该项目已经发展壮大,图书馆现在解决了处理俄语自然语言的所有基本任务:分割成标记和句子,形态和句法分析,词形化,提取命名实体。

对于新闻报道,所有任务的质量都可以与现有解决方案相比或更高... 例如,娜塔莎(Natasha)的NER任务比Deeppavlov BERT NER(F1 PER 0.97,LOC 0.91,ORG 0.85)差1个百分点,该模型的重量减轻了75倍(27MB),在CPU上的处理速度提高了2倍(25篇/秒) ),而不是GPU上的BERT NER。
项目中有9个存储库,Natasha库将它们合并在一个界面下。在本文中,我们将讨论新工具,并将它们与现有解决方案进行比较:Deeppavlov,SpaCy和UDPipe。

在阅读此长篇文章之前,在natasha.github.io上发布了一系列文章:如果您对以下文本的大小感到恐惧,请观看关于Natasha项目历史的电视广播节目的前20分钟,以下是简短的重述:
- Natasha-用于俄语的高质量紧凑型NER
- Navec-俄语的紧凑型嵌入
- Corus-俄语NLP数据集的集合
- Razdel-将俄语文本分割为令牌和优惠
- Naeval-俄语NLP系统的定量比较
- Nerus是一个大型的综合俄语语言数据集,具有形态,语法和命名实体的标记
文本使用来自t.me/natural_language_processing聊天的注释和讨论,指向新材料的链接出现在同一位置:
对于那些喜欢聆听更多内容的人,请查看Datafest 2020上的每小时谈话,它几乎涵盖了这篇文章:
内容:
- Natasha — .
- Razdel —
- Slovnet — deep learning
- Navec —
- Nerus — ,
- Corus — +
- Naeval — NLP
- Yargy- —
- Ipymarkup —
Natasha — .

以前,Natasha库基于规则解决了俄语的NER问题,显示了平均质量和性能。现在,娜塔莎是一个很大的项目,它由9个存储库组成。Natasha库将它们统一在一个界面上,解决了处理俄语自然语言的基本任务:分割成标记和句子,预训练的嵌入,形态和语法分析,词形化,NER。所有解决方案在新闻主题中均显示最佳结果,并在CPU上快速运行。
Natasha与其他组合库类似:SpaCy,UDPipe,Stanza... SpaCy隐式初始化并调用模型,用户将文本传递给magic函数
nlp,获得完全解析的文档。
import spacy
# load ,
# , NER
nlp = spacy.load('...')
# ,
text = '...'
doc = nlp(text)
Natasha的界面更详细。用户显式初始化组件:加载预训练的嵌入,并将它们传递给模型构造函数。萨姆称方法为
segment,tag_morph,parse_syntax分割成标记和需求,词法和语法分析。
>>> from natasha import (
Segmenter,
NewsEmbedding,
NewsMorphTagger,
NewsSyntaxParser,
Doc
)
>>> segmenter = Segmenter()
>>> emb = NewsEmbedding()
>>> morph_tagger = NewsMorphTagger(emb)
>>> syntax_parser = NewsSyntaxParser(emb)
>>> text = ' , , 2019 () ...'
>>> doc = Doc(text)
>>> doc.segment(segmenter)
>>> doc.tag_morph(morph_tagger)
>>> doc.parse_syntax(syntax_parser)
>>> sent = doc.sents[0]
>>> sent.morph.print()
NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
PROPN|Animacy=Inan|Case=Gen|Gender=Masc|Number=Sing
ADP
PROPN|Animacy=Inan|Case=Loc|Gender=Fem|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
...
>>> sent.syntax.print()
┌──► nsubj
│
│ ┌► case
│ └─
│ ┌─
│ └► flat:name
┌─────┌─└───
│ │ ┌──► , punct
│ │ │ ┌► mark
│ └►└─└─ ccomp
│ │ ┌► case
│ └──►└─ obl
...
命名实体提取器不依赖于形态学和解析的结果,可以单独使用。
>>> from natasha import NewsNERTagger
>>> ner_tagger = NewsNERTagger(emb)
>>> doc.tag_ner(ner_tagger)
>>> doc.ner.print()
, ,
LOC──── LOC──── PER───────
2019
LOC──────────────
()
LOC─── ORG───────────────────────────────────────
...
PER────────────
Natasha解决了词根化问题,使用Pymorphy2和形态分析结果。
>>> from natasha import MorphVocab
>>> morph_vocab = MorphVocab()
>>> for token in doc.tokens:
>>> token.lemmatize(morph_vocab)
>>> {_.text: _.lemma for _ in doc.tokens}
{'': '',
'': '',
'': '',
'': '',
'': '',
'': '',
'': '',
',': ',',
'': '',
'': ''
...
要使该短语恢复正常状态,仅查找单个单词的词根是不够的,因为对于俄罗斯民族主义者组织-乌克兰民族主义者组织来说,俄罗斯外交部将变成俄罗斯外交部。Natasha使用解析结果,考虑单词之间的关系,对命名实体进行规范化。
>>> for span in doc.spans:
>>> span.normalize(morph_vocab)
>>> {_.text: _.normal for _ in doc.spans}
{'': '',
'': '',
' ': ' ',
' ': ' ',
'': '',
' ()': ' ()',
' ': ' ',
...
Natasha在文本中查找姓名,组织和地名。对于库中的名称,Yargy解析器有一组现成的规则,该模块将归一化的名称分为多个部分,从“ Viktor Fedorovich Yushchenko”中获得
{first: , last: , middle: }。
>>> from natasha import (
PER,
NamesExtractor,
)
>>> names_extractor = NamesExtractor(morph_vocab)
>>> for span in doc.spans:
>>> if span.type == PER:
>>> span.extract_fact(names_extractor)
>>> {_.normal: _.fact.as_dict for _ in doc.spans if _.type == PER}
{' ': {'first': '', 'last': ''},
' ': {'first': '', 'last': ''},
' ': {'first': '', 'last': ''},
'': {'last': ''},
' ': {'first': '', 'last': ''}}
该库包含用于解析日期,金额和地址的规则,这些规则在文档和参考书中进行了描述。
Natasha图书馆非常适合演示教育中使用的项目技术。带有模型权重的归档文件内置在软件包中;安装后,您无需下载和配置任何内容。
Natasha在一个界面下结合了其他项目库。要解决实际问题,应直接使用它们:
- Razdel-将文本分割为句子和标记;
- Navec-高品质紧凑型嵌入;
- Slovnet-用于形态,语法,NER的现代紧凑模型;
- Yargy-提取结构化信息的规则和词汇;
- Ipymarkup -NER和语法标记的可视化;
- Corus-到公共俄语数据集的链接的集合;
- Nerus是一个大型语料库,具有命名实体,形态和语法的自动标记。
Razdel-将俄语文本分割为令牌和优惠

Razdel库是Natasha项目的一部分,将俄语文本分为标记和句子。Razdel存储库中的安装说明,用法示例和性能度量。
>>> from razdel import tokenize, sentenize
>>> text = '- 0.5 (50/64 ³, 516;...)'
>>> list(tokenize(text))
[Substring(start=0, stop=13, text='-'),
Substring(start=14, stop=16, text=''),
Substring(start=17, stop=20, text='0.5'),
Substring(start=20, stop=21, text=''),
Substring(start=22, stop=23, text='(')
...]
>>> text = '''
... - " ?" - " --".
... . . . . ,
... '''
>>> list(sentenize(text))
[Substring(start=1, stop=23, text='- " ?"'),
Substring(start=24, stop=40, text='- " --".'),
Substring(start=41, stop=56, text=' . . . .'),
Substring(start=57, stop=76, text=' , ')]
现代模型通常不用理会分段,它们使用BPE,显示出非凡的效果,记住所有版本的GPT和BERT Zoo 。Natasha解决了语法和语法解析问题,仅对一个句子中的单独单词有意义。因此,我们负责任地接近细分的阶段,试图从流行的开放式数据集重复标记:SynTagRus,OpenCorpora,GICRYA。
Razdel的速度和质量与其他俄语开放源解决方案相当或更好。
| 令牌分割解决方案 | 每1000个令牌的错误 | 处理时间,秒 |
| 正则表达式基准 | 19 | 0.5 |
| 空间
|
17 | 5.4 |
| NLTK
|
130 | 3.1 |
| MyStem
|
19 | 4.5 |
| 摩西
|
十一 | 1.9 |
| 赛格通
|
12 | 2.1 |
| SpaCy Russian Tokenizer
|
8 | 46.4 |
| RuTokenizer
|
15 | 1.0 |
| Razdel
|
7 | 2.6 |
| 1000 | , | |
| Regexp-baseline | 76 | 0.7 |
| SegTok
|
381 | 10.8 |
| Moses
|
166 | 7.0 |
| NLTK
|
57 | 7.1 |
| DeepPavlov
|
41 | 8.5 |
| Razdel | 43 | 4.8 |
对于4点错误的平均数量的数据集:SynTagRus,OpenCorpora,GICRYA和RNC。更多详细信息,请参见Razdel存储库。
如果带有规则线条的基线具有相似的质量并且有很多现成的俄语解决方案,为什么我们根本需要Razdel?实际上,Razdel不仅是一个分词器,而且是一个基于规则的小型分段引擎。细分是一项基本任务,在实践中经常会遇到。例如,有一项司法行为,您需要突出显示其中的执行部分并将其分成几段。自然,现成的解决方案无法做到这一点。阅读如何在源代码中编写自己的规则。此外,我们将讨论如何推动自己,并为我们的引擎上的代币和报价提供最佳解决方案。
有什么困难?
在俄语中,句子通常以句号,问号或感叹号结尾。让我们使用正则表达式拆分文本
[.?!]\s+。该解决方案每1000个句子将产生76个错误。错误的类型和示例:
缩写词
...拥有3,000或更多观众的平台都是博客。
...从17世纪末开始,贝伊(Bey)站在那里;
…在以BB.A.命名的室内音乐剧院波克罗夫斯基。
首字母
在歌剧的觉醒“伊多梅纽斯”V.A.▒Motsarta - R.▒Shtrausa......
列出
2.▒dumal将在芬兰领事馆漂亮的长队......
g.▒bilety火车俄罗斯铁路......
这句话笑脸或印刷点的结束
谁提出了消除这些弊端的方法-多亏了:)▒我看上去很体贴……▒现在这更令人不愉快,因为内容将被破坏。
用引号,直接引语,句子的结尾加上引号
-您在城里有新娘吗?”““谁有新娘?”
“好极了,我不喜欢这样!”▒现在,在翻译时,我犯了一个弗洛伊德式的错误:“意识形态”。
Razdel考虑到了这些细微差别,将错误的数量从每1000个句子中的76个减少到43个。
令牌的情况与此类似。一个很好的基本解决方案是regex
[--]+|[0-9]+|[^-0-9 ],它每1000个令牌产生19个错误。例如:
分数,复杂的标点符号
...在1980年代末-1990年代初
...BS-▒3的质量略低(3▒,▒6t)
-她死了▒.▒。猎鹰,你了解这个女孩吗?
Razdel将错误率降低到每1000个令牌7个。
工作原理
该系统基于规则构建。分成代币和要约的原理是相同的。
候选人集
我们在文本中找到句子结尾的所有候选项:句号,省略号,方括号,引号。
6.▒最频繁且同时获得最高评分的答案“我很高兴”▒(13句,25分)▒–受到认可和鼓励的情况。 ,但只有在遇到“我是女人”的回答▒;时才声明“一生就是我一生中等待我的一切”▒和“我迟早要生下孩子”▒.▒编译:V.▒P.▒Golovin ,F.▒V.▒Zanichev,A.▒L.▒Rastorguev,R.▒V.▒Savko,I.▒I.▒Tuchkov。
对于令牌,我们将文本拆分为原子。标记边界未完全通过原子内部。
在1980年-年末-年末-年末-1990年年末-年末
BS--年3 3年,可能会标记一个稍稍较小的质量数((3 3,▒6▒▒)
▒▒— Da▒and▒umerla▒.▒.▒.▒好▒ligirl,f猎鹰▒?▒!
联盟
我们始终绕过候选人进行离职,删除不必要的候选人。我们使用启发式列表。
项目清单。分隔符是句号或括号,左边是数字或字母
6.▒。最常见且同时受到高度赞赏的答案是“我很高兴”(13句,25分),是一种获得认可和鼓励的情况。 7.▒值得注意的是,在答案“我知道” ...的
缩写中。分隔符-点,左边是一个大写字母
...编译器:V.▒P.▒Golovin,F.▒V.▒Zanichev,A.▒L.▒Rastorguev,R.▒V.▒Savko,I.▒I.▒Tuchkov ...
分隔符的右边没有空格
……但答案只有一次“我是女人”▒有这样的说法:“一辈子婚姻就是我一生中等待的一切”和“我迟早要生”。
在结束引号或括号之前没有句号,这不是引号或直接引语
。6最常见和最受赞赏的答案是“我很高兴”«(13句,25分)▒-获得批准和鼓励的情况。 ……“一生是我今生的全部婚姻”和“我迟早要生育”。
结果,剩下两个分隔符,我们认为它们是句子的结尾。
6.回答“我很高兴”(13句话,满分25)是最常见且最受赞赏的选择,那就是得到认可和鼓励的情况7。值得注意的是,在“我知道”的答案中,它被认为是最陈规定型的,但只有在遇到“我是女人”的答案时才被认为是最刻板印象。有这样的说法:“婚姻是我一生中等待的一切”,“我迟早要生育。”由V.P. Golovin,F.V. Zanichev,A.L. Rastorguev,R.V.编写。 Savko,I。I. Tuchkov。
令牌的过程相似,规则不同。
分数或有理数
...(3▒,▒6t)...
复杂的标点符号
-是的,死了。猎鹰,你了解这个女孩吗?
连字符周围没有空格,这不是直接讲话的开始
。1980▒-▒末期-1990年初BS▒-▒3
值得一提...
剩下的全部被认为是令牌的边界。
在1980年代末(x--early▒-1990-x▒BS-3▒)
处,有可能∙轻声地抽调–较低的mass▒(▒3,6▒t▒)▒▒—
是的,死了。 ....
局限性
Razdel规则针对带有正确标点的整洁文本进行了优化。该解决方案适用于新闻文章,文学文本。在社交网络上的帖子,电话交谈的笔录上,质量较低。如果句子之间没有空格或末尾没有句点,或者句子以小写字母开头,则Razdel会出错。阅读
如何在源代码中为您的任务编写规则,该主题尚未在文档中公开。
Slovnet-用于自然俄语处理的深度学习建模

Natasha Slovnet在该项目中为讲俄语的NLP从事现代模型的教学和推理。该库包含用于提取命名实体,解析形态和语法的高质量紧凑模型。在新闻文本上,所有任务的质量都可以与俄语的其他开放式解决方案相比或更高。安装说明,使用示例-在Slovnet存储库中。让我们仔细看看NER问题的解决方案是如何安排的,对于形态和语法,一切都是类推。
在2018年底,在Google发表关于BERT的文章之后,英语NLP取得了很大进步。在2019年,DeepPavlov项目的家伙为俄语改编了多语言BERT,RuBERT出现了。一名CRF负责人在顶部接受了培训,结果发现DeepPavlov BERT NER -SOTA是俄语的。该模型具有出色的质量,比最接近的追求者DeepPavlov NER少2倍的错误,但是其大小和性能令人恐惧:6 GB-消耗GPU RAM ,2 GB-模型大小,每秒13篇文章-良好GPU上的性能。
2020年,在Natasha项目中,我们设法在质量上与DeepPavlov BERT NER接近,模型尺寸缩小了75倍(27MB),内存消耗降低了30倍(205MB),在CPU上的速度提高了2倍(每秒25篇文章) )。
| 娜塔莎(Slovnet NER) | DeepPavlov BERT NER | |
| PER / LOC / ORG F1代币,平均按Collection5,事实RuEval-2016,BSNLP-2019,Gareev | 0.97 / 0.91 / 0.85 | 0.98 / 0.92 / 0.86 |
| 型号尺寸 | 27MB | 2GB |
| 内存消耗 | 205MB | 6GB(GPU) |
| 性能,每秒新闻文章(1文章≈1KB) | 每个CPU 25个(Core i5) | 13个GPU(RTX 2080 Ti),1个CPU |
| 初始化时间,秒 | 1个 | 35 |
| 该库支持 | Python 3.5 +,PyPy3 | Python 3.6+ |
| 依存关系 | NumPy | TensorFlow |
Slovnet NER的质量比SOTA DeepPavlov BERT NER的质量低1个百分点,模型的尺寸小75倍,内存消耗少30倍,速度在CPU上高2倍。在Slovnet存储库中与SpaCy,PullEnti和其他针对俄语NER的解决方案的比较。
您如何得到这个结果?简短的食谱:
Slovnet NER = Slovnet BERT NER -通过合成标记(DeepPavlov BERT NER +蒸馏的类似物Nerus)在WordCNN-CRF与量化的嵌入(Navec)+对NumPy的推理引擎。
现在按顺序。计划如下:在一个小的手动注释数据集上训练具有BERT架构的重型模型。我们用新闻语料对其进行标记,然后得到一个庞大的综合训练数据集。让我们在上面训练一个紧凑的原始模型。这个过程称为蒸馏:重型模型是老师,紧凑模型是学生。我们期望BERT体系结构对于NER问题是多余的,而紧凑型模型在质量上不会给重型模型带来太多损失。
示范老师
DeepPavlov BERT NER由RuBERT编码器和CRF头组成。我们繁重的教师模型在较小的改进下重复了此体系结构。
所有基准均会衡量新闻文本中的NER质量。让我们对RuBERT进行新闻培训。Corus存储库包含指向公共俄语新闻语料库的链接,总共12 GB的文本。我们使用Facebook关于RoBERTa的文章中的技术:大量批处理,动态掩码,拒绝预测下一个句子(NSP)。鲁伯特使用庞大的字典,包含12万个子令牌,这是Google多语言BERT的传承。将大小减少到50,000个最常见的新闻项,覆盖率将减少5%。我们得到新闻,该模型预测新闻中的变相子标记比RuBERT(前1名中的63%)好5个百分点。
让我们的火车NewsRuBERT编码器和CRF头从1000篇Collection5。我们得到的Slovnet BERT NER的质量比DeepPavlov BERT NER的质量高0.5个百分点,模型的大小小4倍(473MB),工作速度快3倍(每秒40篇文章)。
NewsRuBERT = RuBERT + RoBERTa提供的12GB新闻+技术+ 50K词典。
Slovnet BERT NER(DeepPavlov BERT NER的类似产品)= NewsRuBERT + CRF头+ Collection5。
现在,要训练具有类似BERT的架构的模型,习惯上使用Hugging Face中的Transformers。变形金刚是100,000行Python代码。当丢失或垃圾在推理上爆炸时,很难弄清楚出了什么问题。好的,在那里重复了很多代码。即使我们训练RoBERTa,我们也可以将问题迅速地定位到约3000行代码,但这也很多。使用现代PyTorch,Transformers库几乎没有相关性。使用
torch.nn.TransformerEncoderLayer类似RoBERTa的模型代码需要100行:
class BERTEmbedding(nn.Module):
def __init__(self, vocab_size, seq_len, emb_dim, dropout=0.1, norm_eps=1e-12):
super(BERTEmbedding, self).__init__()
self.word = nn.Embedding(vocab_size, emb_dim)
self.position = nn.Embedding(seq_len, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.drop = nn.Dropout(dropout)
def forward(self, input):
batch_size, seq_len = input.shape
position = torch.arange(seq_len).expand_as(input).to(input.device)
emb = self.word(input) + self.position(position)
emb = self.norm(emb)
return self.drop(emb)
def BERTLayer(emb_dim, heads_num, hidden_dim, dropout=0.1, norm_eps=1e-12):
layer = nn.TransformerEncoderLayer(
d_model=emb_dim,
nhead=heads_num,
dim_feedforward=hidden_dim,
dropout=dropout,
activation='gelu'
)
layer.norm1.eps = norm_eps
layer.norm2.eps = norm_eps
return layer
class BERTEncoder(nn.Module):
def __init__(self, layers_num, emb_dim, heads_num, hidden_dim,
dropout=0.1, norm_eps=1e-12):
super(BERTEncoder, self).__init__()
self.layers = nn.ModuleList([
BERTLayer(
emb_dim, heads_num, hidden_dim,
dropout, norm_eps
)
for _ in range(layers_num)
])
def forward(self, input, pad_mask=None):
input = input.transpose(0, 1) # torch expects seq x batch x emb
for layer in self.layers:
input = layer(input, src_key_padding_mask=pad_mask)
return input.transpose(0, 1) # restore
class BERTMLMHead(nn.Module):
def __init__(self, emb_dim, vocab_size, norm_eps=1e-12):
super(BERTMLMHead, self).__init__()
self.linear1 = nn.Linear(emb_dim, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.linear2 = nn.Linear(emb_dim, vocab_size)
def forward(self, input):
x = self.linear1(input)
x = F.gelu(x)
x = self.norm(x)
return self.linear2(x)
class BERTMLM(nn.Module):
def __init__(self, emb, encoder, head):
super(BERTMLM, self).__init__()
self.emb = emb
self.encoder = encoder
self.head = head
def forward(self, input):
x = self.emb(input)
x = self.encoder(x)
return self.head(x)
这不是原型,代码是从Slovnet存储库复制的。变形金刚很好看,他们做了很多工作,用Arxiv填充了文章的代码,通常Python的源代码比科学文章中的解释更清楚。
综合数据集
让我们用一个沉重的模型标记Lenta.ru语料库中的700,000条文章。我们获得了庞大的综合训练数据集。该归档文件位于Natasha项目的Nerus存储库中。标记的质量非常高,F1通过令牌估计:PER-99.7%,LOC-98.6%,ORG-97.2%。罕见的错误示例:
ORG────────────── LOC────────────────────────────
241- 4- 10-
<
LOC─── LOC──────
>.
───────────~~~~~~~~~~~
ORG────────────────────~~~~~~~~~~~~~~~~
.
LOC───
<>
~~~~~~~~ LOC──────────────────
.
~~~~ ~~~~~~ LOC───
.
LOC────
-
PER─────────────────────
M&A.
~~~
:
~~~~~~~~~~~~ORG─── LOC──
,
PER─────── LOC───
,
ORG─ LOC─────────────
.
LOC
模型学习者
选择重型教师模型的体系结构没有问题,只有一种选择-变压器。紧凑型学生模型比较困难,有很多选择。从2013年到2018年,从出现word2vec到有关BERT的文章,人类提出了许多神经网络架构来解决NER问题。都有一个共同的方案:
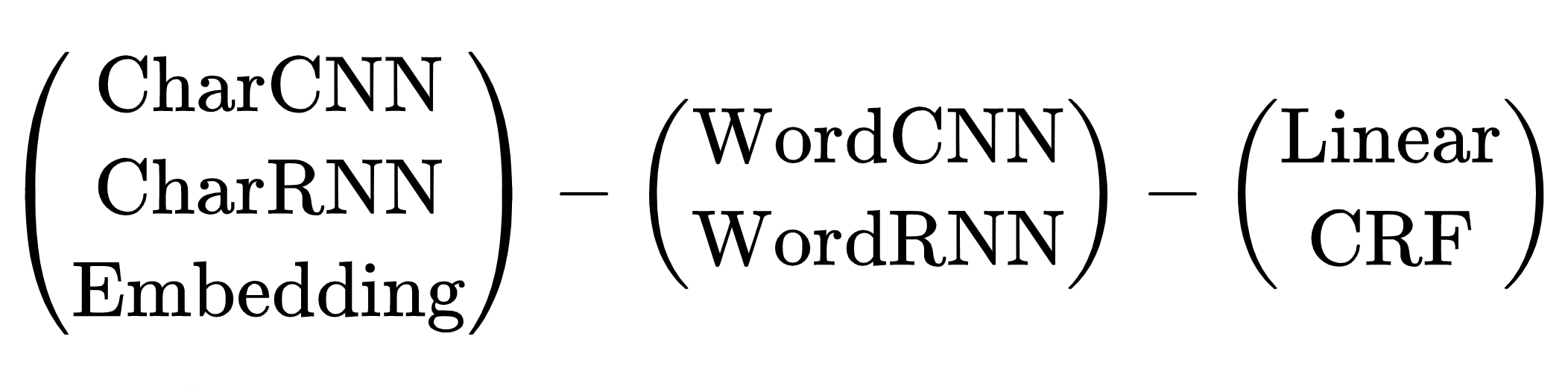
用于NER任务的神经网络体系结构方案:令牌编码器,上下文编码器,标签解码器。评论文章Yang(2018)中的缩写说明。
有许多架构组合。选择哪一个?例如,(CharCNN + Embedding)-WordBiLSTM-CRF是有关DeepPavlov NER的文章的模型图,该文章适用于俄罗斯语言,直到2019年为止。
我们用CharCNN,CharRNN跳过这些选项,通过每个令牌上的符号启动一个小型神经网络不是我们的方式,太慢了。我还想避免使用WordRNN,该解决方案应在CPU上运行,并慢慢将每个令牌上的矩阵相乘。对于NER,线性和CRF之间的选择是有条件的。我们使用BIO编码,标签的顺序很重要。我们必须忍受可怕的刹车,使用CRF。仍然有一个选项-Embedding-WordCNN-CRF。此模型不区分大小写,对于NER来说很重要,“希望”只是一个词,“希望”可能是一个名称。添加ShapeEmbedding-嵌入令牌轮廓,例如:“ NER”-EN_XX,“ Vainovich”-RU_Xx,“!” -PUNCT_!,“和”-RU_x,“ 5.1”-NUM,“纽约”-RU_Xx-Xx Slovnet NER方案-(WordEmbedding + ShapeEmbedding)-WordCNN-CRF。
蒸馏法
让我们在庞大的综合数据集上训练Slovnet NER。让我们将结果与重型教师模型Slovnet BERT NER进行比较。在手动标记的Collection5,Gareev,factRuEval-2016,BSNLP-2019上计算质量并取平均值。训练样本的大小非常重要:对于250篇新闻文章(factRuEval-2016),PER,LOC,LOG F1的平均值为0.64,对于1000(与Collection5类似)的平均值为0.81,对于整个数据集为0.91,Slovnet BERT NER的质量为0.92。
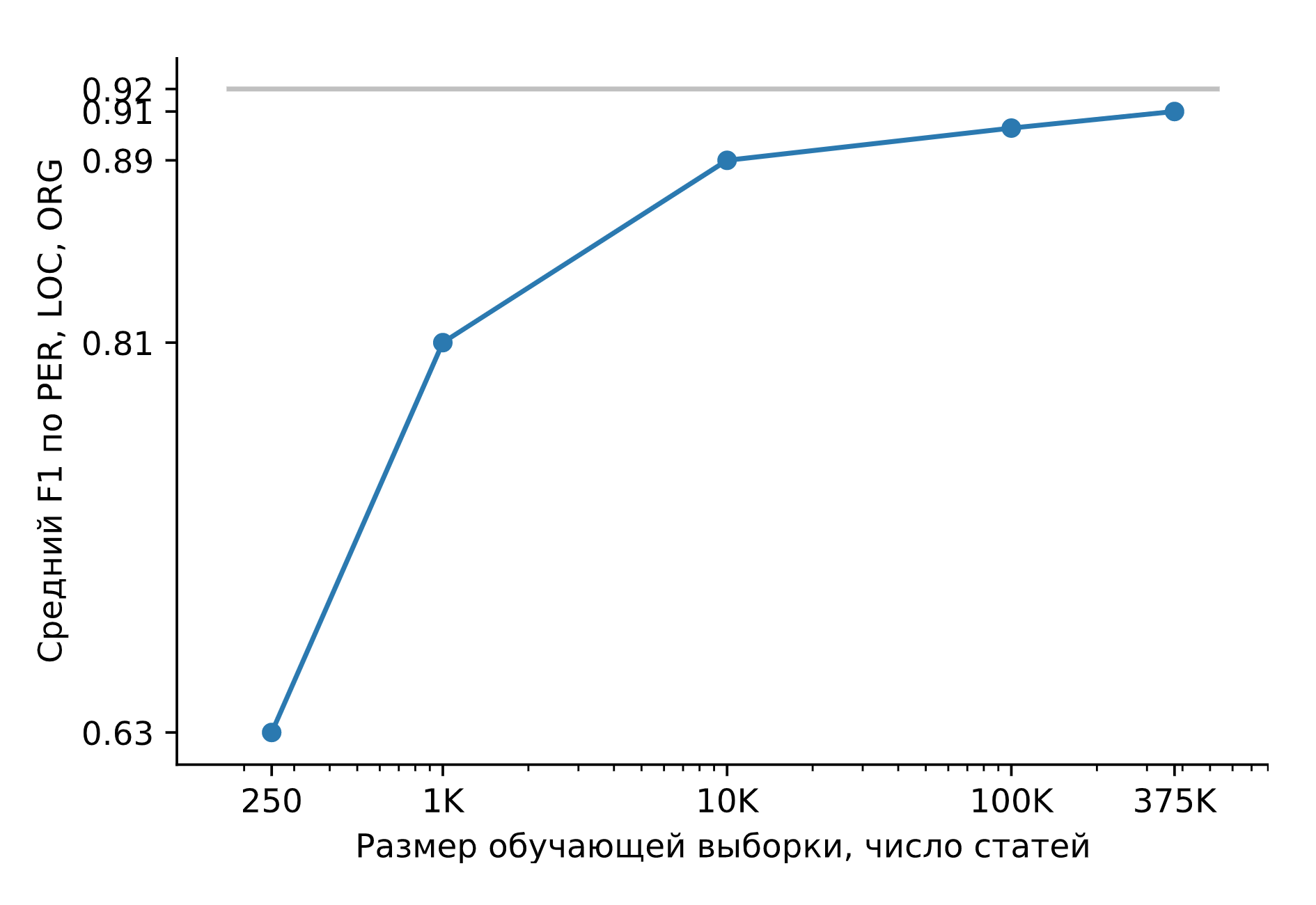
Slovnet NER的质量,取决于合成训练示例的数量。灰线-Slovnet BERT NER质量。 Slovnet NER没有看到手写的示例,它仅对综合数据进行训练。
原始的学生模型比严格的老师模型差1个百分点。这是一个了不起的结果。通用食谱表明:
我们手动标记一些数据。我们训练重型变压器。我们生成了大量综合数据。我们在一个大样本上训练一个简单的模型。我们得到了变压器的质量,简单模型的尺寸和性能。
Slovnet库还根据此配方对两个模型进行了训练:Slovnet Morph-形态标记器,Slovnet Syntax-句法解析器。Slovnet Morph落后重型教师模型2个百分点,Slovnet语法-5个百分点。与现有的俄罗斯新闻报道解决方案相比,这两种模型都具有更好的质量和性能。
量化
Slovnet NER的大小为289MB。287MB被带嵌入表的占用。该模型使用了25万行的大词汇量,覆盖了新闻文本中98%的单词。使用量化,将100维8位浮点向量替换为300维浮点向量。模型的大小将减少10倍(27MB),质量不会改变。Navec库是Natasha项目的一部分,该项目是量化的预训练嵌入的集合。根据综合估计,经过小说训练的权重占用50MB,绕过所有静态RusVectores模型。
推理
Slovnet NER使用PyTorch进行培训。 PyTorch软件包的重量为700MB,我不想将其拖入生产进行推断。 PyTorch也不能与PyPy解释器一起使用。 Slovnet与Yargy解析器(Yandex Tomita解析器的类似物)结合使用。使用PyPy,Yargy的工作速度将提高2到10倍,具体取决于语法的复杂程度。我不想因为依赖PyTorch而失去速度。
标准解决方案是使用TorchScript或将模型转换为ONNX,并在ONNXRuntime中进行推断。 Slovnet NER使用非标准块:量化嵌入,CRF解码器。 TorchScript和ONNXRuntime不支持PyPy。
Slovnet NER是一个简单的模型,手动实现NumPy中的所有块,使用PyTorch计算的权重。让我们应用一些NumPy魔术,仔细实现CNN块,CRF解码器,解压缩量化嵌入需要5行。CPU的推理速度与ONNXRuntime和PyTorch相同,Core i5上每秒25条新闻。
该技术适用于更复杂的模型:Slovnet Morph和Slovnet语法也在NumPy中实现。Slovnet NER,Morph和Syntax共享一个公用的嵌入表。让我们在一个单独的文件中取出权重,该表在内存和磁盘中不重复:
>>> navec = Navec.load('navec_news_v1_1B.tar') # 25MB
>>> morph = Morph.load('slovnet_morph_news_v1.tar') # 2MB
>>> syntax = Syntax.load('slovnet_syntax_news_v1.tar') # 3MB
>>> ner = NER.load('slovnet_ner_news_v1.tar') # 2MB
# 25 + 2 + 3 + 2 25+2 + 25+3 + 25+2
>>> morph.navec(navec)
>>> syntax.navec(navec)
>>> ner.navec(navec)
局限性
Natasha提取标准实体:名称,地名和组织名称。该解决方案在新闻上显示出良好的质量。如何处理其他实体和文本类型?我们需要训练一种新模型。这不容易做到。我们通过模型准备的复杂性来支付紧凑的尺寸和工作速度。脚本的笔记本电脑准备了沉重的老师模型,脚本笔记本电脑学生模型,准备量化的嵌入指令。
Navec-俄语的紧凑型嵌入

紧凑型模型使用起来很方便。它们快速启动,使用很少的内存,并且一个实例可以容纳更多并行进程。
在NLP中,模型权重的80-90%在嵌入表中。Navec库是Natasha项目的一部分,该项目是俄语预训练的嵌入的集合。就内在质量指标而言,它们略低于RusVectores的顶级解决方案,但具有权重的归档文件的大小则小5-6倍(51MB),而字典的大小则是2-3倍(500K字)。
| 质量* | 型号大小,MB | 字典大小,×10 3 | |
| Navec | 0.719 | 50.6 | 500 |
| RusVectores | 0.638-0.726 | 220.6–290.7 | 189-249 |
这是关于在2013年彻底改变NLP的老式逐字嵌入的好成绩。如今,这项技术仍然适用。在Natasha项目中,用于解析形态,语法和提取命名实体的模型在逐词Navec嵌入中工作,并且显示出优于其他开放式解决方案的质量。
RusVectores
对于俄语,习惯上使用来自RusVectores的预训练嵌入,它们具有令人不愉快的功能:表中不包含单词,而是成对的“ word_POS-tag”。这个主意很好,对于“ oven_VERB”对,我们期望一个类似于“ cook_VERB”,“ cook_VERB”的向量,对于“ oven_NOUN”-“ hut_NOUN”,“ furnace_NOUN”。
实际上,使用这种嵌入是不方便的。仅将文本分成令牌是不够的,因为每个令牌都需要以某种方式定义POS标签。嵌入表正在膨胀。代替一个单词“ become”,我们存储6:2个合理的“ become_VERB”,“ become_NOUN”和4个奇怪的“ become_ADV”,“ become_PROPN”,“ become_NUM”,“ become_ADJ”。一个表中有195,000个唯一词,其中包含250,000个条目。
质量
让我们估计语义邻近问题上嵌入的质量。让我们用几个词,每个词我们都会找到一个嵌入向量,我们将计算余弦相似度。Navec对于类似的单词“ cup”和“ jug”将返回0.49,对于“ fruit”和“ oven”则为-0.0047。让我们收集许多具有相似参考标记的对,并根据我们的答案计算Spearman的相关性。
RusVectores的作者使用经过仔细检查和修订的SimLex965对的小型测试列表。让我们从RUSSE项目中添加一个新的Yandex LRWC和数据集:HJ,RT,AE,AE2:
| 6个数据集的平均质量 | 加载时间,秒 | 型号大小,MB | 字典大小,×10 3 | ||
| Navec | hudlit_12B_500K_300d_100q |
0.719 | 1.0 | 50.6 | 500 |
news_1B_250K_300d_100q |
0.653 | 0.5 | 25.4 | 250 | |
| RusVectores | ruscorpora_upos_cbow_300_20_2019 |
0.692 | 3.3 | 220.6 | 189 |
ruwikiruscorpora_upos_skipgram_300_2_2019 |
0.691 | 5.0 | 290.0 | 248 | |
tayga_upos_skipgram_300_2_2019 |
0.726 | 5.2 | 290.7 | 249 | |
tayga_none_fasttextcbow_300_10_2019 |
0.638 | 8.0 | 2741.9 | 192 | |
araneum_none_fasttextcbow_300_5_2018 |
0.664 | 16.4 | 2752.1 | 195 |
其质量
hudlit_12B_500K_300d_100q与RusVectores解决方案相当或更好,字典的大小是2-3倍,模型的大小是5-6倍。您如何获得这种质量和尺寸的?
工作原理
hudlit_12B_500K_300d_100q-手套的嵌入训练小说145GB。让我们将RUSSE项目中的文本存档。让我们使用C语言中GloVe的原始实现,并将其包装在方便的Python接口中。
为什么不使用word2vec? GloVe在大型数据集上进行实验的速度更快。一旦我们计算出搭配矩阵,就可以使用它准备不同尺寸的嵌入物,选择最佳选项。
为什么不使用fastText?在Natasha项目中,我们使用新闻文本。它们中的错别字很少,OOV令牌的问题由一个大字典解决。表格中的250,000行
news_1B_250K_300d_100q覆盖了新闻文章中98%的单词。
字典大小
hudlit_12B_500K_300d_100q-500,000个条目,覆盖小说文本中98%的单词。向量的最佳维数是300。500,000×300的浮点数表占用578MB,带权重的归档文件的大小hudlit_12B_500K_300d_100q小12倍(48MB)。关于量化。
量化
用8位代码替换32位浮点数:[-∞,-0.86)-代码0,[-0.86,-0.79)-代码1,[-0.79,-0.74)-2,…,[0.86, ∞)-255。表格的大小将减少4倍(143MB)。
:
-0.220 -0.071 0.320 -0.279 0.376 0.409 0.340 -0.329 0.400
0.046 0.870 -0.163 0.075 0.198 -0.357 -0.279 0.267 0.239
0.111 0.057 0.746 -0.240 -0.254 0.504 0.202 0.212 0.570
0.529 0.088 0.444 -0.005 -0.003 -0.350 -0.001 0.472 0.635
────── ──────
-0.170 0.677 0.212 0.202 -0.030 0.279 0.229 -0.475 -0.031
────── ──────
:
63 105 215 49 225 230 219 39 228
143 255 78 152 187 34 49 204 198
163 146 253 58 55 240 188 191 246
243 155 234 127 127 35 128 237 249
─── ───
76 251 191 188 118 207 195 18 118
─── ───
数据是粗略的,不同的值-0.005和-0.003替换一个代码127,-0.030和-0.031-118
让我们用代码替换不是一个,而是三个数字。我们使用k-means算法将嵌入表中的所有三元组数字分为256个簇,而不是每个三元组,我们将存储从0到255的代码。该表将减少3倍(48MB)。 Navec使用PQk-means库,将矩阵分成100列,每列分别进行聚类,综合测试的质量将下降1个百分点。在k-NN的产品量化器一文中,有关量化的知识很清楚。
量化嵌入比通常的嵌入慢。使用前,必须解压缩压缩后的载体。我们认真执行程序,应用Numpy魔术在PyTorch中,我们使用torch.gather。在Slovnet NER中,访问嵌入表需要花费总计算时间的0.1%。
一个模块
NavecEmbedding从该Slovnet库集成到Navec车型PyTorch:
>>> import torch
>>> from navec import Navec
>>> from slovnet.model.emb import NavecEmbedding
>>> path = 'hudlit_12B_500K_300d_100q.tar' # 51MB
>>> navec = Navec.load(path) # ~1 sec, ~100MB RAM
>>> words = ['', '<unk>', '<pad>']
>>> ids = [navec.vocab[_] for _ in words]
>>> emb = NavecEmbedding(navec)
>>> input = torch.tensor(ids)
>>> emb(input) # 3 x 300
tensor([[ 4.2000e-01, 3.6666e-01, 1.7728e-01,
[ 1.6954e-01, -4.6063e-01, 5.4519e-01,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00,
...Nerus是一个大型的综合数据集,具有形态,语法和命名实体的标记

在Natasha项目中,形态,语法分析和命名实体提取由3个紧凑模型完成:Slovnet NER,Slovnet Morph和Slovnet Syntax。与采用BERT架构的重型解决方案相比,解决方案的质量要差1-5个百分点,解决方案的尺寸要小50-75倍,CPU的速度要高2倍。在庞大的合成Nerus数据集上训练了模型,该数据集包含700,000条具有CoNLL-U形态,语法和命名实体标记的新闻文章:
# newdoc id = 0
# sent_id = 0_0
# text = - , ...
1 - _ NOUN _ Animacy=Anim|C... 7 nsubj _ Tag=O
2 _ ADP _ _ 4 case _ Tag=O
3 _ ADJ _ Case=Dat|Degre... 4 amod _ Tag=O
4 _ NOUN _ Animacy=Inan|C... 1 nmod _ Tag=O
5 _ PROPN _ Animacy=Anim|C... 1 appos _ Tag=B-PER
6 _ PROPN _ Animacy=Anim|C... 5 flat:name _ Tag=I-PER
7 _ VERB _ Aspect=Perf|Ge... 0 root _ Tag=O
8 , _ PUNCT _ _ 13 punct _ Tag=O
9 _ ADP _ _ 11 case _ Tag=O
10 _ DET _ Case=Loc|Numbe... 11 det _ Tag=O
11 _ NOUN _ Animacy=Inan|C... 13 obl _ Tag=O
12 _ PROPN _ Animacy=Inan|C... 11 nmod _ Tag=B-LOC
13 _ VERB _ Aspect=Perf|Ge... 7 ccomp _ Tag=O
14 _ ADV _ Degree=Pos 15 advmod _ Tag=O
15 _ ADJ _ Case=Nom|Degre... 16 amod _ Tag=O
16 _ NOUN _ Animacy=Inan|C... 13 nsubj _ Tag=O
17 _ ADP _ _ 18 case _ Tag=O
18 _ NOUN _ Animacy=Inan|C... 16 nmod _ Tag=O
19 , _ PUNCT _ _ 20 punct _ Tag=O
20 _ VERB _ Aspect=Imp|Moo... 0 root _ Tag=O
21 _ PROPN _ Animacy=Inan|C... 20 nsubj _ Tag=B-ORG
22 _ PROPN _ Animacy=Inan|C... 21 appos _ Tag=I-ORG
23 . _ PUNCT _ _ 20 punct _ Tag=O
# sent_id = 0_1
# text = , , , ...
1 _ ADP _ _ 2 case _ Tag=O
2 _ NOUN _ Animacy=Inan|C... 9 parataxis _ Tag=O
...Slovnet NER,Morph,语法-基本模型。当训练集中有1000个示例时,Slovnet NER落后于笨重的BERT模拟量11个百分点,而10,000个示例-减少3个点,
则500,000-1个。 NER,Slovnet BERT语法,Slovnet BERT语法。在Tesla V100上处理700,000条新闻文章需要20个小时。我们节省了其他研究人员的时间,将完成的存档置于开放访问中。在SpaCy-Ru中为讲俄语的SpaCy教授Nerus定性模型时,请在官方存储库中准备一个补丁。

合成标记具有高质量:确定形态标记的准确性为98%,句法链接为96%。对于NER,F1通过令牌估算:PER-99%,LOC-98%,ORG-97%。为了评估质量,我们标记了SynTagRus,Collection5和新闻切片GramEval2020,将参考标记与我们的标记进行比较,以在Nerus存储库中获取更多详细信息。由于语法标记中的错误,存在循环和多个词根,因此POS标签有时不对应于语法边缘。使用通用依赖项验证器很有用,请跳过此类示例。
Python套件Nerus整理了一个方便的界面来加载和呈现标记:
>>> from nerus import load_nerus
>>> docs = load_nerus('nerus_lenta.conllu.gz')
>>> doc = next(docs)
>>> doc
NerusDoc(
id='0',
sents=[NerusSent(
id='0_0',
text='- , ...',
tokens=[NerusToken(
id='1',
text='-',
pos='NOUN',
feats={'Animacy': 'Anim',
'Case': 'Nom',
'Gender': 'Masc',
'Number': 'Sing'},
head_id='7',
rel='nsubj',
tag='O'
),
NerusToken(
id='2',
text='',
pos='ADP',
...
>>> doc.ner.print()
- ,
PER───────────── LOC───
, . ,
ORG──────── PER──────
...
>>> sent = doc.sents[0]
>>> sent.morph.print()
- NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
ADP
ADJ|Case=Dat|Degree=Pos|Number=Plur
NOUN|Animacy=Inan|Case=Dat|Gender=Masc|Number=Plur
PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
VERB|Aspect=Perf|Gender=Fem|Mood=Ind|Number=Sing
...
>>> sent.syntax.print()
┌►┌─┌───── - nsubj
│ │ │ ┌──► case
│ │ │ │ ┌► amod
│ │ └►└─└─ nmod
│ └────►┌─ appos
│ └► flat:name
┌─└─────────
│ ┌──────► , punct
│ │ ┌──► case
│ │ │ ┌► det
│ │ ┌►└─└─ obl
│ │ │ └──► nmod
└──►└─└───── ccomp
│ ┌► advmod
│ ┌►└─ amod
└►┌─└─── nsubj:pass
│ ┌► case
└──►└─ nmod
┌► , punct
┌─┌─└─
│ └►┌─ nsubj
│ └► appos
└────► . punct
安装说明,使用的例子,质量评估在Nerus库。
Corus-到公共俄语数据集的链接的集合+下载功能

Corus库是Natasha项目的一部分,该项目是指向公共俄语NLP数据集和带有加载程序功能的Python包的链接的集合。到Corus资料库中的资源,安装说明和使用示例的链接列表。
>>> from corus import load_lenta
# Corus Lenta.ru, :
# wget https://github.com/yutkin/Lenta.Ru-News-Dataset/...
>>> path = 'lenta-ru-news.csv.gz'
>>> records = load_lenta(path) # 2, 750 000
>>> next(records)
LentaRecord(
url='https://lenta.ru/news/2018/12/14/cancer/',
title=' \xa0 ...',
text='- ...',
topic='',
tags=''
)
有用的俄语开放数据集非常隐蔽,几乎没人知道。
示例
新闻文章语料库
我们想在新闻文章上训练语言模型,我们需要大量文本。首先想到的是Taiga数据集(约1GB)的新闻片段。很多人都知道Lenta.ru转储(2GB)。其他来源更难找到。在2019年,Dialogue举办了一场争夺头条新闻的竞赛;组织者准备了一份为期4年的RIA Novosti转储(3.7GB)。 2018年,尤里·巴布罗夫(Yuri Baburov)发布了来自40种俄语新闻资源(7.5GB)的上载内容。ODS的 志愿者分享了为该项目收集的有关新闻议程分析的档案(7GB)。
在Corus注册表中链接到这些数据集标记«新闻»,对所有源具有功能装载机:
load_taiga_*,load_lenta,load_ria,load_buriy_*,load_ods_*。
内尔
我们想教NER俄语,我们需要带注释的文本。首先,我们回顾一下事实RuEval-2016竞赛的数据。标记的缺点是:格式复杂,实体跨度重叠,“ LocOrg”类别模棱两可。并非所有人都知道Persons-1000的继承者Named Entities 5集合。标准格式布局,跨度不相交,美观!其他三个来源只有俄语为NER的最忠实的粉丝才知道。我们将通过邮件给Rinat Gareev写信,并附上他在2013年的文章的链接,作为回应,我们将收到250篇带有标记名称和组织的新闻文章。BSNLP-2019的竞争是在2019年举行关于斯拉夫语言的NER,我们将写信给组织者,我们将获得450多个带有标记的文本。WiNER项目提出了从Wikipedia转储中制作半自动NER标记的想法,可以在Github上获得俄语的大量下载。
链接和功能加载寄存器Corus公司:
load_factru,load_ne5,load_gareev,load_bsnlp,load_wikiner。
链接集
在获得引导加载程序并进入注册表之前,与票据的部分中已累积了指向源的链接。30个集的集合:大雅的新版本,从抓取共同568GB俄文本,评论ÇBanki.ru和Auto.ru。我们邀请您分享您的发现,创建带有链接的故障单。
装载机功能
简单数据集的代码很容易编写。Lenta.ru转储格式正确,实现简单。Taiga包含约1500万个CoNLL-U文件,并打包为zip存档。为了使加载快速进行,不占用大量内存并且不破坏文件系统,您需要感到困惑,请谨慎地对zip文件进行低级实施。
对于35个来源,Corus Python软件包具有加载程序功能。访问Taiga的界面并不比Lenta.ru转储复杂:
>>> from corus import load_taiga_proza_metas, load_taiga_proza
>>> path = 'taiga/proza_ru.zip'
>>> metas = load_taiga_proza_metas(path)
>>> records = load_taiga_proza(path, metas)
>>> next(records)
TaigaRecord(
id='20151231005',
meta=Meta(
id='20151231005',
timestamp=datetime.datetime(2015, 12, 31, 23, 40),
genre=' ',
topic='',
author=Author(
name='',
readers=7973,
texts=92681,
url='http://www.proza.ru/avtor/sadshoot'
),
title=' !',
url='http://www.proza.ru/2015/12/31/1875'
),
text='... ...\n... ..\n...
)
我们邀请用户发出拉取请求,发送其加载程序功能,Corus存储库中的简短说明。
Naeval-俄语NLP系统的定量比较

娜塔莎(Natasha)不是一个科学项目,没有击败SOTA的目标,但是重要的是要检查公共基准的质量,在不损失太多性能的情况下尝试占据较高的位置。就像他们在学院里所做的那样:测量质量,获取数字,从其他文章中获取数位板,并将这些数字与自己的数字进行比较。此方案有两个问题:
- 忘了性能。不要比较模型的大小,工作速度。重点仅在于质量。
- 不要发布代码。在计算质量指标时,通常有100万个细微差别。在其他文章中该怎么算?未知。
Naeval是Natasha项目的一部分,该项目是一组脚本,用于评估用于处理自然俄语的开源工具的质量和速度:
| 任务 | 数据集 | 解决方案 |
| 代币化 | SynTagRus, OpenCorpora, GICRYA, RNC
|
SpaCy, NLTK, MyStem, Moses, SegTok, SpaCy Russian Tokenizer, RuTokenizer, Razdel
|
| SynTagRus, OpenCorpora, GICRYA, RNC
|
SegTok, Moses, NLTK, RuSentTokenizer, Razdel
|
|
| SimLex965, HJ, LRWC, RT, AE, AE2
|
RusVectores, Navec
|
|
| GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga)
|
DeepPavlov Morph, DeepPavlov BERT Morph, RuPosTagger, RNNMorph, Maru, UDPipe, SpaCy, Stanza, Slovnet Morph, Slovnet BERT Morph
|
|
| GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga)
|
DeepPavlov BERT Syntax, UDPipe, SpaCy, Stanza, Slovnet Syntax, Slovnet BERT Syntax
|
|
| NER | factRuEval-2016, Collection5, Gareev, BSNLP-2019, WiNER
|
DeepPavlov NER,DeepPavlov BERT NER,DeepPavlov Slavic BERT NER,PullEnti,SpaCy,Stanza,Texterra,Tomita,MITIE,Slovnet NER,Slovnet BERT NER
|
让我们仔细看一下下面的NER问题。
数据集
俄语NER有5个公开基准:factRuEval-2016,Collection5,Gareev,BSNLP-2019,WiNER。源链接收集在Corus注册表中。所有数据集均由新闻文章,带有名称的子字符串,组织名称和地名组成,并在文本中进行标记。有什么会更容易?
所有源都有不同的标记格式。 Collection5使用防区格式的顽童,Gareev和温纳公用事业-不同的方言生物标记,BSNLP-2019有自己的格式,factRuEval-2016也有自己的不平凡的规范... Naeval将所有源转换为通用格式。标记由范围组成。跨度-三:实体类型,子字符串的开头和结尾。
实体类型。factRuEval-2016和Collection5分别标记了半名称-半组织:“克里姆林宫”,“欧盟”,“苏联”。BSNLP-2019和WiNER突出显示了事件的名称:“俄罗斯冠军”,“英国脱欧”。Naeval会修改并删除一些标签,留下参考标签PER,LOC,ORG:人员姓名,地名和组织名称。
嵌套范围。实际上RuEval-2016,跨度重叠。Naeval简化了标记:
:
, 5 Retail Group,
org_name───────
Org────────────
"", "" "",
org_descr───── org_name─ org_name─── org_name
Org──────────────────────
org_descr─────
Org─────────────────────────────────────
org_descr─────
Org──────────────────────────────────────────────────
, .
:
, 5 Retail Group,
ORG────────────
"", "" "",
ORG────── ORG──────── ORG─────
, .
楷模
Naeval比较了俄罗斯NER问题的12种开放式解决方案。所有工具都通过Web界面包装在Docker容器中:
$ docker run -p 8080:8080 natasha/tomita-algfio
2020-07-02 11:09:19 BIN: 'tomita-linux64', CONFIG: 'algfio'
2020-07-02 11:09:19 Listening http://0.0.0.0:8080
$ curl -X POST http://localhost:8080 --data \
' \
\
'
<document url="" di="5" bi="-1" date="2020-07-02">
<facts>
<Person pos="18" len="16" sn="0" fw="2" lw="3">
<Name_Surname val="" />
<Name_FirstName val="" />
<Name_SurnameIsDictionary val="1" />
</Person>
<Person pos="67" len="14" sn="0" fw="8" lw="9">
<Name_Surname val="" />
<Name_FirstName val="" />
<Name_SurnameIsDictionary val="1" />
</Person>
</facts>
</document>
有些解决方案很难启动和配置,因此很少有人使用它们。PullEnti是一个复杂的基于规则的系统,在2016年RuSval竞赛中获得第一名。该工具作为C#的SDK分发。在Naeval上进行的工作导致了一个单独的项目,该项目带有一组针对PullEnti的包装器:PullentiServer是C#Web服务器,pullenti-client是PullentiServer的Python客户端:
$ docker run -p 8080:8080 pullenti/pullenti-server
2020-07-02 11:42:02 [INFO] Init Pullenti v3.21 ...
2020-07-02 11:42:02 [INFO] Load lang: ru, en
2020-07-02 11:42:03 [INFO] Load analyzer: geo, org, person
2020-07-02 11:42:05 [INFO] Listen prefix: http://*:8080/
>>> from pullenti_client import Client
>>> client = Client('localhost', 8080)
>>> text = ' ' \
... ' ' \
... ' '
>>> result = client(text)
>>> result.graph
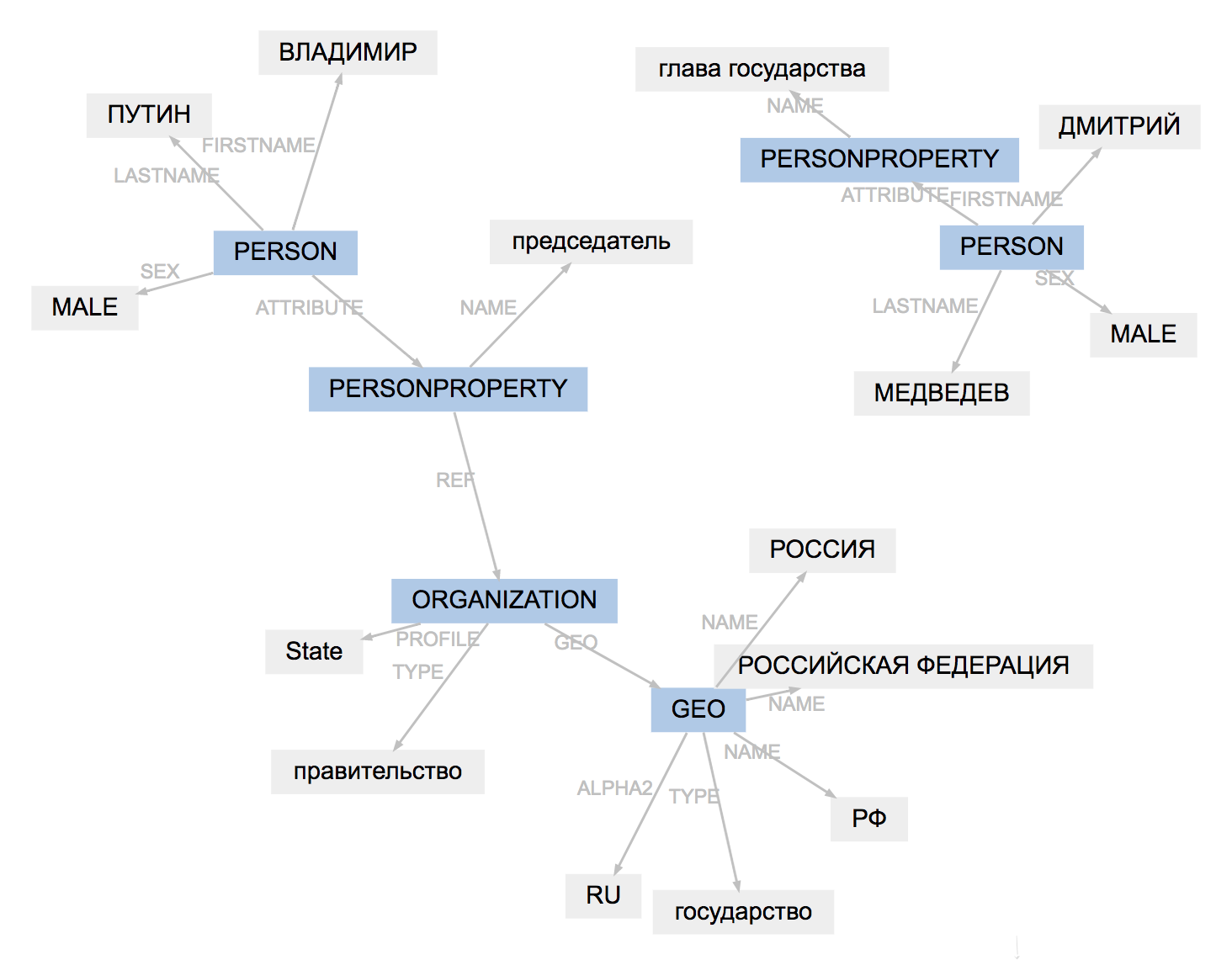
所有工具的标记格式略有不同。原始载荷结果,适应实体类型,简化跨距的结构:
(PullEnti):
, 19
ORGANIZATION──────────
GEO─────────
PERSON────────────────
PERSONPROPERTY───────
──────────────── PERSON───────────────────────
PERSONPROPERTY──────────────
ORGANIZATION───
.
────────────────
:
, 19
ORG────── LOC─────────
PER───────────── ORG────────────
.
PER─────────────
PullEnti的工作成果比事实RuEval-2016标记更难适应。该算法删除PERSONPROPERTY标签,将嵌套的PERSON,ORGANIZATION和GEO拆分为不重叠的PER,LOC,ORG。
比较方式
对于每对“模型,数据集”,Naeval均按令牌计算F1度量,并发布具有质量得分的表格。
Natasha不是一个科学项目,该解决方案的实用性对我们很重要。 Naeval测量开始时间,运行速度,模型大小和RAM消耗。具有结果的表在存储库中。
我们准备了数据集,将20个系统包装在Docker容器中,并为俄语NLP的其他5个任务计算了指标,将结果存储在Naeval存储库中:标记化,分段为句子,嵌入,形态和语法分析。
Yargy- —

Yargy解析器是Python的Yandex Tomita解析器的类似物。安装说明,例如使用的,文件中Yargy库。使用上下文无关的语法和词典描述提取实体的规则。两年前,我在Habr上写了一篇关于Yargy和Natasha库的文章,谈论解决俄语的NER问题。该项目受到好评。 Yargy-parser在Sberbank,Interfax和RIA Novosti的大型项目中取代了Tomita。已经出现了许多教育资料。来自Yandex的一个研讨会的大型视频,一个半小时左右,内容涉及开发语法的过程和示例:
文档已更新,我整理了介绍部分和参考书。最重要的是,《食谱》已经出现-包含一些实用做法的部分。它包含来自t.me/natural_language_processing的最常见问题的答案:
Yargy解析器是一个复杂的工具。该食谱描述了使用大量规则时出现的非显而易见的要点:
在Yargy实验室中,我们有几个大型服务正在运行。我重新阅读了代码,并在菜谱中收集了未公开描述的模式:
阅读文档之后,使用示例查看存储库会很有帮助:
Natasha项目还具有一个natasha-usage存储库。这是在Github上发布的Yargy解析器用户的代码所在的地方。80%的链接是教育项目,但也有提供参考的示例:
当然,使用Yargy解析器最有趣的情况并未在Github上公开发布。如果公司使用Yargy,请写信给PM,如果您不介意,请将徽标添加到natasha.github.io。
Ipymarkup-可视化命名实体标记和语法关系

Ipymarkup是一个原始库,用于在NER可视化中突出显示文本中的子字符串。安装说明,在Ipymarkup存储库中的使用示例。该库类似于displaCy和displaCy ENT,对于调试Yargy解析器的语法非常有用。
>>> from yargy import Parser
>>> from ipymarkup import show_span_box_markup as show_markup
>>> parser = Parser(...)
>>> text = '...'
>>> matches = parser.findall(text)
>>> spans = [_.span for _ in matches]
>>> show_markup(text, spans)

Natasha项目对解析问题有解决方案。不仅需要突出显示文本中的单词,还需要在它们之间绘制箭头。有很多现成的解决方案,甚至有关于该主题的科学文章。
当然,没有现有的解决方案出现,有一天我感到非常困惑,应用了CSS和HTML的所有著名魔术,为Ipymarkup添加了新的可视化。在扩展坞中使用的说明。
>>> from ipymarkup import show_dep_markup
>>> words = ['', '', '', '', '', '', '-', '', '', '', '', '', '', '', '.']
>>> deps = [(2, 0, 'case'), (2, 1, 'amod'), (10, 2, 'obl'), (2, 3, 'nmod'), (10, 4, 'obj'), (7, 5, 'compound'), (5, 6, 'punct'), (4, 7, 'nmod'), (9, 8, 'case'), (4, 9, 'nmod'), (13, 11, 'case'), (13, 12, 'nummod'), (10, 13, 'nsubj'), (10, 14, 'punct')]
>>> show_dep_markup(words, deps)
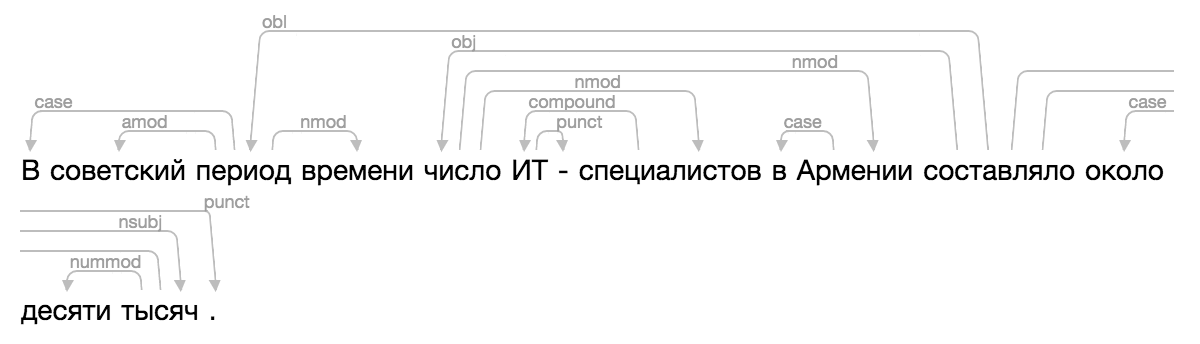
现在,在Natasha和Nerus中,可以方便地查看解析结果。
