使用Python使用自然语言处理文本非常方便,因为它是相当高级的编程工具,具有完善的基础结构,并在数据分析和机器学习领域证明了自己。社区已经开发了一些库和框架来解决Python中的NLP问题。在我们的工作中,我们将使用交互式Web工具来开发python脚本Jupyter Notebook,用于文本分析的NLTK库和用于构建词云的wordcloud库。
该网络包含大量有关文本分析主题的材料,但是在许多文章(包括俄语)中,建议使用英语分析文本。俄语文本的分析有一些使用NLP工具包的细节。例如,考虑对A. Pushkin的故事“ Snowstorm”的文本进行频率分析。
频率分析可以大致分为几个阶段:
- 加载和浏览数据
- 文字清理和预处理
- 删除停用词
- 将单词翻译成基本形式
- 计算文本中单词出现的统计
- 词流行度的云可视化
该脚本位于github.com/Metafiz/nlp-course-20/blob/master/frequency-analisys-of-text.ipynb上,来源-github.com/Metafiz/nlp-course-20/blob/master/pushkin -metel.txt
加载数据中
我们使用打开的内置函数打开文件,指定读取模式和编码。我们读取了文件的全部内容,结果得到了字符串文本:
f = open('pushkin-metel.txt', "r", encoding="utf-8")
text = f.read()
文本的长度(字符数)可以通过标准len函数获得:
len(text)
python中的字符串可以表示为字符列表,因此索引访问和切片操作也可以用于字符串。例如,要查看文本的前300个字符,只需运行以下命令:
text[:300]
文本的预处理(预处理)
为了进行频率分析并确定文本的主题,建议清除标点符号,多余的空白字符和数字中的文本。您可以通过多种方式来执行此操作-使用内置的字符串函数,使用正则表达式,使用列表处理或其他方式。
首先,让我们将字符转换为单个大小写,例如,小写:
text = text.lower()
我们使用来自字符串模块的标准标点字符集:
import string
print(string.punctuation)
string。标点符号是一个字符串。可以扩展从文本中删除的特殊字符集。有必要分析源文本并标识应删除的字符。让我们将在源文本中找到的换行符,制表符和其他符号添加到标点符号(例如,具有代码\ xa0的字符):
spec_chars = string.punctuation + '\n\xa0«»\t—…'
要删除字符,我们使用字符串的逐元素处理-将原始文本字符串划分为字符,仅保留spec_chars集合中未包含的字符,然后再次将字符列表组合为字符串:
text = "".join([ch for ch in text if ch not in spec_chars])
您可以声明一个简单的函数,该函数从源文本中删除指定的字符集:
def remove_chars_from_text(text, chars):
return "".join([ch for ch in text if ch not in chars])
它既可以用来删除特殊字符,也可以用来删除原始文本中的数字:
text = remove_chars_from_text(text, spec_chars)
text = remove_chars_from_text(text, string.digits)
标记文字
为了进行进一步处理,清除的文本必须分为其组成部分-标记。自然语言文本分析使用符号,单词和句子细分。分区过程称为令牌化。对于我们的频率分析任务,有必要将文本分解为单词。为此,可以使用NLTK库的现成方法:
from nltk import word_tokenize
text_tokens = word_tokenize(text)
变量text_tokens是单词(令牌)的列表。要计算预处理文本中的单词数,您可以获取令牌列表的长度:
len(text_tokens)
要显示前10个字,让我们使用slice操作:
text_tokens[:10]
要使用NLTK库的频率分析工具,您需要将标记列表转换为Text类,该类包含在该库中:
import nltk
text = nltk.Text(text_tokens)
让我们推断出变量文本的类型:
print(type(text))
切片操作也适用于此类型的变量。例如,此操作将输出文本中的前10个标记:
text[:10]
计算文本中单词出现的统计
FreqDist(频率分布)类用于计算文本中单词频率分布的统计信息:
from nltk.probability import FreqDist
fdist = FreqDist(text)
尝试显示fdist变量将显示一个包含令牌及其频率的字典-这些单词在文本中出现的次数:
FreqDist({'': 146, '': 101, '': 69, '': 54, '': 44, '': 42, '': 39, '': 39, '': 31, '': 27, ...})
您还可以使用most_common方法获取具有最常见标记的元组列表:
fdist.most_common(5)
[('', 146), ('', 101), ('', 69), ('', 54), ('', 44)]
文字中单词分布的频率可以使用图形显示。FreqDist类包含用于绘制此类图的内置图方法。必须指出令牌的数量,令牌的频率将在图表上显示。使用参数cumulative = False,该图说明了齐普夫定律:如果足够长的文本的所有单词按其使用频率的降序排列,则该列表中第n个单词的频率将与其序数n近似成反比。
fdist.plot(30,cumulative=False)
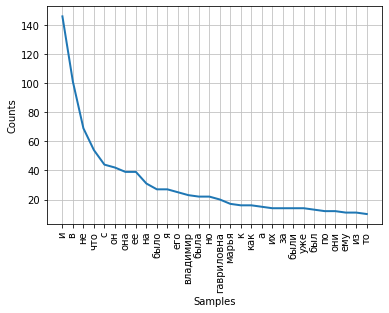
可以注意到,目前最高频率具有不带语义负载,而仅表达单词之间的语义-句法关系的连词,介词和其他语音服务部分。为了使频率分析的结果能够反映文本的主题,有必要从文本中删除这些单词。
删除停用词
通常,停用词(或干扰词)包括介词,连词,感叹词,助词和其他在语音中出现的词性,都是正式的,并且不承担语义负荷-它们是多余的。
NLTK库包含各种语言的现成停用词列表。让我们获取一百个俄语单词的列表:
from nltk.corpus import stopwords
russian_stopwords = stopwords.words("russian")
应当注意,停用词是上下文相关的-对于不同主题的文本,停用词可能有所不同。与特殊字符一样,有必要分析源文本并识别标准集中未包含的停用词。
停用词列表可以使用标准的extend方法扩展:
russian_stopwords.extend(['', ''])
删除停用词后,令牌在文本中的分配频率如下:
fdist_sw.most_common(10)
[('', 23),
('', 20),
('', 17),
('', 9),
('', 9),
('', 8),
('', 7),
('', 6),
('', 6),
('', 6)]
如您所见,频率分析的结果提供了更多信息,并且更准确地反映了本文的主题。但是,我们在结果中看到诸如“ vladimir”和“ vladimira”之类的标记,它们实际上是一个词,但形式不同。要纠正这种情况,有必要将源文本的单词带入其基础或原始形式-进行词干或词形化。
词流行度的云可视化
在工作结束时,我们以“词云”的形式可视化文本的频率分析结果。
为此,我们需要wordcloud和matplotlib库:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
%matplotlib inline
要构建词云,必须将字符串作为输入传递给方法。为了在预处理和除去停用词之后转换标记列表,我们将使用join方法,并指定一个空格作为分隔符:
text_raw = " ".join(text)
让我们称之为构建云的方法:
wordcloud = WordCloud().generate(text_raw)
结果,我们为文本得到了这样的``词云'':

查看它,您可以对作品的主题和主要特征有一个总体了解。