数据科学家找出人们感兴趣的东西以及他们将钱花在什么上面
在研究各种受众的过程中,数据科学家观察到自然和令人惊讶的事实,这些事实生动地描绘了我们周围的社会。在本文中,我将讨论在执行与审计分析相关的任务,研究Internet用户的利益以及购买各种社会群体的行为时发现的那些好奇和不寻常的情况。
通过使用机器学习模型已经确定了哪些社会学特征?我们对客户有什么了解?

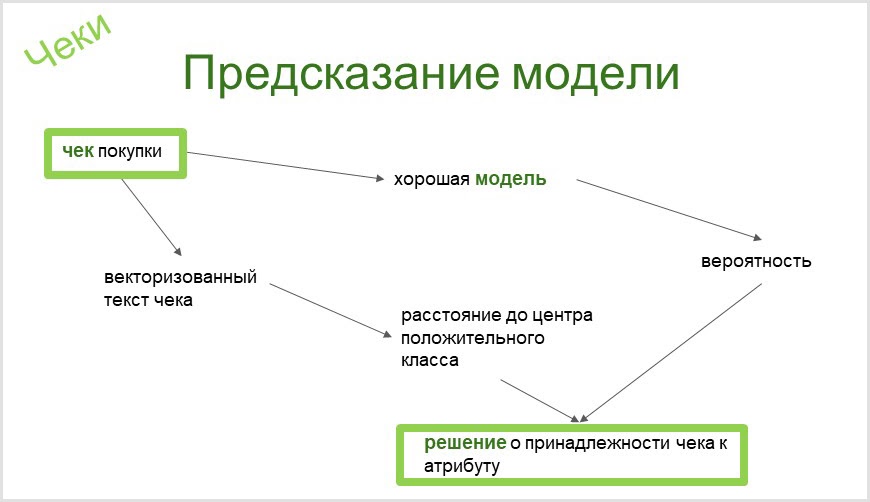
支票上的客户资料?简单!
我在CleverDATA担任数据分析师,通常要完成以下任务:当客户有自己的听众并且他想找到一个相似的模型时,原始数据分类,审计分析和构建外观相似模型(LaL)。对各种在线广告活动的需求很大。
我们拥有1DMC数据交换,会员可以在其中丰富和利用其数据。它包含两种非个人化数据,这些数据已汇总到我们分类法的属性中-在线购买和点击流,即我们能够跟踪的页面访问顺序。数据格式符合用于个人数据保护的欧洲GDPR标准。
我们分类法的属性是事物的所有权或对人的某种兴趣的存在。这是二进制信息-是否存在。
以下是我们的分类属性的一些示例:

最重要的任务之一是将原始供应商数据聚合到分类属性中,即分类任务。
我需要得出有关人们购买的商品的结论,例如人们的生活方式和某些事物的存在(有条件地检查品牌Rod Rod车型可能表明购买者是Harley-Davidson摩托车的所有者),或者确定对购买汽车的潜在兴趣通过他们访问的Internet页面。然后,此信息将用于定向广告。

在我的工作过程中,出现以下链条:
- 检查-我的AI模型-买家资料;
- 点击流-我的AI模型-网站访问者个人资料。
我们在CleverDATA中使用的工具将自动为分类中的任何属性构建一个二进制分类器。根据分类属性的名称(斩波器摩托车属性的所有者),我们最终得到了一个已经自动评估的二进制分类器(无论模型是好的还是需要改进的分析方法),该分类器能够通过检查确定一个人中是否存在此类项目。您可以在我们有关Habré的文章中阅读有关此内容的更多信息。

在对支票进行分类时,您需要一个工具,该工具可让您将单词相似和含义相似的支票分开。因此,我以某种方式建立了一个模型来吸引对专业再培训课程的兴趣。她还发现购买Paolo Cossi的儿童读物“普通猫的魔术课”的支票是该主题的兴趣所在。当然,这是一个有趣的错误。顺便说一下,我从这张支票中学到了这本书的存在。

为了避免这种好奇心,我们使用语言模型来评估生成的二进制分类器,并切断那些单词相似但含义不相似的示例。
我不得不不时地翻阅收据,以便找到一些错误的匹配项,并随后自动搜索这种错误建立的连接。深入浅出可能会有所帮助,因为也许一个难以理解的案例将使我改善整个过程。
在我的整个实践过程中,我积累了整套的谜题检查,不仅可以分类,甚至可以破译买家购买的商品。我定期与同事分享这些有趣的案例,甚至开始“ AI笑话”专栏。
最常见的线索是书名中没有产品名称的指示。这正是我们在“普通猫的魔法”中看到的。而购买的商品则记录在“栅栏新西伯利亚1029卢布”支票中。和“合同箱5000卢布。”我还是不明白。我在本文的评论中接受您的版本。
接下来,让我们继续进行点击流分类。
客户在网站上的动作简介
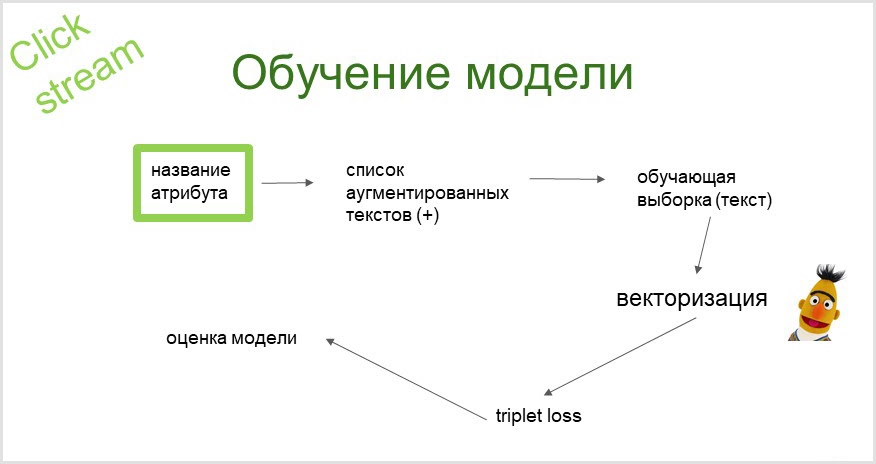
点击流分类系统是我们在2019年推出的,在NLP(自然语言处理)领域取得了许多突破。该领域中最引人注目的和成功的发明之一是BERT(来自变压器的双向编码器表示)网络。因此,未来还会有一些Bertology。

通过使用概率语言模型从属性的名称中,我们获得了经过爬网(发送至搜索引擎并收集搜索结果)的查询的扩充列表(带有同义词),从而获得了训练样本。让我们使用预训练的BERT语言模型对其进行矢量化。使用获得的嵌入(向量),我们训练分类器(具有三重态损失函数)。
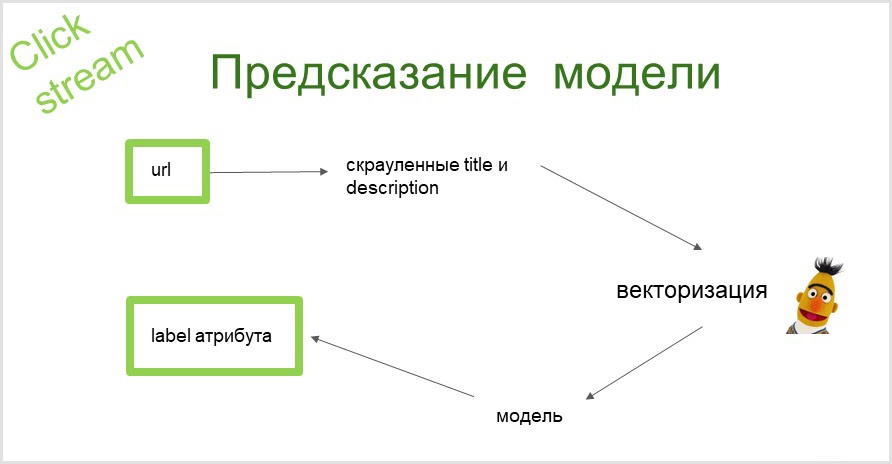
预测如何运作?
我们获取页面的url,收集文本信息(页面的标题和描述)。借助BERT,我们获得了这些文本的矢量表示。然后将这些向量输入模型,并在输出处获得一个属性,我们可以参考该页面。
总的来说,这个系统非常成功,我遇到的所有有趣的案例都是例外而不是规则。但是我尝试特别注意它们,因为一个小错误会导致大的不愉快后果,因为大量数据会通过系统。
我研究的在线数据表明人们在Internet上阅读更多。原来,这是非常受欢迎的主题之一-占星术,算命等。

每天有超过500万人(唯一标识符)访问这些特定页面(URL,而不是域)。专门研究猫占星术并揭示出动物的性格与其生肖之间的联系的我尤其感到震惊。

每个人都知道停用词,通常它们会连接字典或按频率过滤,而不会深入探讨文本的细节。首先,我还连接了字典。结果令人不快:不使用烘焙食品的食谱位置被归类为烘焙(家庭烘焙)的关注属性。这是由于所有否定词都存在于我的停用词词典中。

以我的示例为例,我敦促我的同事仔细阅读用于过滤数据的字典。
另一个常见的问题是人们经常使用讽刺性语言,在爬行阶段,这会导致在标题和与Internet上某些查询相关的页面描述中出现有趣的短语。例如,该模型可以将馅饼和对素食的兴趣联系起来。在我看来,这可以通过本着“你如何活在没有馅饼的情况下”的精神对有关素食主义的文章进行大量评论来解释。

现在,在我们题为“ AI笑话”的标题中,出现了一分钟的黑色幽默:该模型将对安乐死合法化的讨论与购买房屋的兴趣联系在一起,而饶舌歌手提马蒂(Timati)与马戏团联系在一起。我不得不抓取数据并手动重新标记该类。
有些设置是我们无法控制的,它们取决于我们生活的社会。犯罪再加上喜剧和家庭关系。

在有些争议的情况下,您甚至都不知道是否值得责骂模型,重新设计某些东西,为错误而苦苦挣扎还是保留一切。
收到包裹可能会带来业务风险。
在公告板上可以找到任何内容。

搜索相似的受众
作为分析师,我要解决的下一个任务是Audience研究/相似建模。通常,客户希望获得有关受众的一些新知识,这应该有助于他与她建立联系。但是,即使对他的要求没有明确表述,我们也始终会尽力帮助他,并且在大多数情况下,我们会成功。
在这里,您可以选择是专注于受众研究,即专注于内部洞察(对受众的智能分析),还是专注于相似的模型,这将使您能够加快交流的受众并根据有关目标受众的客户内部数据查找潜在客户。受众被理解为一组编码的标识符(电话号码,电子邮件地址或在线ID)。我提醒您,我们不会以开放形式使用数据,我们遵守所有法律规则。
因此,我们可以与交易所交叉使用一组编码的标识符,并查看购买行为或其点击流。我们针对任何目标受众和任何任务进行聚类。在该模型根据人们的购买行为对他们进行分组之后,我以某种方式看到了一个仅由从事体育运动而不再在线购买任何产品的人们组成的集群。但是,出于簿记目的,它们可能具有某种单独的帐户。
这是该群集的屏幕截图。

案例“幸福的母亲”
对于一个知名尿布品牌的广告活动,有必要进行受众调查并在怀孕的三个月之内找到女性-客户建议必须从孕晚期开始对该产品做广告,以便大多数受众购买。
在分析开始时,对孕妇生活状况的描述就像一幅田园诗般的图画:一个年轻的养宠物的家庭,在孩子出生前夕装备住房。

来自不同地区的女性拥有不同品牌的小玩意,更喜欢不同品牌的卫生用品,总的来说一切都很好。你自己看。
拥有25.5%ID
的Huggies Elite Soft买家购买帮宝适的可能性要低三倍,而购买Lovular产品的可能性要低7倍。他们使用Peligrin产品。女孩的父母很有可能(0.6)。他们倾向于通过互联网为公用事业付费。
25.5%的标识符
倾向于通过Internet支付通信和保险服务费用。养狗的人极有可能(0.6)。购买Helen Harper产品。在消费电子产品中,表达了小米品牌。
标识符的17.5%
Ozon Premium用户。他们购买了Philips Avent婴儿护理设备,并对熨烫设备和装置感兴趣。
注意,对未来的建议:当心促销活动/品牌,这些都会在数据总量中产生噪音。
事实证明,在我们许多集群中,Ozon Premium的地位都是决定性因素之一。但是,仅针对Ozon Premium定位潜在尿布购买者的受众是常识。因此,我不得不从所有数据中删除状态。是的,因此我降低了指标,但同时增加了模型的适用性。首先是新生儿产品,而不是被提升的受欢迎程度。这是一次经验,使我学会了切断对模型来说太重要的商品。
对于相似的建模,为了突出目标受众,在表面上构建了几个简单的目标受众分类(类别1)和广义分类(类别0)的想法。
例如,让我们以目标受众群体的购买量和随机配置文件数量的十倍进行购买。我们将这些信息按顺序带入购买。然后,我们对结果文本进行处理(预处理):我们删除所有高频的,不具信息性的词,并将其余词恢复为初始形式。接下来,我们建立几个不同系列的简单分类器-线性(线性SVC,逻辑回归),“木质”(RandomForest)等-并测量特征重要性,即根据模型对任何单词的重要性。我发现阈值,在这些阈值之上这些标志的重要性不足,也就是说,标志太吵。在自动构建东西之前,您必须多次运用常识和仔细浏览的方法来收集内部统计数据,并了解哪些方法有效,哪些无效。
我们在孩子出生前夕用田园诗般的照片检查了簇,但也追溯了其他生活故事。例如,在其中一个集群中,新生儿尿布的潜在购买者极有可能(0.65)在交友网站上拥有一个帐户。这不是毫无根据的声明,他们为此类网站上的服务付费。
为了使见解“工作”,您总是必须解释新知识,但是这次我根本不想寻找内在故事-每个人都知道我们国家的社会不适和日常生活的混乱。

让我提醒您,在本案例中,我们调查了所有对购买新生儿尿布感兴趣的受众。结果表明,不仅妊娠中期的女性。
我将一个单独的集群称为“星期日爸爸”-它的代表是足球迷,狂热的汽车爱好者,购买Sparco汽车的零部件以及不时购买Chupa Chups产品。
现在要注意的问题是:如果“星期日爸爸”与最初指定的目标受众无关,是否值得删除?我经常问这个问题给我的项目经理,任务被重新考虑了。也许我们并不是真的需要特定的目标受众,但是可以成为产品购买者的每个人。在我们的例子中,这些是劳动中的妇女的父亲,祖父母,兄弟姐妹和女友,准备照顾婴儿。应将业务代表视为目标受众的答案。
案例“个人企业家”

我将向您介绍的下一个案例是针对目标受众“个人企业家”的受众研究,他们已经在一家知名银行开设了一个活期账户。
这些人与交易对象之间的主要区别可以从他们的购买中清楚看出。最明显的是非住宅场所的特许权使用费(个人资料的10-15%),安全服务和水电费的支付。在指向企业家的间接标志中,有一个是在飞行过程中购买了额外的行李(在案例中占15-20%)。在全部检查中,很大一部分由有关心理学,自我知识和自我发展的书籍,与下属进行沟通的讲习班和指导文学的书籍组成。
借助LaL功能的重要性,我们获得了目标受众的间接信号:航空运输,购买机器人吸尘器,咖啡机,Honor智能手机,鲜花递送,保险费支付。这是机器为我们提供易于解释的结果的绝佳案例之一。
忙碌的人们购买家用机器人。没有咖啡机,任何办公室都无法做。鲜花递送和频繁飞行也可以链接=)。
案例“车主”
一个“高于平均水平”价格的知名汽车品牌绝对相信其客户是完全杰出的人,并想知道他们的习惯和喜好。
该目标受众与先前的案例(“个体企业家”)有很大的重叠。但是,并非所有个人企业家都购买这种品牌的汽车。

事实证明,客户对客户唯一性的想法被大大夸大了。是的,听众并不与普通大众相吻合,而是仅在某些细节上,例如,驾驶者更喜欢购买名贵茶(价格高出300卢布),并且通常在美观和美感上花费更多,而不是在功能和实用上花费更多。
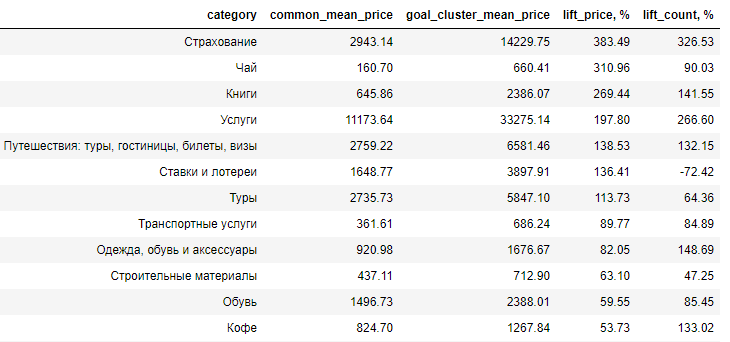
此处显示的是目标受众与购买者的平均受众之间在提升方面的差异,即,所研究受众中产品的平均价格超出平均受众价值(lift_price)相同值的百分比。如您所见,主要费用用于娱乐。
我们始终公平公正地检验假设。可以预见的是,有时客户的关于其受众独占性的假设不受所获得数据的支持。无需担心,它只需要一个新的假设和新的研究。

总之,我想说的是,在我的工作中,我遵循“例程镇定”的原则。我建议你。
拥有如此众多的数据,当务之急是要非常谨慎并注意小事情,因为乍一看,任何异常都可能后来成为规则,并且我们可能会得到许多错误的结果。
因此,如果我没有看到“不烘烤”模型所指的“烘烤”,那么“漏水”系统将投入生产。因此,不要忽略常规:如果您花半个小时检查一下眼睛,就可以睡个好觉-模型不会出错。
