解析中
什么是解析?这是使用使过程自动化的特殊程序对发布在网站上的信息进行收集和系统化。
解析通常用于定价分析和内容检索。
开始
为了从庄家那里筹集资金,我不得不迅速从几个站点接收有关某些事件的赔率的信息。我们将不涉及数学部分。
自从我在sharaga中学习C#以来,我决定在其中编写所有内容。建议Stack Overflow的人员使用Selenium WebDriver。它是浏览器驱动程序(软件库),使您可以开发控制浏览器行为的程序。我想这就是我们所需要的。
我安装了图书馆,然后奔跑观看Internet上的指南。一段时间后,我编写了一个程序,该程序可以打开浏览器并跟踪某些链接。
万岁!虽然停止了,但是如何按下按钮,如何获得必要的信息呢?XPath将在这里为我们提供帮助。
XPath
简而言之,它是用于查询XML和XHTML文档元素的语言。
对于本文,我将使用Google Chrome。但是,其他现代浏览器应该具有相似的界面,如果不相同的话。
要查看您所在页面的代码,请按F12键。

要查看代码中页面的哪个位置(文本,图片,按钮),请单击左上角的箭头,然后在页面上选择此元素。现在让我们继续语法。
编写XPath的标准语法:
//标记名[@ attribute ='value']
//:从当前节点开始选择html文档中的所有节点
标记名:当前节点的标记。
@:选择属性
Attribute:节点的属性名称。
值:属性的值。
起初可能还不清楚,但是在示例之后,所有内容都应该放在适当的位置。
让我们看一些简单的示例:
//输入[@ type ='text']
//标签[@ id ='l25']
//输入[@ value ='4']
// // [@ href ='www.walmart。 com']
考虑给定html'i的更复杂的示例:
<div class ='contentBlock'>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habr</span>
</a>
<div class = 'textConainer'>
<span class='description'>cool site</span>
"text2"
</div>
</div>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habrhabr</span>
</a>
<div class = 'textConainer'>
<span class='description'>the same site</span>
"text1"
</div>
</div>
</div>XPath = // div [@ class ='contentBlock'] // div
将为此XPath选择以下元素:
<div class = 'listItem'>
<div class = 'textConainer'>
<div class = 'listItem'>
<div class = 'textConainer'>XPath = // div [@ class ='contentBlock'] / div
<div class = 'listItem'>
<div class = 'listItem'>注意/(从根节点获取)和//(从当前节点获取节点,而不管它们的位置)之间的区别。如果不清楚,请再次查看上面的示例。
// div [@ class ='contentBlock'] / div [@ class ='listItem'] / a [@ class ='link'] / span [@ class ='name']
此请求与此html相同:
// div / div / a / span
// span [@ class ='name']
// a [@ class ='link'] / span [@ class ='name']
// a [@ class ='链接'和href='habr.com'] / span
// span [text()='habr'or text()='habrhabr']
// div [@ class ='listItem'] // span [@ class ='name' ]
// a [包含(href,'habr')] / span
// span [包含(text(),'habr')]
结果:
<span class='name'>habr</span>
<span class='name'>habrhabr</span>// span [text()='habr'] / parent :: a / parent :: div
等于
// div / div [@ class ='listItem'] [1]
结果:
<div class = 'listItem'>parent :: -返回上一级父级。
还有一个超酷的功能,例如after-sibling :: -返回当前元素之后处于同一级别的许多元素,类似于previous-sibling :: -返回许多当前元素之前处于同一级别的元素。
//跨度[@ class ='name'] /跟随其后:: :: text()[1]
结果:
"text1"
"text2"我认为现在更清楚了。为了巩固材料,我建议您转到此站点并写一些请求以查找此html'i的某些元素。
<div class="item">
<a class="link" data-uid="A8" href="https://www.walmart.com/grocery/?veh=wmt" title="Pickup & delivery">
<span class="g_b">Pickup and delivery</span>
</a>
<a class="link" data-uid="A9" href="https://www.walmart.com/" title="Walmart.com">
<span class="g_b">Walmart.com</span>
</a>
</div>
<div class="item">
<a class="link" data-uid="B8" href="https://www.walmart.com/grocery/?veh=wmt" title="Savings spotlight">
<span class="g_b">Savings spotlight</span>
</a>
<a class="link" data-uid="B9" href="https://www.walmartethics.com/content/walmartethics/it_it.html" title="Walmart.com">
<span class="g_b">Walmart.com(Italian)</span>
"italian virsion"
</a>
</div>现在我们知道了XPath是什么,让我们回到编写代码。由于Habr主持人不喜欢博彩公司,因此他们将解析沃尔玛的咖啡价格
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
IWebDriver driver = new ChromeDriver(pathToFile);
driver.Navigate().GoToUrl("https://walmart.com");
Thread.Sleep(5000);
IWebElement element = driver.FindElement(By.XPath("//button[@id='header-Header sparkButton']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//button[@data-tl-id='GlobalHeaderDepartmentsMenu-deptButtonFlyout-10']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//div[text()='Coffee']/parent::a"));
driver.Navigate().GoToUrl(element.GetAttribute("href"));
Thread.Sleep(10000);
List<string> names = new List<string>(), prices = new List<string>();
List<IWebElement> listOfElements =driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-title']/div")).ToList();
foreach (IWebElement a in listOfElements)
names.Add(a.Text);
listOfElements = driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-price']/span/span[contains(text(),'$')]")).ToList();
foreach (IWebElement a in listOfElements)
prices.Add(a.Text);
for (int i = 0; i < prices.Count; i++)
Console.WriteLine(names[i] + " " + prices[i]);编写Thread.Sleep的目的是为了使网页有时间加载。
该程序将打开沃尔玛商店的网站,按几个按钮,打开咖啡部分,并获取商品名称和价格。
如果网页很大,因此XPath需要很长时间或很难编写,那么您需要使用其他方法。
HTTP请求
首先,让我们看一下内容在网站上的显示方式。

简而言之,浏览器向服务器发出请求,请求提供必要的信息,然后服务器提供此信息。所有这些都是使用HTTP请求完成的。
要查看浏览器在特定站点上发送的请求,只需打开该站点,按F12并转到“网络”选项卡,然后重新加载页面即可。

现在剩下的就是找到我们需要的请求。
怎么做? -考虑所有具有提取类型的请求(上图中的第三列),然后查看“预览”标签。

如果不为空,则必须为XML或JSON格式,否则,请继续查找。如果是这样,请查看您所需的信息是否在这里。要对此进行检查,我建议您使用某种JSON Viewer或XML Viewer(谷歌并打开第一个链接,从“响应”选项卡中复制文本并将其粘贴到Viewer中)。找到所需的请求后,将其名称(左列)或URL主机(“页眉”选项卡)保存在某处,以便以后无需搜索。例如,如果您在walmart网站上开设咖啡部门,则会发送请求,该请求的合法性始于walmart.com/cp/api/wpa。将有关于出售咖啡的所有信息。
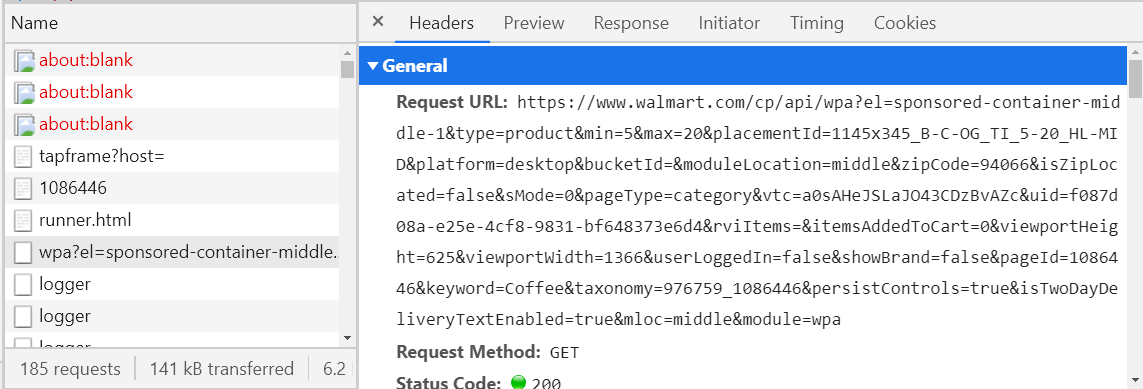
中途过去了,现在可以将该请求“伪造”并立即通过程序发送,在几秒钟内接收到必要的信息。它仍然可以解析JSON或XML,这比编写XPath容易得多。但是形成这样的请求通常是一件很不愉快的事情(请参见上图中的URL),并且即使您成功了,在某些情况下您也会收到这样的响应。
{
"detail": "No authorization token provided",
"status": 401,
"title": "Unauthorized",
"type": "about:blank"
}现在,您将学习如何避免使用替代服务器(代理服务器)模仿请求的问题。
代理服务器
代理服务器是在计算机和Internet之间进行中介的设备。
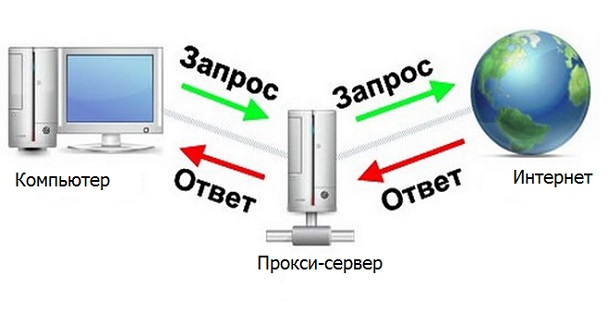
如果我们的程序是代理服务器,那就太好了,那么您可以快速方便地处理来自服务器的必要响应。然后将有一个这样的链浏览器-程序-Internet(已解析的站点服务器)。
幸运的是,对于SI Sharp而言,有一个满足此类需求的出色图书馆-Titanium Web Proxy。
让我们创建PServer类
class PServer
{
private static ProxyServer proxyServer;
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")){
Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}
}现在,让我们分别介绍每种方法。
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}proxyServer.BeforeRepsone + = OnRespone-添加用于处理服务器响应的方法。响应到达时将自动调用它。
explicitEndPoint-代理服务器配置,
ExplicitProxyEndPoint(IPAddress ipAddress,int端口,布尔型cryptoSsl = true)
运行代理服务器的IP地址和端口。
cryptoSsl-是否解密SSL。换句话说,如果decrtyptSsl = true,则代理服务器将处理所有请求和响应。
visibleEndPoint.BeforeTunnelConnectRequest + = OnBeforeTunnelConnectRequest-添加一种用于在将请求发送到服务器之前处理请求的方法。发送请求之前,也会自动调用它。
proxyServer.Start() -从此刻开始“启动”代理服务器,它开始处理请求和响应。
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}e.DecryptSsl = false-当前的请求和响应将不被处理。
如果我们对请求或响应不感兴趣(例如,图片或某种脚本),那么为什么要对其解密?在此上花费了大量资源,并且如果所有请求和响应都被解码,则该程序将运行很长时间。因此,如果当前请求不包含我们感兴趣的请求的主机,则解密它毫无意义。
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")) Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}等待e.GetResponseBodyAsString() -以字符串形式返回响应。
为了使WebDriver连接到代理服务器,您需要编写以下内容:
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
ChromeOptions options = new ChromeOptions();
options.AddArguments("--proxy-server=" + IPAddress.Loopback + ":8000");
IWebDriver driver = new ChromeDriver(pathToFile, options);现在,您可以处理所需的请求。
结论
使用WebDriver,您可以浏览页面,单击按钮并模仿普通用户的行为。使用XPath,您可以从网页中提取所需的信息。如果XPath不起作用,则代理服务器始终可以提供帮助,该服务器可以拦截浏览器和站点之间的请求。