
并行运行的查询是否可以比顺序运行的查询使用更少的CPU并运行得更快?
是! 为了演示,我将使用具有一个列类型的两个表
integer。

注意-文本形式的TSQL脚本在本文结尾。
生成演示数据
我们
#BuildInt在表中插入5,000个随机整数(以便您拥有与我相同的值,我将RAND与种子和WHILE循环一起使用)。在

表中
#Probe插入5,000,000条记录。

顺序计划
现在让我们编写一个查询来计算这些表中值的匹配数。我们使用MAXDOP 1提示来确保查询不会并行执行。
其执行计划和统计信息如下:

该查询耗时891ms,使用890ms的CPU。
平行计划
现在,我们使用MAXDOP 2运行相同的查询。该

查询需要221毫秒和436毫秒的CPU。执行时间减少了四倍,CPU使用率减少了一半!
魔术位图
并行查询执行效率更高的原因在于Bitmap运算符。
让我们仔细看一下并行查询的实际执行计划:

并将其与顺序计划进行比较:

Bitmap运算符的原理已被详细记录,因此在此我仅提供简短描述,并在文章末尾提供指向该文档的链接。
哈希联接
哈希联接分为两个步骤:
- “建筑物”的阶段(英语-build)。读取表之一的所有行,并为联接键创建一个哈希表。
- “验证”阶段(英语-探针)。读取第二个表的所有行,使用相同的哈希函数使用相同的连接键来计算哈希,并在哈希表中找到匹配的存储桶。
自然地,由于可能的哈希冲突,仍然有必要比较密钥的实际值。
译者注:有关散列连接如何工作的更多详细信息,请参见可视化和处理散列匹配 连接的文章
顺序计划中的位图
许多人不知道,即使在顺序请求中,哈希匹配始终使用位图。但是用这种方式,您将看不到它,因为它是Hash Match运算符内部实现的一部分。
在建立和创建哈希表的阶段,HASH JOIN将在位图中设置一个(或多个)位。然后您可以使用位图有效地匹配哈希值,而无需访问哈希表。
使用顺序计划,将为第二张表的每一行计算一个哈希,并对照位图进行检查。如果设置了位图中的相应位,则哈希表中可能存在匹配项,因此接下来将检查哈希表。相反,如果没有设置与哈希值相对应的位,则可以确保哈希表中没有匹配项,并且可以立即丢弃所检查的字符串。
不检查哈希表中不存在完全匹配的字符串所节省的时间,可以抵消构建位图所需的相对较低的成本。这种优化通常是有效的,因为检查位图比检查哈希表要快得多。
并行计划中的位图
在并行计划中,位图显示为单独的位图语句。
从构造阶段进入验证阶段时,位图将从第二个(探针)表的侧面传递给HASH MATCH运算符。至少,将位图传递给JOIN和交换运算符之前的探针侧(并行)。
在此,位图可以在传递给交换语句之前排除不满足连接条件的字符串。
当然,顺序计划中没有交换语句,因此,将位图移到HASH JOIN之外不会比HASH MATCH语句中的“嵌入”位图提供任何其他优势。
在某些情况下(尽管仅在并行计划中),优化器可能会将位图在连接探针侧的平面上进一步向下移动。
这里的想法是,越早对行进行过滤,则在语句之间移动数据所需的开销就越少,甚至可以消除某些操作。
此外,优化器通常会尝试将简单的过滤器放置在尽可能靠近叶子的位置:最有效的方法是尽早过滤行。但是,我必须提到,我们正在讨论的位图是在优化完成后添加的。
在优化之后,将根据过滤器的预期选择性做出将这种(静态)位图添加到计划的决定(因此准确的统计数据很重要)。
移动位图过滤器
让我们回到将位图过滤器移到连接的探针端的概念。
在许多情况下,位图过滤器可以移动到Scan或Seek语句。发生这种情况时,计划谓词将如下所示:

它适用于与查找谓词匹配的所有行(对于“索引查找”)或对“索引扫描”或“表扫描”的所有行。例如,上面的屏幕截图显示了应用于堆表的表扫描的位图过滤器。
更深入...
如果位图过滤器建立在单个整数或bigint列或表达式上,并应用于单个整数或bigint列,则位图运算符可以走得更远,甚至比Seek或Scan运算符更远。
该谓词仍将像上面的示例一样出现在Scan或Seek语句中,但现在将使用INROW属性进行标记,这意味着该过滤器将移动到存储引擎并在读取行时应用于行。
通过这种优化,行将在查询处理器看到行之前被过滤。从存储引擎仅发送与HASH MATCH JOIN匹配的那些字符串。
应用此优化的条件取决于SQL Server的版本。例如,在SQL Server 2005中,除了前面提到的条件外,还必须将probe列定义为NOT NULL。在SQL Server 2008中已经放宽了此限制。
您可能想知道INROW优化如何影响性能。将操作员移动到尽可能接近“搜索”或“扫描”的效率是否会像在存储引擎中进行过滤一样有效?我将在其他文章中回答这个有趣的问题。在这里,我们还将介绍MERGE JOIN和NESTED LOOP JOIN。
其他JOIN选项
使用没有索引的嵌套循环是一个坏主意。我们必须从另一张表的每一行中完全扫描一张表-总共进行50亿次比较。此请求可能需要很长时间。
合并加入
这种类型的物理联接需要排序的输入,因此,强制的MERGE JOIN会导致在排序之前出现排序。顺序计划如下所示:
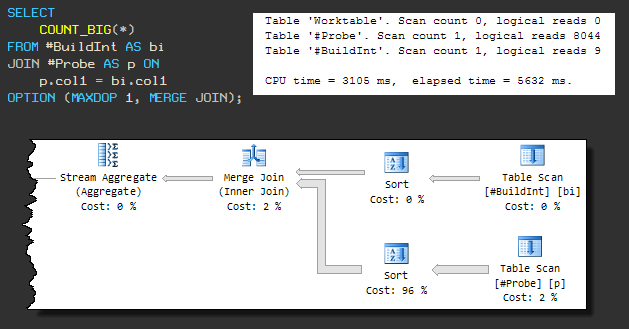
查询现在使用3105ms CPU,总执行时间为5632ms。
整体执行时间的增加是由于以下事实之一:排序操作正在使用tempdb(即使SQL Server具有足够的内存用于排序)。
发生泄漏到tempdb的原因是默认的内存授予算法没有预先保留足够的内存。直到我们关注这一点,很明显,请求将在不到3105毫秒内完成。
让我们继续强制MERGE JOIN,但允许并行性(MAXDOP 2):

正如我们在前面的并行HASH JOIN中所见,位图过滤器位于MERGE JOIN的另一侧,更靠近表扫描,并使用INROW优化来应用。
使用468 ms CPU和240 ms经过时间,具有其他种类的MERGE JOIN几乎与并行HASH JOIN(436 ms / 221 ms)一样快。
但是并行的MERGE JOIN有一个缺点:它根据要排序的预期行数保留330 KB内存。由于这些类型的位图是在成本优化之后使用的,因此即使只有2488行经过最底层排序,也不会对估算值进行调整。
位图语句只能在带有MERGE JOIN的计划中显示,而后继才是阻塞语句(例如,排序)。阻塞运算符必须在生成第一行输出之前将所有必需值作为输入接收。这样可以确保在读取JOIN表中的行并对其进行检查之前,位图已完全填满。
阻塞语句不必位于MERGE JOIN的另一侧,但重要的是在位图的哪一侧使用。
带索引
如果有合适的索引可用,情况将有所不同。我们的“随机”数据的分布使得
#BuildInt可以在表上创建唯一索引。并且该表#Probe包含重复项,因此您必须使用一个非唯一索引:

该更改不会影响HASH JOIN(串行和并行)。HASH JOIN无法使用索引,因此计划和性能保持不变。
合并加入
MERGE JOIN不再需要执行多对多联接操作,并且不再需要输入上的Sort运算符。
缺少阻塞排序运算符意味着无法使用位图。
结果,无论使用MAXDOP参数如何,我们都会看到一个顺序计划,并且在添加索引之前性能比并行计划差:702 ms CPU和704 ms经过时间:

但是,与原始顺序MERGE JOIN计划(3105 ms)相比,有明显的改进。/ 5632毫秒)。这是由于消除了排序和更好的一对多连接性能。
嵌套循环联接
如您所料,NESTED LOOP的性能明显更好。与MERGE JOIN相似,优化器决定不使用并发:

这是迄今为止最有效的计划-仅16ms CPU和16ms花时间。
当然,这假定完成请求所需的数据已在内存中。否则,探测表中的每个查找将生成随机I / O。
在我的笔记本电脑上,NESTED LOOP的冷缓存性能消耗了78 ms CPU和2152 ms消耗的时间。在相同的情况下,MERGE JOIN使用686 ms的CPU和1471 ms的CPU 。哈希联接-391毫秒CPU和905毫秒。
MERGE JOIN和HASH JOIN受益于使用预读的大型I / O(可能是顺序I / O)。
其他资源
并行哈希联接(Craig Freedman)
查询执行位图过滤器(SQL Server查询处理团队)
Microsoft SQL Server 2000中的位图(MSDN文章)
解释包含位图过滤器的执行计划(SQL Server文档)
了解哈希联接(SQL Server文档)
测试脚本
USE tempdb;
GO
CREATE TABLE #BuildInt
(
col1 INTEGER NOT NULL
);
GO
CREATE TABLE #Probe
(
col1 INTEGER NOT NULL
);
GO
-- Load 5,000 rows into the build table
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @I INTEGER = 1;
INSERT #BuildInt
(col1)
VALUES
(CONVERT(INTEGER, RAND(1) * 2147483647));
WHILE @I < 5000
BEGIN
INSERT #BuildInt
(col1)
VALUES
(RAND() * 2147483647);
SET @I += 1;
END;
-- Load 5,000,000 rows into the probe table
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @I INTEGER = 1;
INSERT #Probe
(col1)
VALUES
(CONVERT(INTEGER, RAND(2) * 2147483647));
BEGIN TRANSACTION;
WHILE @I < 5000000
BEGIN
INSERT #Probe
(col1)
VALUES
(CONVERT(INTEGER, RAND() * 2147483647));
SET @I += 1;
IF @I % 25 = 0
BEGIN
COMMIT TRANSACTION;
BEGIN TRANSACTION;
END;
END;
COMMIT TRANSACTION;
GO
-- Demos
SET STATISTICS XML OFF;
SET STATISTICS IO, TIME ON;
-- Serial
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 1);
-- Parallel
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 2);
SET STATISTICS IO, TIME OFF;
-- Indexes
CREATE UNIQUE CLUSTERED INDEX cuq ON #BuildInt (col1);
CREATE CLUSTERED INDEX cx ON #Probe (col1);
-- Vary the query hints to explore plan shapes
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 1, MERGE JOIN);
GO
DROP TABLE #BuildInt, #Probe;
阅读更多: