我们将告诉您该工具为何出现以及它可以做什么。

缺乏算法
机器学习的关键挑战之一是数据维数的减少。数据科学家通过在变量中隔离对结果影响最大的值来减少变量的数量。完成此操作后,机器学习模型需要更少的内存,工作更快更好。下面的示例显示,消除重复特征可以将分类精度从0.903提高到0.943。
>>> from sklearn.linear_model import SGDClassifier
>>> from ITMO_FS.embedded import MOS
>>> X, y = make_classification(n_samples=300, n_features=10, random_state=0, n_informative=2)
>>> sel = MOS()
>>> trX = sel.fit_transform(X, y, smote=False)
>>> cl1 = SGDClassifier()
>>> cl1.fit(X, y)
>>> cl1.score(X, y)
0.9033333333333333
>>> cl2 = SGDClassifier()
>>> cl2.fit(trX, y)
>>> cl2.score(trX, y)
0.9433333333333334降维有两种方法-特征设计和特征选择。在生物信息学和医学等领域,经常使用后者,因为它使您可以在保留语义的同时突出显示重要的功能,也就是说,它不会改变功能的原始含义。但是,最常见的Python机器学习库-scikit-learn,pytorch,keras和tensorflow-缺少一套完整的功能选择方法。
为了解决这个问题,ITMO大学的学生和研究生已经开发了一个开放库-ITMO_FS。在信息技术与编程学院副教授Ivan Smetannikov的领导下,一个团队正在研究它机器学习实验室副主任。首席开发人员Nikita Pilnenskiy,毕业于机器学习和数据分析硕士学位。现在他去读研究生。
« , . , , , (-) .
, , , . , , , ».
—
ITMO_FS是用Python实现的,并且与scikit-learn兼容,后者被认为是事实上的主要数据分析工具。其功能选择器采用相同的参数:
data: array-like (2-D list, pandas.Dataframe, numpy.array);
targets: array-like (1-D list, pandas.Series, numpy.array).该库支持所有经典的特征选择方法-过滤器,包装器和内联方法。其中包括基于Spearman和Pearson相关性的滤波器,Fit Criterion,QPFS,爬山滤波器等算法。

该库还通过结合基于特征量选择算法的特征选择算法来支持训练合奏。这种方法可让您以较少的时间投入获得更高的预测结果。
什么是类似物
特征选择算法库不多,尤其是在Python中。规模最大的公司之一被认为是亚利桑那州立大学(ASU)工程师的发展。它支持大量算法,但是最近几乎没有更新。
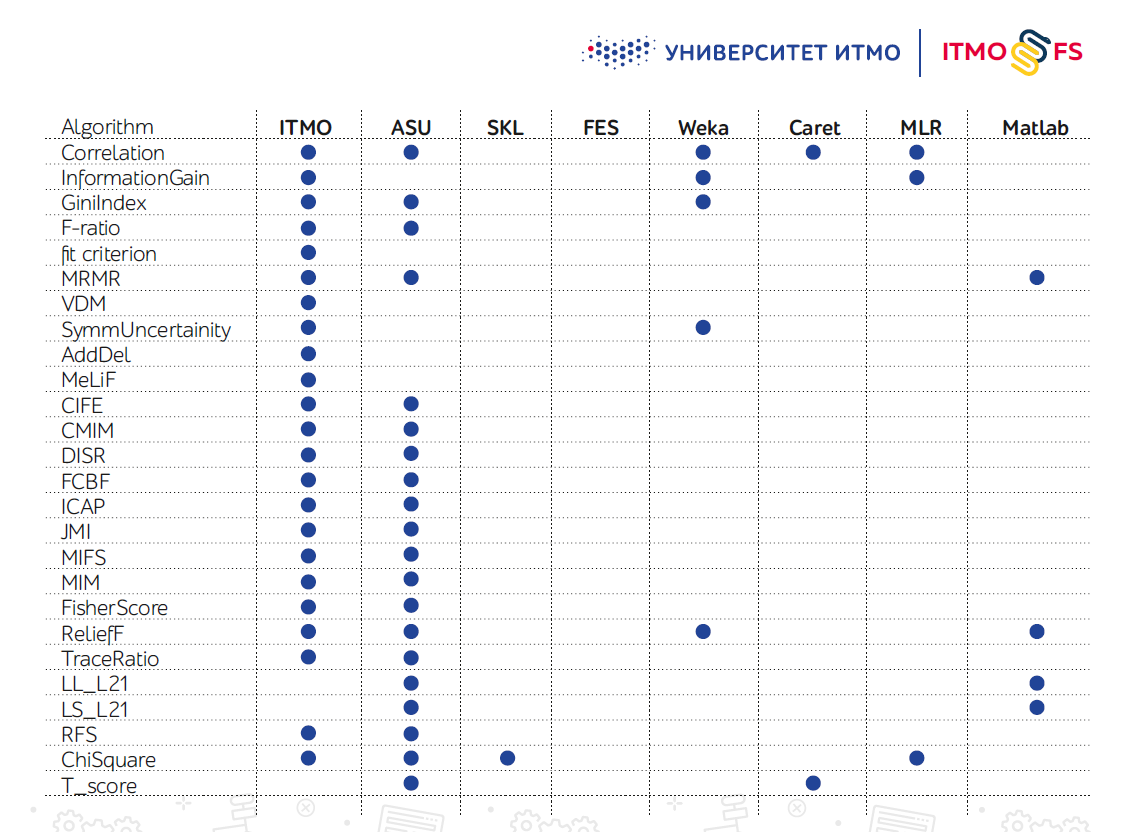
Scikit学习本身也具有几种功能选择机制,但实际上它们还不够。
“总的来说,在过去的五到七年中,重点已经转移到用于特征选择的整体算法上,但是在此类库中并未特别体现出来,我们也希望对其进行修复。”
-伊万·斯梅坦尼科夫(Ivan Smetannikov)
项目前景
ITMO_FS的作者计划将其产品与scikit-learn集成,方法是将其添加到正式兼容的库列表中。目前,该库中已经包含了所有库中数量最多的特征选择算法,但是它们的添加仍在继续。路线图上进一步增加了新算法,包括我们自己的开发。
在更遥远的计划中,需要执行以下任务:将库引入元学习系统,添加用于直接处理矩阵数据的算法(填补空白,生成元属性空间数据等),以及图形界面。同时,将使用该库举行黑客马拉松,以吸引更多产品开发人员并获得反馈。
预计ITMO_FS将在医学和生物信息学领域找到应用-诸如各种癌症的诊断,表型特征的预测模型的构建(例如,一个人的年龄)和药物合成等问题。
在哪里可以下载
如果您对ITMO_FS项目感兴趣,可以下载该库并进行实际尝试-这是GitHub上的存储库。该文档的初始版本可在readthedocs上找到。在此您还可以看到安装说明(pip支持)。我们欢迎任何反馈。
我们在Habré博客上的其他资料: