1.1什么是决策树?
1.1.1决策树示例
例如,我们有以下数据集(日期集):天气,温度,湿度,风,高尔夫。根据天气和其他所有因素,我们去(〇)或不(×)打高尔夫球。假设我们有14个先入为主的选择。

根据这些数据,我们可以组成一个数据结构,显示在什么情况下我们去打高尔夫球。由于其分支形状,此结构称为决策树。
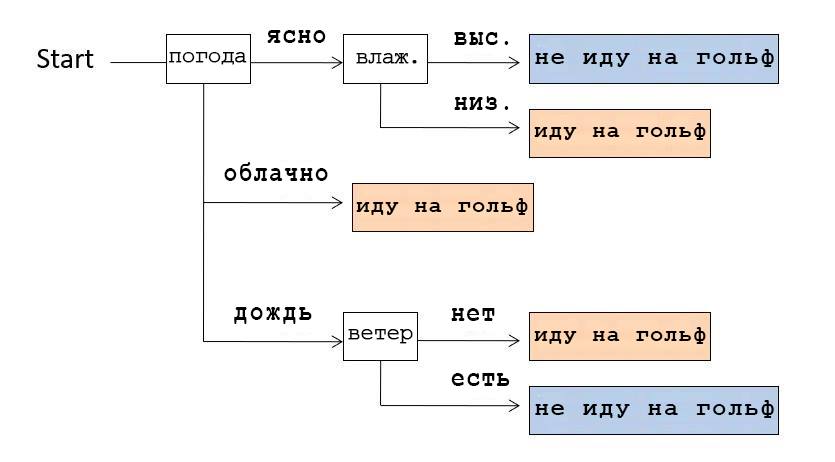
例如,如果我们看上图所示的决策树,我们意识到我们首先检查了天气。如果天气晴朗,我们检查湿度:如果湿度高,那么我们就不去打高尔夫球,如果湿度低,我们就去。如果天气多云,那么不管其他条件如何,他们都去打高尔夫球。
1.1.2关于本文
有一些算法会根据可用数据自动创建此类决策树。在本文中,我们将在Python中使用ID3算法。
本文是系列文章的第一篇。以下文章:(
译者注:“如果您对续集感兴趣,请在评论中告知我们。”)
- Python编程基础
- 熊猫数据分析的基本库基础
- 数据结构基础(就决策树而言)
- 信息熵的基础
- 学习用于生成决策树的算法
1.1.3关于决策树的一些知识
决策树的生成与有监督的机器学习和分类有关。机器学习中的分类是一种基于对带有正确答案和得出答案的数据的日期进行训练来创建导致正确答案的模型的方法。近年来,尤其是在图像识别领域非常流行的深度学习,也是基于分类方法的机器学习的一部分。深度学习与决策树之间的区别在于,最终结果是否简化为人们理解生成最终数据结构原理的形式。深度学习的独特之处在于,我们获得了最终结果,但不了解其产生的原理。与深度学习不同,决策树易于人类理解,这也是一个重要功能。
决策树的这一功能不仅对机器学习有好处,而且对日期挖掘也很有用,在此情况下,用户对数据的理解也很重要。
1.2关于ID3算法
ID3是由Ross Quinlan在1986年开发的决策树生成算法。它具有两个重要功能:
- 分类数据。这是与我们上面的示例类似的数据(是否高尔夫),带有特定类别标签的数据。ID3不能使用数字数据。
- 信息熵是一种指示符,用于指示一类数据的属性变化最小的数据序列。
1.2.1关于使用数值数据
算法C4.5是ID3的高级版本,可以使用数字数据,但是由于本系列的基本思想相同,因此我们将首先使用ID3。
1.3开发环境
我在下面描述的程序经过测试并在以下条件下运行:
- Jupyter笔记本(使用Azure笔记本)
- Python 3.6
- 库:数学,熊猫,函数工具(未使用scikit-learn,tensorflow等)
1.4示例程序
1.4.1实际上,该程序
首先,让我们将程序复制到Jupyter Notebook中并运行它。
import math
import pandas as pd
from functools import reduce
#
d = {
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
# - , ,
# .
"":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"],
}
df0 = pd.DataFrame(d)
# - , - pandas.Series,
# -
# s value_counts() ,
# , , items().
# , sorted,
#
# , , : (k) (v).
cstr = lambda s:[k+":"+str(v) for k,v in sorted(s.value_counts().items())]
# Decision Tree
tree = {
# name: ()
"name":"decision tree "+df0.columns[-1]+" "+str(cstr(df0.iloc[:,-1])),
# df: , ()
"df":df0,
# edges: (), ,
# , .
"edges":[],
}
# , , open
open = [tree]
# - .
# - pandas.Series、 -
entropy = lambda s:-reduce(lambda x,y:x+y,map(lambda x:(x/len(s))*math.log2(x/len(s)),s.value_counts()))
# , open
while(len(open)!=0):
# open ,
# ,
n = open.pop(0)
df_n = n["df"]
# , 0,
#
if 0==entropy(df_n.iloc[:,-1]):
continue
# ,
attrs = {}
# ,
for attr in df_n.columns[:-1]:
# , ,
# , .
attrs[attr] = {"entropy":0,"dfs":[],"values":[]}
# .
# , sorted ,
# , .
for value in sorted(set(df_n[attr])):
#
df_m = df_n.query(attr+"=='"+value+"'")
# ,
attrs[attr]["entropy"] += entropy(df_m.iloc[:,-1])*df_m.shape[0]/df_n.shape[0]
attrs[attr]["dfs"] += [df_m]
attrs[attr]["values"] += [value]
pass
pass
# , ,
# .
if len(attrs)==0:
continue
#
attr = min(attrs,key=lambda x:attrs[x]["entropy"])
#
# , , open.
for d,v in zip(attrs[attr]["dfs"],attrs[attr]["values"]):
m = {"name":attr+"="+v,"edges":[],"df":d.drop(columns=attr)}
n["edges"].append(m)
open.append(m)
pass
#
print(df0,"\n-------------")
# , - tree: ,
# indent: indent,
# - .
# .
def tstr(tree,indent=""):
# .
# ( 0),
# df, , .
s = indent+tree["name"]+str(cstr(tree["df"].iloc[:,-1]) if len(tree["edges"])==0 else "")+"\n"
# .
for e in tree["edges"]:
# .
# indent .
s += tstr(e,indent+" ")
pass
return s
# .
print(tstr(tree))1.4.2结果
如果您运行上述程序,我们的决策树将以符号表的形式表示,如下所示。
decision tree ['×:5', '○:9']
=
=['○:2']
=['×:3']
=['○:4']
=
=['×:2']
=['○:3']
1.4.3更改我们要探索的属性(数据数组)
日期集d中的最后一个数组是类属性(我们要分类的数据数组)。
d = {
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"],}
# - , , .
"":["","","","","","","","","","","","","",""],
}例如,如上例所示,如果交换数组“ Golf”和“ Wind”,则会得到以下结果:
decision tree [':6', ':8']
=×
=
=
=[':1', ':1']
=[':1']
=[':2']
=○
=
=[':1']
=[':1']
=
=[':2']
=[':1']
=[':1']
=[':3']本质上,我们创建了一条规则,在该规则中,我们根据是否存在风以及是否要打高尔夫球来告诉程序首先分支。
谢谢阅读!
如果您告诉我们您是否喜欢本文,我们将非常高兴,翻译是否清晰,对您有用吗?