 你好居住者!量子计算机引发了新的计算机革命,您现在有很大的机会加入技术突破。开发人员,计算机图形专家和有抱负的IT专业人员将在本书中找到程序员所需的量子计算实用信息。无需学习理论和公式,您将立即专注于展示量子技术独特功能的特定任务。
你好居住者!量子计算机引发了新的计算机革命,您现在有很大的机会加入技术突破。开发人员,计算机图形专家和有抱负的IT专业人员将在本书中找到程序员所需的量子计算实用信息。无需学习理论和公式,您将立即专注于展示量子技术独特功能的特定任务。
埃里克·约翰斯顿(Eric Johnston),尼克·哈里根(Nick Harrigan)和梅赛德斯·吉门诺·塞哥维亚(Mercedes Gimeno-Segovia)帮助开发必要的技能和直觉,并掌握创建量子应用程序所需的工具。您将了解量子计算机的功能以及如何在现实生活中应用它。本书包括三个部分:-编程QPU:对量子处理器进行编程,使用量子位执行操作和进行量子隐形传态的基本概念。-QPU原语:算法原语和方法,幅度放大,量子傅立叶变换和相位估计。-练习QPU:使用QPU原语,量子搜索方法和Shor分解算法解决特定问题。
书籍结构
. , , (GPU), , .
— , QPU. , ( , ). (QPU) , QPU.
. I , .
I. QPU
, QPU: , , . QPU.
II. QPU
. , , . « », . , , QPU. QPU, , .
III. QPU
QPU — II — , QPU. .
, , , , .
— , QPU. , ( , ). (QPU) , QPU.
. I , .
I. QPU
, QPU: , , . QPU.
II. QPU
. , , . « », . , , QPU. QPU, , .
III. QPU
QPU — II — , QPU. .
, , , , .
真实数据
完整的QPU应用程序可以与真实的非训练数据一起使用。实际数据并不总是限于到目前为止所掌握的基本整数。因此,如何在QPU中表示更复杂的数据这一问题值得我们付出努力,并且好的数据结构与好的算法一样重要。在本章中,我们将尝试回答两个先前已被忽略的问题:
- 如何在QPU寄存器中表示复杂的数据类型?正整数可以用简单的二进制编码表示。但是,无理数甚至是向量或矩阵之类的复合数据类型又如何呢?当我们认为叠加和相对相位可以为这些数据类型提供新的量子编码选项时,这个问题将迎来新的深度。
- , QPU? , WRITE . , QPU . , , , QPU , .
让我们从第一个问题开始。当描述越来越复杂的数据类型的QPU表示形式时,我们将介绍成熟的量子数据结构和量子随机存取存储器(QRAM)的概念。量子RAM是许多实际QPU应用程序的关键资源。
后续各章中的材料将高度依赖于本章中介绍的数据结构。例如,将在矢量数据中描述的所谓复振幅编码对于第13章介绍的所有量子机器学习应用都是至关重要的。
非目标数据
如何在QPU寄存器中编码非整数数字数据?用二进制表示这种值的两种标准方法是定点和浮点表示。尽管浮点表示更灵活(并且适应于需要用一定数量的位表示的值的范围),但是由于qubit的高值以及我们对简单性的渴望,定点表示是一个更好的入门方法。
定点数通常用Q表示法描述(不幸的是,在这种情况下Q并不表示“量子”)。这有助于消除关于小数位结束和整数位开始的位置的歧义。 Qn.m表示一个n位寄存器,其中的m位用于小数部分(因此,其余(n-m)包含整数部分)。当然,您可以使用相同的符号来指定应如何使用QPU寄存器对定点数进行编码。例如,在图图9.1显示了一个八比特的QPU寄存器,该寄存器以定点表示形式Q8.6编码值3.640625。
在给定的示例中,所选数字可以精确地编码为定点表示形式,因为3.640625 =
 当然,并非总是能找到这种运气。增加定点寄存器的整数部分中的位数会扩大它可以表示的整数值的范围,而增加小数部分中的位数会提高数的小数部分的精度。小数部分中的
当然,并非总是能找到这种运气。增加定点寄存器的整数部分中的位数会扩大它可以表示的整数值的范围,而增加小数部分中的位数会提高数的小数部分的精度。小数部分中的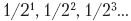 位数越多,某种组合可以更准确地表示给定数字的可能性就越大。
位数越多,某种组合可以更准确地表示给定数字的可能性就越大。

尽管我们将在以下各章中简要提及定点表示法的使用,但它在试验小型QPU寄存器中的实际数据方面起着极其重要的作用。当使用不同的编码方法时,您需要仔细监视特定QPU寄存器中的数据使用的是哪种特定编码,以便正确解释其量子位的状态。
QRAM
QPU寄存器可以存储不同数值的表示形式,但是如何在其中存储这些值呢?手工初始化的数据很快就会过时。我们真正需要的是能够从内存中读取值,在二进制地址中获取存储的值的能力。程序员使用两个寄存器来处理传统的随机存取存储器:一个用存储器地址初始化,而另一个未初始化。随机存取存储器将存储在第一个寄存器指定地址的二进制数据写入第二个寄存器,如图2所示。 9.2。
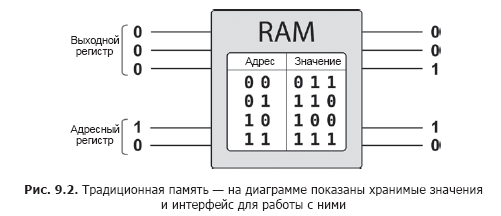
可以使用传统内存来存储用于初始化QPU寄存器的值吗?当然,这个主意看起来很吸引人。
如果只想用一个传统值(二进制补码,定点数或简单的二进制编码)初始化QPU寄存器,那么RAM就可以了。所需的值仅存储在存储器中,并且write()和read()用于写入或读取QPU寄存器。到目前为止,QCEngine JavaScript代码已使用这种受限制的机制与QPU寄存器进行交互。
例如,清单9.1中的示例代码接收一个数组a并实现a [2] + = 1;操作,从RAM中隐式获取此值数组以初始化QPU寄存器。电路如图。9.3。

样例代码
该示例可以在http://oreilly-qc.github.io?p=9-1上在线完成。
代码清单9.1 使用QPU增加内存数量
var a = [4, 3, 5, 1];
qc.reset(3);
var qreg = qint.new(3, 'qreg');
qc.print(a);
increment(2, qreg);
qc.print(a);
function increment(index, qreg)
{
qreg.write(a[index]);
qreg.add(1);
a[index] = qreg.read();
}应当注意的是,在这种简单情况下,不仅传统的RAM用于存储整数,而且传统的处理器也对阵列进行索引以选择和传输所需值的QPU。
尽管这种使用RAM可以将QPU寄存器初始化为简单的二进制值,但是它具有严重的局限性。如果需要通过存储值的叠加来初始化QPU寄存器该怎么办?例如,假设在RAM中,值3(110)存储在地址0x01,值5(111)存储在地址0x11。如何准备这两个值的叠加输入寄存器?
使用传统的RAM和笨拙的传统write()操作,这将无法工作。就像他们的电子管祖先所做的那样,量子处理器从根本上将需要新的存储设备-本质上就是量子。 Meet Quantum随机存取存储器(QRAM)使您可以在量子级别读取和写入数据。关于如何物理构建QRAM的想法已经很多,但值得注意的是,历史可能会重演,而功能强大的量子处理器可能会在任何可行的量子存储硬件出现之前就出现了。
值得更精确地解释QRAM的功能。像传统存储器一样,QRAM接收两个寄存器作为输入:用于存储器地址的QPU地址寄存器和用于返回存储在给定地址的值的QPU输出寄存器。对于QRAM,两个寄存器都由量子位组成。这意味着在地址寄存器中可以设置存储单元的叠加,因此可以在输出寄存器中获得对应值的叠加(图9.4)。

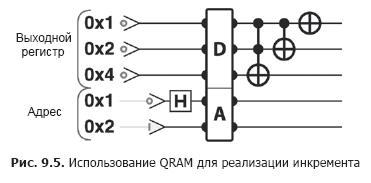
因此QRAM实际上允许您叠加读取存储的值。输出寄存器中要获得的叠加的确切复数幅值由地址寄存器中提供的叠加决定。在图。图9.2显示了执行清单9.1(图9.5)中的相同增量操作时的区别,但使用QRAM而不是QPU读/写操作来访问数据。字母“ A”表示在其中发送QRAM地址(或叠加)的寄存器。字母``D''表示QRAM返回存储值(数据)的相应叠加的寄存器。
样例代码
该示例可以在oreilly-qc.github.io?p=9-2上在线完成。
清单9.2。使用QPU从QRAM递增数字-地址寄存器可能包含叠加,这将导致输出寄存器包含存储值的叠加
var a = [4, 3, 5, 1];
var reg_qubits = 3;
qc.reset(2 + reg_qubits + qram_qubits());
var qreg = qint.new(3, 'qreg');
var addr = qint.new(2, 'addr');
var qram = qram_initialize(a, reg_qubits);
qreg.write(0);
addr.write(2);
addr.hadamard(0x1);
qram_load(addr, qreg);
qreg.add(1);QRAM的这种描述似乎太含糊-什么是量子存储硬件?在本书中,我们将不会在实践中描述如何构建QRAM(例如,大多数C ++书籍都没有提供传统内存的工作原理的详细描述)。清单9.2中的代码示例是使用模拟QRAM行为的简化模型执行的。尽管如此,QRAM技术的原型还是存在的。
尽管量子存储器将成为任何重要QPU的关键组成部分,但实现细节可能会与任何量子计算设备一样发生变化。对我们来说重要的是基本行为的想法,如图所示。9.4,以及可以在其之上构建的强大应用程序。
有了量子内存,您就可以继续构建复杂的量子数据结构。特别令人感兴趣的是允许您表示向量和矩阵数据的结构。
向量编码
假设您要初始化QPU寄存器以表示一个简单的矢量,如公式9.1。
公式9.1。用于初始化QPU寄存器的向量的示例。

这种形式的数据通常在量子机器学习应用程序中找到。
编码矢量数据最明显的方法也许是将每个组件表示为具有合适二进制表示形式的单独QPU寄存器。我们将这种(可能是最明显的)向量的方法状态编码称为。可以将上述示例中的向量编码在四个两个二比特寄存器中,如图2所示。 9.6。

天真的状态编码的问题之一是它浪费了量子比特-QPU的最宝贵资源。但是,传统的状态编码向量的优点之一是它们不需要量子存储器。向量分量可以简单地存储在标准存储器中,并使用它们各自的值来控制每个单独的QPU寄存器的准备。但是,这种优势也隐藏了向量状态编码中最严重的缺陷:以这种传统方式存储向量数据会阻止我们使用QPU的非传统功能。要使用QPU的功能,您需要能够操纵叠加的相对相位,这并不容易做到,如果向量的每个分量实际上都将您的量子处理器视为传统二进制寄存器的集合!
相反,您需要下降到量子水平。假设矢量分量存储在一个QPU寄存器的振幅的叠加中。由于可以将n个量子位的QPU寄存器以2n个幅度叠加(因此将有2n个圆形用于圆形记录实验),因此可以在具有ceil(log(n))个量子位的QPU寄存器中表示具有n个分量的向量的编码。
对于公式9.1中的矢量示例,此方法将需要一个2量子位寄存器-这个想法是找到一个合适的量子电路来编码图1中的矢量数据。 9.7。

我们称这种独特的量子矢量数据编码为复振幅编码。重要的是要理解复振幅编码和更常规的状态编码之间的差异。表9.1比较了不同矢量数据的两种编码方法。最后一个状态编码示例将需要四个7位寄存器,每个寄存器使用Q7.7的定点表示形式。
表9.1。向量数据编码方式(复振幅编码和状态编码)之间的差异

要在QCEngine中使用复杂的幅度编码获取矢量,可以使用方便的振幅_编码()函数。清单9.3中的程序采用值的向量和对QPU寄存器的引用(必须足够大),并通过对该向量执行复杂的幅度编码来准备该寄存器。
样例代码
该示例可以在oreilly-qc.github.io?p=9-3上在线完成。
清单9.3。在QCEngine中使用复杂的幅度编码准备向量
// ,
// 2
var vector = [-1.0, 1.0, 1.0, 5.0, 5.0, 6.0, 6.0, 6.0];
//
//
var num_qubits = Math.log2(vector.length);
qc.reset(num_qubits);
var amp_enc_reg = qint.new(num_qubits, 'amp_enc_reg');
// amp_enc_reg
amplitude_encode(vector, amp_enc_reg);在此示例中,向量只是作为存储在传统内存中的JavaScript数组传递的,即使我们已经表明复杂的幅度编码取决于QRAM。当程序只有计算机的RAM可用时,QCEngine如何执行复杂的幅度编码?尽管可以在没有QRAM的情况下生成复杂的幅度编码方案,但是肯定不能有效地完成它。QCEngine提供了一个缓慢但可行的QRAM访问模型。
复振幅编码的局限性
最初,复振幅编码背后的想法看起来很棒-它使用较少的量子位,并提供用于处理矢量数据的量子工具。在使用这种机制的任何应用程序中,都需要考虑两个重要因素。
问题1:量子结果
您可能已经注意到了这些限制中的第一个:量子叠加通常无法通过READ读取。我们的主要敌人了!如果将矢量分量分布在量子叠加上,则无法再次读取它们。自然地,将向量数据从内存传输到另一个QPU程序的输入时,这不会造成任何特殊问题。但通常,在输入端接收具有复振幅编码的矢量数据的QPU应用程序也会在输出端产生具有复振幅编码的矢量数据。
因此,使用复杂的幅度编码会严重限制我们使用READ操作读取应用程序输出的能力。幸运的是,通常可以从复杂的幅度编码结果中提取有用的信息。正如您将在以下各章中看到的那样,尽管您无法识别各个组成部分,但可以找到以这种方式编码的向量的全局属性。但是,复杂的幅度编码不是万能的,它的成功应用需要关注和独创性。
问题2:标准化向量的要求
表中隐藏了与复振幅编码相关的第二个问题。 9.1。仔细查看表中前两个矢量的复振幅编码:[0,1,2,3]和[6,1,1,4]。两比特QPU寄存器的复数幅度可以取值为[0,1,2,3]还是取值为[6,1,1,4]?不幸的是没有。在前面的章节中,我们通常绕开了幅度和相对相位的讨论,而采用了更直观的圆形符号。尽管这种方法更加直观,但它使您摆脱了关于复振幅的重要数字规则:寄存器复振幅的平方必须加起来为1。当您记得寄存器中振幅的平方与读取的概率相对应时,这种要求称为归一化,这似乎是合乎逻辑的。结果不同。由于必须获得一个结果,因此这些概率(以及所有复振幅的平方)应加起来为1。使用方便的圆形符号时,很容易忘记归一化,但是它对哪个向量设置了重要的约束。复振幅编码可以应用于数据。物理定律不允许创建具有复振幅[0,1,2,3]或[6,1,1,4]的寄存器。与复振幅[0,1,2,3]或[6,1,1,4]重叠。与复振幅[0,1,2,3]或[6,1,1,4]叠加。
对表中的两个问题向量应用复振幅编码。在9.1中,您首先需要通过将每个分量除以所有分量的平方和来归一化它们。例如,在向量[0,1,2,3]的复振幅编码中,您首先需要将所有分量除以3.74,以获得归一化向量[0.00、0.27、0.53、0.80],该向量现在适用于在复数叠加振幅中进行编码。
归一化向量数据是否有任何不良影响?数据似乎已完全更改!实际上,归一化使大多数重要信息保持不变(在几何表示中,它只是缩放向量的长度,而使方向不变)。我们可以假设规范化数据完全替代了原始数据吗?这取决于您打算在其中使用特定QPU应用程序的需求。请记住,必要时可以将归一化因子的数值存储在其他寄存器中。
复振幅编码和循环记录
当您开始更具体地考虑寄存器的复振幅的数值时,可能会有助于提醒自己如何以圆形符号表示复振幅,并注意可能的陷阱。圆形符号的填充区域表示量子态复振幅的振幅的平方。在诸如复振幅编码的情况下,其中复振幅必须表示具有实数值的矢量的分量,这意味着填充区域由矢量的相应分量的平方确定,而不由分量本身确定。在图。图9.8显示了在以圆括号表示法归一化之后,如何正确解释向量[0,1,2,3]的表示。

您现在对复振幅编码矢量已经足够了解,以了解将在本书中介绍的QPU应用。但是对于许多应用程序,尤其是与量子机器学习有关的应用程序,有必要进一步走下去,并使用QPU不仅操纵向量,而且操纵整个数据矩阵。您如何编码数字的二维数组?
»有关这本书的更多详细信息,请访问出版商的网站
»目录
»摘录
给居住者的优惠券可享受25%的折扣-编程
在为该书的纸质版本付款后,会向该电子邮件发送一本电子书。