研究路径
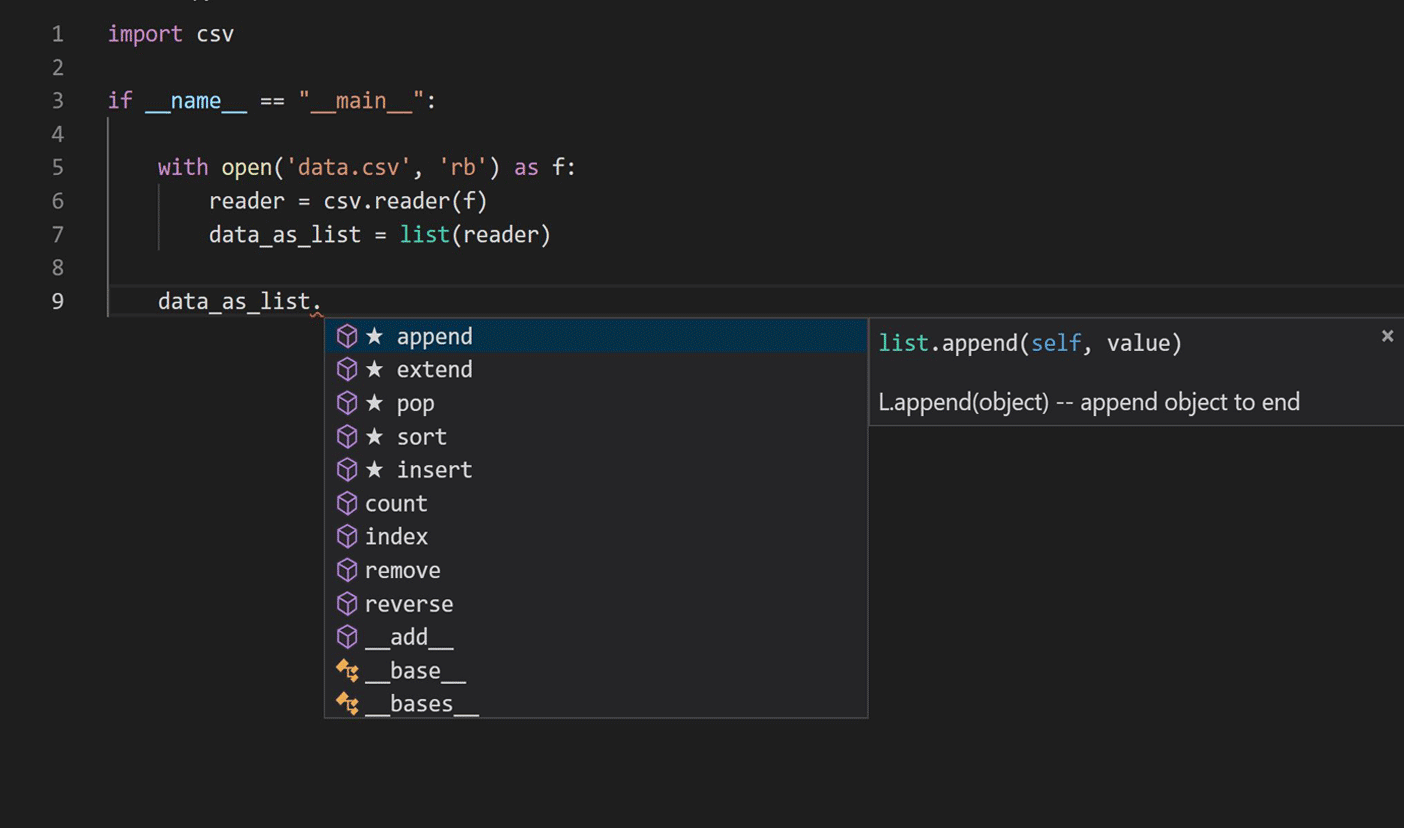
旅程始于研究语言建模技术在自然语言处理中的应用,以学习Python代码。我们专注于当前的IntelliCode完成脚本,如下图所示。

主要任务是查找类型最可能的片段(成员),并考虑到该片段(成员)调用之前的代码片段。换句话说,给定原始的C代码片段,词汇表V和所有可能的方法M⊂V的集合,我们想定义:
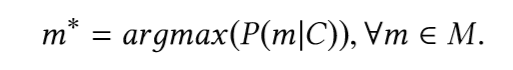
为了找到这个片段,我们需要建立一个可以预测可用片段概率的模型。
先前基于递归神经网络(RNN)的现代方法仅使用源代码的顺序性质,试图在不利用编程语言语法和代码语义的独特特征的情况下传达自然语言技术。代码完成问题的性质使其成为长期短期记忆(LSTM)的有希望的候选者)。在准备用于训练模型的数据时,我们使用了与包含用户访问表达式(成员)和模块函数调用的代码段相对应的部分抽象语法树(AST),以捕获远程代码所携带的语义。
训练深度神经网络是一项资源密集型任务,需要高性能的计算集群。我们将Horovod的分布式并行训练框架与Adam优化器一起使用,在每个工人上保留整个神经模型的副本,并行处理训练数据集的不同小批次。我们使用了Azure机器学习用于模型训练和超参数调整,因为其GPU按需集群服务使根据需要轻松扩展我们的训练,并且还有助于提供和管理VM集群,调度作业,收集结果并处理故障。该表显示了我们测试过的体系结构模型,以及它们各自的准确性和模型大小。

我们选择预测实施制造是因为在离线模型评估期间,模型尺寸较小,并且模型精度比以前的生产模型提高了20%;模型大小对于生产部署至关重要。
该模型的架构如下图所示:

为了在生产中部署LSTM,我们必须提高模型推断速度和内存占用量,以满足编辑期间的代码完成要求。我们的内存预算约为50MB,我们需要将平均输出速度保持在50毫秒以下。 IntelliCode LSTM经过TensorFlow培训,我们选择ONNX Runtime进行推理以获得最佳性能。 ONNX Runtime可与流行的深度学习框架配合使用,并通过提供涵盖多种语言的API(包括Python,C,C ++,C#,Java和JavaScript)使它易于集成到各种服务环境中-我们使用了与.NET Core兼容的C#API集成到Microsoft Python语言服务器中。
当可以接受由低位数字近似引起的精度下降时,量化是减小模型大小并提高性能的有效方法。借助ONNX Runtime提供的训练后INT8量化,结果得到了显着改善:与原始模型相比,内存占用空间和推理时间减少到预量化值的约四分之一,模型精度降低了3%。您可以在我们在KDD 2019大会上发表的研究论文中找到有关模型架构设计,超参数调整,准确性和性能的详细信息。
发布到生产的最后阶段是进行在线A / B实验,将新的LSTM模型与以前的工作模型进行比较。下表中的在线A / B实验结果显示,一级推荐的准确性(完成列表中第一个推荐的完成项目的准确性)提高了约25%,平均逆排名(MRR)则提高了17%,这使我们确信新的LSTM模型要好得多。以前的模型。

Python开发人员:试用IntelliCode附加组件并将您的反馈发送给我们!
由于团队的巨大努力,我们已经向Visual Studio Code中的所有IntelliCode Python用户分阶段推出了第一个深度学习模型。在用于Visual Studio Code的IntelliCode扩展的最新版本中,我们还集成了ONNX运行时和LSTM以与新的Pylance扩展一起使用,该扩展完全以TypeScript编写。如果您是Python开发人员,请安装IntelliCode扩展并与我们分享您的意见。