...进入设计合理的查询中,并为相应的计划节点提供上下文提示:

在PGConf.Russia 2020演讲的第二部分的笔录中,我将告诉您我们如何做到这一点。
第一部分的记录涉及典型的查询性能问题及其解决方案,可以在文章“ SQL查询异常的食谱”中找到。
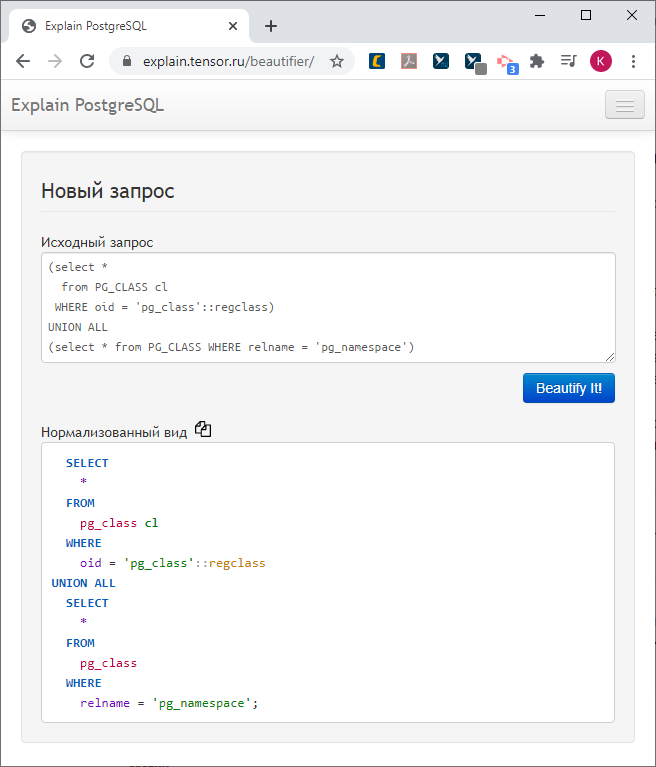
首先,我们将绘画-我们将不再绘画该计划,我们已经绘画了它,我们已经使它美丽且可以理解,但这是一个要求。
在我们看来,使用未格式化的“工作表”从日志中提取的查询看起来非常丑陋,因此不方便。

尤其是当开发人员在代码中将请求主体(当然是一种反模式,但它确实发生)粘在一行上时。恐怖!
让我们以更精美的方式绘制它。
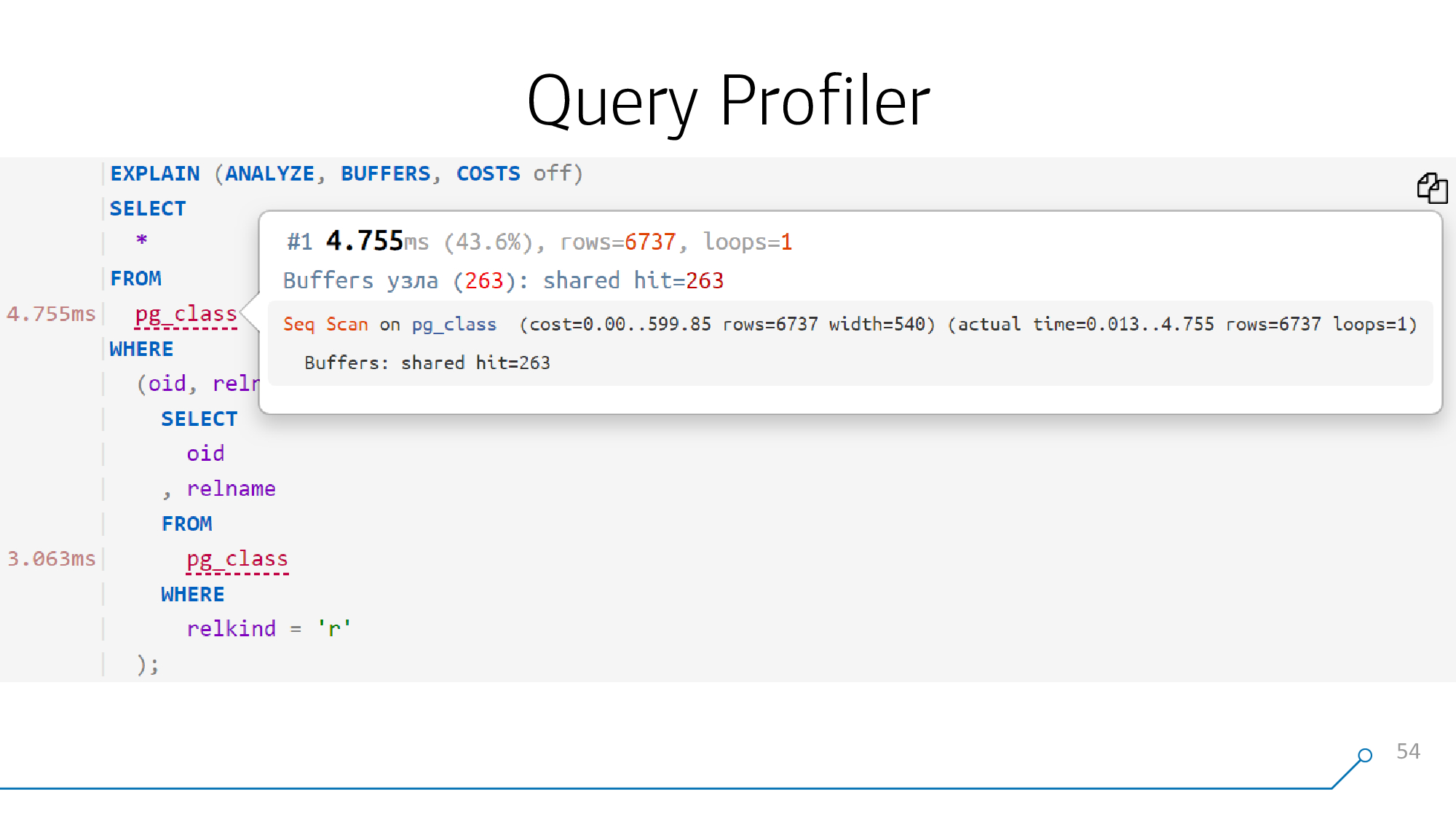
如果可以精美地绘制它,也就是分解并重新组装请求主体,则可以向该请求的每个对象附加提示-在计划中的相应点发生了什么。
语法查询树
为此,必须首先解析该请求。
由于我们的系统核心运行在NodeJS上,因此我们为其创建了模块,因此可以在GitHub上找到它。实际上,这些是对PostgreSQL解析器本身内部的扩展“绑定”。也就是说,语法只是简单地以二进制形式编译,并且从NodeJS端对其进行绑定。我们以其他人的模块为基础-这里没有什么大秘密。
我们将请求主体提供给函数的输入-在输出处,我们以JSON对象的形式获得了语法分析树。

现在,您可以沿相反的方向浏览此树,并使用所需的缩进,着色和格式收集请求。不,它不是可配置的,但是在我们看来,这将很方便。

映射查询和计划节点
现在,让我们看看如何将第一步中分析的计划与第二步中分析的查询结合起来。
让我们举一个简单的例子-我们有一个生成CTE并读取两次的请求。他制定了这样的计划。

CTE
如果仔细看一下,在第12版之前(或从第一个版本开始,使用关键字
MATERIALIZED),CTE的形成绝对是计划者的障碍。
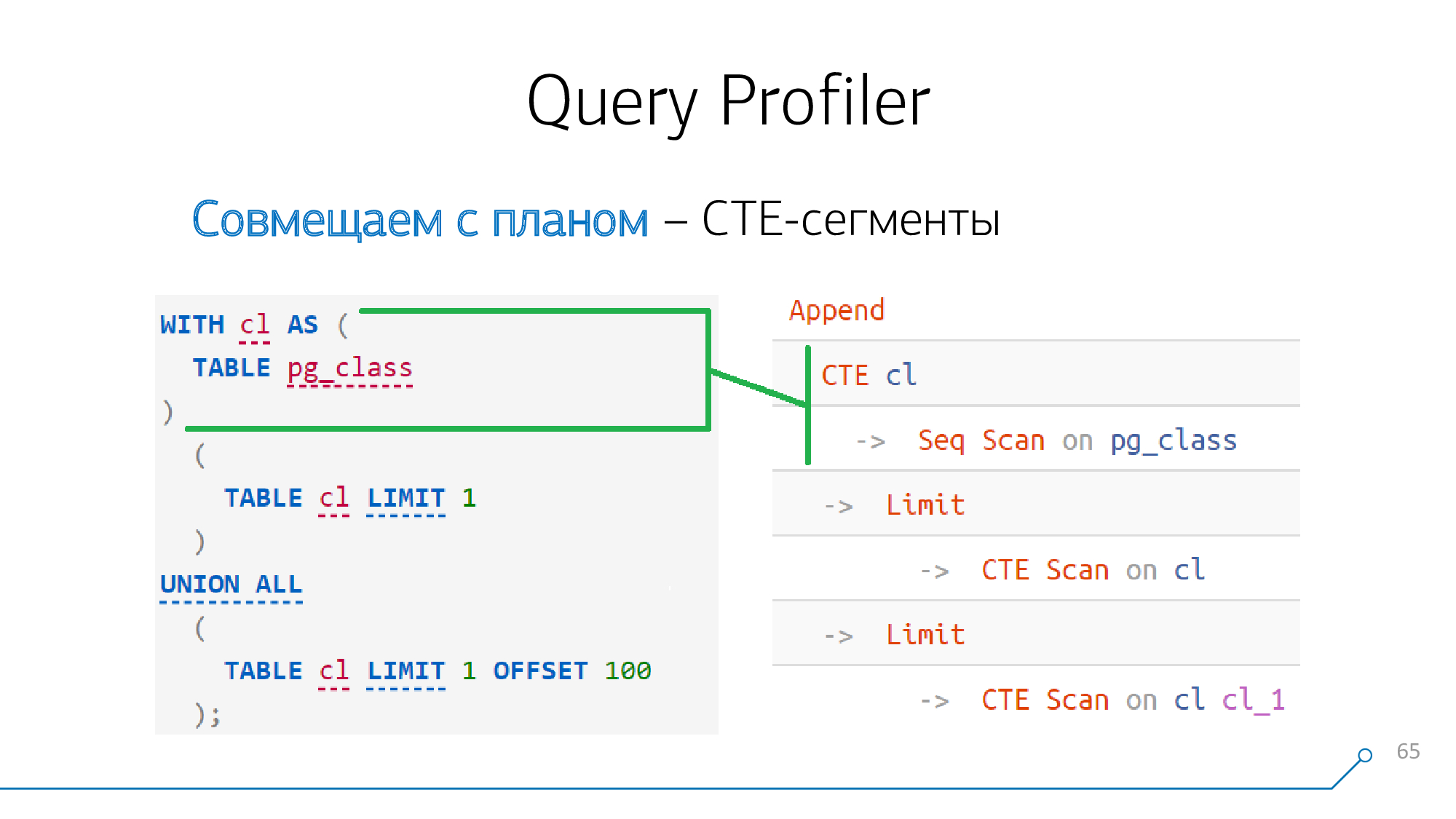
这意味着如果我们在请求中某处和计划中某处看到CTE的生成
CTE,那么这些节点肯定会彼此“打架”,我们可以立即将它们组合在一起。
星号问题:CTE可以嵌套。

有非常糟糕的嵌套,甚至是相同的名称。例如,您可以在中
CTE A执行此操作,然后CTE X在同一级别中CTE B再次执行该操作CTE X:
WITH A AS (
WITH X AS (...)
SELECT ...
)
, B AS (
WITH X AS (...)
SELECT ...
)
...比较时必须了解这一点。用“眼睛”很难理解这一点-甚至看到计划,甚至看到请求的主体。如果您的CTE一代是复杂的,嵌套的,请求量很大,那么您就完全无意识了。
联盟
如果我们在查询中有一个关键字
UNION [ALL](连接两个选择的运算符),则计划中的节点Append或某个其他节点都对应于该关键字Recursive Union。

上方的“上方”是
UNION节点的第一个孩子,下方的是第二个节点。如果通过UNION我们一次“胶合”了几个块,那么Append仍然只有一个-节点,但不会有两个子节点,而是有许多子节点-按照它们的顺序:
(...) -- #1
UNION ALL
(...) -- #2
UNION ALL
(...) -- #3Append
-> ... #1
-> ... #2
-> ... #3
“带有星号”的问题:在递归选择(
WITH RECURSIVE)的生成内,可能还存在多个UNION。但是,只有最后一个之后的最后一个块始终是递归的UNION。上面的一切都是一个,但又不同UNION:
WITH RECURSIVE T AS(
(...) -- #1
UNION ALL
(...) -- #2,
UNION ALL
(...) -- #3, T
)
...您还需要能够“粘贴”此类示例。在此示例中,我们看到
UNION请求中包含3个细分。因此,一个UNION 对应于Append-node,另一个对应于Recursive Union。

读写数据
就是这样,我们将其展开,现在我们知道请求的哪一部分对应于计划的哪一部分。在这些片段中,我们可以轻松自然地找到那些“可读”的对象。
从查询的角度来看,我们不知道这是表还是CTE,但是它们由同一节点表示
RangeVar。就“可读”而言,它也是一组相当有限的节点:
Seq Scan on [tbl]Bitmap Heap Scan on [tbl]Index [Only] Scan [Backward] using [idx] on [tbl]CTE Scan on [cte]Insert/Update/Delete on [tbl]
我们知道计划和查询的结构,我们知道块的对应关系,我们知道对象的名称-我们进行了明确的比较。

同样,一个星号问题。我们接受请求,执行它,我们没有任何别名-我们只从一个CTE读取了两次。

我们看一下计划-有什么问题吗?为什么别名消失了?我们没有订购。他为什么这么“编号”?
PostgreSQL本身添加了它。您只需要了解,对于与计划进行比较的目的,这样的别名对我们没有任何意义,只需在此处添加即可。让我们不要注意他。
第二个任务是“带有星号”:如果我们正在从分区表中读取数据,则将得到一个节点
Append或Merge Append,其中将包含大量的“子代”,并且每个子代都是Scan表格部分的Seq Scan,Bitmap Heap Scan即或Index Scan。但是,无论如何,这些“子项”将不会是复杂的查询-这就是如何从Appendwhen区分这些节点的方法UNION。

我们也了解这些节点,我们将它们“一堆”地收集起来,然后说:“您从兆表读取的所有内容都在这里和树上。”
用于接收数据的“简单”节点

Values Scan在计划中符合VALUES要求。
Result-这是一个没有FROM喜欢的要求SELECT 1。或WHERE-block中有一个已知为假的表达式时(该属性出现One-Time Filter):
EXPLAIN ANALYZE
SELECT * FROM pg_class WHERE FALSE; -- 0 = 1Result (cost=0.00..0.00 rows=0 width=230) (actual time=0.000..0.000 rows=0 loops=1)
One-Time Filter: false
Function Scan“映射”到同名的SRF。
但是对于嵌套查询,一切都变得更加复杂-不幸的是,它们并不总是变成
InitPlan/ SubPlan。有时它们变成... Join或... Anti Join,尤其是当你写些像WHERE NOT EXISTS ...。而且并非总是可以在那里合并-计划文本中没有对应于计划节点的运算符。
同样,带有星号的任务:
VALUES请求中有多个。在这种情况下,在计划中,您将收到几个节点Values Scan。

“编号”后缀将有助于将它们彼此区分开-确切地按照在
VALUES请求中从上到下查找相应-block的顺序添加后缀。
数据处理
似乎我们要求中的所有内容都已整理好-仅剩一个
Limit。
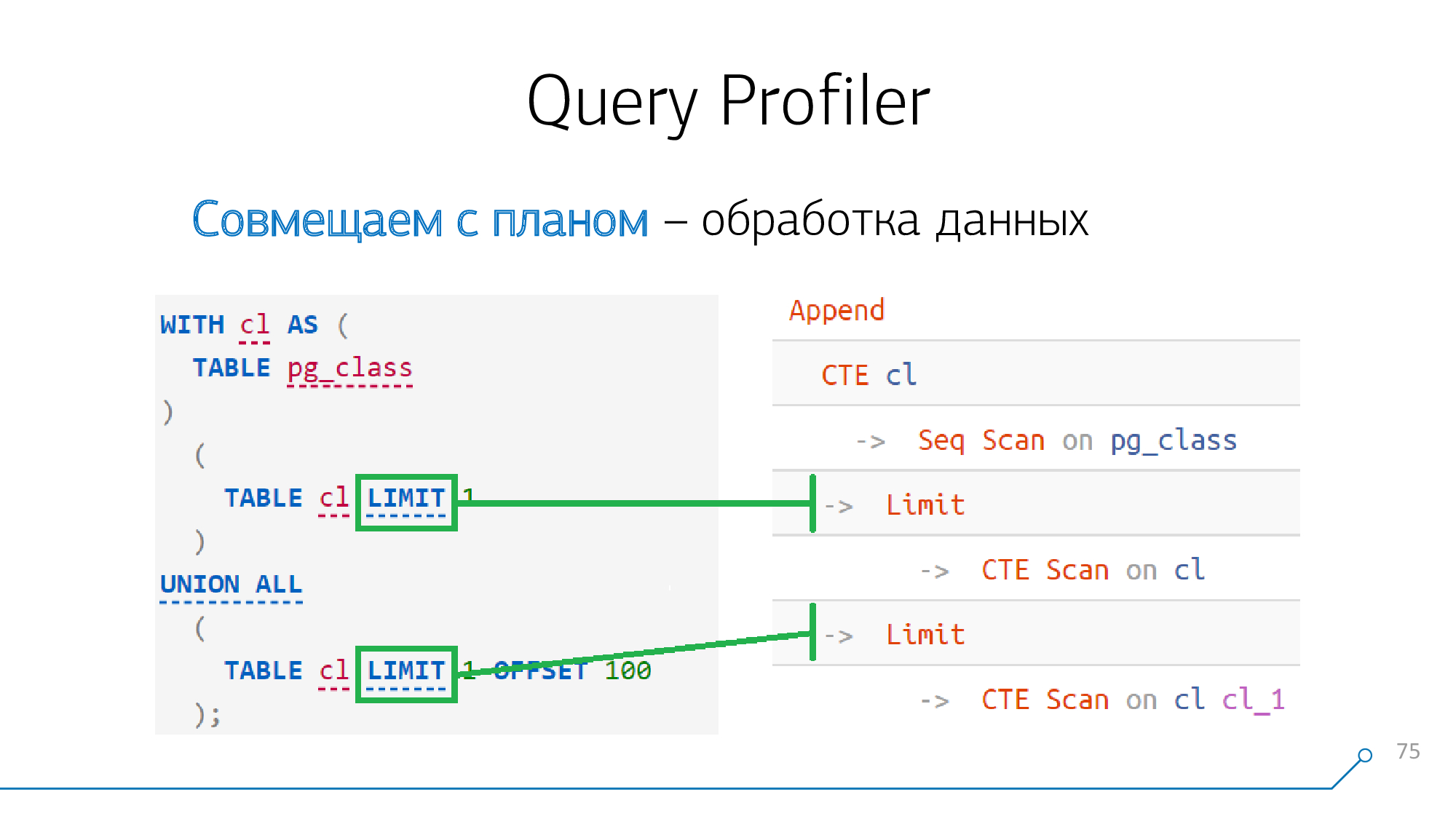
但是,一切都非常简单-比如节点
Limit,Sort,Aggregate,WindowAgg,Unique“mapyatsya”一到一个请求中所对应的语句,如果它们的存在。没有“星星”,也没有困难。

加入
当我们想
JOIN彼此结合时会遇到困难。并非总是如此,但是可以。

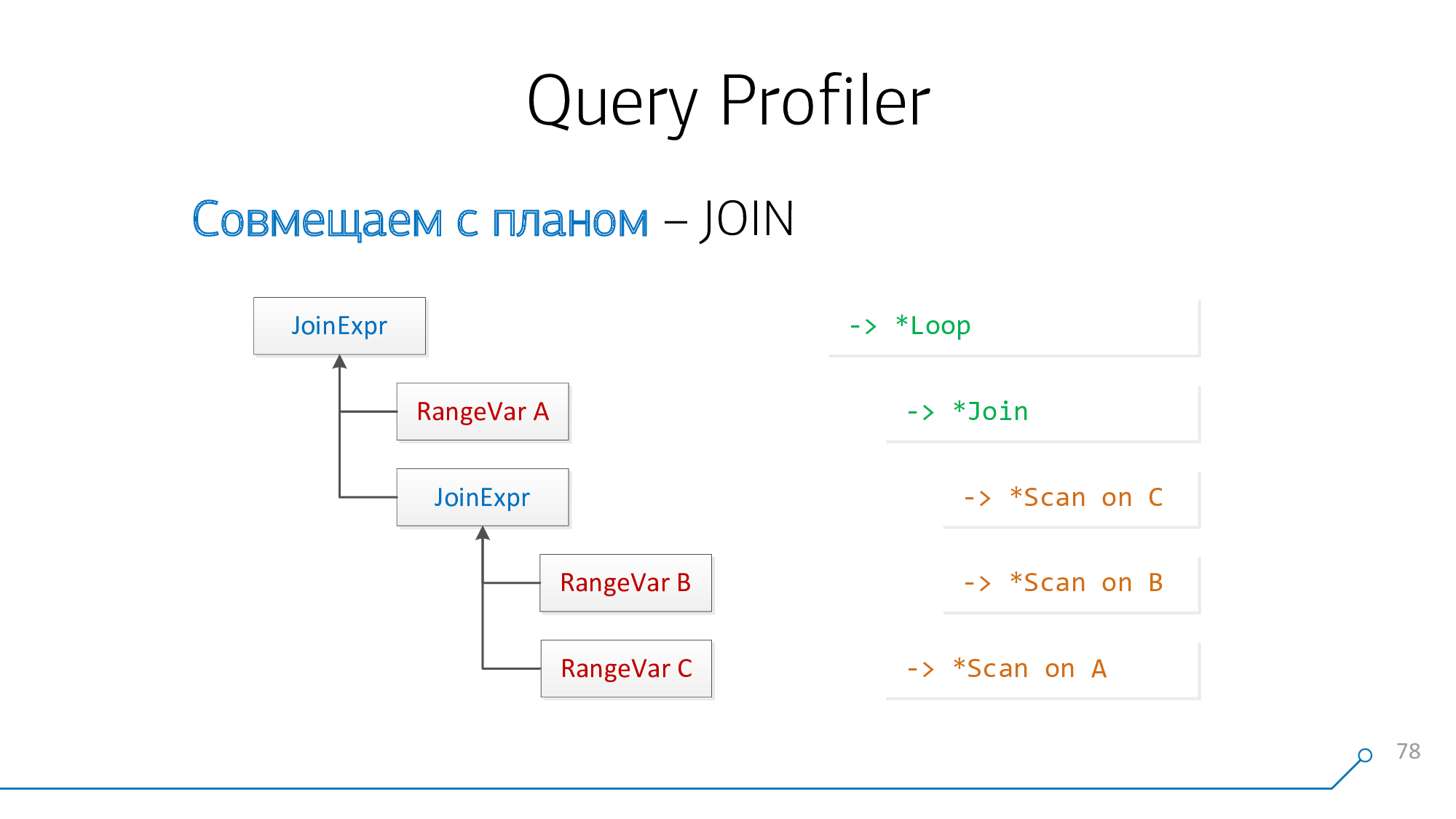
从查询解析器的角度来看,我们有一个节点
JoinExpr,该节点恰好有两个子节点-左和右。这分别是您的JOIN的“上方”和“在其下方”的内容。
而且从规划的角度来看,这些都是一些两个后代
* Loop/ * Join-node。Nested Loop,Hash Anti Join...-就是这样。
让我们使用一个简单的逻辑:如果我们有板A和B,它们在计划中彼此“接合”,那么在请求中它们可以位于
A-JOIN-B或B-JOIN-A。让我们尝试以这种方式进行合并,以另一种方式进行合并,依此类推,直到此类货币对耗尽为止。
拿我们的语法树,拿我们的轮廓,看看它们……不是那样!
让我们以图形的形式重绘它-哦,它已经变成了类似的东西!
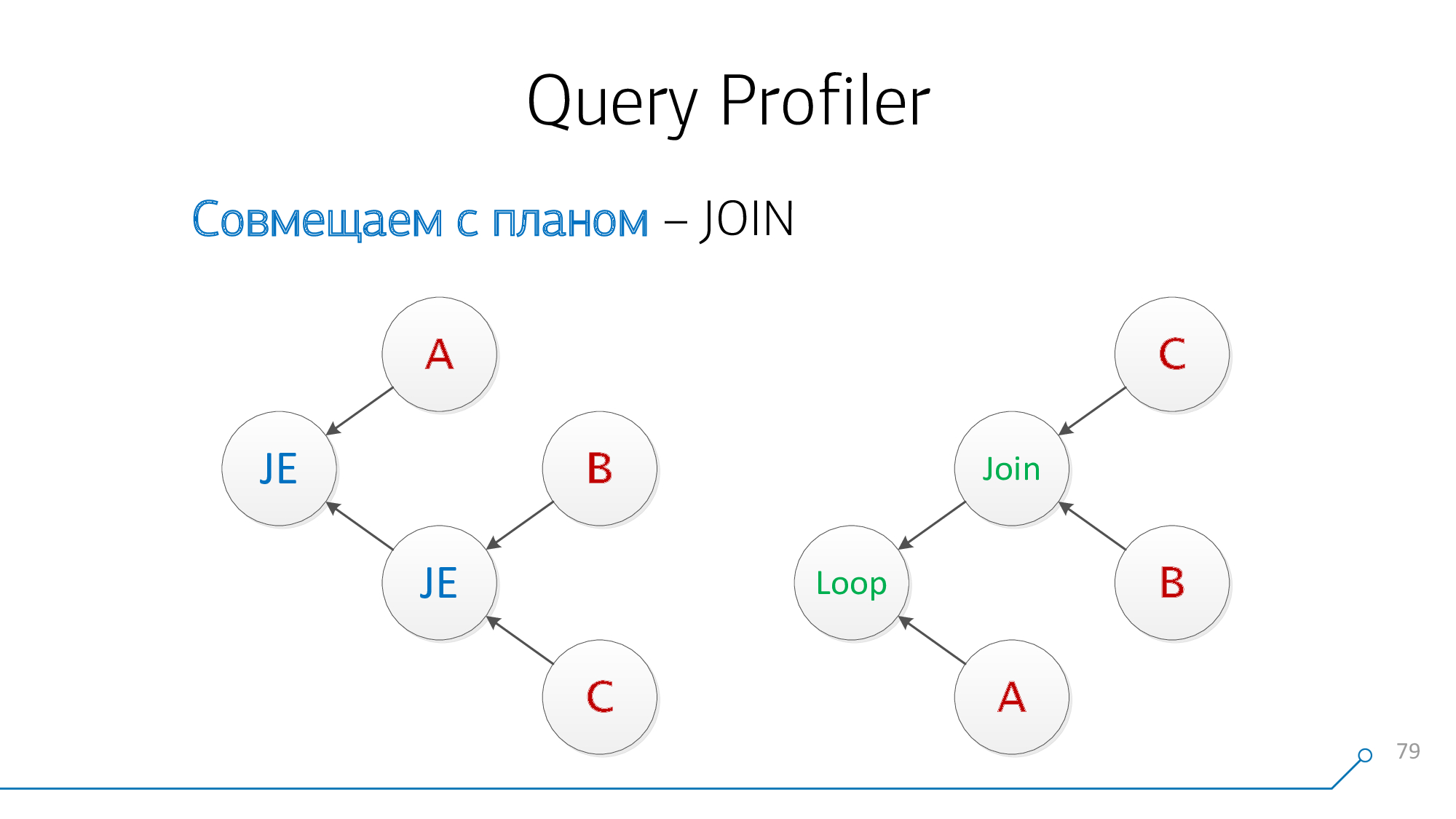
请注意,我们的节点同时具有子B和C-我们不在乎顺序。让我们结合起来,打开图片。

让我们再看一遍。现在我们有了带有子A和对(B + C)的节点-也与它们兼容。
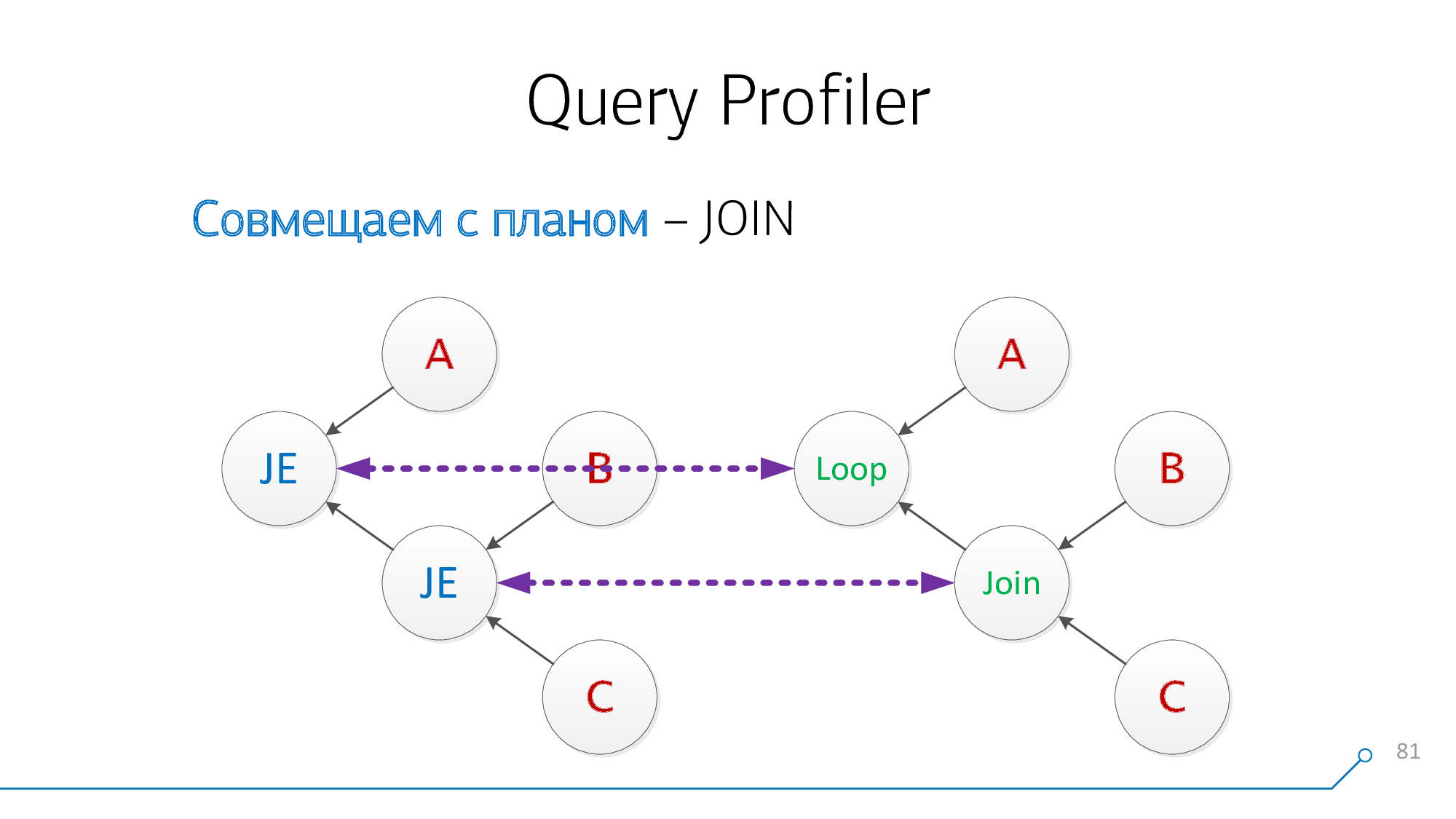
优秀的!事实证明,我们已经
JOIN成功地将查询中的这两个与计划节点组合在一起。
,,这个任务并非总能解决。
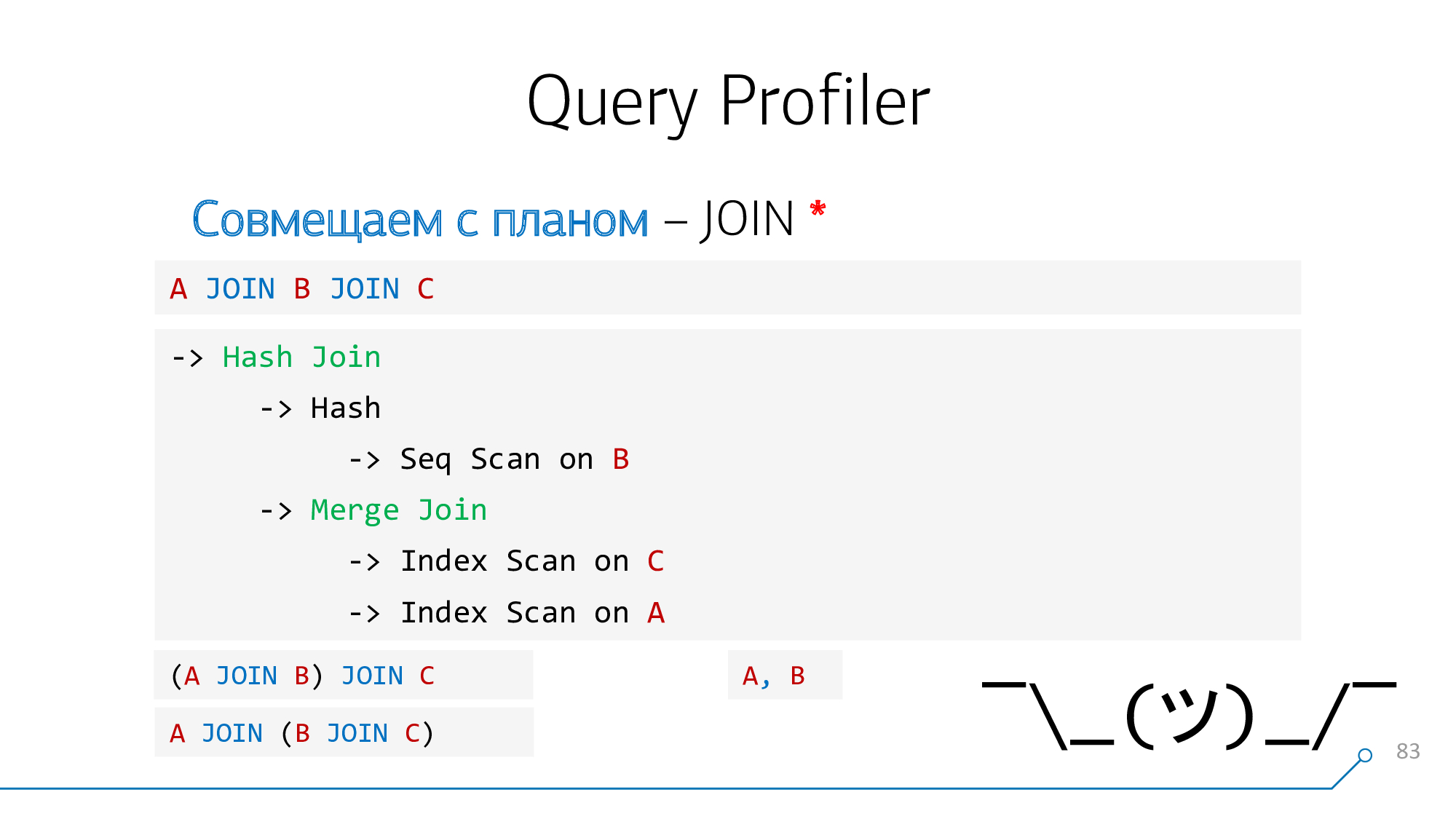
例如,如果在查询中
A JOIN B JOIN C,但在计划中,首先连接了“极端”节点A和C,并且在查询中没有此类运算符,则没有要突出显示的内容,也没有将提示绑定到的内容。编写时,“逗号”与之相同A, B。
但是,在大多数情况下,几乎所有节点都可以“合并”,并且您可以在左侧及时得到这种分析-实际上,当您分析JavaScript代码时,就像在Google Chrome中一样。您可以看到每行和每条语句被“执行”了多长时间。

为了使您更轻松地使用所有这些内容,我们建立了档案存储,您可以在其中保存并找到计划以及相关的查询,或者与他人共享链接。
如果您只需要将不可读的查询转换为适当的格式,请使用我们的“ normalizer”。