让我们看看这个问题有什么解决方案。
“按容量”分配对象
为了不深入研究无趣的抽象,我们将使用特定任务监控的示例进行考虑。我相信您将能够自行将建议的方法与您的特定任务相关联。
“等效”监视对象
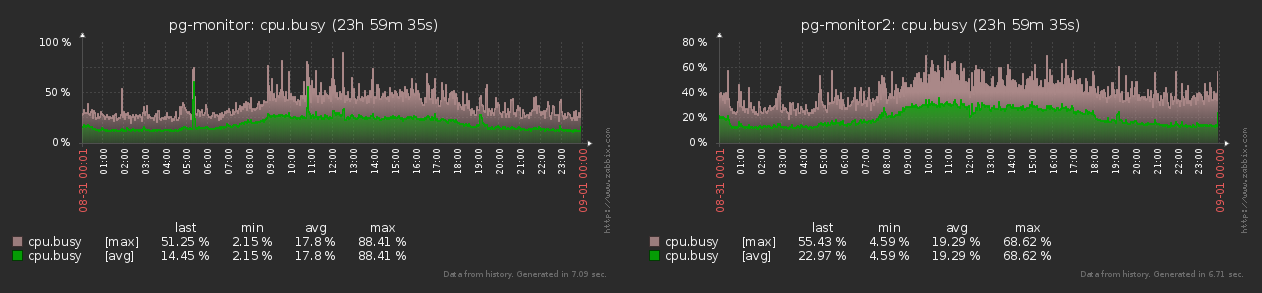
我们的Zabbix指标收集器 就是一个例子,该收集器在历史上与PostgreSQL日志收集器具有通用的体系结构。实际上
,每个监视对象(主机)始终稳定地以相同的频率为zabbix生成相同的一组度量:
正如您在图中看到的那样,生成的指标数量的最小-最大值之间的差异不超过15%。因此,我们可以认为所有对象在相同的“鹦鹉”中都相等。
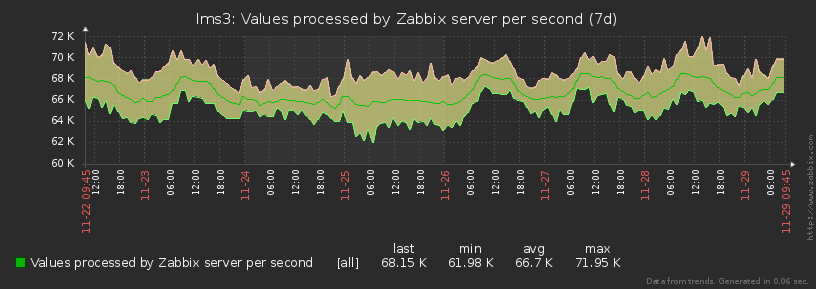
物体之间强烈的“不平衡”
与以前的模型不同,对于日志收集器而言,受监视的主机远非同质。
例如,一台主机每天可以在日志中生成一百万个计划,另外几万个,甚至有几个。计划本身在数量和复杂性以及一天中的时间分布方面都大不相同。因此,事实证明,负载有时会剧烈“抖动”:

好吧,既然负载可能发生很大变化,那么您需要学习如何对其进行管理...
协调员
我们立即了解到,显然,我们需要扩展收集器系统,因为总有一个负载的一个单独节点将有一天无法应对。为此,我们需要一个协调员-负责管理整个动物园的人。
原来是这样的:

每个工作人员的负载都是“鹦鹉”,并且按CPU的百分比定期将主服务器(集线器)重置为收集器。然后,他可以根据这些数据发出命令,例如“将新主机放置在4号卸载的工作器上”或“必须将hostA转移到3号工作器”。
在这里,您还需要记住,与监视对象不同,收集器本身根本没有相等的“功率”,例如,一个收集器可能有8个CPU内核,而另一个则只有四个,甚至更低的频率。并且,如果您“平等地”加载任务,则第二个将开始“关闭”,第一个将处于空闲状态。因此,它遵循...
协调员的任务
实际上,只有一项任务-确保在所有可用工人中最均匀地分配整个负载(以%cpu计)。如果我们能够完美地解决它,那么将自动获得收集器上%cpu-load分布的均匀性。
显然,即使每个对象产生相同的负载,随着时间的流逝,它们中的一些也可能“消失”,并且出现一些新的。因此,您需要能够动态管理整个情况并不断保持平衡。
动态平衡
我们可以很简单地解决一个简单的问题(zabbix):
- 我们计算“任务”中每个收集器的相对容量
- 按比例划分所有任务
- 我们在工人之间平均分配

但是,如果“高度不相等”的对象(如日志收集器)怎么办?
均匀性评估
上面,我们一直使用术语“最大均匀分布”,但是如何正式比较两个分布,哪个是“更均匀”呢?
为了评估数学的均匀性,长期以来就有诸如标准偏差之类的东西。谁愿意读:
S[X] = sqrt( sum[ ( x - avg[X] ) ^ 2 of X ] / count[X] )由于每个收集器上的工人数量也可能对我们有所不同,因此负荷分布不仅应在它们之间进行标准化,而且在整个收集器之间也应标准化。
也就是说,两个收集器的工作人员之间的负载分配
[ (10%, 10%, 10%, 10%, 10%, 10%) ; (20%) ]也不是很好,因为第一个收集器的负载率为10%,第二个收集器的负载率为20%,相对而言,它是原来的两倍。
因此,我们为“均匀性”的一般估计引入了一个度量距离:
d([%wrk], [%col]) = sqrt( S[%wrk] ^ 2 + S[%col] ^ 2 )造型
如果我们有几个对象,那么我们可以用强力“分解”工人之间的对象,从而使度量标准最小。但是我们有成千上万的对象,因此此方法将不起作用。但是我们知道收集器能够将一个对象从一个工作人员“移动”到另一个工作人员-让我们使用梯度下降方法对该选项进行建模。
显然,我们可能找不到度量的“理想”最小值,但是本地度量是可以肯定的。而且负载本身会随时间变化很大,因此绝对不需要在无限时间内寻找“理想”产品。
也就是说,我们只需要确定“移动”最有效的对象和工作对象即可。让我们对其进行详尽的详尽建模:
- ( host, worker)
- host worker' «»
«» . - « »
- d «»
我们按照度量的升序排列所有对。理想情况下,我们应该始终执行第一对的转移,因为它提供了最小目标指标。不幸的是,实际上,传输过程本身会“耗费资源”,因此您不应为某个对象运行它的时间超过一定的“冷却”间隔。
在这种情况下,如果仅目标指标相对于当前值降低,我们可以将第二,第三,...乘以该对的排名。
如果无处可减少-这是当地的最小值!
图片中的示例:

完全没有必要“一直”开始迭代。例如,您可以在1分钟的间隔内进行平均负载分析,并在完成后执行一次转移。
微观优化
显然,具有复杂性的算法
T() x W()不是很好。但是在其中,您不应忘记应用或多或少的明显优化,这些优化有时可以加快速度。
零“鹦鹉”
如果一个对象/任务/主机在所测量的时间间隔上已产生“ 0件”的负载,则它不是可以移动到某处的东西-甚至不需要考虑和分析它。
自我转移
生成对时,无需评估将对象转移到已经位于该对象上的同一worker的效率。毕竟,它已经是
T x (W - 1)-一件小事,但是很好!
难以区分的负荷
由于我们正在对负载的传递进行建模,而对象只是一种工具,因此尝试传递“相同的”%cpu毫无意义-度量的值将保持完全相同,即使对象的分布不同。
也就是说,为元组评估单个模型就足够了(wrkSrc,wrkDst,%cpu)。好了,您可以考虑“等于”,例如,%cpu值最多匹配小数点后一位。
JavaScript示例实现
var col = {
'c1' : {
'wrk' : {
'w1' : {
'hst' : {
'h1' : 5
, 'h2' : 1
, 'h3' : 1
}
, 'cpu' : 80.0
}
, 'w2' : {
'hst' : {
'h4' : 1
, 'h5' : 1
, 'h6' : 1
}
, 'cpu' : 20.0
}
}
}
, 'c2' : {
'wrk' : {
'w1' : {
'hst' : {
'h7' : 1
, 'h8' : 2
}
, 'cpu' : 100.0
}
, 'w2' : {
'hst' : {
'h9' : 1
, 'hA' : 1
, 'hB' : 1
}
, 'cpu' : 50.0
}
}
}
};
// ""
let $iv = (obj, fn) => Object.values(obj).forEach(fn);
let $mv = (obj, fn) => Object.values(obj).map(fn);
// initial reparse
for (const [cid, c] of Object.entries(col)) {
$iv(c.wrk, w => {
w.hst = Object.keys(w.hst).reduce((rv, hid) => {
if (typeof w.hst[hid] == 'object') {
rv[hid] = w.hst[hid];
return rv;
}
// ,
if (w.hst[hid]) {
rv[hid] = {'qty' : w.hst[hid]};
}
return rv;
}, {});
});
c.wrk = Object.keys(c.wrk).reduce((rv, wid) => {
// ID -
rv[cid + ':' + wid] = c.wrk[wid];
return rv;
}, {});
}
//
let S = col => {
let wsum = 0
, wavg = 0
, wqty = 0
, csum = 0
, cavg = 0
, cqty = 0;
$iv(col, c => {
$iv(c.wrk, w => {
wsum += w.cpu;
wqty++;
});
csum += c.cpu;
cqty++;
});
wavg = wsum/wqty;
wsum = 0;
cavg = csum/cqty;
csum = 0;
$iv(col, c => {
$iv(c.wrk, w => {
wsum += (w.cpu - wavg) ** 2;
});
csum += (c.cpu - cavg) ** 2;
});
return [Math.sqrt(wsum/wqty), Math.sqrt(csum/cqty)];
};
// -
let distS = S => Math.sqrt(S[0] ** 2 + S[1] ** 2);
//
let iterReOrder = col => {
let qty = 0
, max = 0;
$iv(col, c => {
c.qty = 0;
c.cpu = 0;
$iv(c.wrk, w => {
w.qty = 0;
$iv(w.hst, h => {
w.qty += h.qty;
});
w.max = w.qty * (100/w.cpu);
c.qty += w.qty;
c.cpu += w.cpu;
});
c.cpu = c.cpu/Object.keys(c.wrk).length;
c.max = c.qty * (100/c.cpu);
qty += c.qty;
max += c.max;
});
$iv(col, c => {
c.nrm = c.max/max;
$iv(c.wrk, w => {
$iv(w.hst, h => {
h.cpu = h.qty/w.qty * w.cpu;
h.nrm = h.cpu * c.nrm;
});
});
});
// ""
console.log(S(col), distS(S(col)));
//
let wrk = {};
let hst = {};
for (const [cid, c] of Object.entries(col)) {
for (const [wid, w] of Object.entries(c.wrk)) {
wrk[wid] = {
wid
, cid
, 'wrk' : w
, 'col' : c
};
for (const [hid, h] of Object.entries(w.hst)) {
hst[hid] = {
hid
, wid
, cid
, 'hst' : h
, 'wrk' : w
, 'col' : c
};
}
}
}
// worker
let move = (col, hid, wid) => {
let w = wrk[wid]
, h = hst[hid];
let wsrc = col[h.cid].wrk[h.wid]
, wdst = col[w.cid].wrk[w.wid];
wsrc.cpu -= h.hst.cpu;
wsrc.qty -= h.hst.qty;
wdst.qty += h.hst.qty;
// "" CPU
if (h.cid != w.cid) {
let csrc = col[h.cid]
, cdst = col[w.cid];
csrc.qty -= h.hst.qty;
csrc.cpu -= h.hst.cpu/Object.keys(csrc.wrk).length;
wsrc.hst[hid].cpu = h.hst.cpu * csrc.nrm/cdst.nrm;
cdst.qty += h.hst.qty;
cdst.cpu += h.hst.cpu/Object.keys(cdst.wrk).length;
}
wdst.cpu += wsrc.hst[hid].cpu;
wdst.hst[hid] = wsrc.hst[hid];
delete wsrc.hst[hid];
};
// (host, worker)
let moveCheck = (orig, hid, wid) => {
let w = wrk[wid]
, h = hst[hid];
// -
if (h.wid == w.wid) {
return;
}
let col = JSON.parse(JSON.stringify(orig));
move(col, hid, wid);
return S(col);
};
// (hsrc,hdst,%cpu)
let checked = {};
// ( -> )
let moveRanker = col => {
let currS = S(col);
let order = [];
for (hid in hst) {
for (wid in wrk) {
// ( 0.1%) ""
let widsrc = hst[hid].wid;
let idx = widsrc + '|' + wid + '|' + hst[hid].hst.cpu.toFixed(1);
if (idx in checked) {
continue;
}
let _S = moveCheck(col, hid, wid);
if (_S === undefined) {
_S = currS;
}
checked[idx] = {
hid
, wid
, S : _S
};
order.push(checked[idx]);
}
}
order.sort((x, y) => distS(x.S) - distS(y.S));
return order;
};
let currS = S(col);
let order = moveRanker(col);
let opt = order[0];
console.log('best move', opt);
//
if (distS(opt.S) < distS(currS)) {
console.log('move!', opt.hid, opt.wid);
move(col, opt.hid, opt.wid);
console.log('after move', JSON.parse(JSON.stringify(col)));
return true;
}
else {
console.log('none!');
}
return false;
};
// -
while(iterReOrder(col));结果,我们水库的负荷几乎在每个时刻均等地分布,迅速平整正在出现的山峰: