真的值得三思。一年中零支持的可能性非常高,因为作者现在最有可能需要从事其他项目,没有时间,也没有动机去投资模块或存储库的开发。
在这方面,la scikit学习的图书馆之所以出色,恰好是因为它们实际上有一群有保障的爱好者,并且如果某件事情受到严重破坏,则迟早会修复它们。
偏见与公平
除了自动决策外,对此类决策不满意的人也变得栩栩如生-想象一下,我们有某种排名系统,可用于申请大学的奖学金或研究资助。我们的大学将是不寻常的-只有两类学生:历史学家和数学家。如果该系统突然根据其数据和逻辑将所有补助金全部发放给历史学家,而没有将其授予任何数学家,那么这可能不会弱地冒犯数学家。他们将这种系统称为偏见。现在只有懒惰的人不会谈论这个,公司和人们正在互相起诉。
按照惯例,请想象一个简化的模型,该模型仅计算文章的引用并让历史学家互相主动引用-平均为100次引用,但没有数学,它们的平均值为20-并且他们写得很少,然后系统将所有历史学家视为“良好”,因为引用率很高100> 60(平均),而数学家则称为“差”,因为他们的引用率均远低于平均20 <60。这样的系统对于某人来说似乎并不足够。
现在,经典著作提出了与这种偏颇的方法作斗争的决策和训练模型的逻辑。因此,对于每个决定,您(有条件地)都有一个解释,说明为什么做出该决定以及如何实际努力确保该模型不做废话(ELI5 GDPR)。在这里

阅读更多来自Google的信息,或在此处的文章中。
通常,许多公司已经开始了此类活动,尤其是考虑到GDPR的发布-这种措施和检查可以帮助避免将来出现问题。
如果某个主题比其他主题更有趣-在评论中写下,我们将更深入。(DFS)!
