机器学习。神经网络(第1部分):感知器的学习过程
在本文中,我们将使用神经网络对逻辑OR操作的执行进行建模。 XOR,这是一种用于神经网络的“ Hello World”应用程序。
本文将逐步描述使用TensorFlow.js进行建模的过程。
因此,让我们为逻辑或运算构建一个神经网络。在输入端,我们将始终发送两个信号X 1和X 2,在输出端,我们将接收一个输出信号Y。要训练神经网络,我们还需要一个训练数据集(图1)。

图1-训练数据集和用于对逻辑OR操作进行建模的模型
为了了解要设置的神经网络的结构,让我们想象一下训练数据集在坐标轴为X 1和X 2的坐标平面上(图2,左)。
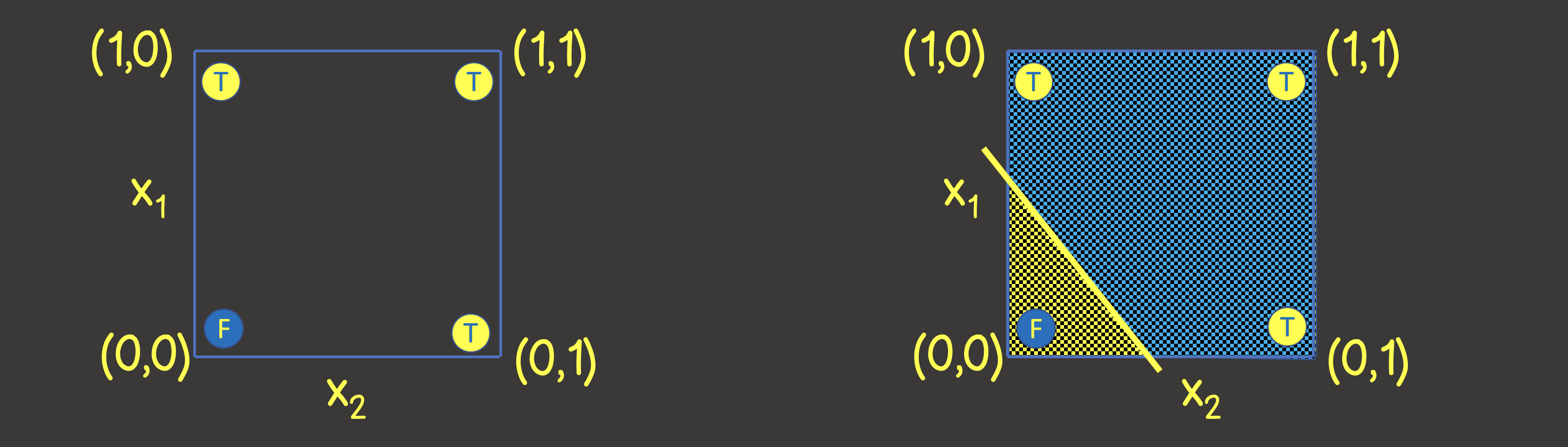
图2-坐标平面上用于逻辑OR操作的训练集
请注意,要解决此问题,我们只需要画一条线将平面分开即可,使得在该线的一侧上所有TRUE值,在另一侧上所有FALSE值(图2,右)。我们还知道,神经网络(感知器)中的一个神经元可以完美地满足此目的,其输出值根据输入信号计算为:
这是直线方程的数学表示。
考虑到我们的值在0到1的范围内,我们也应用了S型激活函数。因此,我们的神经网络

如图3所示。图3-用于训练逻辑OR操作的神经网络
因此,让我们使用TensorFlow.js解决此问题。
首先,我们需要将训练数据集转换为张量。张量是可以包含轴和沿每个轴的任意数量的元素。大多数带有张量的人都熟悉数学-向量(一个轴的张量),矩阵(两个轴的张量-行,列)。
为了定义训练数据集,第一个轴(轴0)始终是所有可用数据样本实例所在的轴(图4)。
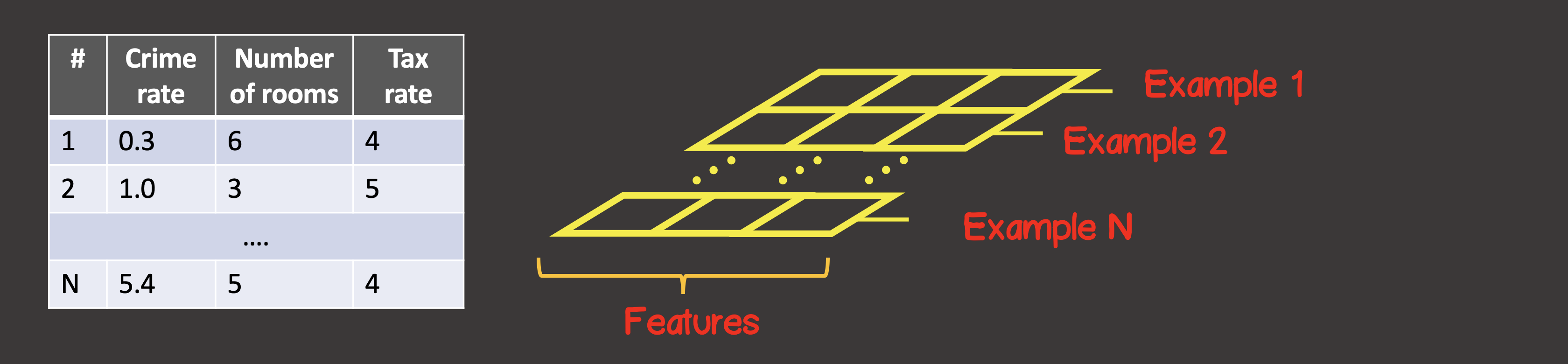
图4-张量结构
在我们的特定情况下,我们有4个数据样本实例(图1),这意味着沿第一个轴的输入张量将包含4个元素。训练样本的每个元素都是一个由两个元素X1,X2组成的向量... 因此,输入张量具有2个轴(矩阵),沿着第一个轴有4个元素,沿着第二个轴有2个元素。
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
同样,将输出转换为张量。对于输入信号,沿着第一个轴,我们有4个元素,每个元素包含一个包含一个值的向量:
const output = [[0], [1], [1], [1]]
const outputTensor = tf.tensor(output, [output.length, 1]);
让我们使用TensorFlow API创建模型:
const model = tf.sequential();
model.add(
tf.layers.dense({ inputShape: [2], units: 1, activation: 'sigmoid' })
);
模型创建总是从调用tf.sequential()开始。模型的主要构建块是图层。我们可以根据需要在神经网络中连接尽可能多的模型。在这里,我们使用密集 层,这意味着下一层中的每个神经元与上一层中的每个神经元都有联系。例如,如果我们有两个密集层,则在第一层神经元,第二个-,则层之间的连接总数为。
如我们所见,在我们的例子中,神经网络由一层组成,其中有一个神经元,因此单位设置为一层。
另外,对于神经网络的第一层,我们必须设置inputShape,因为每个输入实例都由两个值X1和X2的向量表示,因此inputShape = [2]。请注意,无需为中间层设置inputShape -TensorFlow可以从上一层的单位值确定此值。
同样,如果有必要,可以为每个层分配一个激活函数,我们在上面确定这将是一个S型函数。 TensorFlow中当前可用的激活功能可以在此处找到。
接下来,我们需要编译模型(请参阅此处的API ),同时我们需要设置两个必需的参数-这是错误函数以及将寻找其最小值的优化器类型:
model.compile({
optimizer: tf.train.sgd(0.1),
loss: 'meanSquaredError'
});
我们将随机梯度下降设置为优化器,训练步骤为0.1。
库中已实现的优化器的列表:tf.train.sgd,tf.train.momentum,tf.train.adagrad,tf.train.adadelta,tf.train.adam,tf.train.adamax,tf.train.rmsprop。
实际上,默认情况下,与sgd相比,默认情况下,您可以立即选择具有最佳模型收敛速度的adam优化器-训练的每个阶段的学习率取决于先前步骤的历史记录,并且在整个学习过程中并非恒定不变。
作为误差函数,它由均方根误差函数给出:
设置好模型,下一步是训练模型的过程,为此必须在模型上调用fit方法:
async function initModel() {
// skip for brevity
await model.fit(trainingInputTensor, trainingOutputTensor, {
epochs: 1000,
shuffle: true,
callbacks: {
onEpochEnd: async (epoch, { loss }) => {
// any actions on during any epoch of training
await tf.nextFrame();
}
}
})
}
我们已经设定学习过程应包含100个学习步骤(学习时期的数量);同样在每个连续的时期-输入数据应以随机顺序(shuffle = true)进行混洗-这将加快模型收敛的速度,因为我们的训练数据集中很少有实例(4)。
训练过程完成后,我们可以使用预测方法,该方法将基于新的输入信号来计算输出值。
const testInput = generateInputs(10);
const testInputTensor = tf.tensor(testInput, [testInput.length, 2]);
const output = model.predict(testInputTensor).arraySync();
generateInputs 方法仅生成一个10x10样本数据集,将坐标平面分为100个正方形:
完整的代码在这里给出
import React, { useEffect, useState } from 'react';
import LossPlot from './components/LossPlot';
import Canvas from './components/Canvas';
import * as tf from "@tensorflow/tfjs";
let model;
export default () => {
const [data, changeData] = useState([]);
const [lossHistory, changeLossHistory] = useState([]);
useEffect(() => {
async function initModel() {
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
const output = [[0], [1], [1], [1]]
const outputTensor = tf.tensor(output, [output.length, 1]);
const testInput = generateInputs(10);
const testInputTensor = tf.tensor(testInput, [testInput.length, 2]);
model = tf.sequential();
model.add(
tf.layers.dense({ inputShape:[2], units:1, activation: 'sigmoid'})
);
model.compile({
optimizer: tf.train.adam(0.1),
loss: 'meanSquaredError'
});
await model.fit(inputTensor, outputTensor, {
epochs: 100,
shuffle: true,
callbacks: {
onEpochEnd: async (epoch, { loss }) => {
changeLossHistory((prevHistory) => [...prevHistory, {
epoch,
loss
}]);
const output = model.predict(testInputTensor)
.arraySync();
changeData(() => output.map(([out], i) => ({
out,
x1: testInput[i][0],
x2: testInput[i][1]
})));
await tf.nextFrame();
}
}
})
}
initModel();
}, []);
return (
<div>
<Canvas data={data} squareAmount={10}/>
<LossPlot loss={lossHistory}/>
</div>
);
}
function generateInputs(squareAmount) {
const step = 1 / squareAmount;
const input = [];
for (let i = 0; i < 1; i += step) {
for (let j = 0; j < 1; j += step) {
input.push([i, j]);
}
}
return input;
}
在下图中,您将看到部分学习过程:

规划器实施:
逻辑运算XOR的仿真
此功能的训练集如图6所示,我们还将在坐标平面上按照逻辑运算OR的方式安排这些点。
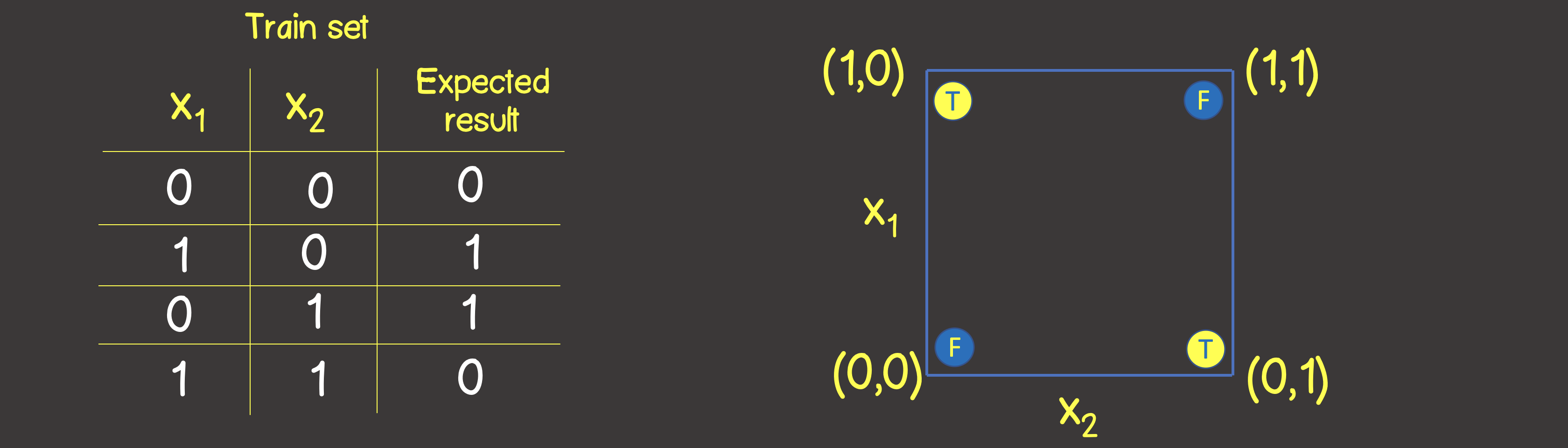
图6-用于建模逻辑运算EXCLUSIVE OR(XOR)的训练数据集和模型
请注意与逻辑“或”运算相反-您不能用一条直线划分平面,以使一侧全是TRUE值,而另一侧全是FALSE。但是,我们可以使用两条曲线来完成此操作(图7)。
显然,在这种情况下,一层中的一个神经元是不够的-至少需要再增加一个具有两个神经元的层,每个层将定义平面上的两条线之一。
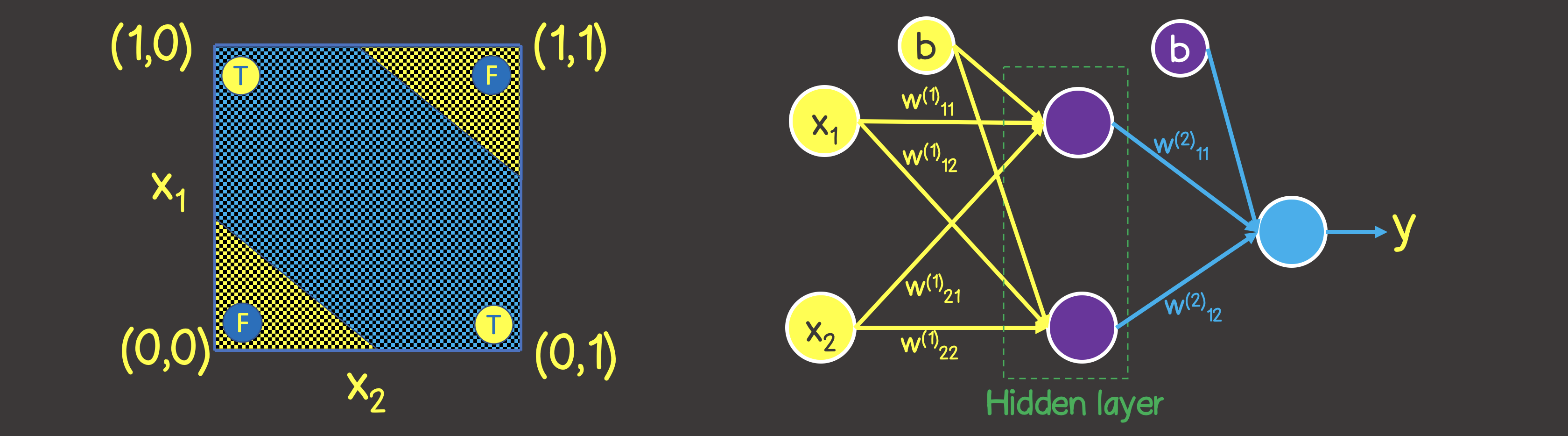
图7-逻辑运算EXCLUSIVE OR(XOR)的神经网络模型
在前面的代码中,我们需要在几个地方进行更改,其中之一是训练数据集本身:
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
const output = [[0], [1], [1], [0]]
const outputTensor = tf.tensor(output, [output.length, 1]);
第二个地方是更改后的模型结构,如图7所示:
model = tf.sequential();
model.add(
tf.layers.dense({ inputShape: [2], units: 2, activation: 'sigmoid' })
);
model.add(
tf.layers.dense({ units: 1, activation: 'sigmoid' })
);
在这种情况下,学习过程如下所示:

规划器实施:
下一篇文章的主题在下一篇
文章中,我们将基于一些功能列表来描述如何解决与将对象分类为类别有关的问题。