-晚上好,我叫Masha,我在Eddila数据分析部门工作,今天我们与您进行测试讲座。

首先,我们将与您讨论总体上有哪些类型的测试,我将尝试说服您为什么需要编写测试。然后,我们将讨论在Python中可以直接与测试一起使用的功能,以及它们的编写和辅助模块。最后,我将向您介绍一些关于CI的信息-CI是大公司生活中不可避免的一部分。
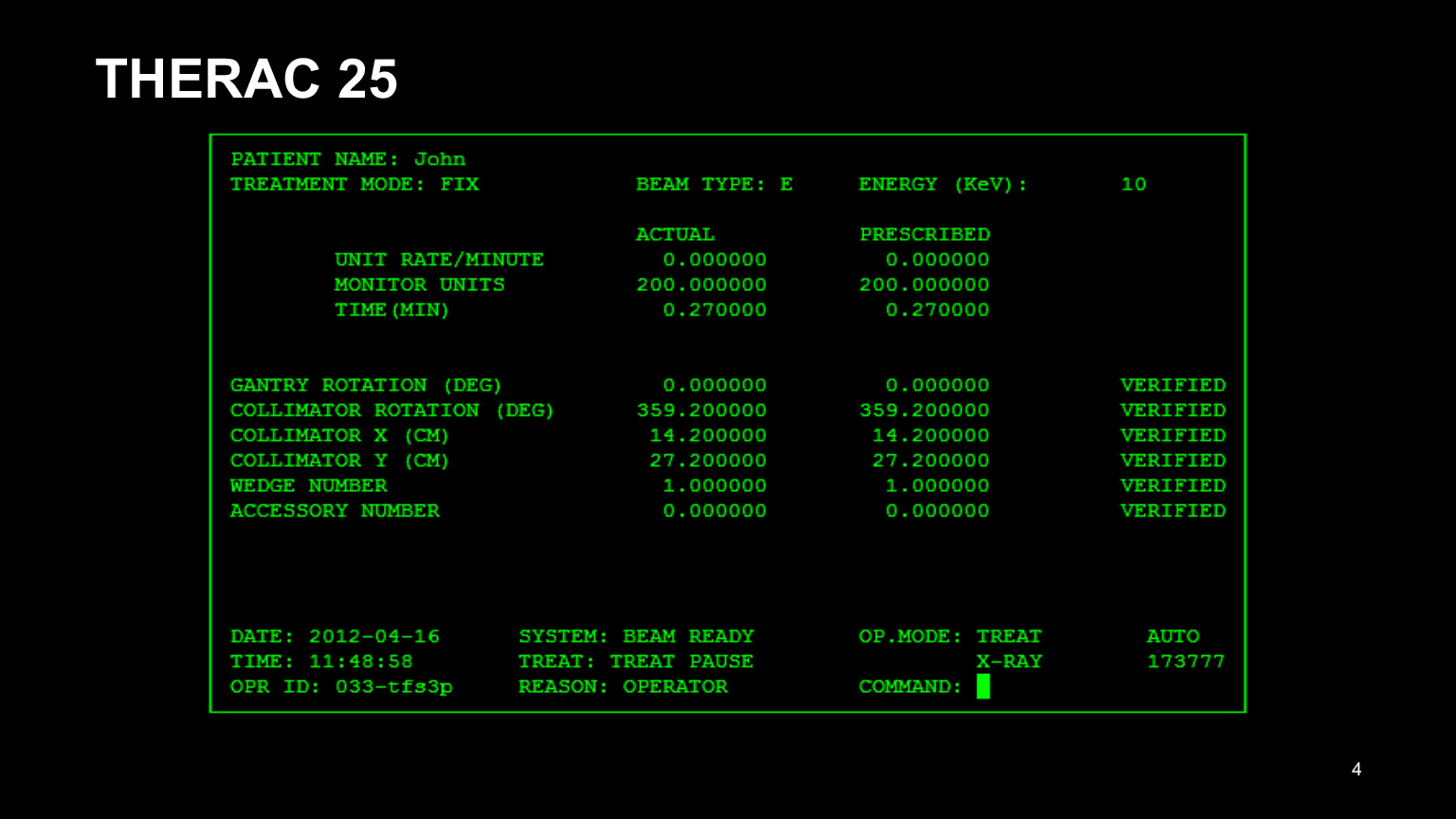
我想举一个例子。我将尝试用非常可怕的示例来解释为什么值得编写测试。
这是THERAC 25程序的界面,这是用于癌症患者放射治疗的设备的名称,并且一切都变得非常糟糕。首先,它的界面不好。看着他,人们已经可以理解他不是很好:医生很难以所有这些数字开车。结果,他们复制了先前患者记录中的数据,并尝试仅编辑需要编辑的内容。
显然,他们忘了纠正一半,并弄错了。结果,患者得到了不正确的治疗。 UI也值得测试,从来没有太多的测试。
但是除了不良的界面外,后端还有许多其他问题。我确定了两个在我看来最糟糕的事情:
- . , . , . , .
- C . THERAC , — , . . , , , - , - — .
值得编写测试。因为它最终有5例记录在案的死亡人数,而且尚不清楚有多少人因服用过多毒品而遭受痛苦。

还有另一个例子,在某些情况下编写测试可以为您节省很多钱。这就是火星气候轨道器-一种应该用来测量火星大气层中的大气的装置,以了解那里的气候发生了什么。
但是,地面上的模块在SI系统,公制系统中发出命令。火星轨道上的模块认为这是英国的测量系统,对它的解释不正确。
结果,模块以错误的角度进入大气并坍塌。尽管似乎有可能在测试中模拟这种情况并避免这种情况,但1.25亿美元才刚刚投入到垃圾中。但这没有解决。
现在,我将讨论为什么您应该编写测试的更平淡的原因。让我们分别讨论每个项目:
- 测试可以确保您的代码有效,并且可以使您平静一些。在编写测试的情况下,可以肯定的是,该代码可以正常工作-当然,如果编写得很好。睡得更好 这是非常重要的。
- . . , , , . , . , .
, - , — , - . , . , , . , , , git blame, , , , . - . , . , . , , . - - , - - . , , , . - .
- , . ? , , , , : , . 500 -, . . .
- : — . , , . , , .
, , , . , , . - . — , . , , . , .
: - . , , . , , , - , .
现在,我想谈谈测试类型的分类是什么。有很多。我只会提及一些。
测试过程分为黑盒测试,白色和灰色测试。
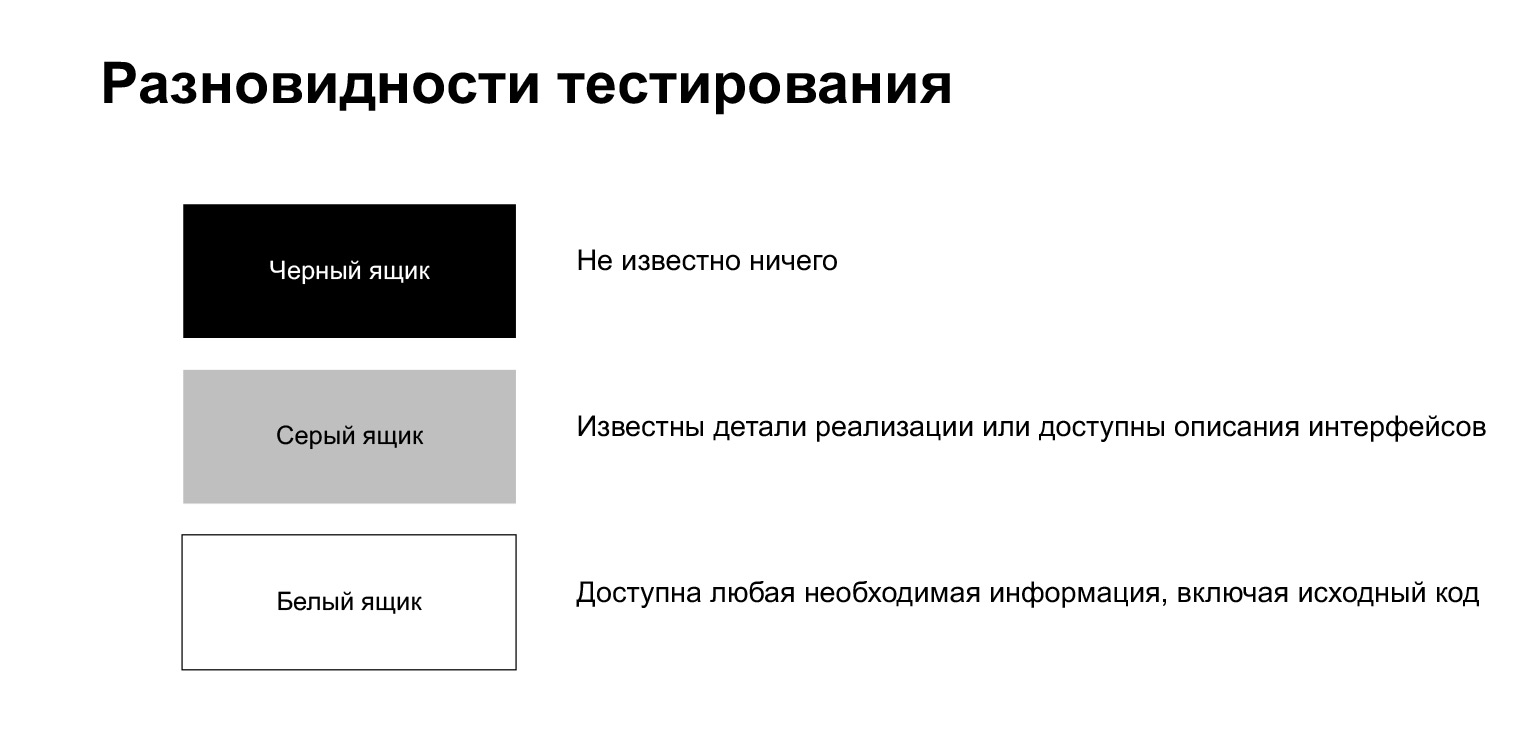
黑匣子测试是指测试人员对内部内容一无所知的过程。他像普通用户一样,在不了解任何实现细节的情况下执行了某些操作。
白盒测试意味着测试人员可以访问他需要的任何信息,包括源代码。在我们自己的代码上编写测试时,我们处于这种情况。
灰盒测试介于两者之间。这是当您知道一些实现细节,而不是全部的时候。
而且,测试过程可以分为手动,半自动和自动。手动测试是由一个人完成的。假设他点击了浏览器中的按钮,点击了某处,看起来是什么东西坏了或没坏。半自动测试是指测试人员运行测试脚本的时间。可以说,在本地运行测试时,我们处于这种情况。自动化测试不涉及人工参与:测试应自动运行,而不要人工运行。
同样,可以按详细程度划分测试。在这里,它们通常分为单元测试和集成测试。可能会有差异。有人称任何自动测试为单元测试。但是更经典的划分是这样的。
单元测试检查系统各个组件的运行,集成测试检查某些模块的捆绑销售。有时,还有一些系统测试可以检查整个系统的整体运行情况。但这似乎是集成测试的一大变体。
我们代码的测试是单元测试和集成测试。有些人认为只应编写集成测试。我不是其中之一,我认为一切都应该适度,并且在测试一个组件时进行单元测试,在测试大型组件时进行集成测试都是有用的。
我为什么这么认为?因为单元测试通常更快。当您需要调整某些内容时,您会非常恼火,因为您单击了“运行测试”按钮,然后等待三分钟以启动数据库,进行迁移,然后发生了其他事情。在这种情况下,单元测试很有用。它们可以快速方便地运行,一次运行一次。但是,一旦您修复了单元测试,那就好了,让我们修复集成测试。
集成测试也是非常必要的事情,最大的好处是它们与系统有关。另一个大优点:它们更耐代码重构。如果您更有可能重写某些小功能,则您不太可能以相同的频率更改整个管道。

还有更多不同的分类。我将快速浏览我在这里写的内容,但我不会详细介绍,这些是您在其他地方可以听到的词。
冒烟测试是针对关键功能的测试,这是第一个也是最简单的测试。如果它们损坏了,则您不再需要测试,而是需要去修复它们。假设应用程序已启动,但没有崩溃-太好了,烟雾测试通过了。
有回归测试-测试旧功能。假设您推出了一个新版本,并且必须检查旧版本中没有损坏。这是回归测试的任务。
有兼容性测试,安装测试。他们会检查在不同的OS和不同的OS版本,不同的浏览器和不同的浏览器版本中,一切是否都能正常工作。
验收测试是验收测试。我已经谈论过它们,他们谈论您的更改是否可以投入生产。
还有alpha和beta测试。这两个概念都与产品更相关。通常,当您拥有或多或少准备好的版本时,但并非所有内容都已固定在那里,您可以将其提供给有条件的外部人员或外部人员(志愿者),以便他们为您找到错误并进行报告,然后可以发布非常好的版本。 Alpha版本完成得越少,Beta版本完成得越多。在Beta测试中,到目前为止,几乎所有内容都应该没问题。
然后是性能和压力测试,负载测试。他们检查例如您的应用程序如何处理负载。有一些代码。您已经计算出有多少用户,它将拥有多少请求,什么RPS,每秒将有多少请求。我们模拟了这种情况,启动了它,看起来-它成立了,不成立了。如果不成立,请考虑下一步该怎么做。为了优化代码或增加硬件数量,可能有不同的解决方案。
压力测试大致相同,只是负载高于预期。如果性能测试给出了您期望的负载水平,那么在压力测试中,您可以增加负载直到损坏。
短绒在这里分开站立。稍后我将介绍有关linter的知识,这些是代码格式化测试和样式指南。在Python中,我们很幸运拥有PEP8,这是每个人都应该遵循的简单明了的样式指南。而且,当您编写某些东西时,通常会发现很难遵循这些代码。假设您忘了留空行,或者做了多余的行,或者留下了太长的行。之所以会这样,是因为您已经习惯了以相同样式编写代码的事实。短绒可以让您自动捕获此类东西。
通过理论,一切,然后我将讨论Python中的内容。

这是一些库的列表。我不会详细介绍所有这些,但我会介绍大多数。当然,我们将讨论unittest和pytest。这些是直接用于编写测试的库。 Mock是用于创建模拟对象的帮助程序库。我们还将讨论她。 doctest是用于测试文档的模块,flake8是linter,我们还将对其进行研究。我不会谈论pylama和tox。如果您有兴趣,可以自己看看。 Pylama还是短绒棉,甚至是金属短绒棉,它结合了多个包装,非常方便且不错。如果需要在不同的环境中(例如,使用不同版本的Python或不同版本的库)测试代码,则需要tox库。从这个意义上说,Tox很有帮助。
但是在讨论不同的库之前,我将首先介绍平庸性。随意在代码中使用assert。这不是耻辱。它通常有助于了解发生了什么。

假设有一个计算序数统计量的函数,向其中写入了两个断言。在完全没有意义的情况下,应该在函数中编写断言。这些都是非常极端的情况,很可能您甚至在生产中都不会遇到。也就是说,如果您弄乱了代码,很可能在测试中失败。
断言可在原型设计时提供帮助,您尚无生产代码,可以在任何地方(在被调用的函数中,在任何地方)使用断言。这对于严肃的项目不是很好,但是在原型设计阶段就很好。
假设您出于某种原因要禁用断言-例如,您希望它在生产中永远不会触发。 Python为此提供了一个特殊选项。

我会告诉你什么是doctest。这是一个模块,一个用于测试文档的Python标准库。为什么好呢?用代码编写的文档往往会经常中断。这里有一个非常小的玩具功能,您可以看到所有内容。但是,如果您的代码很大,参数很多并且在末尾添加了一些内容,那么很有可能您会忘记更正文档字符串。 Doctest避免了这些事情。您修复了某些问题,请不要在此处更新,请运行doctest,否则它将崩溃。因此,您将记住您未正确纠正的内容,然后去纠正。
它是什么样子的? Doctest在文档字符串中查找这些圣诞树,然后执行它们并比较获得的结果。

这是运行doctest的示例。我们启动了它,我们看到我们进行了两项测试,其中一项跌落了-完全在案子上。太好了,我们看到了一些有关该错误的明确信息。

幻灯片链接
doctest有一些有用的指令可能会派上用场。我不会讨论所有这些内容,但是我认为其中一些最常见,放在幻灯片上。 SKIP伪指令允许您不要在带有标记的示例上运行测试。 IGNORE_EXCEPTION_DETAIL指令将忽略EXCEPTION测试。 ELLIPSIS允许您在输出中的任何地方写省略号。第一次失败的测试后,FAIL_FAST停止。其他所有内容均可在文档中阅读,内容很多。我最好举个例子给你看。

此示例具有ELLIPSIS指令和IGNORE_EXCEPTION_DETAIL指令。您可以在ELLIPSIS指令的第K个序数统计中看到,并且我们期望会出现一些结果,从9开始到9结束。中间可能有什么。这样的测试不会失败。
下面是IGNORE_EXCEPTION_DETAIL指令,它将仅检查AssertionError中出现的内容。瞧,我们在那儿写了等等。测试将通过,它不会将第一个参数与预期的可迭代性进行比较。它将只比较AssertionError和AssertionError。这些是有用的东西,您可以使用。

那么计划是这样的:我将告诉您有关unittest,然后是pytest的信息。我马上要说,除了它是标准库的一部分之外,我可能不了解单元测试的优点。我看不到会迫使我现在使用unittest的情况。但是有些项目正在使用它,在任何情况下,了解语法的外观和含义都是很有用的。
另一点:用unittest编写的测试知道如何立即运行pytest。他不在乎。 (…)单元
测试看起来像这样。有一个以单词test开头的课程。在内部,以单词test开头的函数。测试类继承自unittest.TestCase。我必须马上说,这里的一个测试写的正确,而另一个测试是不正确的。
写入普通断言的最高测试将失败,但是看起来很奇怪。让我们来看看。

启动命令。您可以在代码本身中编写unittest main,也可以从Python调用它。

我们运行了这个测试,我们看到它编写了一个AssertionError,但是它没有写出它的下落-与下一个使用self.assertEqual的测试不同。清楚地写在这里:三个不等于两个。

当然,必须修理。但是随后在屏幕上看不到该魔术输出。
让我们再看一看。在第一种情况下,我们在第二种情况下写了assert,即self.assertEqual。不幸的是,这是单元测试的唯一方法。有一些特殊功能-self.assertEqual,self.assertnotEqual和另外100,500个功能,如果您想查看足够的错误消息,则需要使用。
为什么会发生?因为assert是一个接收bool以及可能是字符串的语句,但是在这种情况下是bool。他发现自己是对还是错,他无处可走。因此,unittest具有特殊功能,可以正确显示错误消息。
我认为这不是很方便。更确切地说,这根本不方便,因为这些是仅在此库中的一些特殊方法。它们不同于我们惯用的普通语言。

您不必记住这一点-我们稍后将讨论pytest,我希望您能主要在其中进行编写。如果您想测试某些东西并获得良好的错误消息,Unittest可以使用许多功能。
接下来,让我们讨论一下如何在unittest中编写fixture。但是要做到这一点,我首先需要告诉您什么是灯具。这些是在测试运行之前或之后调用的函数。如果测试需要执行特殊设置,则需要使用它们-测试后创建一个临时文件,删除该临时文件;创建数据库,删除数据库;创建一个数据库,向它写一些东西。总的来说。让我们看看它在单元测试中的外观。

Unittest具有用于编写固定装置的特殊方法setUp和tearDown。为什么仍然没有按照PEP8编写它们,这对我来说是一个很大的谜。 (...)
SetUp是测试之前执行的操作,tearDown是测试之后执行的操作。在我看来,这是一个极为不便的设计。为什么?因为,首先,我的手不会抬起来写下这些名字:我已经生活在一个仍然有PEP8的世界中。其次,您有一个临时文件,该文件本身在测试本身的参数中没有任何内容。他来自哪里?尚不清楚它为什么存在以及它的全部含义。
当我们有一个紧贴屏幕的小类时,它很酷,可以通过外观捕捉它。当您拥有这张大床单时,您会遭受酷刑,寻找那是什么,为什么他会那样,为什么他会那样。
单元测试中的夹具还有另一个不太方便的功能。假设我们有一个需要一个临时文件的测试类,而另一个需要一个数据库的测试类。优秀的。您编写了一个类,执行了setUp,tearDown,创建/删除了一个临时文件。我们编写了另一个类,在其中我们还编写了setUp,tearDown,在其中创建/删除了一个数据库。
题。第三组测试需要同时进行。这一切怎么办?我看到两个选择。或者获取并复制粘贴代码,但这不是很方便。或创建一个新类,从前两个继承它,然后调用super。通常,这也可以使用,但是看起来对于测试来说是一个过大的杀伤力。

因此,我希望您在理论上保持对单元测试的熟悉。接下来,我们将讨论一种更方便的编写测试方法,一个更方便的库,这就是pytest。
首先,我将尝试告诉您pytest为什么方便。

幻灯片的链接
第一点:在pytest中,断言通常可以正常工作,您习惯的是断言,并且它们提供正常的错误信息。第二:pytest有很好的文档,其中分解了许多示例,您可以查看任何您想了解的内容。
第三,测试只是以test_开头的函数。也就是说,您不需要额外的类,只需编写一个常规函数,将其称为test_即可通过pytest运行。之所以方便,是因为编写测试越容易,编写测试而不是给分数打分的可能性就越大。
Pytest具有许多方便的功能。您可以编写参数化测试,可以方便地编写不同级别的灯具,还可以使用一些技巧:xfail,raises,skip等。 pytest中有许多插件,此外您还可以编写自己的插件。

让我们来看一个例子。这就是用pytest编写的测试的样子。含义与unittest相同,只是看起来更加简洁。第一次测试通常是两行。

运行命令python -m pytest。优秀的。通过了两次测试,一切都很好,我们可以看到它们通过了什么,什么时候通过了。

现在,让我们打破一个测试并进行测试,以便获得有关错误的信息。打印断言3 == 2和错误。也就是说,我们看到了:尽管事实上我们编写了一个常规的断言,但我们仍正确显示了有关错误的信息,尽管在单元测试之前,我们说断言接受了字符串或布尔值中的布尔值,所以显示有关错误的信息是有问题的。
有人可能想知道为什么这一切有效?因为pytest尽了最大努力并清理了界面的丑陋部分。 Pytest首先解析您的代码,它看起来像是一种树结构,即抽象语法树。在此结构中,顶点处有运算符,叶子处有操作数。断言是一个运算符。它位于树的顶部,此刻,在将所有内容提供给解释器之前,您可以使用内部功能来替换此断言,该功能进行自省并了解左侧和右侧的内容。实际上,这已经被提供给解释器,而assert被替换了。
我不会详细介绍,有一个链接上,您可以阅读他们的操作方式。但我喜欢这一切都在幕后运作。用户看不到它。正如他习惯的那样,他写断言,而库本身负责其余的工作。您甚至不必考虑它。
进一步在pytest中使用标准类型,无论如何您都会获得良好的错误信息。因为pytest知道如何显示此错误信息。但是您可以在测试中比较自定义数据类型,例如树或复杂的东西,而pytest可能不知道如何显示它们的错误信息。对于这种情况,你可以添加一个特殊的钩-在这里是一个部分的文档-在这个钩子怎么写错误的信息应该是。一切都非常灵活和方便。

让我们看一下夹具在pytest中的样子。如果在单元测试中有必要编写setUp和tearDown,则可以在此处随意调用常用函数。我们在顶部编写了pytest.fixture装饰器-太好了,这是一个固定装置。
这不是最简单的例子。夹具可以做一个返回,返回一些东西,这类似于setUp。在这种情况下,它将产生某种tearDown,即在此处,在测试结束后,它将调用close,并且将删除临时文件。
似乎很方便。您具有任意函数,可以随意命名。您将其明确传递给测试。通过filled_file,您知道它是什么。您不需要任何特别的东西。通常,使用它。这比unittest方便得多。

有关固定装置的更多信息。在pytest中,创建不同范围的夹具非常容易。默认情况下,使用功能级别创建夹具。这意味着您通过它的每个测试都将调用它。也就是说,如果有成品率或类似tearDown的情况,则在每次测试后也会发生这种情况。
您可以声明scope ='module',然后夹具将对每个模块执行一次。假设您只想创建一个数据库,而又不想在每次测试后删除并滚动所有迁移。
同样在fixture中,可以指定autouse = True参数,然后无论您是否要求,都会调用该fixture。似乎永远不要使用或应该使用此选项,但要非常小心,因为它是隐式的东西。最好避免隐式。

我们运行了这段代码-让我们看看发生了什么。有一个取决于夹具的测试,需要时可一次打电话给我,每次都打电话给我。同时,在需要时给我打电话是模块级夹具。我们看到,我们第一次调用fixtures时会在需要时调用我一次,每次都调用我,这会输出,但是也调用了具有autouse的fixture,因为它不在乎,因此总是被调用。
第二项测试取决于相同的夹具。我们看到第二次调用我一次使用时没有被打印,因为它是在模块级别上的,因为它已经在模块级别被调用了,因此不会再次调用。
另外,从这个示例中,您可以看到pytest并没有我们在unittest中谈到的问题,当在一个测试中您可能需要一个数据库,而在另一个测试中您可能需要一个数据库(一个临时文件)。通常如何聚合它们尚不清楚。这是pytest中此问题的答案。如果通过了两个灯具,则内部将有两个灯具。
优秀,非常舒适,没问题。灯具非常灵活,可以依赖于其他灯具。这没有矛盾,并且pytest会以正确的顺序调用它们。

实际上,您可以在内部从其他灯具继承灯具,使它们的范围有所不同,并且可以自动使用而无需自动使用。他本人将按照正确的顺序安排它们并给他们打电话。
在这里,我们有第一个测试,即测试一个,它取决于罕见的依赖关系_for_test_one,其中此夹具取决于另一个夹具-还有一个。让我们看看排气中会发生什么。
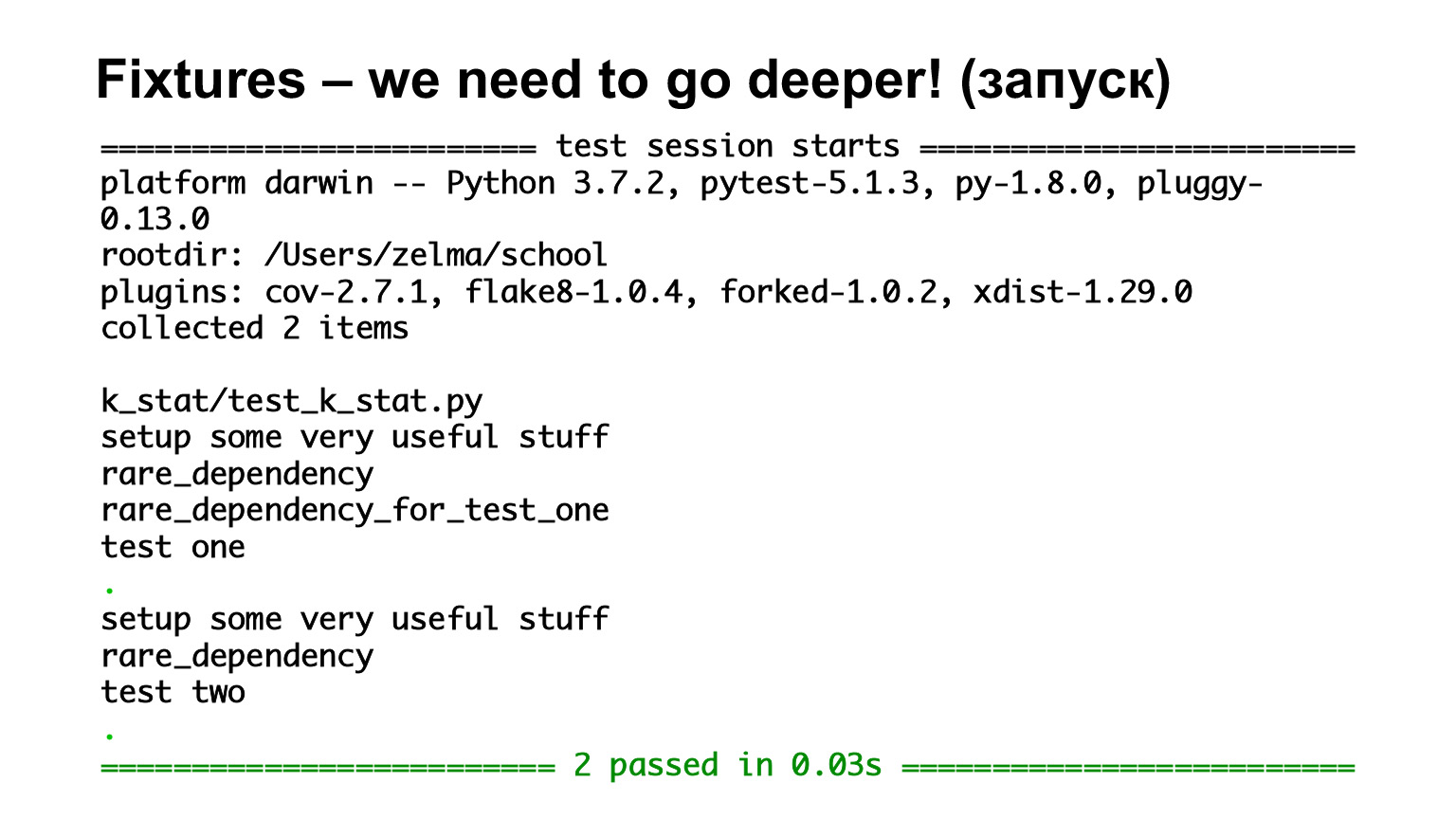
我们已经看到,它们按继承顺序被调用。有所有功能级别的固定装置,因此每次测试都需要调用它们。第二个测试取决于稀土稀有度,而稀土依赖性取决于some_common_dependency。我们查看了排气口,发现在测试之前调用了两个固定装置。
Pytest有一个特殊的配置文件conftest.py,您可以在其中放置所有的固定装置,如果您放了它,那就很好了:通常,当一个人查看别人的代码时,他通常会在conftest中查看固定装置。
这不是强制性的。如果在此文件中仅需要一个固定装置,并且可以确定它是特定的,狭义适用的,并且不需要在另一个文件中使用它,则可以在该文件中声明它。或创建很多比赛,它们都会在不同的级别上起作用。

让我们谈谈pytest中的功能。如我所说,参数化测试非常容易。在这里,我们看到一个具有三组参数的测试:两个输入和一个预期的参数。我们将它们传递给函数参数,看看传递给输入的内容是否与预期的相符。

让我们看看它的外观。我们看到有三个测试。也就是说,pytest认为这是三个测试。两人过去了,一人摔倒了。这有什么好对于下降的测试,我们可以看到参数,可以看到它落在哪组参数上。
同样,当您的函数较小且参数设置为3时,您可能会用肉眼看到到底掉了什么。但是,当参数中有很多设置时,您将看不到它。相反,您会看到的,但对您而言将非常困难。 pytest以这种方式显示所有内容非常方便-您可以立即看到测试失败的情况。

参数化是一件好事。而且,当您编写一次测试,然后执行许多很多参数集时,这是一个好习惯。不要为类似的测试创建许多代码变体,而只需编写一次测试,然后创建大量参数,它就会起作用。
pytest中还有很多有用的东西。如果您谈论它们,那么讲座显然不够,因此,我将只展示其中一些。第一个测试使用pytest.raises()来表明您期望发生异常。也就是说,在这种情况下,如果引发AssertionError,则测试将通过。您应该抛出异常。
第二方便的是xfail。它是一个装饰器,它允许测试失败。假设您有很多测试,很多代码。您重构了某些内容,测试开始失败。同时,您了解它不是很关键,或者修复起来非常昂贵。就像这样:好的,我要在其上悬挂一个装饰器,它会变成绿色,稍后再修复。还是假设测试开始泛滥。显然,这是一个符合自己良心的协议,但有时是必须的。而且,无论测试是否通过,此形式的xfail均为绿色。您仍然可以将其传递给Strict = True参数,这将是一个稍微不同的情况,pytest将等待测试失败。如果测试通过,将返回错误消息,反之亦然。
另一个有用的东西是skipif。只是跳过而不会运行测试。还有skipif。如果将鼠标悬停在此装饰器上,则该测试将在某些条件下无法运行。
在这种情况下,如果我安装了Mac平台,则由于无法进行测试,因此无法启动。它发生了。但是总的来说,有特定于平台的测试将始终在特定平台上失败。这很有用。

让我们开始吧。我们看到了字母X,我们看到了S。这里的X表示xfail,S-表示skipif。也就是说,pytest显示了我们完全错过了哪个测试以及我们运行了哪个测试,但是我们不看结果。

pytest本身有许多不同的有用选项。我当然不能在这里显示它们,您可以在文档中查看。但我会告诉你一些。
这是一个有用的--collect-only选项。它显示找到的测试的列表。有一个选项-k-按测试名称过滤。这是我最喜欢的选项之一:如果一项测试失败,特别是如果测试很复杂,并且您还不知道如何解决它,请过滤并运行它。
您想节省时间,可能不希望再运行15个其他测试-您知道它们通过或失败,但是您还没有参加。运行崩溃的测试,将其修复并继续。
还有一个非常不错的选项-s,它可以在测试中启用stdout和stderr的输出。默认情况下,pytest将仅输出stdout和stderr用于失败的测试。但是有时,通常是在调试阶段,您想在测试中输出某些内容,却不知道测试是否会失败。它可能不会掉下来,但是您想在测试本身中查看其中的内容和输出。然后使用-s运行,您应该看到所需的内容。
-v是标准的详细选项,增加详细程度。
--lf,-last-failed是一个选项,允许您仅重新启动在上次运行中失败的测试。 --sw,-stepwise也是有用的功能,例如-k。如果按顺序修复测试,则使用--stepwise进行运行,它将通过绿色测试,并且一旦看到失败的测试,它将停止。当您再次运行--sw时,它将以崩溃的测试开始。如果它再次下降,它将再次停止;如果它没有下降,它将继续运行直到下一次下降。

幻灯片中的链接
在pytest中,有一个主要的配置文件pytest.ini。在其中,您可以更改pytest的默认行为。我在这里给出了配置文件中经常出现的选项。
测试路径是pytest搜索测试的路径。 addopts是启动时添加到命令行的内容。在这里,我向addopts添加了flake8和coverage插件。我们待会儿再看。

幻灯片中的链接
pytest中有很多不同的插件。我写了那些再次被广泛使用的文章。 flake8是一个linter,覆盖率是测试的代码覆盖率。然后是一整套的插件,可以更轻松地使用某些框架:pytest-flask,pytest-django,pytest-twisted,pytest-tornado。可能还有别的东西。
如果要并行运行测试,请使用xdist插件。超时插件使您可以限制测试运行时间:这很方便。您将超时装饰器挂在测试上,如果测试花费更长的时间,它将失败。

让我们来看看。我在pytest.ini中添加了coverage和flake8。 Coverage给了我一份报告,我那里有一个带有测试的文件,没有调用它,但是没关系:)
这是文件k_stat.py,它包含多达五个语句。这与五行代码大致相同。覆盖率是100%,但这是因为我的文件很小。
实际上,覆盖率通常不是百分之一百,而且,它绝不能以任何方式实现。从主观上讲,似乎60-70%的测试覆盖率足够正常工作。
覆盖率是一个指标,即使是百分之一百,也并不表示您很棒。您调用此代码的事实并不意味着您已检查了某些内容。您也可以在最后写断言True。您需要合理地接近覆盖率,对于100%的测试覆盖率,有衰落和机器人,但是人们不需要这样做。
在pytest.ini中,我还连接了一个插件。在这里,您可以看到--flake8,这是显示我的样式错误的linter,还有一些不是来自PEP8,而是来自pyflakes。

在这里,在排气管中写有PEP8或pyflakes中的错误号。总的来说,一切都很清楚。该行太长,要进行重新定义,您需要两个空行,在文件末尾需要一个空行。最后,它说我不使用CitizenImport。通常,使用linter可以捕获重大错误和代码设计错误。

我们已经讨论过超时插件,它允许您限制测试运行时间。对于某些性能而言,运行时间很重要。您可以将它限制在test.time和timeit内部测试中。或使用超时插件,这也非常方便。如果测试工作太多,则可以通过不同的方式对它进行概要分析,例如cProfile,但是Yura将在他的演讲中讨论这一点。
如果您使用的是IDE,并且值得使用辅助工具,那么我在这里特别是PyCharm,那么直接从中运行测试非常容易。

剩下要谈论模拟了。假设我们有模块A,我们要对其进行测试,还有其他模块我们不想进行测试。其中一个进入网络,另一个进入数据库,第三个是一个简单的模块,不会以任何方式困扰我们。在这种情况下,模拟将为我们提供帮助。同样,如果我们正在编写集成测试,则很可能会启动一个测试数据库,编写一个测试客户端,这也很好。这只是一个集成测试。
有时候我们只想测试一个,就要做单元测试。然后我们需要一个模拟。

模拟是对象的集合,可用于替换实际对象。在对方法,属性的任何调用中,它也会返回模拟。

在这个例子中,我们有一个简单的模块。我们将保留它,并用模拟代替一些更复杂的模型。现在,我们将了解其工作原理。

此处清楚显示。我们导入了它,我们说m是一个模拟。叫回模拟。他们说m有方法f。叫回模拟。他们说m是is_alive属性。太好了,又有一个模拟又回来了。我们看到m和f被调用一次。也就是说,它是一个棘手的对象,在其中重写了getattr方法。

让我们看一个更清晰的例子。假设有一个AliveChecker。他使用某种http_session,他需要一个目标,并且他具有一个do_check函数,该函数根据是否收到200来返回True或false。这是一个虚假的示例。但是假设在do_check内部,您可以结束复杂的逻辑。
假设我们不想测试任何有关会话的信息,我们不想了解有关get方法的任何信息。我们只想测试do_check。太好了,让我们测试一下。

你可以这样模拟http_session,在这里称为pseudo_client。我们模拟她的get方法,说get是一个返回200的模拟。我们启动,从中创建一个AliveChecker,然后启动它。此测试将起作用。
另外,让我们检查一次get,并且使用与编写的参数完全相同的参数。就是说,我们在不知道会话是什么或其方法是什么的情况下调用了do_check。我们只是冻结他们。我们唯一知道的是它返回了200。

另一个例子。它与上一个非常相似。这里唯一的东西是side_effect而不是return_value。但这是模拟程序所做的。在这种情况下,它将引发异常。断言行已更改为断言不是AliveChecker.do_check()。也就是说,我们看到支票不会通过。
这是两个示例,这些示例说明了如何在不了解上层内容,此类内容的情况下测试do_check函数。
当然,该示例看起来是人为的:尚不清楚为什么检查(200或不检查200)逻辑最少。但是,让我们想象一下,根据返回代码来做一些棘手的事情。然后,这样的测试似乎变得更加有意义。我们看到200个字符,然后检查处理逻辑。如果不是200-相同。

您也可以使用模拟补丁库。假设您已经有一个库,需要在其中进行一些更改。这是一个示例,我们已对正弦进行了修补。现在,他总是返回一个平局。优秀的。
我们还看到m被调用了两次。当然,Mock对您所模拟的方法的内部API一无所知,通常不需要匹配它们。但是模拟可让您检查调用的内容,次数和参数。从这个意义上讲,它有助于测试代码。

我想警告您,如果有一个模块和一个巨大的模拟对象。请合理处理所有事情。如果您有简单的东西,请不要弄湿它们。测试中包含的模拟越多,您越远离现实:您的API可能不匹配,并且通常来说,这与您所测试的不完全相同。您不需要浸泡所有东西。智能地处理过程。

我们剩下关于持续集成的最后一部分。当您独自开发一个宠物项目时,可以在本地运行测试,没关系,它们会起作用。
一旦项目发展,并且其中有多个开发人员,它就会停止工作。首先,一半不会在本地运行测试。其次,他们将在其版本上运行它们。某个地方会发生冲突,一切都会不断崩溃。
为此,需要进行持续集成,这是一种开发实践,需要快速将候选人注入主流。但同时,他们必须在特殊系统中进行某种自动组装或自动测试。您在存储库中有代码,您要合并到主项目分支中的提交。在这些提交上,测试将在特殊系统中通过。如果测试是绿色的,则要么提交本身被提交,要么您有机会将其倒入。
这样的方案当然也有缺点,也有缺点。至少,您需要其他硬件,而不是CI是免费的。但是,在或多或少的大型公司中,也无论是大型公司,如果没有CI,您将无所不能。
例如-来自CI之一TeamCity的屏幕截图。有一个程序集,它已成功完成。它有很多变化,它是在某时某某时间在某某代理程序上启动的。这是什么都可以并且可以注入的例子。
有许多不同的CI系统。我写了一份清单,如果有兴趣的话,看看:AppVeyor,Jenkins,Travis,CircleCI,GoCD,Buildbot。谢谢。
关于Python的视频课程的其他讲座在Habré的帖子中。