我和我的团队与Rosbank的合作伙伴一起代表了业务发展的方向。今天,我们想谈谈使用系统之间的直接集成,基于GreenOCR的图像和文本识别方面的人工智能,RF立法以及准备培训样本来实现银行业务流程自动化的成功经验。

所以,让我们开始吧。罗斯银行有一个业务流程,可以为合作伙伴银行代表的借款人开设帐户。遵循所有法规要求和法国兴业银行集团的要求,在自动化之前,每个客户最多需要20分钟的运营时间。该过程包括:由后台办公室接收文档扫描,检查填写每个文档的正确性以及在银行的信息系统中过帐文档字段,进行许多其他检查,并且直到最后才打开帐户。这正是“打开帐户”按钮背后的过程。
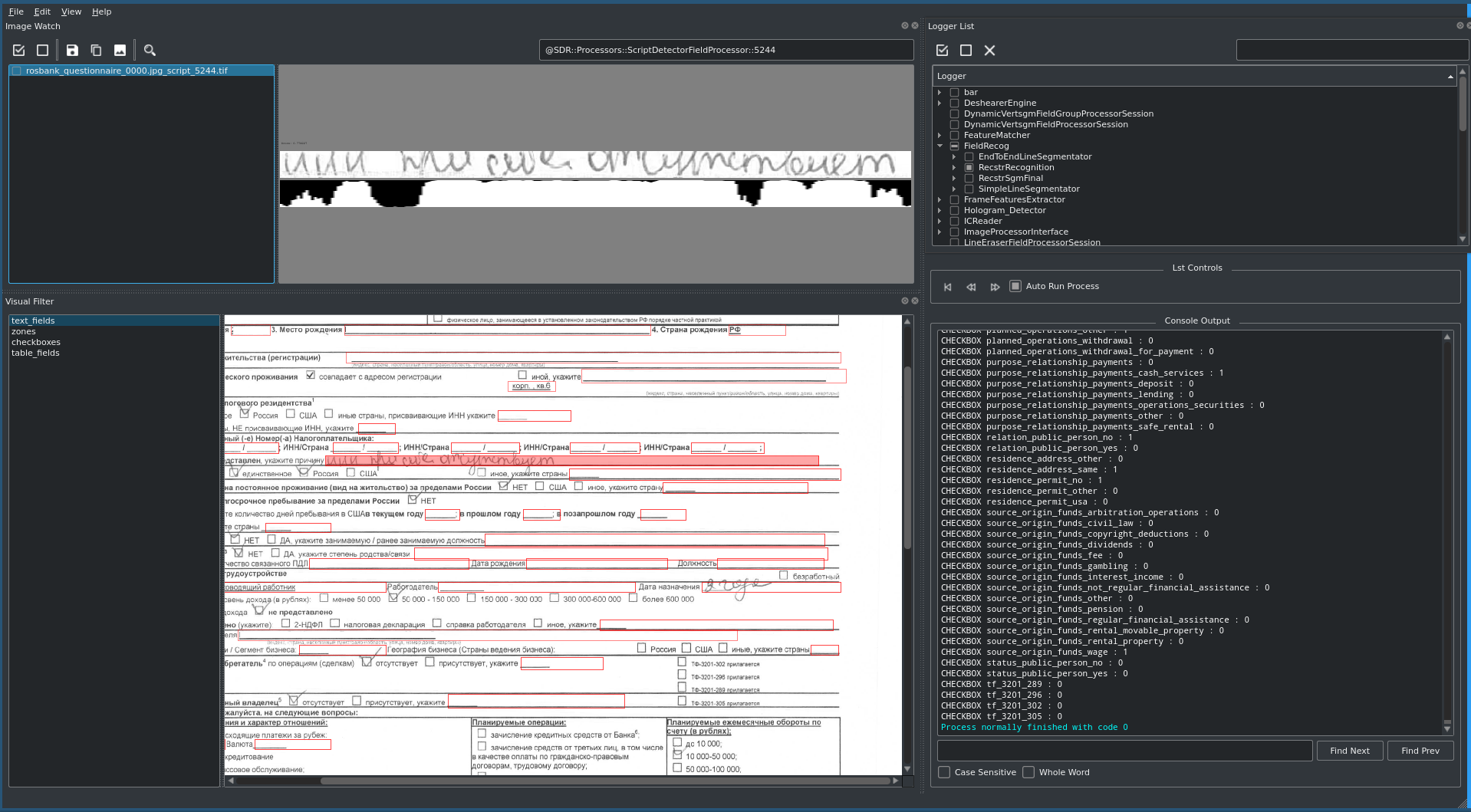
文件的主要字段-姓氏,名字,庇护权,客户的出生日期等-几乎包含在收到的所有类型的文件中,并在输入银行的不同系统时会被复制。最复杂的文档-KYC调查表(来自“了解您的客户-认识您的客户”)是一种可打印的A4格式,填充有8点字体,并且包含大约170个文本字段和复选框以及表格视图。
我们该怎么办?
我们的主要目标是将开设帐户的时间减少到最少。
对过程的分析表明有必要:
- 减少每个文档的手动验证次数;
- 自动填充不同银行系统中的相同字段;
- 减少系统之间扫描文件的移动;
为了解决问题(1)和(2),决定使用已经在银行中实现的基于GreenOCR的图像和文本识别解决方案(工作名称为“识别器”)。业务流程中使用的文档格式不是标准格式,因此该团队面临着制定“识别器”要求并准备用于训练神经网络(样本)的示例的任务。
为了解决问题(2)和(3),有必要完善系统和系统间集成。
我们的团队由Julia Aleksashina领导
- 亚历山大·巴什科夫(Alexander Bashkov)-内部系统开发(.Net)
- Valentina Sayfullina-业务分析,测试
- Grigory Proskurin-系统之间的集成(.Net)
- Ekaterina Panteleeva-业务分析,测试
- Sergey Frolov-项目管理,模型质量分析
- 外部供应商的参与者(智能引擎与Philosophy.it结合使用)
识别器培训
业务流程中使用的客户文档集包括:
- 护照;
- 同意-1升A4纸本;
- 授权书-A4纸,2升;
- KYC问卷-1升A4表格;
首先,对文档进行了彻底的研究并提出了要求,其中不仅包括带有动态字段的识别器的工作,还包括使用静态文本,带有手写数据的字段的工作,通常是沿周边的文档识别以及其他改进。
护照识别已包含在GreenOCR系统的包装盒功能中,不需要进行修改。
对于其他类型的文档,作为分析的结果,确定了应返回“识别器”的必要属性和符号。同时,必须考虑以下几点,这使识别过程变得复杂,并要求所用算法明显复杂:
- , . , «» ;
- 8- . , ;
- ( ) ;
- ;
- , , ;
- ;
最初,任务对我们来说似乎并不太复杂,看起来很标准:
需求->供应商->模型->测试模型->启动过程
如果测试未成功,则将模型返回给供应商进行重新培训。
每天我们都会收到大量的文档扫描图,为训练模型准备样本应该不是问题。个人数据的所有处理必须符合联邦法律“关于个人数据” N152-FZ的要求。客户同意仅在Rosbank内部处理客户的个人数据。我们无法将客户文档转移给供应商以训练模型。
考虑了三种解决问题的方法:
- , , , , ;
- . , – () , ;
- () . , , , , , ;
与团队一起分析了建议的选项之后,考虑了它们的实施速度和可能的风险,我们选择了第三个选项-模仿文档训练模型的路径。此过程的主要优点是能够覆盖最大范围的扫描设备,以减少用于校准和模型优化的迭代次数。
文档模板以html格式实现。快速有效地准备了一系列测试数据和宏,用合成数据填充模板并自动打印。接下来,我们生成了pdf格式的可打印表格,并为每个文件分配了唯一的标识符,以检查从“解码器”接收到的响应。
神经网络的培训,区域标记和表格的自定义在卖方方面进行。
由于时间限制,模型的训练分为两个阶段。
在第一阶段,该模型被训练来识别文件类型和“粗”识别的文件本身的内容:
需求- >供应商- >准备测试数据- >数据采集- >形式识别训练模型- >测试形式- >设置模型
在第二阶段对模型进行了详细的培训,以识别每种类型的文档的内容。可以通过以下方案描述第二阶段模型的培训和实施,以下方案对于所有类型的文档都是相同的:
准备不同分辨率的测试数据->收集数据并将其传输给供应商->训练模型->测试模型->校准模型->实施模型->在战斗中检查结果->识别问题案例->模拟问题案例并转移给卖方->从测试中重复步骤
应该注意的是,尽管所用扫描仪的范围非常广泛,但示例中仍未提供用于训练模型的许多设备。因此,将模型引入战斗是在试点模式下进行的,结果并未用于自动化。在试验模式下工作期间获得的数据仅记录在数据库中,以供进一步分析和分析。
测试中
由于模型训练循环在卖方一方,并且没有与银行的系统相连,因此在每个训练周期之后,模型被卖方转移到银行,并在测试环境中进行了测试。如果成功进行验证,则将模型转移到认证环境中,在该环境中对其进行回归测试,然后再转移到工业环境中,以识别训练模型时未考虑的特殊情况。
在银行的外围,将数据提交给模型,并将结果记录在数据库中。使用万能的Excel进行数据质量分析-使用数据透视表,具有公式的逻辑及其组合通过if函数的vlookup,hlookup,index,len,match和逐字符字符串比较。
使用模拟文档进行测试使我们能够运行最大数量的测试方案,并尽可能使流程自动化。
首先,在手动模式下,我们检查了所有字段的返回是否符合每种类型文档的原始要求。接下来,当动态填充不同长度的文本块时,我们检查了模型的响应。目的是测试文本在行与行之间以及页面与页面之间移动时的响应质量。最后,我们根据扫描文档的质量检查了字段中答案的质量。为了对模型进行最高质量的校准,使用了文档的低分辨率扫描。
应该特别注意包含最多字段和复选框的最复杂的文档-KYC调查表。对他而言,事先准备了用于填写文档的特殊脚本,并编写了自动宏,这可以加快测试过程,检查所有可能的数据组合并及时向供应商反馈以校准模型。
整合与内部发展
事先对银行的系统和系统间集成进行了必要的修订,并显示在银行的测试环境中。
实现的方案包括以下阶段:
- 接受文档的传入扫描;
- 将接收到的扫描发送到“识别器”。同步和异步模式下最多可以发送10个线程;
- 接收来自“识别器”的响应,检查并验证接收到的数据;
- 将文件的原始扫描件保存在银行的电子图书馆中;
- 在银行的系统中启动处理从“识别器”接收到的数据并由员工进行后续验证;
结果
目前,该模型的培训已经完成,已经在银行的生产环境中成功测试和实施了业务流程。所执行的自动化使开户的平均时间从20分钟减少到5分钟。以前手动执行的用于识别和输入文档数据的业务流程的繁琐阶段已实现自动化。同时,由人为因素引起的错误的可能性也大大降低了。另外,可以保证从银行的不同系统中的同一文档获取的数据的身份。