
大家好,我叫Igor Sidorenko。监控是我工作的主要领域之一,也是我的业余爱好。我将讨论Zabbix,以及如何使用它来监视我们需要的有关NetApp卷的信息,并且只能通过SSH进行访问。谁对监视和Zabbix主题感兴趣,请关注。
最初,我们通过将卷挂载到特定服务器上来监视卷,该服务器上挂有特殊模板,类似于基本Linux模板的文件系统,在节点上捕获NFS挂载并将其置于监视之下。该挂载必须在fstab中注册并手动挂载-因此,很多丢失和遗忘了。
然后我想到一个好主意:我们需要使所有这些自动化。有几种选择:
有可以使用SNMP的现成模板,但是没有访问权限。获取卷列表并在节点上自动挂载:您需要创建一个文件夹,注册fstab,进行挂载,仅此而已,痔疮太多了。有一个很棒的API,但是由于我们只租用空间,因此在我们的ONTAP版本中,它已被缩减,并且无法为用户提供必要的信息。- 以某种方式使用SSH访问来获取卷并设置它们以进行监视。
选择权在于SSH代理。
低层发现(LLD)
首先,我们需要创建一个低级发现(LLD),这些将是我们卷的名称。为了提取有关我们所需数量的特定信息,所有这些都是必要的。原始数据如下所示(撰写本文时为114):
set -unit B; volume show -state online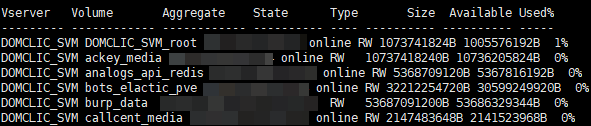
好吧,我们该如何避免出现拐杖问题:让我们编写一个单行bash脚本,它将以JSON格式显示卷的名称(由于这是外部检查,因此这些脚本位于Zabbix服务器上的目录中
/usr/lib/zabbix/externalscripts):
netapp_volume_discovery.sh
#!/usr/bin/bash
SVM_NAME=""
SVM_ADDRESS=""
USERNAME=""
PASSWORD=""
for i in $(sshpass -p $PASSWORD ssh -o StrictHostKeyChecking=no $USERNAME@$SVM_ADDRESS 'set -unit B; volume show -state online' | grep $SVM_NAME | awk {'print $2'}); do echo '{"volume_name":"'$i'"}'; done | jq -s '.
现在,您需要创建一个模板并根据接收到的数据创建数据项:
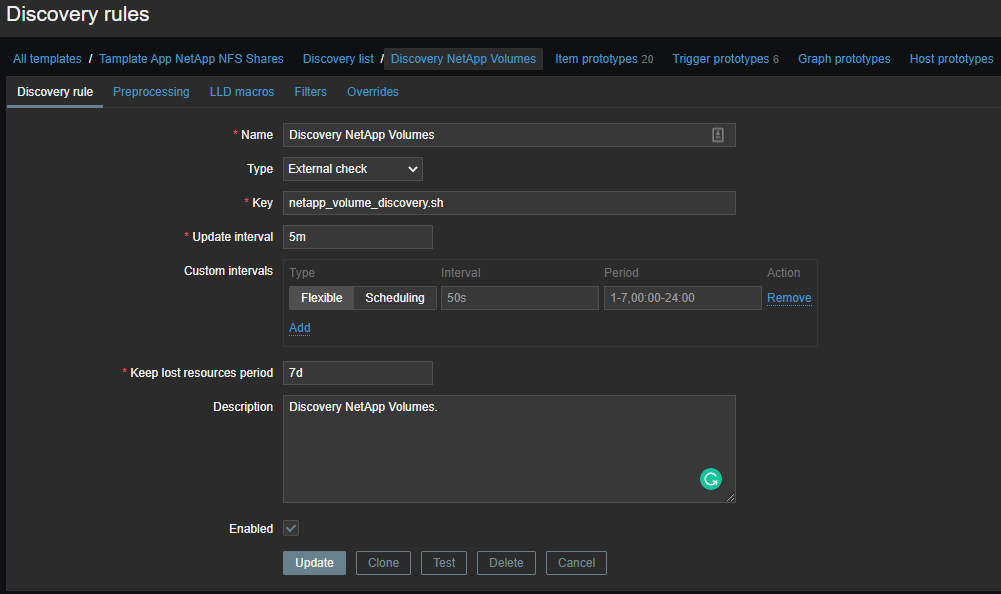
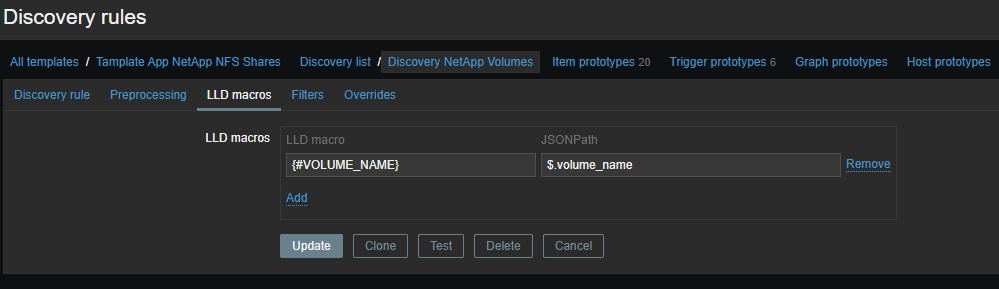
数据项
要自动创建数据项,您需要使这些数据项原型化: 我们将使用主项和一些相关项。因此,对于每个卷,将创建一个主元素,在其中通过SSH执行一组命令:
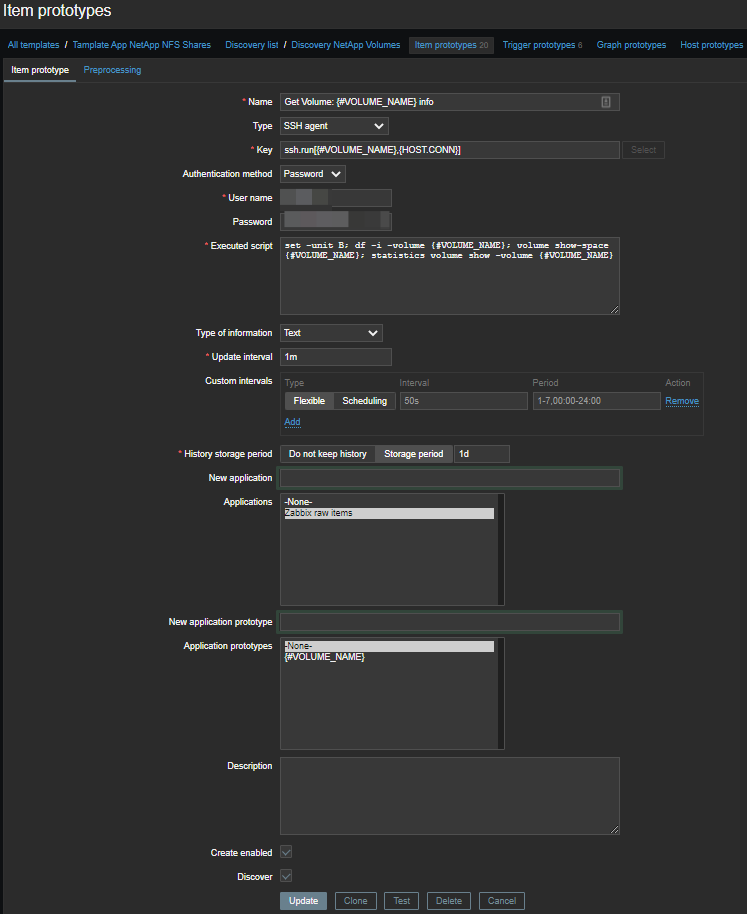
set -unit B; df -i -volume {#VOLUME_NAME}; volume show-space {#VOLUME_NAME}; statistics volume show -volume {#VOLUME_NAME}我们得到这样的一张纸:
获取音量:ackey_media信息
Last login time: 9/15/2020 12:42:45
Filesystem iused ifree %iused Mounted on
/vol/ackey_media/ 96 311191 0% /ackey_media
Volume Name: ackey_media
Volume MSID: 2159592810
Volume DSID: 1317
Vserver UUID: 46a00e5d-c22d-11e8-b6ed-00a098d48e6d
Aggregate Name: NGHF_FAS2720_04
Aggregate UUID: 7ec21b4d-b4db-4f84-85e2-130750f9f8c3
Hostname: FAS2720_04
User Data: 20480B
User Data Percent: 0%
Deduplication: -
Deduplication Percent: -
Temporary Deduplication: -
Temporary Deduplication Percent: -
Filesystem Metadata: 1150976B
Filesystem Metadata Percent: 0%
SnapMirror Metadata: -
SnapMirror Metadata Percent: -
Tape Backup Metadata: -
Tape Backup Metadata Percent: -
Quota Metadata: -
Quota Metadata Percent: -
Inodes: 12288B
Inodes Percent: 0%
Inodes Upgrade: -
Inodes Upgrade Percent: -
Snapshot Reserve: -
Snapshot Reserve Percent: -
Snapshot Reserve Unusable: -
Snapshot Reserve Unusable Percent: -
Snapshot Spill: -
Snapshot Spill Percent: -
Performance Metadata: 28672B
Performance Metadata Percent: 0%
Total Used: 1212416B
Total Used Percent: 0%
Total Physical Used Size: 1212416B
Physical Used Percentage: 0%
Logical Used Size: 1212416B
Logical Used Percent: 0%
Logical Available: 10736205824B
DOMCLIC_SVM : 9/15/2020 12:42:51
*Total Read Write Other Read Write Latency
Volume Vserver Ops Ops Ops Ops (Bps) (Bps) (us)
----------- ----------- ------ ---- ----- ----- ----- ----- -------
ackey_media DOMCLIC_SVM 0 0 0 0 0 0 0从此工作表中,我们需要选择所需的指标。
正则表达式的魔力
最初,我想使用JavaScript进行预处理,但是由于某种原因我没有掌握它,因此无法正常工作。因此,我停止了常客,几乎在所有地方都使用它们。
使用的索引节点数
我们将分两个阶段为每个卷仅选择有关inode 的信息:首先,所有信息:
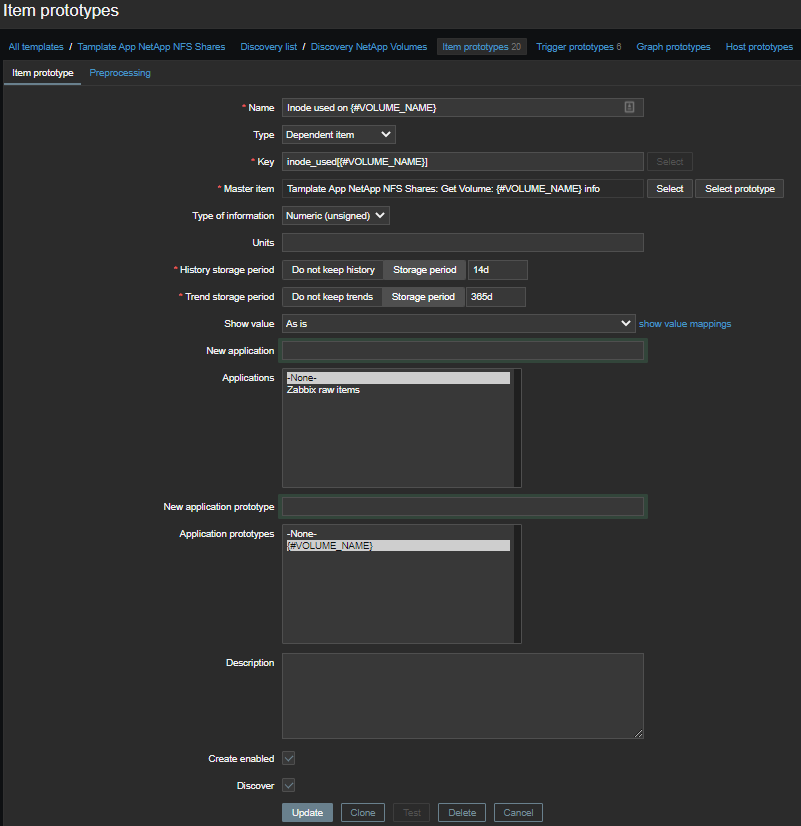
\/vol\/\w+\/.*

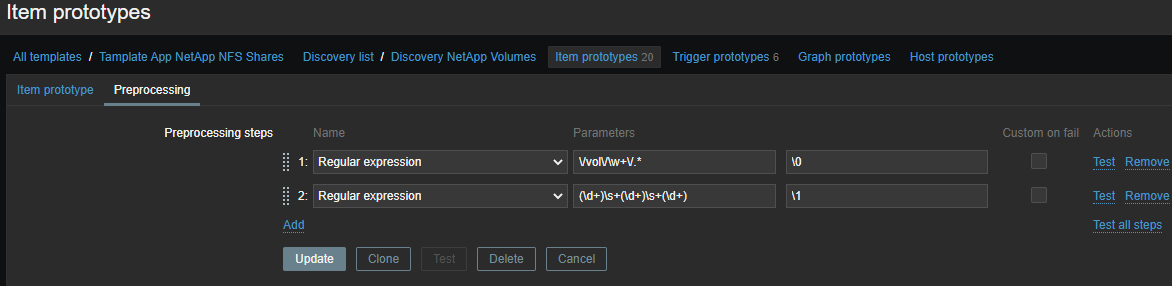
然后,具体按指标:
(\d+)\s+(\d+)\s+(\d+)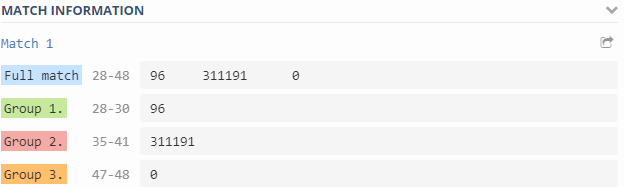

输出-输出格式模板。
\N ( N=1..9)-转义序列被第N个匹配组代替。转义序列\0被替换为匹配的文本:
\1 - Inode used on {#VOLUME_NAME}-使用的索引节点数;\2 - Inode free on {#VOLUME_NAME}-空闲索引节点数;\3 - Inode used percentage on {#VOLUME_NAME}-使用的inode所占百分比;Inode total on {#VOLUME_NAME}-计算的元素,可用索引节点的数量。
last(inode_free[{#VOLUME_NAME}])+last(inode_used[{#VOLUME_NAME}])已用空间
此处的一切都更加简单,数据和常规数据的格式更加舒适: 我们提取所需的指标,仅取数字:
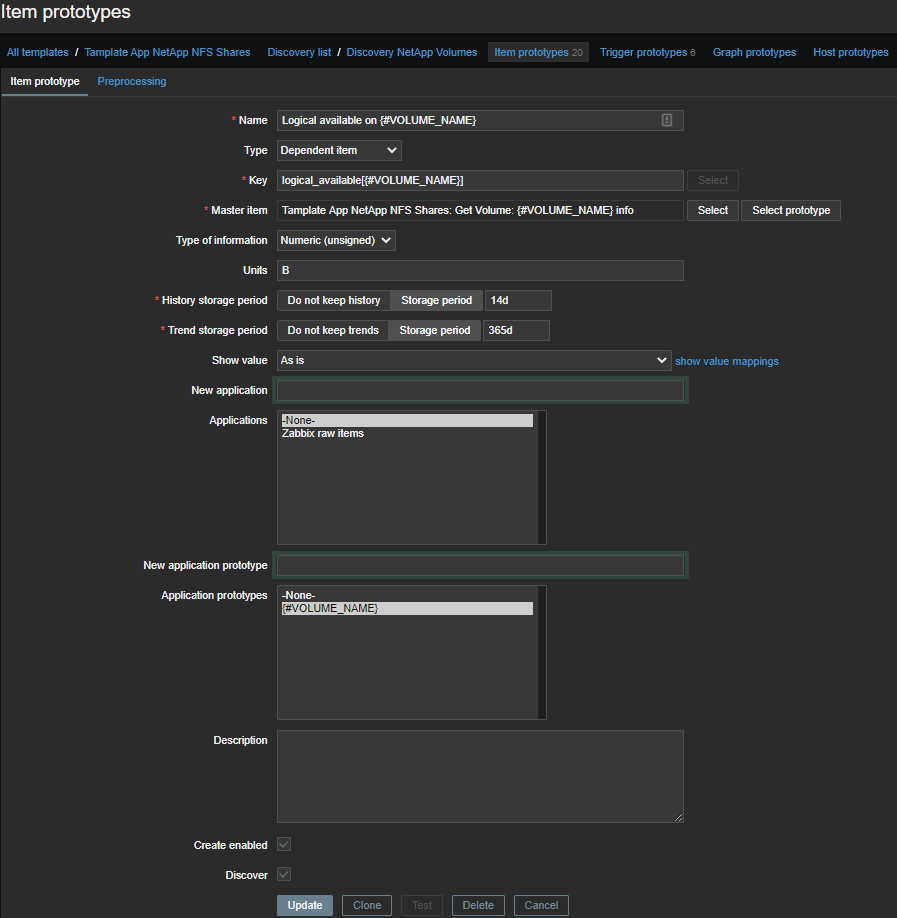
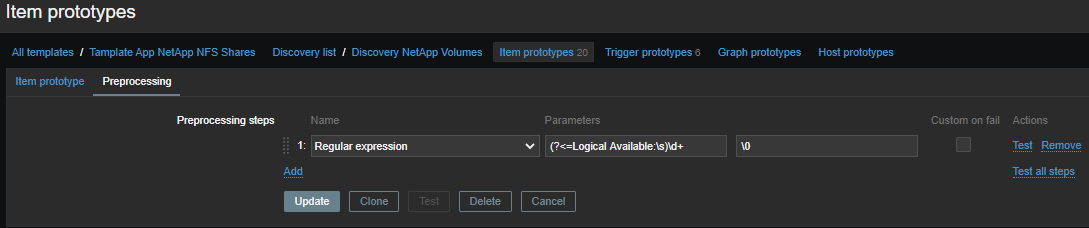
(?<=Logical Available:\s)\d+

收集的指标:
Logical available on {#VOLUME_NAME}-可用逻辑空间量;Logical used percent on {#VOLUME_NAME}-百分比使用的逻辑位置;Logical used size on {#VOLUME_NAME}-使用的逻辑空间量;Physical used percentage on {#VOLUME_NAME}-已用物理空间百分比;Total physical used size on {#VOLUME_NAME}-使用的物理空间量;Total used on {#VOLUME_NAME}-使用的总空间;Total used percent on {#VOLUME_NAME}-使用的总名额百分比;Logical size on {#VOLUME_NAME}-计算元素,可用逻辑空间量。
last(logical_available[{#VOLUME_NAME}])+last(total_used[{#VOLUME_NAME}])音量表现
阅读文档并使用不同的命令四处浏览后,我发现可以获取有关卷性能的指标。一小部分负责:
statistics volume show -volume {#VOLUME_NAME}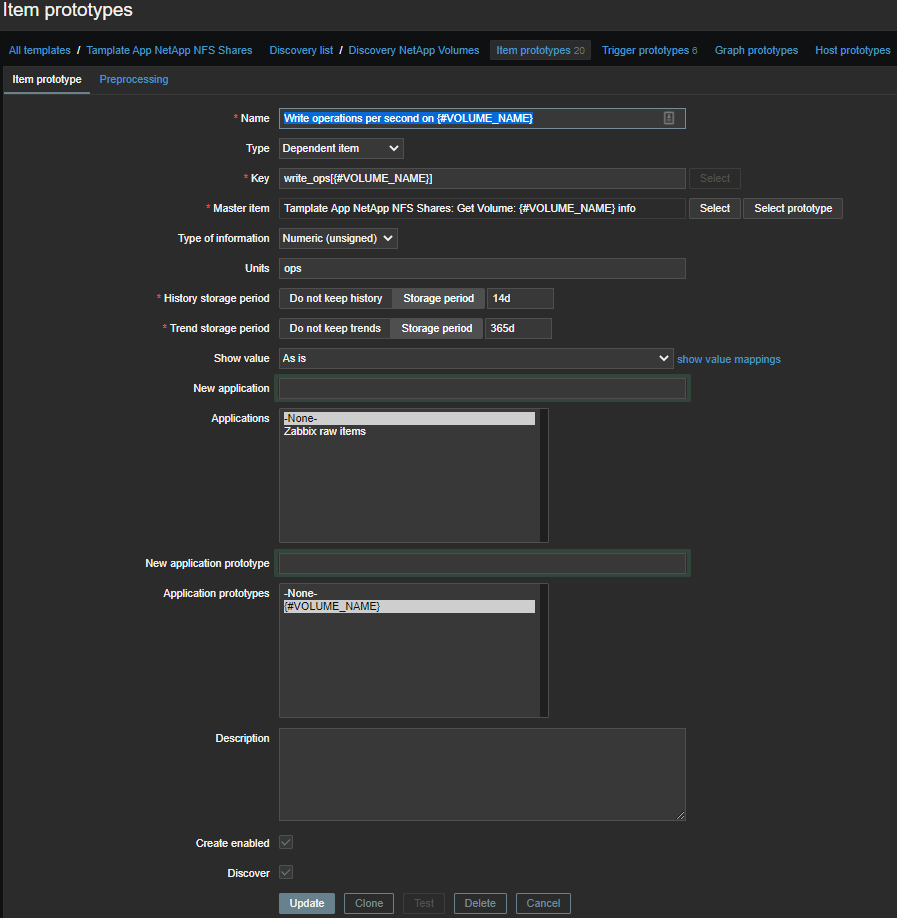
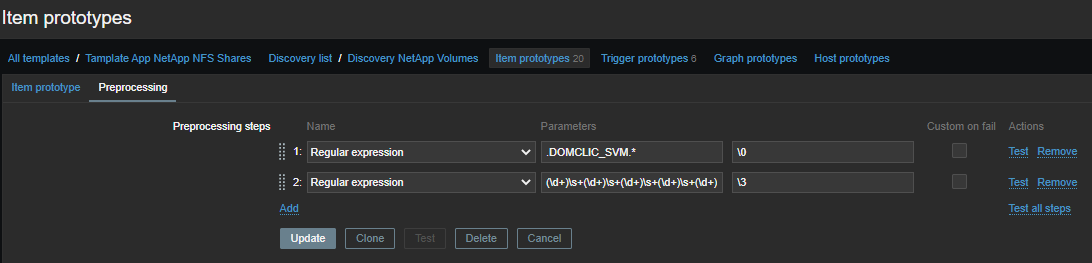
我们从具有第一规律性的通用表中选择绩效指标:
.DOMCLIC_SVM.*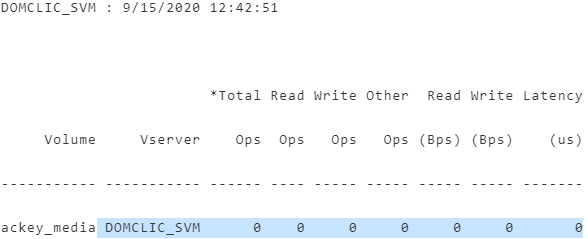

其次,我们将数字分组:
(\d+)\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+)
哪里:
\1 - Total number of operations per second on {#VOLUME_NAME}-每秒的操作总数;\2 - Read operations per second on {#VOLUME_NAME}-每秒读取操作;\3 - Write operations per second on {#VOLUME_NAME}-每秒写入操作;\4 - Other operations per second on {#VOLUME_NAME}-每秒其他操作(我不知道这是什么,但是出于某种原因我拍摄了);\5 - Read throughput in bytes per second on {#VOLUME_NAME}-读取速度,以每秒字节数为单位;\6 - Write throughput in bytes per second on {#VOLUME_NAME}-写入速度,以每秒字节数为单位;\7 - Average latency for an operation in microseconds on {#VOLUME_NAME}-平均操作延迟(以微秒为单位)。
警示
触发器的集合是标准触发器,位置触发器和索引节点:
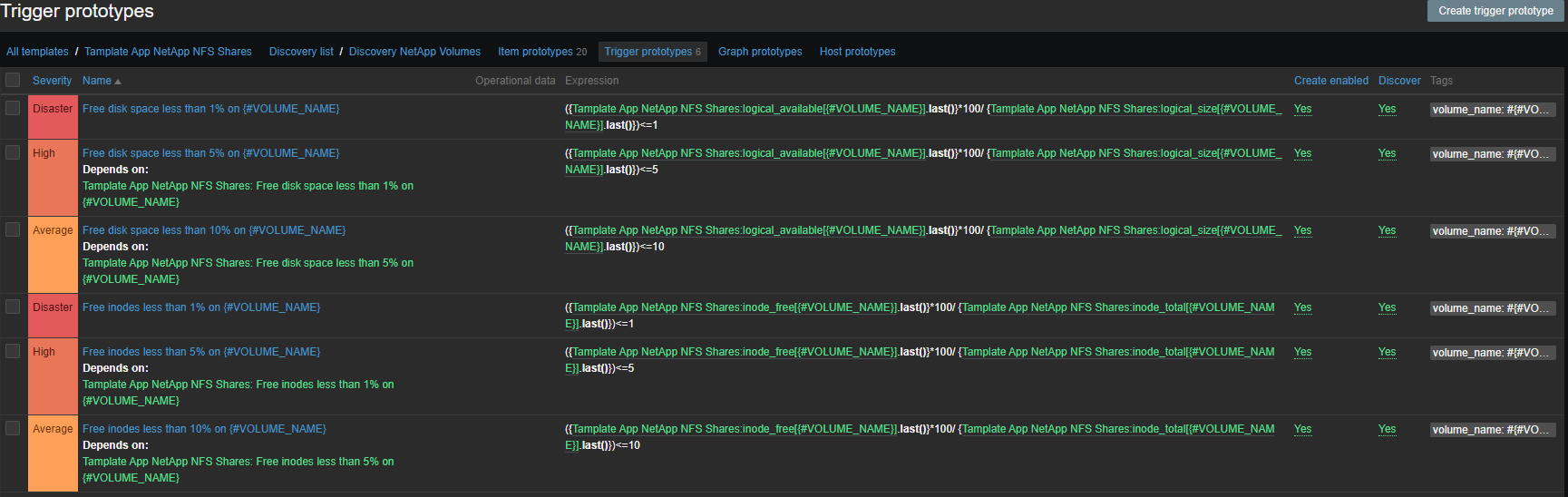
- {#VOLUME_NAME}上的可用磁盘空间少于1%
- {#VOLUME_NAME}上的可用磁盘空间少于5%
- {#VOLUME_NAME}上的可用磁盘空间少于10%
- {#VOLUME_NAME}的可用索引节点少于1%
- {#VOLUME_NAME}的可用索引节点少于5%
- {#VOLUME_NAME}的可用索引节点少于10%
可视化
可视化主要在Grafana上完成,它既美观又方便。例如,一个卷看起来像这样: 在右上角有一个“在Zabbix中显示”按钮,您可以使用它进入Zabbix并查看所选卷的所有指标。
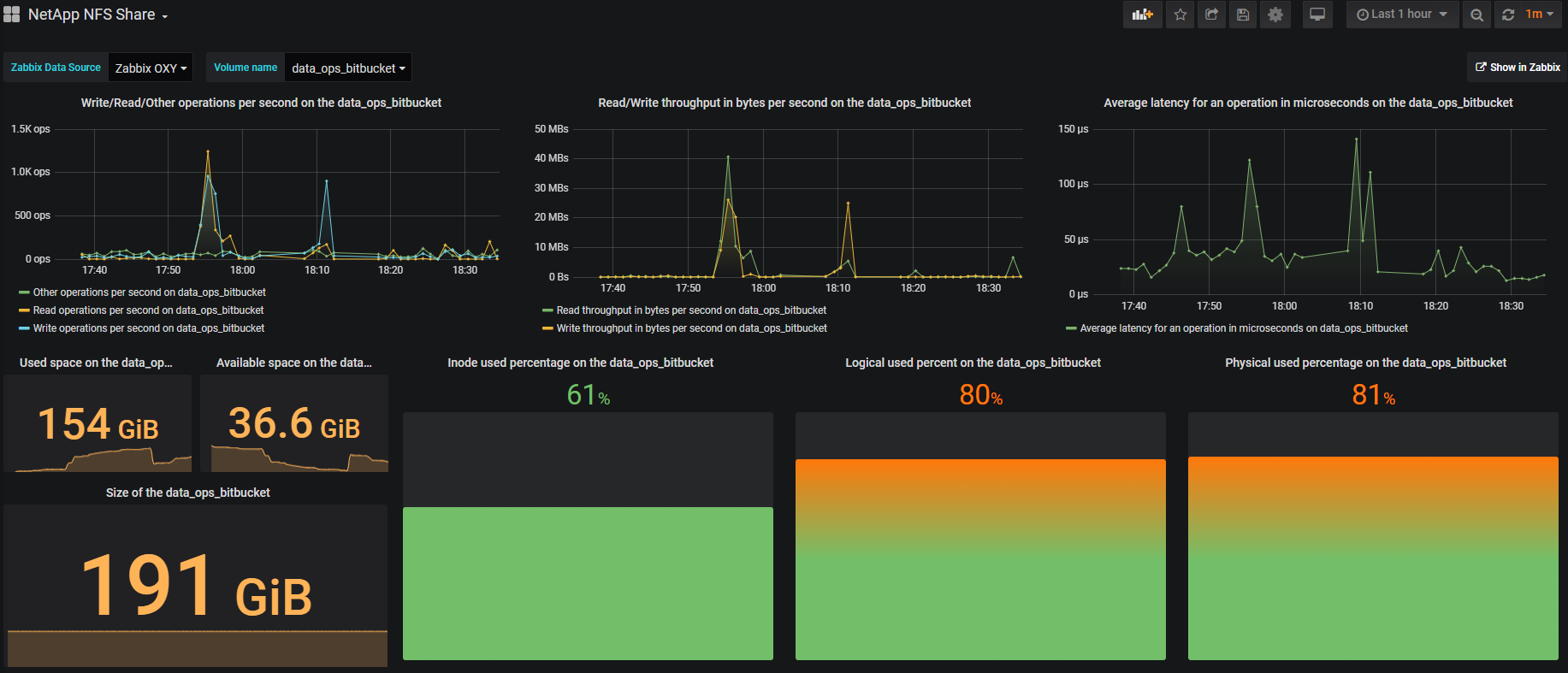
结果
- 自动设置要监视的卷。
- 如果已从NetApp删除卷,则自动从监视中删除卷。
- 我们摆脱了绑定到一台服务器并手动装载卷的麻烦。
- 添加了每个卷的性能指标。现在,为从NetApp获得图表而不再需要数据中心支持。
他们很快承诺将更新ONTAP并引入扩展的API,该模板将移至HTTP代理。
模板,脚本和仪表板
github.com/domclick/netapp-volume-monitoring
有用的链接
docs.netapp.com/ontap-9/index.jsp
www.zabbix.com/documentation/current