
早在2020年4月,Citizenlab报告了对Zoom的相当弱的加密,并指出Zoom使用的是SILK音频编解码器。不幸的是,本文没有包含原始数据来确认这一点,并让我有机会在以后引用它。然而,由于娜塔莉Silvanovich从谷歌的Project Zero使用Frida跟踪工具,我可以转储一些原始的SILK帧。他们的分析促使我研究了WebRTC如何处理音频。一般而言,在可感知的通话质量方面,影响最大的是音频质量,因为我们倾向于注意到很小的毛刺。仅十秒钟的分析就足以开始一场真正的冒险-寻找提高WebRTC提供的声音质量的选择。
我在2017年处理原生的Zoom客户端(在DataChannel发布之前),并注意到与基于WebRTC的解决方案包相比,其音频包有时非常大:

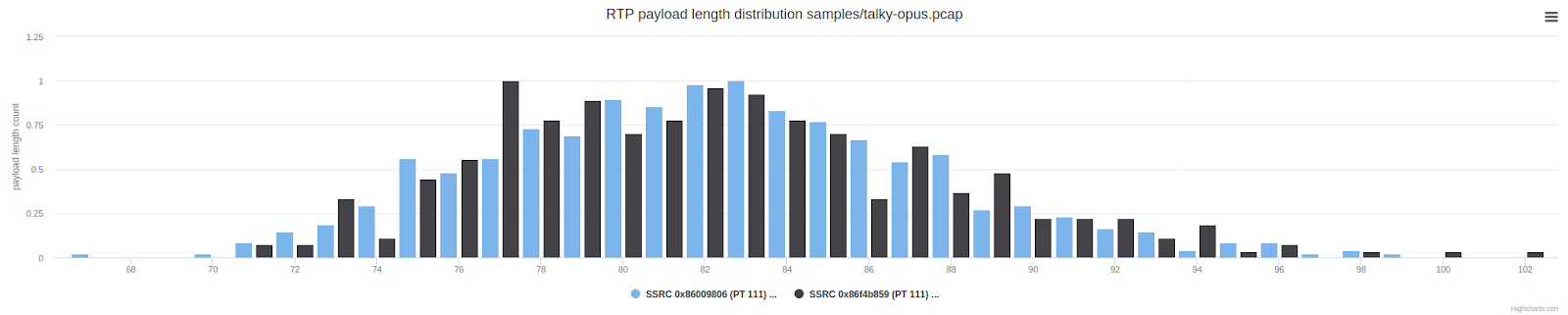
上图显示了具有特定UDP有效负载长度的数据包数量。与典型的WebRTC调用相比,介于150到300字节之间的数据包是不寻常的。它们比我们通常从Opus获得的数据包更长。我们怀疑存在前向错误控制(FEC)或冗余,但是如果无法访问未加密的帧,则很难得出进一步的结论或执行某些操作。
新转储中未加密的SILK帧显示了非常相似的分布。将帧转换为文件后,然后播放一条短消息(感谢Giacomo Vacca提供了非常有用的博客文章描述必要的步骤),我回到Wireshark并查看了软件包。这是我发现特别有趣的三个软件包的示例:
packet 7:
e9e4ab17ad8b9b5176b1659995972ac9b63737f8aa4d83ffc3073d3037b452fe6e1ee
5e6e68e6bcd73adbd59d3d31ea5fdda955cbb7f
packet 8:
e790ba4908639115e02b457676ea75bfe50727bb1c44144d37f74756f90e1ab926ef
930a3ffc36c6a8e773a780202af790acfbd6a4dff79698ea2d96365271c3dff86ce6396
203453951f00065ec7d26a03420496f
packet 9:
e93997d503c0601e918d1445e5e985d2f57736614e7f1201711760e4772b020212dc
854000ac6a80fb9a5538741ddd2b5159070ebbf79d5d83363be59f10ef
e790ba4908639115e02b457676ea75bfe50727bb1c44144d37f74756f90e1ab926ef
930a3ffc36c6a8e773a780202af790acfbd6a4dff79698ea2d96365271c3dff86ce6396
203453951f00065ec7d26a03420496f
e9e4ab17ad8b9b5176b1659995972ac9b63737f8aa4d83ffc3073d3037b452fe6e1ee
5e6e68e6bcd73adbd59d3d31ea5fdda955cbaef程序包9包含两个先前的程序包,程序包8-1先前的程序包。这种冗余是由于使用LBRR(低比特率冗余)格式所引起的,该格式已通过对SILK解码器的深入研究得到证明(可以在Skype团队提供的Internet项目中或在GitHub上的存储库中找到):

Zoom使用SKP_SILK_LBRR_VER1,但具有两个后备程序包。如果每个UDP数据包不仅包含当前音频帧,还包含前两个音频帧,则即使丢失了三个数据包中的两个,它也将很健壮。因此,也许缩放音质的关键是祖母的Skype秘诀?
Opus FEC
如何使用WebRTC达到相同的目的?下一步显然是考虑Opus FEC。
在Opus中也发现了SILK的LBRR(低速率保留)(请记住,Opus是一种混合编解码器,它在比特率范围的下限使用SILK)。但是,Opus SILK与原始SILK有很大不同,原始SILK的源代码是Skype曾经发现的,而LBRR的一部分则用于错误控制模式。
Opus不仅在原始音频帧之后添加了错误控制,而且还在其之前并在比特流中进行了编码。我们尝试使用Insertable Streams API尝试添加自己的错误控制,但这需要完整的代码转换,才能将信息插入到实际数据包之前的比特流中。
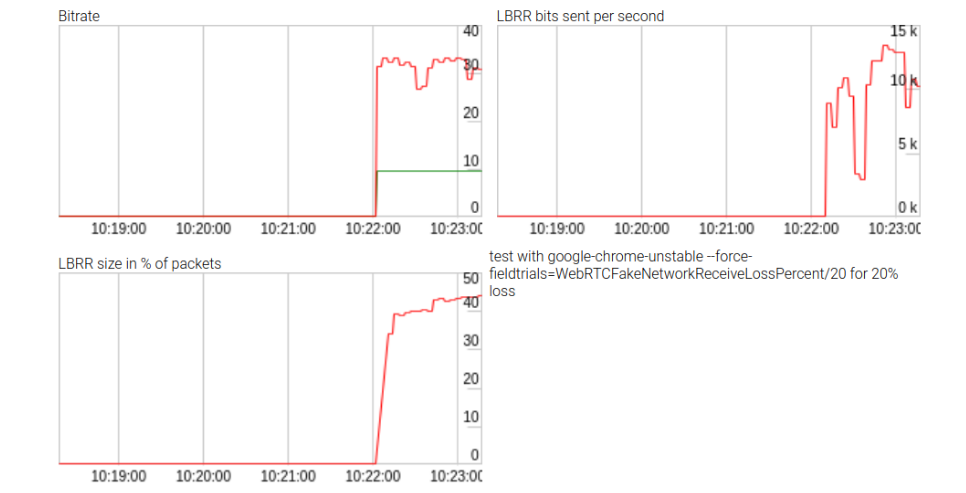
尽管努力没有成功,但它们确实生成了一些有关LBRR影响的统计数据,如上图所示。 LBRR使用高达10 kbps的比特率(或数据速率的三分之二)来处理高丢包率。该存储库位于此处。调用WebRTC
getStats() API时不显示这些统计信息,因此结果非常有趣。
转码并不是Opus FEC的唯一问题。事实证明,它在WebRTC中的设置有些用处:
- , , - . Slack 2016 . , .
- 25%. .
- FEC (. ).
从目标最大比特率中减去FEC比特率根本没有意义-FEC积极降低了主流的比特率。较低的比特率流通常导致较低的质量。如果没有可以使用FEC纠正的丢包,则FEC只会降低质量,而不会提高质量。为什么会发生?主要理论是拥塞是丢包的原因之一。如果遇到拥塞,您可能不希望发送更多数据,因为这只会使问题变得更糟。然而,正如Emil Ivov在其2017年KrankyGeek精彩演讲中所描述的那样拥塞并不总是导致丢包的原因。另外,这种方法也忽略了任何伴随的视频流。当您发送数百千位的视频以及相对较小的50kbps Opus流时,用于Opus音频的基于拥塞的FEC策略没有多大意义。也许将来我们会在libopus中看到一些变化,但是现在我想尝试禁用它,因为默认情况下WebRTC中已启用它。
我们得出结论,这不适合我们...
红
如果我们需要真正的冗余,则RTP有一个称为RTP有效负载的解决方案,用于冗余音频数据或RED。RFC 2198年代很久,始于1997年。该解决方案允许将具有不同时间戳的多个RTP有效负载以相对较低的成本放入同一RTP数据包中。
与Opus FEC相比,使用RED在每个数据包中放置一个或两个冗余音频帧将使数据包丢失的鲁棒性更高。但这只能通过将音频比特率从30 kbps翻倍或翻三倍到60或90 kbps(附加10 kbps的标头)来实现。不过,与每秒超过1兆位的视频数据相比,这还算不错。
WebRTC库包括用于RED的第二个编码器和解码器,这现在是多余的!尽管尝试删除未使用的音频红色代码,但我能够以相对较少的努力来应用此编码器。WebRTC错误跟踪系统中提供了解决方案的完整历史记录。
而且它是作为试用版提供的,当您使用以下标志启动Chrome时会包含该试用版:
--force-fieldtrials=WebRTC-Audio-Red-For-Opus/Enabled/然后可以通过SDP协商启用RED。它将显示如下:
a=rtpmap:someid red/48000/2默认情况下不启用此功能,因为在某些环境中使用额外带宽不是一个好主意。要使用RED,请更改编解码器的顺序,使其先于Opus编解码器。这可以使用API来完成
RTCRtpTransceiver.setCodecPreferences如图所示这里。显然,另一种选择是手动更改SDP。 SDP格式还可以提供一种配置最大冗余级别的方法,但是RFC 2198提供-响应语义尚不完全清楚,因此我决定将其推迟一会儿。
您可以通过在音频示例中运行来演示所有工作原理。这是带有一个备份程序包的早期版本的样子:
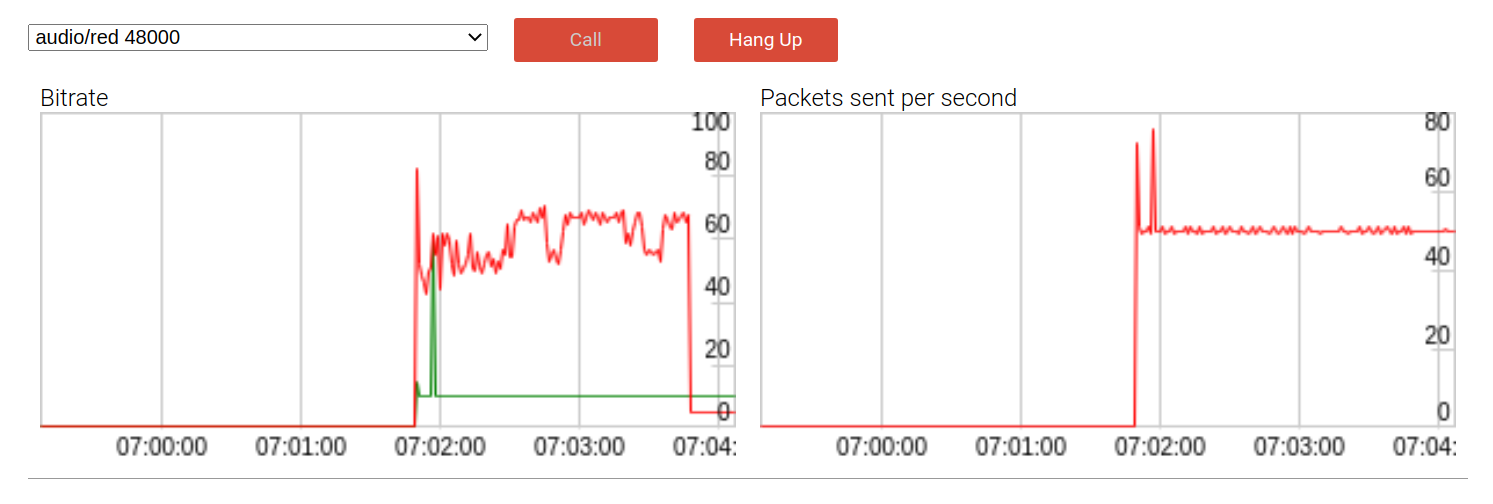
默认情况下,有效负载比特率(红线)几乎是无冗余比特率的两倍,几乎为60 kbps。DTX(不连续传输)是一种带宽节省机制,仅在检测到语音时才发送数据包。正如预期的那样,使用DTX时,比特率的影响有所减弱,正如我们在通话结束时看到的那样。
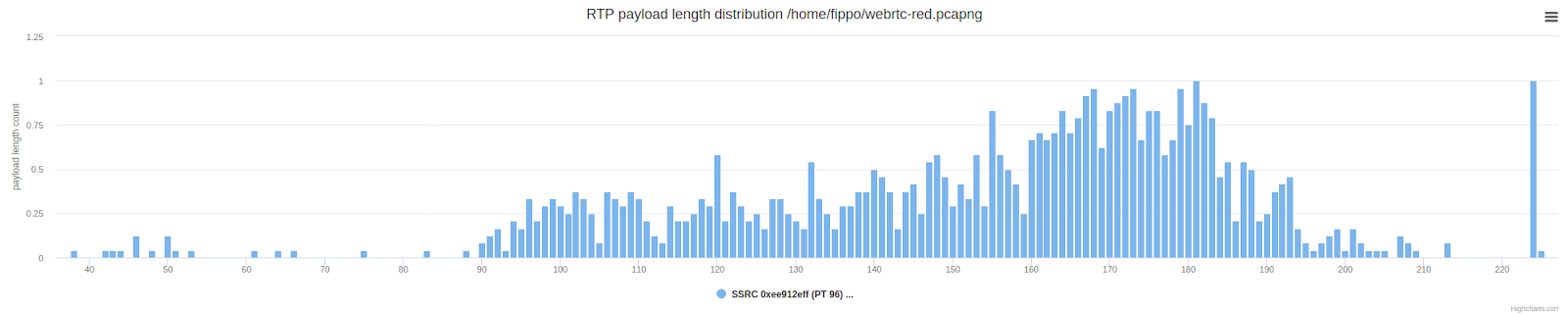
检查数据包长度显示了预期的结果:与以下所示的有效负载长度的正态分布相比,数据包的平均长度(更短)是其两倍。
这与Zoom所看到的部分保留有些许不同。让我们重新查看前面显示的Zoom数据包长度图,以进行比较:
添加语音活动检测(VAD)支持
仅当数据包中有语音活动时,Opus FEC才会发送备份数据。RED实施也应如此。为此,必须将Opus编码器更改为显示SILK级别定义的正确VAD信息。使用此设置,仅在存在语音的情况下,比特率才达到60 kbps(相比之下,恒定的60+ kbps):

并且“光谱”变得更像我们在Zoom中看到的:

实现此目的的更改尚未出现。
找到正确的距离
距离是备份数据包的数量,即当前数据包中的先前数据包的数量。在寻找正确距离的过程中,我们发现如果距离1的RED很冷,那么距离2的RED甚至更冷。我们的实验室估计模拟了60%的随机数据包丢失。在这种环境下,Opus + RED表现出色,而没有RED的Opus表现更差。所述的WebRTC getStats()API提供通过比较由获得除以隐藏样本的百分比来测量这是一个非常有用的能力concealedSamples通过totalSamplesReceived。
在音频样本页面上,可以通过将以下JavaScript代码段粘贴到控制台中来轻松检索此数据:
(await pc2.getReceivers()[0].getStats()).forEach(report => {
if(report.type === "track") console.log(report.concealmentEvents, report.concealedSamples, report.totalSamplesReceived, report.concealedSamples / report.totalSamplesReceived)})我使用一个不太知名但非常有用的标志运行了一些丢包测试
WebRTCFakeNetworkReceiveLossPercent:
--force-fieldtrials=WebRTC-Audio-Red-For-Opus/Enabled/WebRTCFakeNetworkReceiveLossPercent/20/默认情况下,在丢包率为20%且启用了FEC的情况下,音频质量差别不大,但指标略有不同:
| 情景 | 损失率 |
|---|---|
| 没有红色 | 十八% |
| 无红色,禁用FEC | 20% |
| 红色,距离1 | 4% |
| 红色,带距离2 | 0.7% |
如果没有RED或FEC,则指标几乎与请求的数据包丢失匹配。有FEC的作用,但是效果很小。
如果没有RED,则损失60%时,声音质量会变得很差,有点金属质感,并且难以理解:
| 情景 | 损失率 |
|---|---|
| 没有红色 | 60% |
| 红色,距离1 | 32% |
| 红色,带距离2 | 十八% |
在RED处,距离= 1处有一些可听见的伪影,但距离2处的声音几乎完美(这是当前使用的冗余量)。
有一种感觉,人的大脑可以承受一定程度的无规律的沉默。(而且Google Duo似乎正在使用机器学习算法来填补沉默。)
衡量现实世界中的表现
我们希望在Opus中包含RED可以改善声音质量,尽管在某些情况下可能会使情况更糟。 Emil Ivov自愿使用POLQA-MOS方法进行了几次听力测试。 Opus已经做到了这一点,因此我们有一个比较基准。
如果初始测试显示出令人鼓舞的结果,那么我们将使用上面使用的百分比损失指标在Jitsi Meet主扫描上进行大规模实验。
请注意,对于媒体服务器和SFU,启用RED有点困难,因为服务器可能需要管理RED中继以选择客户端,就像并非所有客户端都支持RED会议的情况一样。同样,某些客户端可能位于不需要RED的有限带宽信道上。如果端点不支持RED,则SFU可以删除不必要的编码,并在没有包装的情况下发送Opus。同样,它可以自己实现RED,并在从传输Opus的端点向支持RED的端点重新提交数据包时使用它。
非常感谢Jitsi / 8×8 Inc赞助这次激动人心的冒险,并感谢Google的人员分析并提供了所需更改的反馈。
如果没有Natalie Silvanovich,我将坐下来查看加密字节!