事实是,我们所有的团队都是围绕单独的信息系统,微服务和前端构建的,因此这些团队看不到整个系统的整体运行状况。例如,他们可能不知道深层后端中的一小部分会如何影响前端。他们的兴趣范围仅限于与其系统集成在一起的系统。如果团队及其服务A与服务B几乎没有任何关系,那么团队几乎看不到这样的服务。
反过来,我们的团队则使用彼此非常紧密集成的系统:它们之间有许多连接,这是一个非常大的基础架构。在线商店的工作取决于所有这些系统(顺便说一下,我们有很多系统)。
事实证明,我们的部门不属于任何团队,但是有点超然。在整个故事中,我们的任务是以复杂的方式了解信息系统的工作方式,其功能,集成,软件,网络,硬件以及所有这些如何互连。
我们的在线商店运行的平台如下所示:
- 面前
- 中间办公室
- 后台
尽我们所能,但是并没有所有系统都能流畅,完美地工作。重点再次是系统和集成的数量-尽管测试质量很高,但像我们这样的系统中,某些事件是不可避免的。而且,无论是在单独的系统中还是在它们的集成方面。而且,您需要全面监视整个平台的状态,而不是整个平台的任何单独部分。
理想情况下,应该自动化监视整个平台的运行状况。我们将监视作为此过程的必然部分。最初,它仅用于前线部分,而网络专家,软件和硬件管理员则逐层拥有自己的监视系统。所有这些人仅在自己的级别上进行监视;也没有人有全面的了解。
例如,如果虚拟机崩溃,则在大多数情况下,只有负责硬件的管理员和虚拟机才知道。在这种情况下,前台团队确实看到了应用程序崩溃的事实,但是他们没有有关虚拟机崩溃的数据。管理员可以知道客户是谁,并且可以大致想象一下当前在此虚拟机上正在运行什么,只要这是一个大型项目。他可能对小家伙们一无所知。无论如何,管理员都需要联系所有者,询问这台计算机上的内容,需要还原的内容以及要更改的内容。如果发生了非常严重的故障,他们就会开始四处乱跑-因为没人能看到整个系统。
最终,这些不同的故事会影响整个前端,用户以及我们的核心业务功能在线销售。由于我们不是团队的一部分,而是作为在线商店的一部分从事所有电子商务应用程序的操作,因此我们承担了为电子商务平台创建全面监视系统的任务。
系统结构和堆栈
我们首先强调了对系统的几层监视,在这些背景下,我们需要收集指标。所有这些都必须合并,这是我们在第一阶段所做的。现在,在这个阶段,我们正在为所有层最终确定最高质量的指标集合,以建立关联并了解系统如何相互影响。
在应用程序启动的最初阶段(由于我们在大多数系统运行时就开始构建它),缺乏全面的监视导致了这样一个事实,即我们在建立整个平台的监视方面存在巨大的技术负担。我们不能只专注于设置单个IS的监视并进行详细的监视,因为其余的系统将在一段时间内不进行监视。为了解决此问题,我们已经确定了用于评估信息系统状态的最必要指标的列表,并开始实施它。
因此,他们决定部分吃掉大象。
我们的系统包括:
- 硬件;
- 操作系统;
- 软件;
- 监视应用程序中的UI部分;
- 业务指标;
- 集成应用程序;
- 信息安全;
- 网络;
- 交通平衡器。
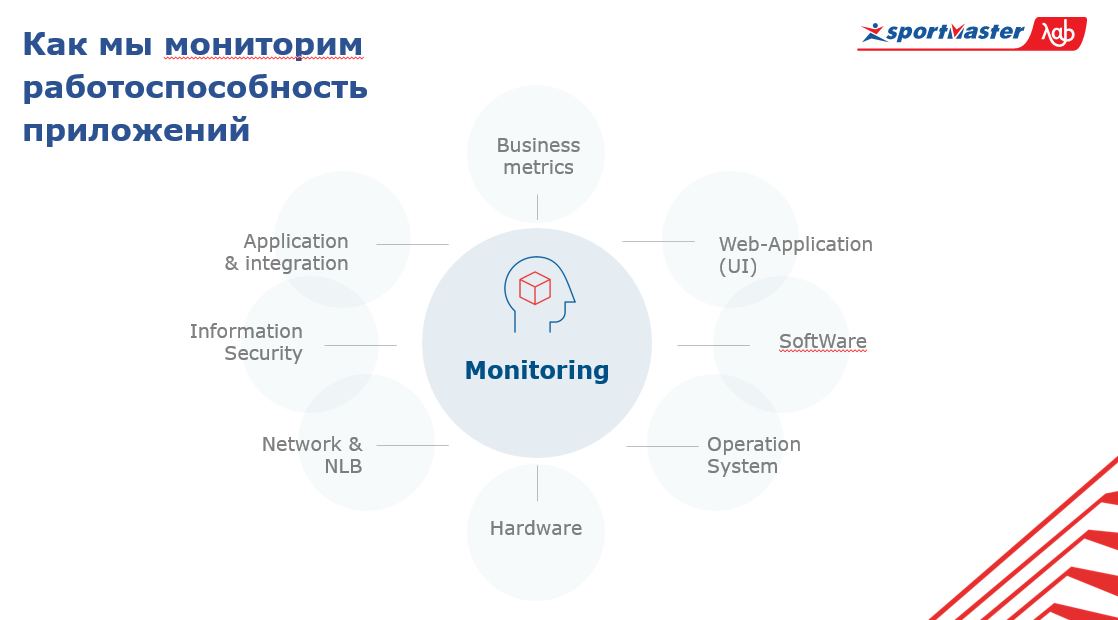
该系统的中心是监视自身。为了大致了解整个系统的状态,您需要了解所有这些层以及整个应用程序范围内应用程序的状况。
因此,关于堆栈。

我们使用开源软件。在中心,我们有Zabbix,我们主要将其用作警报系统。众所周知,这是监视基础结构的理想选择。这是什么意思?这些是每个公司拥有自己的数据中心(而Sportmaster拥有自己的数据中心)的低级指标-服务器温度,内存状态,突袭,网络设备指标。
我们已经将Zabbix与Telegram Messenger和Microsoft Teams集成在一起,它们在团队中得到了积极使用。 Zabbix涵盖了实际网络,硬件和部分软件的层,但这不是万能的。我们从其他一些服务中充实了这些数据。例如,就硬件级别而言,我们直接通过API连接到我们的虚拟化系统并收集数据。
还有什么。除了Zabbix,我们还使用Prometheus,它允许在动态环境应用程序中监视指标。也就是说,我们可以通过HTTP端点接收应用程序指标,而不必担心要向其中加载哪些指标,而不必担心。根据这些数据,您可以计算出分析查询。
其他层的数据源(例如业务指标)分为三个部分。
首先,这些是外部业务系统,即Google Analytics(分析),我们从日志中收集指标。从他们那里我们可以获得有关活跃用户,转化和与业务相关的所有其他信息的数据。其次,它是一个UI监视系统。应该更详细地描述。
曾几何时,我们从手动测试开始,现已发展为功能和集成自动测试。我们对其进行监视,仅保留主要功能,并与尽可能稳定且不会随时间变化的标记绑定在一起。
新的团队结构意味着所有应用程序活动都锁定在产品团队中,因此我们停止进行纯测试。取而代之的是,我们使用Java,Selenium和Jenkins(用作启动和生成报告的系统)编写的测试对UI进行监控。
我们进行了许多测试,但最终我们决定选择最主要的指标,即主要指标。而且,如果我们有很多特定的测试,将很难使数据保持最新。随后的每个发行版都将严重破坏整个系统,我们将只对其进行修复。因此,我们与很少改变的非常基本的事物联系在一起,仅对其进行监视。
最后,第三,数据源是集中式日志记录系统。对于日志,我们使用Elastic Stack,然后可以将此数据拖动到我们的监视系统中以获取业务指标。除此之外,我们自己的以Python编写的Monitoring API服务也可以正常工作,该服务通过API查询任何服务,并将数据从其中获取到Zabbix。
监视的另一个不可替代的属性是可视化。我们基于Grafana构建它。在其他可视化系统中,其突出之处在于可以在仪表板上可视化来自不同数据源的指标。我们可以收集在线商店的顶级指标,例如,过去一小时从DBMS收集的订单数量,从Zabbix运行此在线商店的操作系统的性能指标以及从Prometheus收集的该应用程序实例的指标。所有这些都将放在一个仪表板上。可视且易于访问。
让我注意一下安全性-我们现在正在完成系统的定型,然后将其与全局监视系统集成。我认为,电子商务在信息安全领域面临的主要问题与机器人,解析器和蛮力有关。应该对此进行监视,因为从业务角度来看,它们都会严重影响我们应用程序的性能和声誉。通过选择的堆栈,我们成功地完成了这些任务。
另一个重要的一点是,应用程序层是由Prometheus收集的。他本人也与Zabbix集成在一起。我们还拥有sitespeed,该服务使我们能够相应地查看诸如页面加载速度,瓶颈,页面渲染,加载脚本等参数,该服务也通过API进行了集成。因此,指标分别在Zabbix中收集,我们也从那里发出警报。到目前为止,所有警报均采用发送的主要方法(目前,这些是电子邮件和电报,它们最近与MS Teams联系了)。已经计划将警报发送到这样的状态,即智能机器人将其作为服务并向所有感兴趣的产品团队提供监视信息。
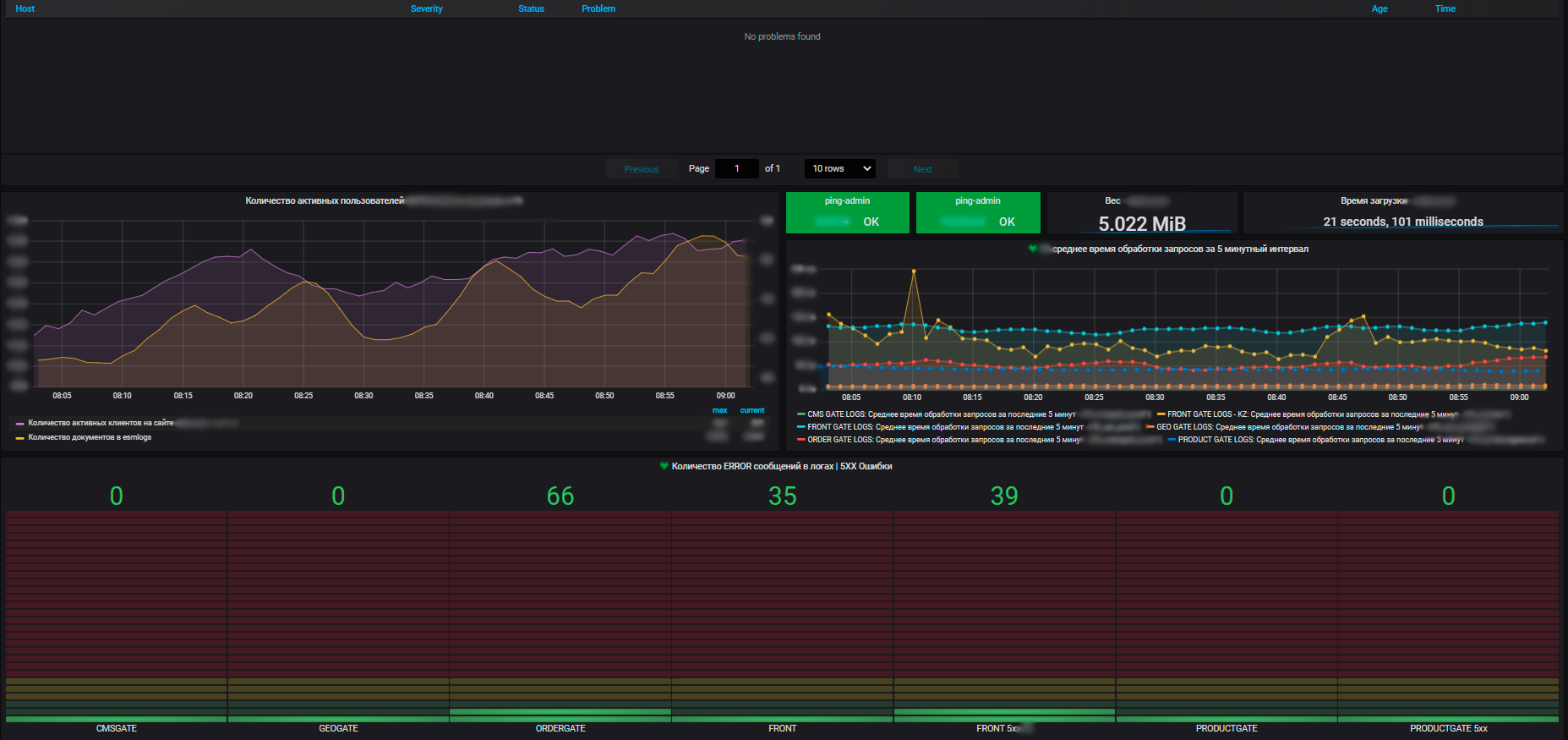
对于我们而言,不仅单个信息系统的指标很重要,而且应用程序使用的整个基础架构的常规指标也很重要:运行虚拟机的物理服务器群集,流量平衡器,网络负载平衡器,网络本身,通信通道的利用率。加上我们自己的数据中心的指标(我们有几个指标,基础架构非常重要)。
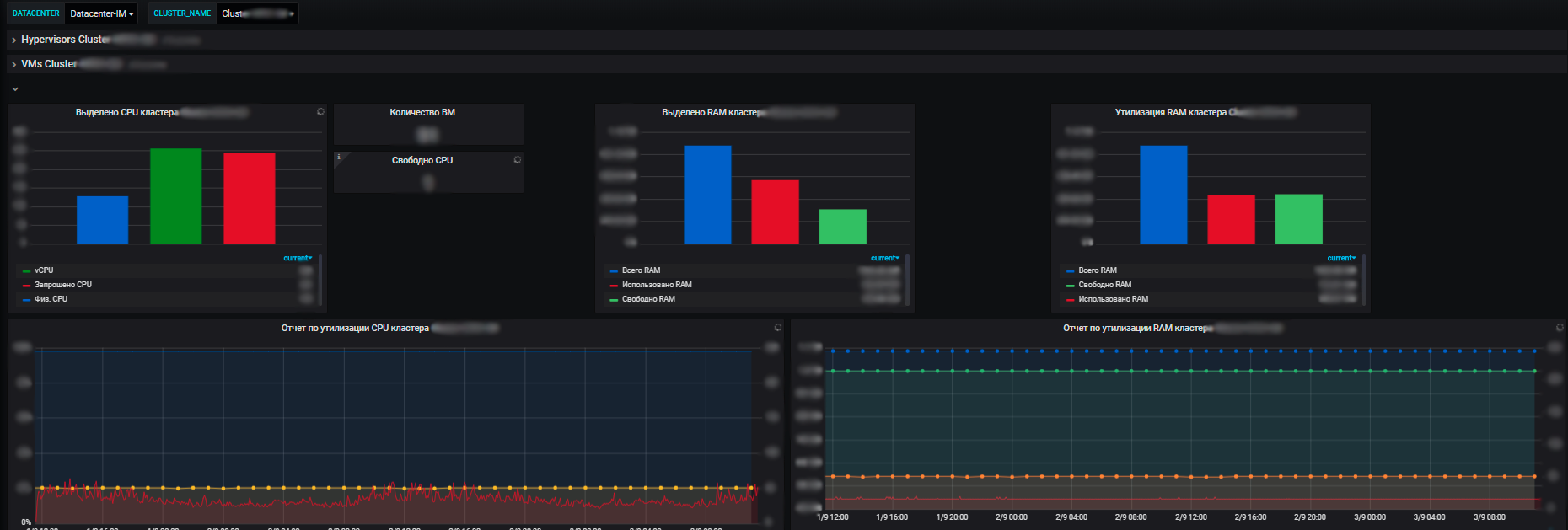
监控系统的优势在于,借助它的帮助,我们可以查看所有系统的运行状况,从而可以评估它们之间的相互影响以及对公共资源的影响。最终,它允许进行资源规划,这也是我们的责任。我们管理服务器资源-电子商务框架内的池,引入和停用新设备,购买新设备,对资源利用进行审核等。团队每年计划新项目,开发他们的系统,对我们来说,为其提供资源很重要。
借助指标,我们可以看到信息系统资源消耗的趋势。在他们的基础上,我们可以计划一些事情。在虚拟化级别,我们收集数据并在数据中心的上下文中查看有关可用资源量的信息。并且已经在数据中心内部,可见利用率和实际分配,资源消耗。此外,对于独立服务器,虚拟机和物理服务器群集,所有这些虚拟机都在其上剧烈旋转。
观点
现在我们已经准备好了整个系统的核心,但是仍然有足够的工作要做。至少这是一个信息安全层,但是到达网络,开发警报并解决相关问题也很重要。我们有很多层和系统,每层上还有更多指标。事实证明,套娃达到了套娃的程度。
我们的任务最终是做出正确的警报。例如,如果硬件出现问题,虚拟机又出现问题,并且存在重要的应用程序,则该服务不会以任何方式进行备份。我们发现虚拟机已失效。然后他们将向业务指标发出警报:用户消失在某个地方,没有转换,界面中的UI不可用,软件和服务也消失了。
在这种情况下,我们将收到来自警报的垃圾邮件,并且此垃圾邮件不再适合正确的监视系统。相关性的问题出现了。因此,理想情况下,我们的监视系统应该说:“伙计,您的物理机器已经死亡,并且此应用程序和此类度量标准也随之死亡”,借助于一个警报,而不是对一百个警报发怒。她必须报告最主要的内容-原因,这有助于迅速解决由于本地化而导致的问题。
我们的通知和警报处理系统围绕24/7热线服务构建。清单中包含的所有对我们来说都是必需的警报都将发送到那里。每个警报必须有一个描述:发生了什么,实际上意味着什么,影响了什么。以及指向仪表板的链接以及在这种情况下的操作说明。
这就是构建警报的全部要求。此外,这种情况可以从两个方向发展:要么有问题需要解决,要么监视系统出现故障。但是无论如何,您都需要解决它。
现在,平均每天大约有一百个警报发送给我们,这是考虑到警报的相关性尚未正确配置这一事实。而且,如果我们需要进行技术工作,并且强行关闭某些设备,它们的数量将大大增加。
除了监视我们正在运行的系统并收集对我们而言很重要的指标外,监视系统还允许我们为产品团队收集数据。它们会影响此处监视的信息系统中指标的组成。
我们的同事可以过来要求添加一些对我们和团队有用的指标。或者,例如,团队可能没有足够的基本指标,他们需要跟踪一些特定指标。在Grafana中,我们为每个团队创建一个空间并发布管理员权限。此外,如果团队需要仪表板,但他们本身不能/不知道如何做,我们会为他们提供帮助。
由于我们不在团队价值创造,发布和计划的范围之内,因此我们逐渐得出结论,所有系统的发布都是无缝的,可以每天发布,而无需与我们协调。对于我们而言,跟踪这些发行版非常重要,因为它们可能潜在地影响应用程序的运行并破坏某些内容,这一点至关重要。为了管理发布,我们使用Bamboo,从竹子那里我们从API那里获取数据,并且可以查看哪个发布的信息系统及其状态。最重要的是什么时候。我们将发布标记放在主要的关键指标上,在出现问题时在视觉上非常有指示性。
这样,我们可以看到新版本与新出现问题之间的相关性。主要思想是了解系统如何在所有层上工作,以快速定位问题并尽快解决。确实,经常发生的是,大部分时间都花在了解决问题上,而不是寻找原因上。
在这个方向上,将来,我们希望专注于主动性。理想情况下,我想事先知道一个迫在眉睫的问题,而不是事后才知道,以便对付它,而不是解决。有时由于人为错误和应用程序更改而导致监视系统出现误报,我们正在对此进行调试,调试,并试图在对监视系统进行任何操作之前警告用户有关此信息,并与我们一起使用。 ,或在技术窗口中执行这些事件。
因此,该系统自春季开始以来已经启动并成功运行,并显示出非常可观的利润。当然,这不是最终版本,我们将介绍更多有用的功能。但是现在,由于集成和应用程序如此之多,监视的自动化确实必不可少。
如果您还监视具有大量集成的大型项目,请在注释中写下您为此找到的精妙之处。