
在IT界有这样一个玩笑,机器学习(ML)就像青少年之间的性爱:每个人都谈论它,每个人都假装这样做,但实际上,很少有人能成功。FunCorp已成功将ML引入其产品的主要机制中,并在关键指标上实现了根本性的改进(将近40%!)。有趣?欢迎来到猫。
有点背景
对于那些不定期阅读FunCorp博客的人,让我提醒您,我们最成功的产品是iFunny UGC应用程序,其中包含面向迷因爱好者的社交网络。用户(这是美国年轻一代的四分之一代表)直接在应用程序中上传或创建新图片或视频,然后智能算法从中(精选)(精选)中选择(或称“功能”)最好的一种,并形成每一种第7天,在单独的供稿中发行了30-60个内容单元,与99%的受众群体进行互动。结果,当进入应用程序时,每个用户都会看到热门的模因,视频和有趣的图片。如果您经常访问,则供稿会快速滚动,并且用户会在几个小时后等待下一个问题。但是,如果您访问频率较低,则特色内容会堆积起来,并且Feed在几天内可能会增加到1000个项目。
因此,出现了任务:向每个用户显示与他最相关的内容,在提要开始时将他个人感兴趣的模因进行分组。
在iFunny成立超过9年的时间里,已经有几种方法可以完成此任务。
首先,我们尝试了一种显而易见的方式,根据微笑次数(我们的“喜欢”的比喻)-微笑率对供稿进行排序。这比按时间顺序排序要好,但同时导致了“医院平均温度”的影响:每个人都不喜欢幽默,而且今天总会有一些人不感兴趣(甚至坦率地烦恼)那些热门话题...但您也想看一看您喜欢的动画片中的所有新笑话。
在下一个实验中,我们尝试考虑各个微型社区的利益:动漫,体育迷,与猫和狗的模因等等。为此,他们开始形成几个专题精选供稿,并通过使用图片中识别的标签和文本为用户提供感兴趣的主题选择。情况有所改善,但社交网络的影响已消失:对特色内容的评论较少,而这些评论在用户参与度方面发挥了重要作用。此外,在细分供稿的过程中,我们损失了很多真正最受欢迎的模因。他们观看了“最喜欢的卡通”,但没有看到关于“最后的复仇者”的笑话。
由于我们已经开始在产品中实现机器学习算法,因此我们在自己的聚会上介绍了该算法,他们想使用该技术来采取另一种方法。
决定尝试基于协作过滤原理构建推荐系统。如果应用程序几乎没有关于用户的数据,则该原则是很好的:注册时很少指出年龄或性别,并且只有通过IP地址才能假定其地理位置(尽管没有算命先生知道绝大多数iFunny用户是居民)美国),并按手机型号-收入水平。就此而言,大体上一切。协作过滤的工作方式是这样的:记录用户内容的正面评分历史,找到其他具有相似评分的用户,然后向他推荐相同用户已经喜欢的内容(具有相似评分)。
任务特征
模因是非常具体的内容。首先,它极易受到快速变化的趋势的影响。一周前让80%的观众欢笑的内容和形式,今天可能会由于其次要性质和无关紧要而引起烦恼。
其次,对模因的含义进行了非常非线性的情境解释。在新闻选择中,您可以捕捉到众所周知的名称,这些名称是特定用户相当一致地使用的主题。在精选的电影中,您可以继续观看演员表,体裁等等。是的,您可以选择一些个人模因来掌握所有这些信息。但是,错过一个真正的幽默杰作会多么令人失望,该杰作使用的图像或词汇根本不适合语义内容!

最后,大量动态生成的内容。在iFunny,用户每天创建数以万计的帖子。所有这些内容都必须尽快“倾斜”,在个性化推荐系统的情况下,不仅要找到“钻石”,而且要能够预测社会各代表对内容的评估。
这些功能对机器学习模型的开发意味着什么?首先,必须对模型进行不断的最新数据训练。在沉浸于推荐系统开发的开始之初,我们谈论的是数十分钟还是几个小时,仍然还不是很清楚。但是,这两者都意味着需要对模型进行持续的重新训练,或者甚至需要更好的-对连续数据流进行在线训练。从找到合适的模型架构并选择其超参数的角度来看,所有这些都不是最容易的任务:这样可以保证在两周之内这些指标不会自信地降级。
一个单独的困难是需要遵循我们采用的a / b测试协议。在未首先检查某些用户并将结果与对照组进行比较的情况下,我们绝不会执行任何操作。
经过长时间的计算,决定启动具有以下特征的MVP:我们仅使用有关用户与内容交互的信息,我们在配备大量内存的服务器上实时训练模型,从而可以在相当长的时间内存储测试用户组的整个交互历史。我们决定将培训时间限制为15-20分钟,以保持新颖性的效果,并有时间使用发布期间大量访问该应用程序的用户的最新数据。
模型
首先,我们开始通过矩阵分解和ALS(交替最小二乘)或SGD(随机梯度下降)训练对最经典的协作过滤进行扭曲。但是他们很快就发现:为什么不立即从最简单的神经网络开始?使用简单的单层网格,其中只有一个线性嵌入层,并且没有隐藏层的包裹,以免您在选择其超参数的几周内陷入困境。超越MVP吗?也许。但是,如果您的硬件配备了出色的GPU(必须为此付出努力),那么训练这样的网格几乎不会比经典的体系结构更困难。
最初,很明显,事件的开发只有两种选择:要么开发将在产品指标方面取得显著成果,然后有必要进一步挖掘用户和内容的参数,对新内容和新用户进行额外的培训,深入神经网络,或者个性化内容排名不会带来有形的增加和“购买”可以覆盖。如果出现第一个选项,则必须将以上所有内容拧紧到起始的嵌入层。
我们决定选择神经分解机。其操作原理如下:每个用户和每个内容由固定长度相等的矢量-嵌入进行编码,这些矢量在用户和内容之间的一组已知交互作用上得到进一步训练。
训练集包括用户查看内容的所有事实。除了微笑之外,还决定考虑单击“共享”或“保存”按钮,以及撰写评论,以获取有关内容的积极反馈。如果存在,则交互标记为1(一)。如果在查看后用户没有留下正面反馈,则将交互标记为0(零)。因此,即使没有明确的评级量表,也将使用明确的模型(具有来自用户的明确评级的模型),而不是隐式模型,这将仅考虑积极行动。
我们还尝试了隐式模型,但是它无法立即生效,因此我们将重点放在显式模型上。也许,对于隐式模型,您需要使用比简单的二进制交叉熵更多的棘手的排名损失函数。
神经矩阵分解和标准神经协作过滤之间的区别在于存在所谓的双向交互池层,而不是通常的简单连接用户和内容嵌入向量的完全连接层。双交互层通过逐元素相乘将一组嵌入矢量(iFunny中只有2个矢量:用户和内容)转换为一个矢量。
在Bi-Interaction之上没有其他隐藏层的情况下,我们得到这些向量的点积,并在添加用户偏差和内容偏差的情况下将其包装成S型。这是查看此内容后来自用户的正面反馈可能性的估计。根据此评估,我们会在特定设备上演示可用内容之前对其进行排名。
因此,培训的任务是确保具有正交互作用的用户和内容嵌入彼此接近(具有最大的点积),并且具有负交互作用的用户和内容嵌入彼此远离。 (最小点积)。
训练的结果是,微笑相同事物的用户的嵌入物彼此之间变得彼此靠近。这是可以在许多其他任务中使用的方便的用户数学描述。不过那是另一回事了。
因此,用户输入提要并开始观看内容。每次您查看,微笑,分享等时客户端将统计信息发送到我们的分析存储(如果感兴趣的话,我们在前面的文章从Redshift到Clickhouse的文章中进行了介绍)。在途中,我们选择了我们感兴趣的事件,并将其发送到ML服务器,然后将它们存储在内存中。
每隔15分钟,将在服务器上对模型进行重新训练,然后在建议中考虑新的用户统计信息。
客户端请求提要的下一页,它以一种标准的方式形成,但是是以将内容列表发送到ML服务的方式,它根据经过训练的模型为该特定用户提供的权重对其进行排序。

结果,用户首先看到根据模型最喜欢他的那些图片和视频。
内部服务架构
该服务通过HTTP运行。Flask与Gunicorn一起用作HTTP服务器。它处理两个请求:add_event和get_rates。
add_event请求在用户和内容之间添加新的交互。它被添加到内部队列中,然后在单独的进程中处理(峰值1600 rps)。
get_rates请求根据模型计算user_id和content_id列表的权重(大约100 rps的峰值)。
内部主要过程是分派器。它是用asyncio编写的,并实现了基本逻辑:
- 处理add_event请求队列并将其存储在巨大的哈希图中(每周200M事件);
- 围成一圈重新计算模型;
- 每隔半小时将新事件保存到磁盘,同时从哈希图中删除早于一周的事件。

训练有素的模型被放置在共享内存中,HTTP工作者从共享内存中读取该模型。
结果
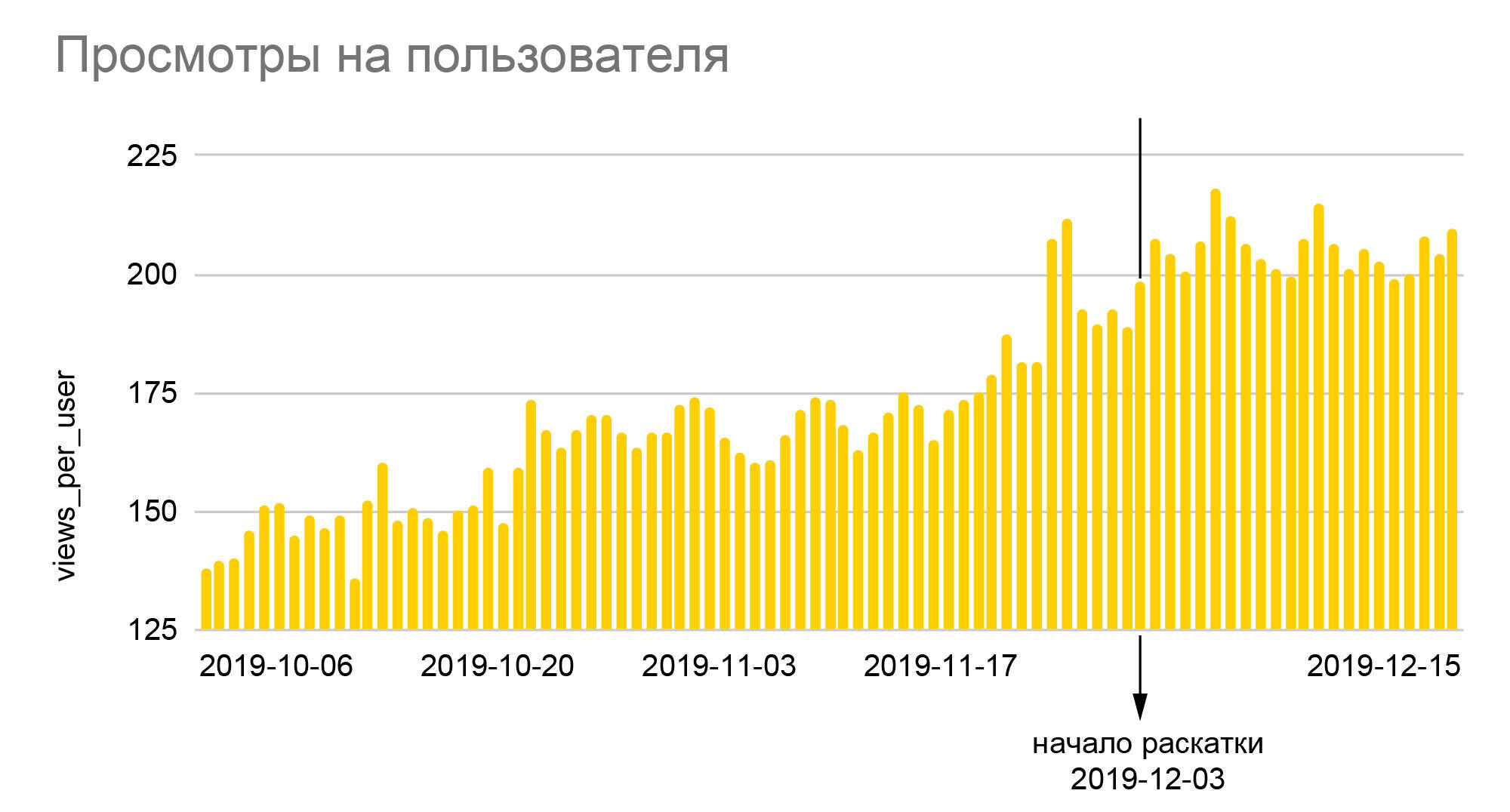

图表不言自明。笑脸的相对数量增长了25%,我们看到的笑脸的深度增长了近40%,是在A / B测试50/50结束时向所有受众推出新算法的结果,即相对于基本值的实际增长几乎是原来的两倍。由于iFunny通过广告赚钱,深度的增加意味着收入的成比例增长,这又使我们能够从容应对2020年的危机月份。笑脸数量的增加转化为更高的忠诚度,这意味着将来放弃申请的可能性更低;忠实的用户开始转到应用程序的其他部分,发表评论,彼此交流。最重要的是,我们不仅为提高建议的质量奠定了可靠的基础,同时也为根据我们多年来在应用程序中积累的大量匿名行为数据奠定了创建新功能的基础。
结论
ML Content Rate服务是大量次要改进和改进的结果。
首先,培训中还考虑了未注册用户。最初,存在关于它们的问题,因为它们先验不能留下图释,这是查看内容后最频繁的反馈。但是很快就变得很清楚,这些担忧是徒劳的,并关闭了很大的增长点。针对训练样本的配置进行了许多实验:将更大比例的受众放入其中,或者扩大考虑到的互动的时间间隔。在这些实验过程中,事实证明,不仅数据量对产品指标起着重要作用,而且更新模型的时间也很重要。通常,排名质量的提高会在额外的10-20分钟内被淹没,以重新计算模型,因此有必要放弃创新。
许多甚至最小的改进都产生了结果:它们要么提高了学习质量,要么加速了学习过程,或者节省了内存。例如,存在一个问题,即交互不适合内存-必须对其进行优化。此外,对代码进行了修改,并且可以将其推入其中,例如,可以进行更多交互以进行重新计算。这也改善了服务的稳定性。
现在正在开展工作,以有效地使用已知的用户和内容参数,以建立递增的,快速的重新训练模型,并且出现了用于未来改进的新假设。
如果您有兴趣了解我们如何开发此服务以及我们实现了哪些其他改进,请在注释中写一些内容,稍后我们将准备编写第二部分。
关于作者
不幸的是,Habr不允许为这篇文章指定几位作者。尽管这篇文章是从我的帐户发布的,但大部分是由FunCorp ML服务的首席开发人员Grisha Kuzovnikov(凤凰城),以及分析师和数据科学家Dima Zemtsov。您的顽固仆人主要负责青少年性笑话,简介和结果部分,以及编辑工作。而且,当然,如果没有后端开发团队,质量保证,分析师和产品团队的帮助,所有这些成就都是不可能的,他们开发了所有这些,并花了几个月的时间进行和调整A / B实验。