
云计算正在越来越深入地渗透到我们的生活中,可能没有一个人至少一次没有使用过任何云服务。但是,什么是云以及云在大多数情况下是如何工作的,即使在一个想法的层面上,很少有人知道。5G已经成为现实,电信基础架构正开始从支柱解决方案过渡到云解决方案,就像它从全铁解决方案过渡到虚拟化“支柱”一样。
今天,我们将讨论云基础架构的内部世界,特别是,我们将分析网络部分的基础知识。
什么是云?相同的虚拟化-配置文件视图?
不仅仅是一个逻辑问题。不-这不是虚拟化,尽管并非没有。考虑两个定义:
云计算(以下称为云)是一种模型,用于提供对分布式计算资源的用户友好访问,必须按需部署和启动分布式计算资源,并以尽可能低的延迟和来自服务提供商的最低成本(来自NIST的定义的翻译)。
虚拟化-这是一种将一个物理实体(例如,一台服务器)划分为多个虚拟实体的能力,从而提高了资源利用率(例如,您有3台服务器以25%到30%的速度加载,在虚拟化后您有1台服务器以80%到90%的速度加载)。自然地,虚拟化会消耗一些资源-您需要提供虚拟机监控程序,但是,正如实践证明的那样,游戏值得一试。虚拟化的理想示例是VMWare,它可以完美地准备虚拟机,或者例如,我更喜欢KVM,但这已经成为一个问题。
我们自己使用虚拟化技术却没有意识到这一点,甚至铁路由器也已经在使用虚拟化技术,例如,在最新版本的JunOS中,操作系统是作为虚拟机安装在实时linux分发工具包(Wind River 9)之上的。但是虚拟化不是云,但是没有虚拟化就不可能存在云。
虚拟化是构建云的基础之一。
仅将几个虚拟机管理程序收集到一个L2域中,添加几个Yaml剧本以通过一些ansans自动注册vlan,并用诸如自动创建虚拟机的编排系统之类的东西填充它,将无法创建云。更确切地说,它将证明,但是由此产生的科学怪人并不是我们需要的云,尽管作为其他人,也许对于某人而言,这是终极梦想。另外,如果您使用相同的Openstack-实际上,它仍然是科学怪人,但是,哦,让我们现在不谈论它。
但是我了解到,根据以上定义,尚不清楚什么可以真正称为云。
因此,NIST(美国国家标准技术研究院)的文档列出了云基础架构应具有的5个主要特征:
根据要求提供服务。应该给用户自由访问分配给他的计算机资源(例如网络,虚拟磁盘,内存,处理器核心等)的权利,并且应该自动提供这些资源-也就是说,无需服务提供商的干预。
广泛的服务可用性。应该通过标准机制提供对资源的访问,以便能够同时使用标准PC和瘦客户机以及移动设备。
资源池。资源池应该能够同时向多个客户端提供资源,从而确保客户端隔离并且不存在相互影响和争用资源的情况。网络也包含在池中,这表明使用重叠寻址的可能性。池必须按需扩展。池的使用允许提供必要级别的资源弹性以及对物理和虚拟资源的抽象-向服务的接收者简单地提供他请求的资源集(这些资源实际位于何处,在多少服务器和交换机上-客户端不在乎)。但是,必须考虑到提供者必须确保透明保留这些资源的事实。
快速适应各种条件。服务应具有灵活性-根据客户端的请求快速提供资源,对其进行重新分配,增加或减少资源,并且客户端应感到云资源无穷无尽。例如,为了便于理解,由于服务器上的硬盘驱动器已损坏且磁盘已损坏,因此您不会看到警告,警告您丢失了Apple iCloud中的一部分磁盘空间。另外,从您的角度来看,这项服务的可能性几乎是无限的-您需要2 TB-没问题,您已经付款并收到了。同样,您可以使用Google.Drive或Yandex.Disk给出示例。
衡量所提供服务的能力。云系统应自动控制和优化消耗的资源,而这些机制对用户和服务提供商均应透明。也就是说,您始终可以检查您和您的客户正在消耗多少资源。
值得考虑的事实是,这些要求主要是对公共云的要求,因此,对于私有云(即,为公司内部需求而启动的云),可以稍微调整这些要求。但是,它们仍然必须执行,否则我们将无法获得云计算的所有优势。
我们为什么需要云?
但是,任何新的或现有的技术,任何新的协议都是为某种东西创建的(当然,除了RIP-ng)。为了达成协议而使用协议-没人需要它(当然,除了RIP-ng)。创建云以向用户/客户端提供某种服务是合乎逻辑的。我们都至少熟悉两个云服务,例如Dropbox或Google.Docs,并且我相信其中大多数都可以成功使用它们-例如,本文是使用Google.Docs云服务编写的。但是,我们知道的云服务只是云功能的一部分-更准确地说,它仅仅是SaaS类型的服务。我们可以通过三种方式提供云服务:SaaS,PaaS或IaaS形式。您需要什么服务取决于您的需求和能力。
让我们按顺序考虑每个:
软件即服务(SaaS)是一种用于向客户端提供完整服务的模型,例如,诸如Yandex.Mail或Gmail的邮件服务。在这样的服务交付模型中,作为客户,您实际上除了使用服务之外什么也不做-也就是说,您无需考虑设置服务,其容错或保留。最主要的是不要破坏您的密码,此服务的提供者将为您完成其余工作。从服务提供商的角度来看,他完全负责整个服务-从服务器硬件和主机操作系统到数据库和软件设置。
平台即服务(PaaS)-使用此模型时,服务提供者会为客户端提供该服务的模板,例如,让我们使用Web服务器。服务提供商为客户端提供了一个虚拟服务器(实际上是一组资源,例如RAM / CPU /存储/网络等),甚至在该服务器上安装了操作系统和必要的软件,但是客户端自己已经配置了所有这些东西,并且已经为服务的性能做好了准备客户回答。与之前的情况一样,服务提供商负责物理设备,虚拟机管理程序,虚拟机本身,其网络可用性等的可操作性,但是服务本身已经不在其职责范围之内。
基础架构即服务(IaaS)-这种方法已经变得更加有趣,事实上,服务提供商向客户端提供了完整的虚拟化基础架构-即一些资源(池),例如CPU核心,RAM,网络等。所有其他一切取决于客户端-客户端要如何处理这些分配的池(配额)内的资源-供应商不是特别重要。客户希望创建自己的vEPC,甚至希望成为一个迷你运营商并提供通信服务-毫无疑问-做到这一点。在这种情况下,服务提供商负责提供资源,其容错性和可用性,以及允许您将这些资源合并到池中并向客户端提供它们的能力的操作系统,该功能可以根据客户端的要求随时增加或减少资源。客户端通过自助服务门户和控制台自行配置所有虚拟机和其他金属丝,包括网络注册(外部网络除外)。
什么是OpenStack?
在所有三个选项中,服务提供商都需要一个可启用云基础架构的操作系统。实际上,在SaaS中,没有哪个部门负责该技术堆栈的整个堆栈-有一个部门负责基础架构-也就是说,它向另一个部门提供IaaS,该部门提供SaaS客户端。OpenStack是一种云操作系统,可让您将一堆交换机,服务器和存储系统收集到一个资源池中,将该公共池划分为子池(租户),然后通过网络将这些资源提供给客户端。
开栈是一种云操作系统,允许您控制大量计算资源,数据存储和网络资源,其供应和管理是通过使用标准身份验证机制的API进行的。
换句话说,这是一组旨在创建云服务(公共和私有)的自由软件项目,即一组工具,使您可以将服务器和交换设备组合到单个资源池中,管理这些资源,提供必要的容错级别...
在撰写本文时,OpenStack结构如下所示:

图片来自openstack.org
组成OpenStack的每个组件都执行特定的功能。这种分布式体系结构使您可以在解决方案中包含所需的功能组件集。但是,某些组件是根组件,将其删除会导致整个解决方案完全或部分无法使用。通常会引用以下组件:
- 仪表板-用于管理OpenStack服务的基于Web的GUI
- Keystone是一种集中式身份服务,可为其他服务提供身份验证和授权功能,并管理用户凭据和角色。
- Neutron — , OpenStack ( VM )
- Cinder —
- Nova —
- Glance —
- Swift —
- Ceilometer — ,
- Heat —
有关所有项目及其目的的完整列表,请参见此处。
每个OpenStack组件都是一项服务,负责特定功能,并提供API来管理该功能并将该服务与其他云操作系统服务进行通信以创建统一的基础架构。例如,Nova提供计算资源管理和API来访问这些资源的配置,Glance提供图像管理和API来管理它们,Cinder提供块存储和API来管理它们,等等。所有功能都以非常紧密的方式相互连接。
但是,如果您判断,那么OpenStack中运行的所有服务最终都是连接到网络的某种虚拟机(或容器)。问题来了-为什么我们需要这么多元素?
让我们研究一下创建虚拟机并将其连接到网络以及Openstack中的持久性存储的算法。
- 当您创建创建机器的请求时,无论是通过Horizon(仪表板)发出的请求,还是通过CLI发出的请求,首先发生的是您对Keystone的请求授权-您是否可以创建机器,拥有或有权使用此网络,是否足够配额草案等
- Keystone对您的请求进行身份验证,并在响应消息中生成一个auth令牌,该令牌将在以后使用。收到Keystone的回复后,该请求将发送给Nova(nova api)。
- Nova-api , Keystone, auth-
- Keystone auth- .
- Nova-api nova-database VM nova-scheduler.
- Nova-scheduler ( ), VM , . VM nova-database.
- nova-scheduler nova-compute . Nova-compute nova-conductor (nova-conductor nova, nova-database nova-compute, nova-database ).
- Nova-conductor nova-database nova-compute.
- nova-compute glance ID . Glace Keystone .
- Nova-compute neutron . glance, neutron Keystone, database ( ), nova-compute.
- Nova-compute cinder volume. glance, cider Keystone, volume .
- Nova-compute libvirt .
实际上,创建简单虚拟机的看似简单的操作变成了云平台元素之间的api调用漩涡。而且,如您所见,即使先前指定的服务也由较小的组件组成,它们之间会发生交互。创建机器只是云平台为您提供的一小部分-有负责平衡流量的服务,负责块存储的服务,负责DNS的服务,负责供应裸机服务器的服务等。云允许您将虚拟机视为一群羊(而不是虚拟化)。如果您的计算机在虚拟环境中发生了某些事情-您从备份等还原了它,则可以通过这种方式构建云应用程序,这样虚拟机就不会扮演重要角色-虚拟机“死了”-没关系-只是根据模板创建了一个新机,正如他们所说,班组没有注意到士兵的损失。自然,这提供了编排机制的存在-使用Heat模板,您可以轻松部署由数十个网络和虚拟机组成的复杂功能,而不会出现任何问题。
始终需要牢记的是,没有网络就没有云基础架构-每个元素以一种或另一种方式通过网络与其他元素交互。此外,云具有完全非静态的网络。自然地,底层网络或多或少是静态的-每天不会添加新的节点和交换机,但是,覆盖组件可以而且将不可避免地不断变化-将添加或删除新的网络,出现新的虚拟机,而旧的虚拟机将消失。正如您从本文开头给出的云的定义所记起的那样,应该自动地将资源分配给用户,并且资源的分配应最少(或更好),而无需服务提供商的干预。也就是说,网络资源的提供类型,现在以前端的形式出现,您可以通过http / https访问个人帐户的形式,而值班的网络工程师则以Vasily作为后端-即使Vasily拥有八只手,这也不是一片乌云。
作为网络服务的Neutron提供用于管理云基础架构的网络部分的API。该服务通过提供称为网络即服务(NaaS)的抽象层来提供Openstack网络部分的运行状况和管理。即,网络是与例如CPU虚拟核或RAM相同的虚拟可测量单元。
但是在进入OpenStack网络体系结构之前,让我们看一下OpenStack网络的工作原理以及为什么网络是云的重要组成部分。
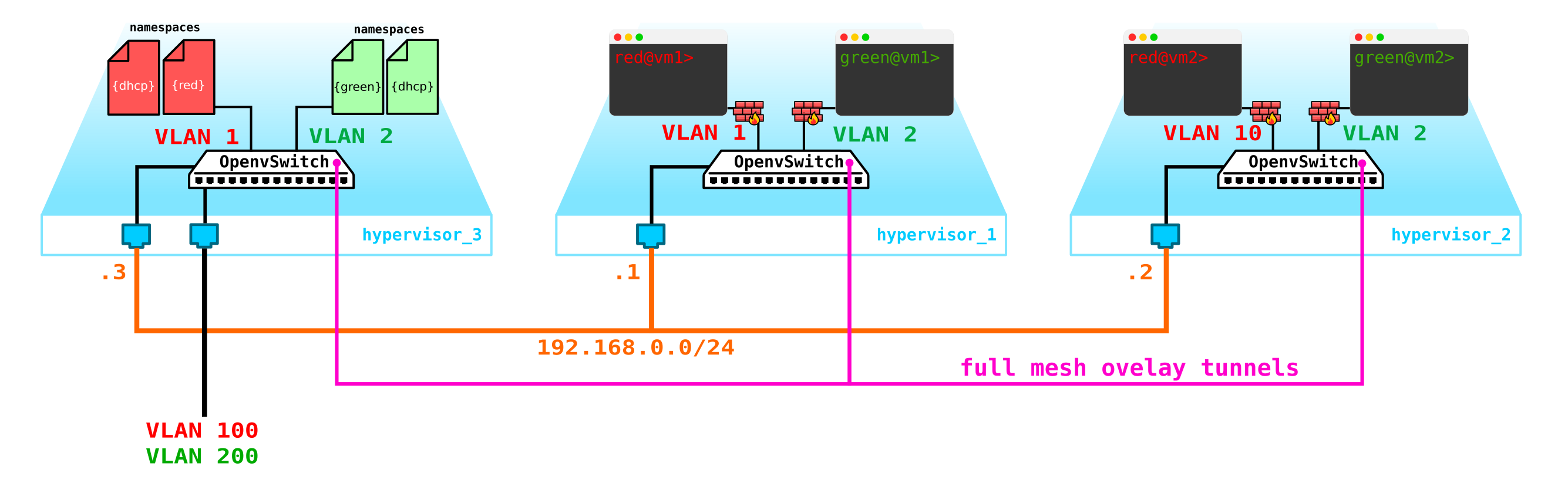
因此,我们有两个RED客户端虚拟机和两个GREEN客户端虚拟机。假设这些机器位于两个这样的管理程序上:
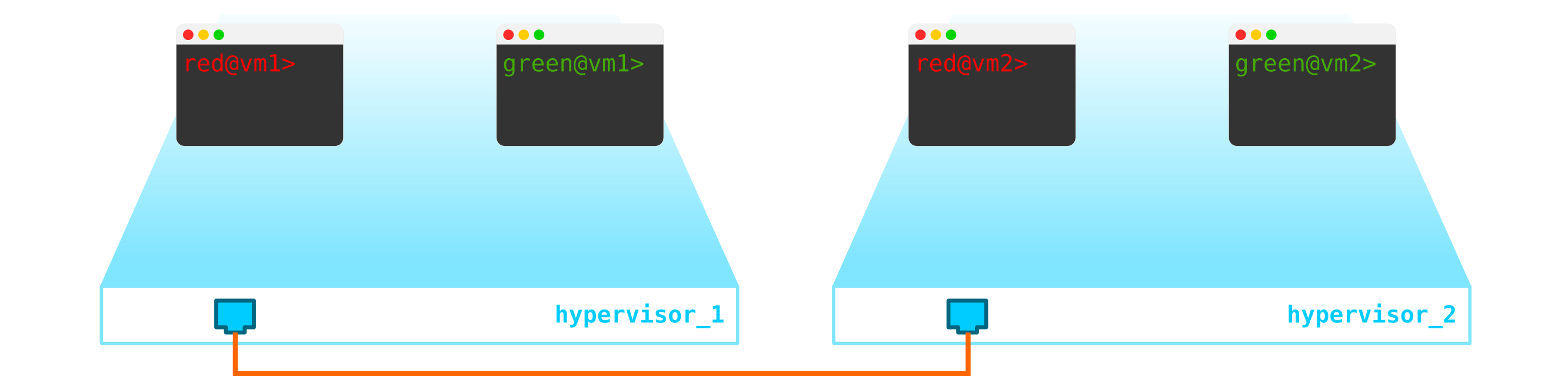
目前,这只是4个服务器的虚拟化,仅此而已,因为到目前为止,我们所做的只是4个服务器的虚拟化,将它们放置在两个物理服务器上。到目前为止,它们甚至都没有连接到网络。
要获得云,我们需要添加几个组件。首先,我们将网络部分虚拟化-我们需要成对地连接这4台计算机,而客户端恰好需要L2连接。您可以使用该交换机并在其方向上设置中继,并使用linux网桥或更高级的openvswitch用户(我们将继续介绍)来管理所有内容。但是可能会有很多网络,并且不断地通过交换机推动L2并不是最好的主意-因此,不同的部门,服务台,数月的应用程序执行等待时间,数周的故障排除-这种方法在现代世界中不再有效。公司越早意识到这一点,就越容易向前迈进。因此,在虚拟机管理程序之间,我们将选择一个L3网络,虚拟机将通过该L3网络进行通信,并且已经在该L3网络之上,我们将构建虚拟的叠加L2(覆盖)网络,虚拟机流量将在哪里运行。 GRE,Geneve或VxLAN可用作封装。现在,让我们继续讨论后者,尽管它并不是特别重要。
我们需要将VTEP放在某个地方(我希望每个人都熟悉VxLAN术语)。由于L3网络立即从服务器中出来,因此没有什么可以阻止我们将VTEP放置在服务器本身上,而OVS(OpenvSwitch)可以完美地做到这一点。结果,我们得到了以下构造:
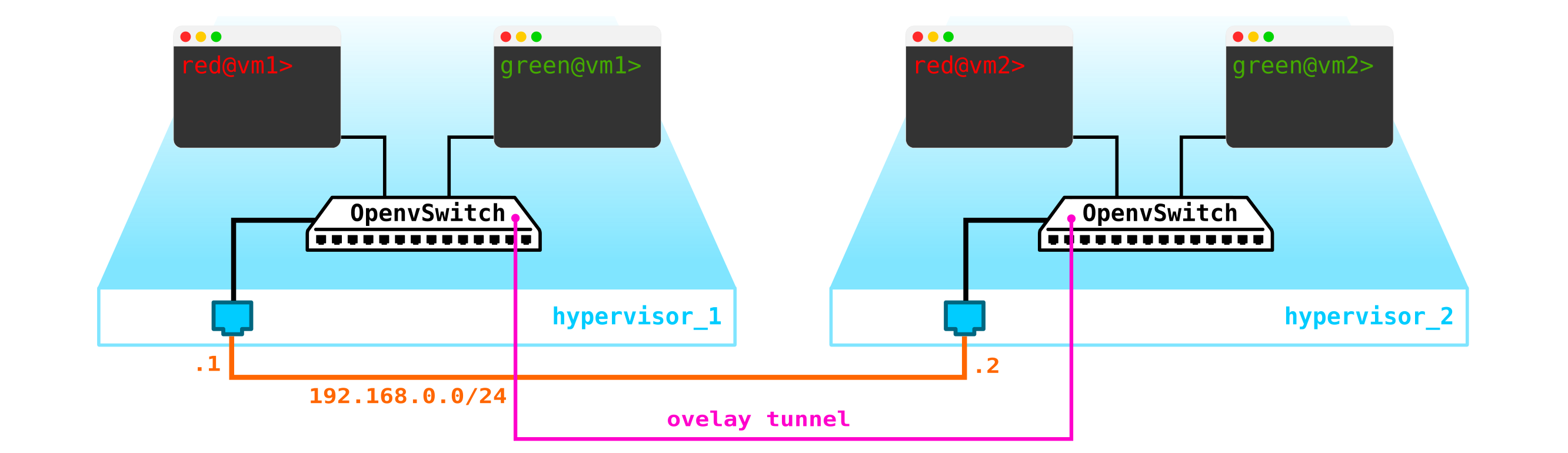
由于必须划分VM之间的流量,因此通往虚拟机的端口将具有不同的VLAN号。标签号仅在一个虚拟交换机中起作用,因为将其封装在VxLAN中时,我们可以毫无问题地删除它,因为我们将拥有一个VNI。

现在,我们可以为其创建机器和虚拟网络,而不会出现任何问题。
但是,如果客户端有另一台计算机,但是在不同的网络上怎么办?我们需要在网络之间扎根。当使用集中式生根时,我们将分析一个简单的选项-也就是说,流量通过特殊的专用网络节点进行路由(通常,它们与控制节点结合在一起,因此我们将拥有相同的东西)。
似乎没有什么复杂的-我们在控制节点上建立一个桥接接口,驱动流量到该节点,然后从那里路由到我们需要的位置。但是问题是RED客户端想要使用10.0.0.0/24网络,而GREEN客户端想要使用10.0.0.0/24网络。即,地址空间的交集开始。此外,客户端不希望将其他客户端路由到其内部网络,这是合乎逻辑的。为了分隔客户数据的网络和流量,我们将为它们各自分配一个单独的名称空间。实际上,命名空间是Linux网络堆栈的副本,也就是说,命名空间RED中的客户端与命名空间GREEN中的客户端是完全隔离的(嗯,可以通过默认命名空间允许这些客户端网络之间的路由,也可以在上游传输设备上进行路由)。
也就是说,我们得到以下方案:
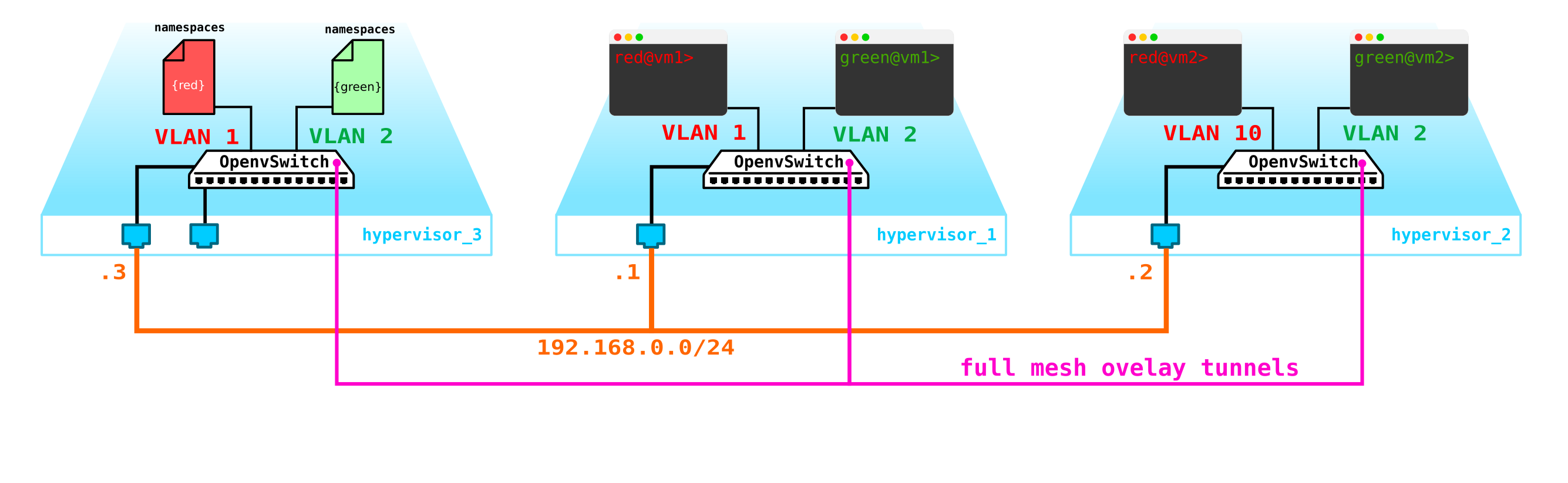
L2隧道从所有计算节点汇聚到控制节点。这些网络的L3接口所在的节点,每个节点都位于专用的名称空间中以进行隔离。
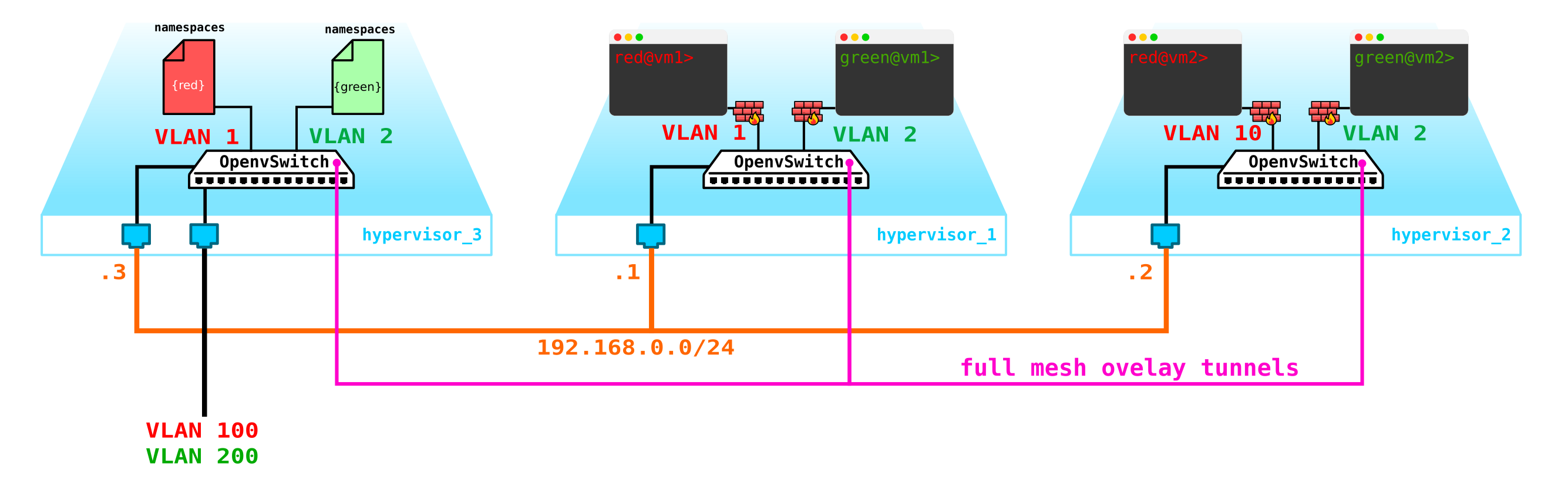
但是,我们忘记了最重要的事情。虚拟机必须向客户端提供服务,也就是说,它必须至少具有一个可以通过其访问外部接口。也就是说,我们需要进入外界。这里有不同的选择。让我们做一个最简单的选择。让我们在一个网络上添加客户端,该客户端将在提供者的网络中有效,并且不会与其他网络相交。网络也可以重叠,并在提供商网络一侧查看不同的VRF。这些网络也将存在于每个客户端的名称空间中。但是,它们仍将通过一个物理(或绑定,更合乎逻辑)接口进入外界。为了分隔客户端流量,将使用分配给客户端的VLAN标签来标记出站流量。
结果,我们得到了以下方案:

一个合理的问题-为什么不在计算节点本身上建立网关?此外,这不是一个大问题,当您打开分布式路由器(DVR)时,它将像这样工作。在这种情况下,我们考虑带有集中式网关的最简单选项,这是Openstack中的默认选项。对于高负载功能,他们将同时使用分布式路由器和加速技术,例如SR-IOV和Passthrough,但是正如他们所说,这是完全不同的故事。首先,让我们处理基本部分,然后再详细介绍。
实际上,我们的方案已经可以运行,但是有一些细微差别:
- 我们需要以某种方式保护我们的机器,即在交换机接口上向客户端挂一个过滤器。
- 使虚拟机可以自动获取IP地址,这样您就不必每次都通过控制台输入IP地址并注册该地址。
让我们从保护机器开始。为此,您可以使用普通的iptables,为什么不呢?
也就是说,现在我们的拓扑变得更加复杂:
让我们进一步。我们需要添加一个DHCP服务器。对于每个客户端而言,DHCP服务器位置的最理想位置将是上面已经提到的控制节点,命名空间位于其中:
但是,存在一个小问题。如果一切重新启动并且所有DHCP地址租约信息都消失了该怎么办。将新地址发布给计算机是合乎逻辑的,这不是很方便。解决方法有两种-要么使用域名并为每个客户端添加一个DNS服务器,然后地址对我们来说就不是很重要(类似于k8s中的网络部分),但是外部网络存在问题,因为也可以在其中发布地址通过DHCP-您需要与云平台中的DNS服务器和外部DNS服务器进行同步,我认为这不是非常灵活,但是很有可能。或者第二种选择是使用元数据-也就是说,保存有关发布到计算机的地址的信息,以便DHCP服务器知道在计算机已经接收到地址的情况下要发布到计算机的地址。第二个选项更简单,更灵活,因为它可以保存有关汽车的其他信息。现在将代理元数据添加到架构中:
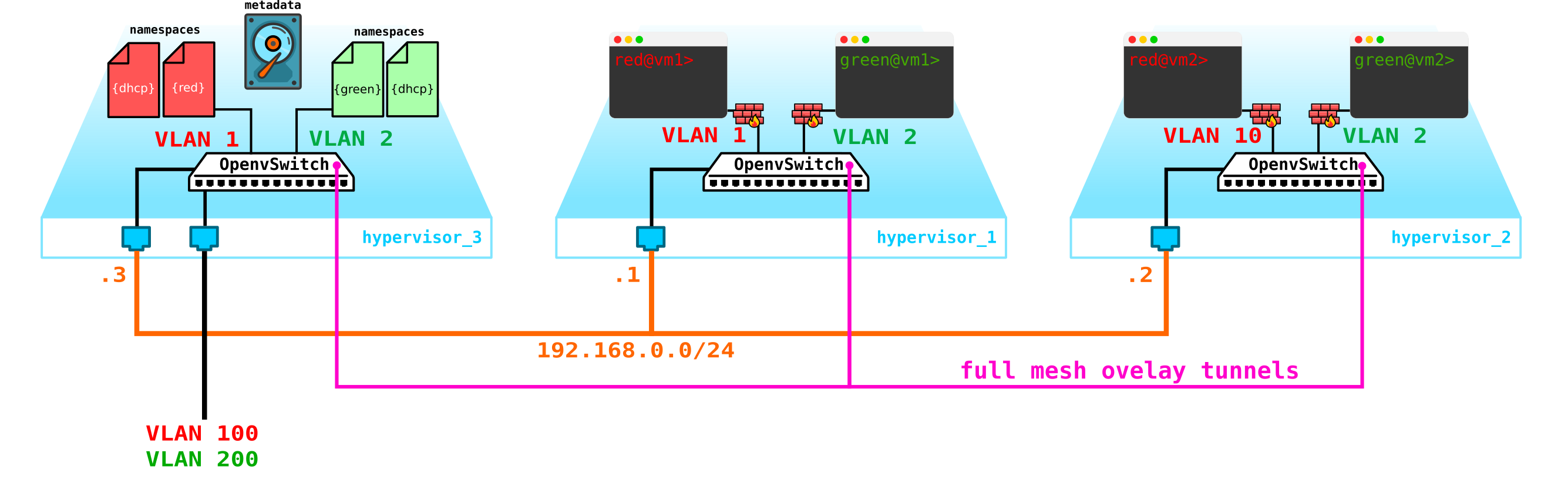
另一个应该明确化的问题是为所有客户端使用一个外部网络的能力,因为外部网络要在整个网络中都有效,将会带来复杂性-您需要不断分配和控制这些网络的分配。创建公共云时,为所有客户端使用单个外部预配置网络的功能将非常有用。这将简化机器部署,因为我们不必检查地址数据库并为每个客户端的外部网络选择唯一的地址空间。此外,我们可以预先注册一个外部网络,并且在部署时,我们只需要将外部地址与客户端计算机相关联即可。
NAT可以为您提供帮助-我们只是使客户端可以使用NAT转换通过默认名称空间访问外界。好吧,这是一个小问题。如果客户端服务器充当客户端而不是服务器,则很好-也就是说,它启动而不是接受连接。但是与我们相反。在这种情况下,我们需要进行目标NAT,以便在接收流量时,控制节点了解到此流量是针对客户端A的虚拟机A的,这意味着我们需要将NAT从外部地址(例如100.1.1.1)转换为内部地址10.0.0.1。在这种情况下,尽管所有客户端都将使用相同的网络,但内部隔离是完全保留的。也就是说,我们需要在控制节点上进行dNAT和sNAT。由于您要拖到云中,因此请使用分配了浮动地址的单个网络或外部网络,或同时使用这两个网络。我们不会在该图中添加浮动地址,但会保留之前已添加的外部网络-每个客户端都有自己的外部网络(在图中,它们在外部接口上分别指定为VLAN 100和VLAN 200)。
结果,我们得到了一个有趣且同时经过深思熟虑的解决方案,该解决方案具有一定的灵活性,但到目前为止还没有容错机制。
首先,我们只有一个控制节点-它的故障将导致所有系统崩溃。要解决此问题,您至少需要使3个节点达到法定人数。让我们将其添加到图中:
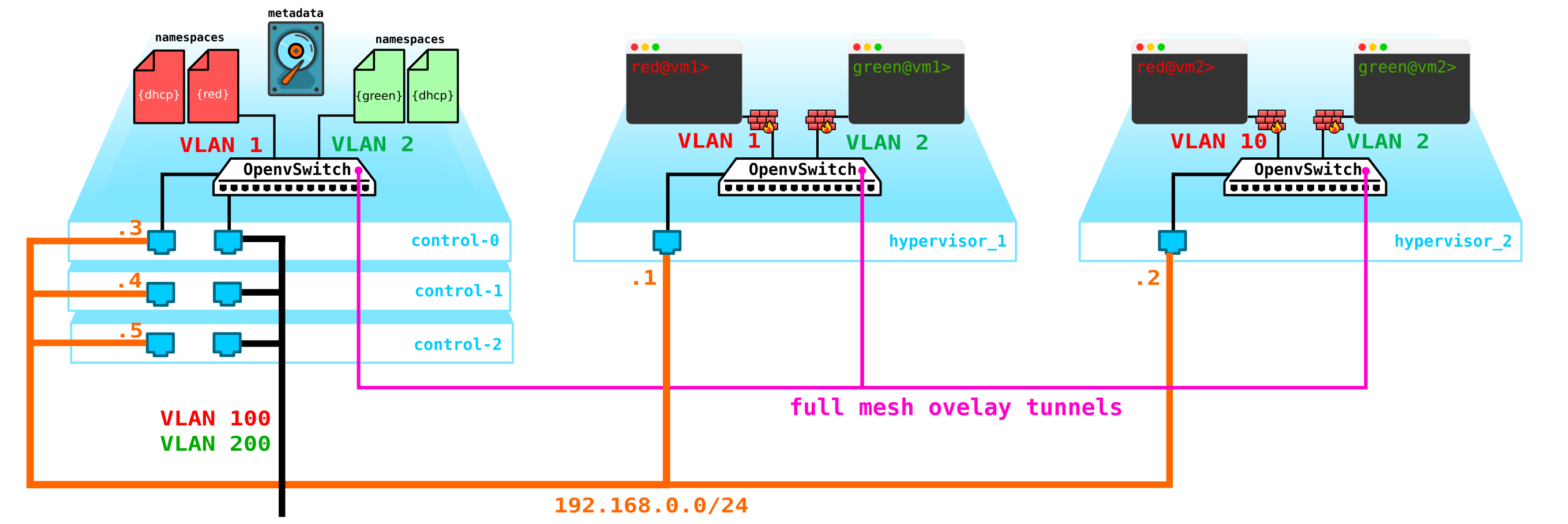
自然地,所有节点都已同步,并且当活动节点退出时,另一个节点将接管其职责。
下一个问题是虚拟机磁盘。目前,它们存储在虚拟机监控程序本身上,如果虚拟机监控程序出现问题,我们将丢失所有数据-如果我们丢失的不是磁盘而是整个服务器,则突袭的存在将无济于事。为此,我们需要提供将充当某些存储前端的服务。什么样的存储对我们来说并不是特别重要,但是它应该保护我们的数据不受磁盘和节点以及整个机柜故障的影响。这里有几种选择-当然有带有光纤通道的SAN网络,但说实话-FC已经是过去的遗物-运输中E1的类似物-是的,我同意,它仍然被使用,但只有在没有它的情况下绝对不可能。因此,我知道有其他更有趣的选择,所以我不会在2020年自愿部署FC网络。尽管对于每个人来说,也许有人会相信,FC具有其所有局限性是我们所需要的-我不会争辩,每个人都有自己的看法。但是,我认为最有趣的解决方案是使用SDS,例如Ceph。
Ceph的允许您与一堆冗余选择构建vyskodostupnoe存储解决方案中,由于码奇偶性(模拟RAID 5或6)用比基于磁盘的位置服务器,和服务器在橱柜等的多个磁盘上的数据的一个完整的复制结束。
对于Ceph程序集还需要3个节点。与存储的交互也将通过网络使用块,对象和文件存储的服务来进行。将存储添加到架构:
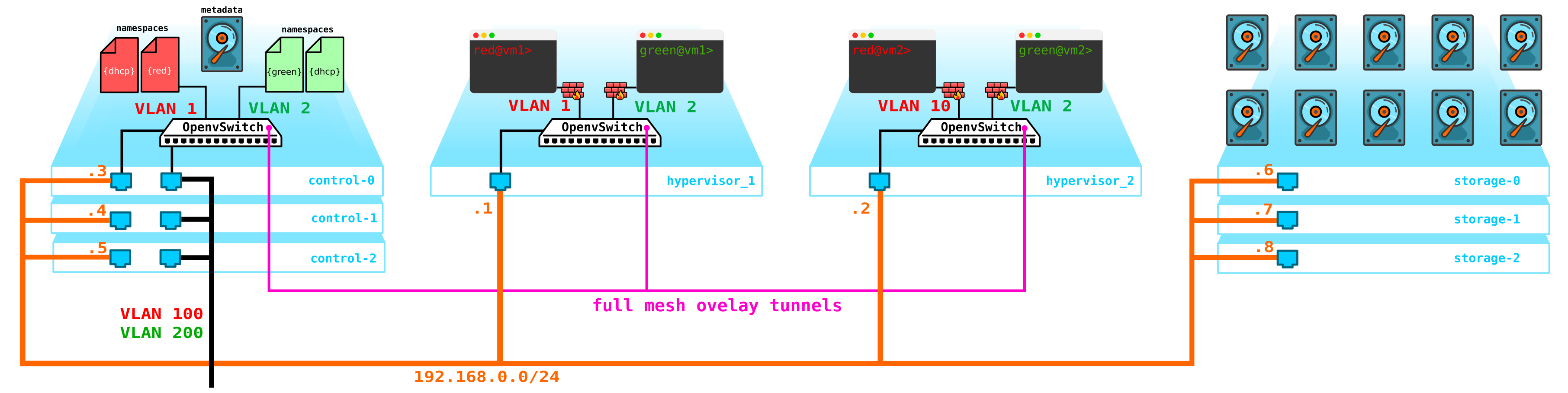
: compute — — storage+compute — ceph storage. — SDS . — — storage ( ) — CPU SDS ( , , ). compute storage.所有这些东西都需要以某种方式进行管理-我们需要通过它们我们可以创建机器,网络,虚拟路由器等。为此,将服务添加到充当仪表板的控制节点中-客户端将能够通过http /连接到该门户。 https并执行所需的所有操作(差不多)。
结果,我们现在有了一个容错系统。必须以某种方式管理此基础结构的所有元素。前面已经描述过Openstack是一组项目,每个项目都提供一些特定的功能。正如我们所看到的,需要配置和控制的元素已经足够多。今天我们将讨论网络部分。
中子架构
在OpenStack中,由Neutron负责将虚拟机的端口连接到公共L2网络,确保位于不同L2网络中的VM之间的流量路由以及向外路由,从而提供NAT,浮动IP,DHCP等
服务。网络服务的高级操作(基本部分)可以描述如下。
启动VM时,网络服务:
- 为该VM创建一个端口(或多个端口),并将其通知给DHCP服务;
- 创建了一个新的虚拟网络设备(通过libvirt);
- VM连接到在步骤1中创建的端口(端口);
奇怪的是,但Neutron工作的核心是标准机制,这些标准机制曾经让每一个涉足Linux的人都熟悉,它们是名称空间,iptables,Linux桥,openvswitch,conntrack等。
应该立即阐明Neutron不是SDN控制器。
Neutron由几个相互连接的组件组成:
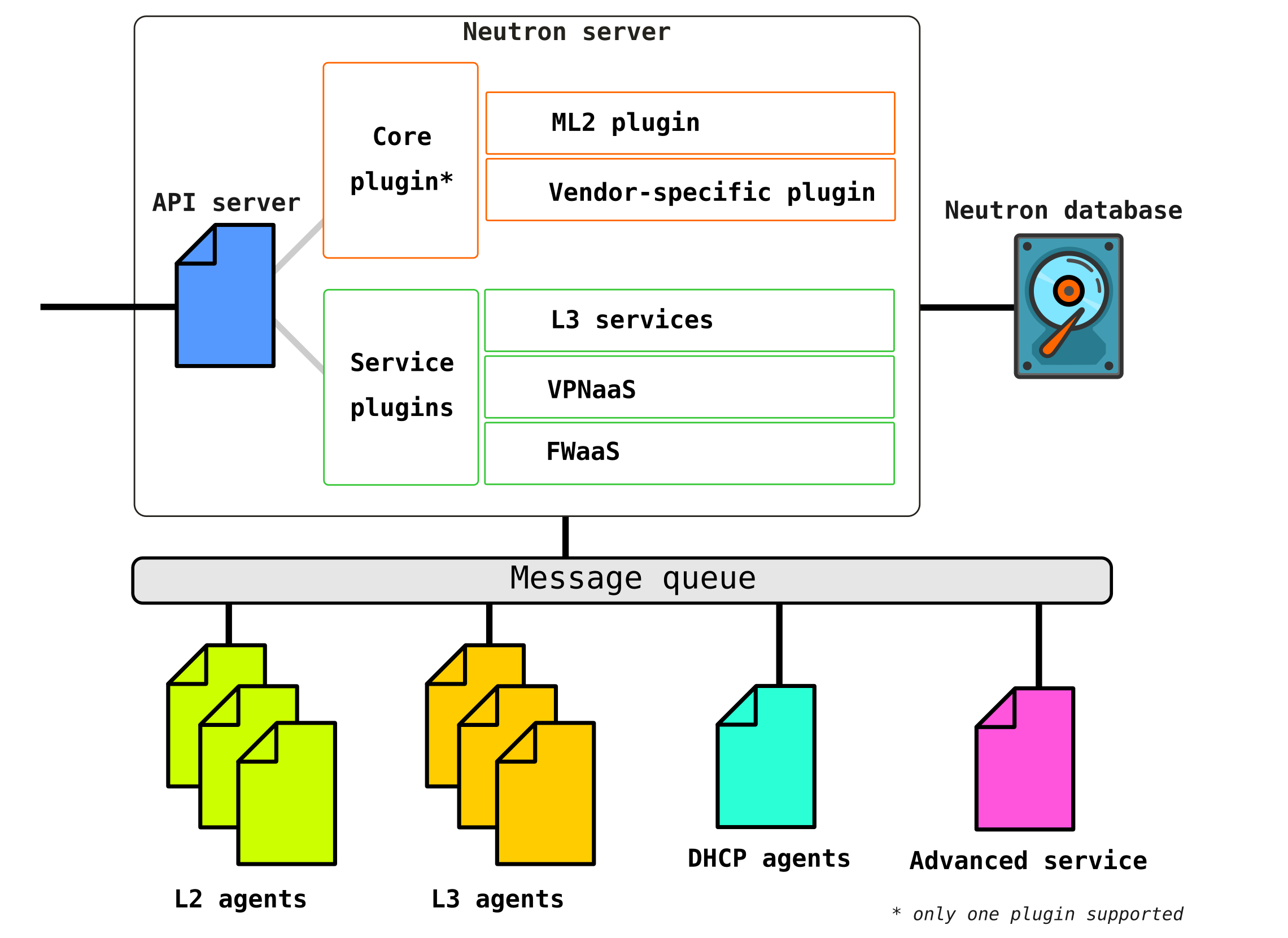
Openstack-neutron-server是一个守护程序,可通过API处理用户请求。该守护程序没有规定任何网络连接性,但是为其插件提供了必要的信息,然后由其配置所需的网络元素。OpenStack节点上的Neutron代理向Neutron服务器注册。
Neutron-server实际上是一个用python编写的应用程序,由两部分组成:
- REST服务
- Neutron插件(核心/服务)
REST服务旨在接收来自其他组件的API调用(例如,提供一些信息的请求等)。
插件是在API请求时调用的插件软件组件/模块-即,某些服务的分配通过它们进行。插件分为两种类型:服务和根。通常,马插件主要负责管理VM之间的地址空间和L2连接,并且服务插件已经提供了其他功能,例如VPN或FW。
例如,
可以在此处查看今天可用的插件列表。可能有几个服务插件,但只能有一个马插件。
Openstack-neutron-ml2是标准的Openstack根插件。该插件具有模块化体系结构(不同于其前身),并通过与其连接的驱动程序来配置网络服务。我们稍后再考虑插件本身,因为实际上它提供了OpenStack在网络部分所具有的灵活性。可以替换根插件(例如,Contrail Networking进行了替换)。
RPC服务(rabbitmq-server) -一种服务,提供队列管理和与其他OpenStack服务的通信,以及网络服务代理之间的通信。
网络代理-位于通过其配置网络服务的每个节点中的代理。
代理有几种类型。
主要代理是L2代理。这些代理在每个管理程序上运行,包括控制节点(更确切地说,在为租户提供任何服务的所有节点上),它们的主要功能是将虚拟机连接到公共L2网络,并在发生任何事件时生成警报(例如,禁用/启用端口)。
另一个同样重要的代理是L3代理...默认情况下,此代理仅在网络节点上运行(通常将网络节点与控制节点结合在一起),并在租户网络之间提供路由(在其网络和其他租户的网络之间,并且可供外部世界使用,提供NAT和DHCP服务)。但是,使用DVR(分布式路由器)时,在计算节点上也需要L3插件。
L3代理使用Linux命名空间为每个租户提供一组自己的隔离网络以及虚拟路由器的功能,这些路由器可路由流量并为第2层网络提供网关服务。
数据库-网络,子网,端口,池等的标识符的数据库。
实际上,Neutron接受来自任何网络实体创建的API请求,对请求进行身份验证,并通过RPC(如果它寻址到某些插件或代理)或REST API(如果在SDN中通信)向代理(通过插件)发送组织请求的服务所需的指令。 ...
现在让我们转到测试安装(如何部署以及它在实际部分的后面),并查看哪个组件位于何处:
(overcloud) [stack@undercloud ~]$ openstack network agent list
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| ID | Agent Type | Host | Availability Zone | Alive | State | Binary |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| 10495de9-ba4b-41fe-b30a-b90ec3f8728b | Open vSwitch agent | overcloud-novacompute-1.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| 1515ad4a-5972-46c3-af5f-e5446dff7ac7 | L3 agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-l3-agent |
| 322e62ca-1e5a-479e-9a96-4f26d09abdd7 | DHCP agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-dhcp-agent |
| 9c1de2f9-bac5-400e-998d-4360f04fc533 | Open vSwitch agent | overcloud-novacompute-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| d99c5657-851e-4d3c-bef6-f1e3bb1acfb0 | Open vSwitch agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| ff85fae6-5543-45fb-a301-19c57b62d836 | Metadata agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-metadata-agent |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
(overcloud) [stack@undercloud ~]$ 
实际上,这就是中子的整体结构。现在值得花一些时间使用ML2插件。
模块化层2
如上所述,该插件是标准的OpenStack根插件,具有模块化体系结构。
ML2插件的前身具有整体结构,例如,不允许在一个安装中同时使用多种技术。例如,您不能同时使用openvswitch和linuxbridge-第一个或第二个。因此,创建了具有其体系结构的ML2插件。
ML2具有两个组件-两种类型的驱动程序:类型驱动程序和机制驱动程序。
类型驱动程序定义将用于组织网络连接的技术,例如VxLAN,VLAN,GRE。在这种情况下,驱动程序允许您使用其他技术。标准技术是用于覆盖网络和vlan外部网络的VxLAN封装。
类型驱动程序包括以下类型的网络:
扁平-不带标记
VLAN的网络-带标记的网络
本地-用于多合一安装的特殊类型的网络(对于开发人员或培训而言,此类安装都是必需的)
GRE-使用GRE
VxLAN隧道的覆盖网络-使用VxLAN隧道的覆盖网络
机制驱动程序定义了提供类型驱动程序中指定的技术组织的方式-例如,openvswitch,sr-iov,opendaylight,OVN等。
根据此驱动程序的实现,将使用由Neutron控制的代理,或者将使用与外部SDN控制器的连接,这将解决组织L2网络,路由等所有问题。
示例如果将ML2与OVS一起使用,则每个计算节点都由管理OVS的L2代理设置。但是,例如,如果我们使用OVN或OpenDayLight,则OVS控件将受其管辖-Neutron通过根插件将命令提供给控制器,而他已经做到了。
让我们刷新内存打开vSwitch
目前,OpenStack的关键组件之一是Open vSwitch。
在没有任何其他供应商SDN(例如Juniper Contrail或Nokia Nuage)的情况下安装OpenStack时,OVS是云网络的主要网络组件,并且与iptables,conntrack,名称空间一起使您可以组织具有多租户的功能完善的覆盖网络。自然,例如在使用第三方专有(供应商)SDN解决方案时,可以替换此组件。
OVS是一种开放源代码软件交换机,旨在在虚拟化环境中用作虚拟流量转发器。
目前,OVS具有非常不错的功能,其中包括QoS,LACP,VLAN,VxLAN,GENEVE,OpenFlow,DPDK等技术。
注意:最初,OVS并不是用于高负载电信功能的软交换机,而是专门用于带宽占用较少的IT功能(例如WEB服务器或邮件服务器)。但是,OVS正在最终确定中,当前的OVS实现已大大提高了其性能和功能,这使其可以被具有高负载功能的电信运营商使用,例如,具有支持DPDK的OVS实现。
有三个重要的OVS组件需要注意:
- 内核模块-位于内核空间中的组件,可根据从控件接收的规则来处理流量;
- vSwitch daemon (ovs-vswitchd) — , user space, kernel —
- Database server — , , OVS, . OVSDB SDN .
所有这些还伴随着一组诊断和管理实用程序,例如ovs-vsctl,ovs-appctl,ovs-ofctl等。
当前,Openstack已被电信运营商广泛使用,以将网络功能迁移到它,例如EPC,SBC,HLR某些功能可以正常使用,而OVS不会出现问题,但是例如EPC处理订户流量-即,它通过自身传递大量流量(现在流量达到每秒几百吉比特)。自然地,通过内核空间驱动此类流量(因为默认情况下转发器位于此处)不是一个好主意。因此,通常使用DPDK加速技术将OVS完全部署在用户空间中,从而绕过内核将流量从NIC转发到用户空间。
注意:对于部署用于电信功能的云,可以从计算节点绕过OVS直接向交换设备输出流量。SR-IOV和直通机制用于此目的。
在实际布局中如何工作?
好了,现在让我们进入实际部分,看看它在实践中如何工作。
让我们从部署一个简单的Openstack安装开始。由于我手边没有一组服务器可以进行实验,因此我们将从虚拟机中将布局组装到一个物理服务器上。是的,当然,这样的解决方案不适合商业用途,但以网络在Openstack中的工作方式为例,这样的安装就足够了。此外,这种用于培训目的的安装更加有趣-因为您可以捕获流量等。
因为我们只需要看基本部分,所以我们不能使用多个网络,而只能使用两个网络来进行所有操作,并且此布局中的第二个网络将专门用于访问undercloud和dns服务器。我们暂时不涉及外部网络-这是另一篇大文章的主题。
因此,让我们按顺序开始。首先,一点理论。我们将使用TripleO(Openstack上的Openstack)安装Openstack。 TripleO的本质是,我们在一个节点上安装了一个称为undercloud的Openstack,即一体式(然后在一个节点上),然后使用已部署的Openstack的功能来安装一个旨在进行利用的Openstack,称为overcloud。 Undercloud将利用其固有的能力来管理物理服务器(裸机)(Ironic项目),以配置将充当计算,控制,存储节点的虚拟机监控程序。也就是说,我们不使用任何第三方工具来部署Openstack-我们将Openstack与Openstack一起部署。在整个安装过程中,它将变得更加清晰,所以我们不要就此停下来继续前进。
: Openstack, . — , , . . ceph ( ) (Storage management Storage) , , QoS , . .
注意:由于我们要在基于虚拟机的虚拟环境中运行虚拟机,因此我们首先需要启用嵌套虚拟化。
您可以像这样检查是否启用了嵌套虚拟化:
[root@hp-gen9 bormoglotx]# cat /sys/module/kvm_intel/parameters/nested N [root@hp-gen9 bormoglotx]#
如果看到字母N,那么我们将根据您在网络上找到的任何指南(例如本指南)启用对嵌套虚拟化的支持。
我们需要从虚拟机中组装以下方案:

在我的情况下,为了实现未来安装中的虚拟机的连接性(我有7个虚拟机,但是如果没有很多资源则可以增加4个),我使用了OpenvSwitch。我创建了一个ovs桥,并通过端口组将虚拟机连接到它。为此,我创建了以下格式的xml文件:
[root@hp-gen9 ~]# virsh net-dumpxml ovs-network-1
<network>
<name>ovs-network-1</name>
<uuid>7a2e7de7-fc16-4e00-b1ed-4d190133af67</uuid>
<forward mode='bridge'/>
<bridge name='ovs-br1'/>
<virtualport type='openvswitch'/>
<portgroup name='trunk-1'>
<vlan trunk='yes'>
<tag id='100'/>
<tag id='101'/>
<tag id='102'/>
</vlan>
</portgroup>
<portgroup name='access-100'>
<vlan>
<tag id='100'/>
</vlan>
</portgroup>
<portgroup name='access-101'>
<vlan>
<tag id='101'/>
</vlan>
</portgroup>
</network>在此声明该组的三个端口-两个访问和一个中继(DNS服务器需要后者),但是您可以不使用它,也可以在主机上提升它-这对您来说更方便。接下来,使用此模板,我们通过virsh net-define声明我们的is:
virsh net-define ovs-network-1.xml
virsh net-start ovs-network-1
virsh net-autostart ovs-network-1 现在,让我们编辑虚拟机管理程序端口的配置:
[root@hp-gen9 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens1f0
TYPE=Ethernet
NAME=ens1f0
DEVICE=ens1f0
TYPE=OVSPort
DEVICETYPE=ovs
OVS_BRIDGE=ovs-br1
ONBOOT=yes
OVS_OPTIONS="trunk=100,101,102"
[root@hp-gen9 ~]
[root@hp-gen9 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ovs-br1
DEVICE=ovs-br1
DEVICETYPE=ovs
TYPE=OVSBridge
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.255.200
PREFIX=24
[root@hp-gen9 ~]# 注意:在这种情况下,端口ovs-br1上的地址将不可用,因为它没有vlan标签。要解决此问题,请发出命令sudo ovs-vsctl set port ovs-br1 tag = 100。但是,重新启动后,该标签将消失(如果有人知道如何使其保持在原位,我将非常感激)。但这并不是那么重要,因为我们仅在安装时需要此地址,而在完全部署Openstack时将不需要此地址。接下来,我们创建一个undercloud汽车:
virt-install -n undercloud --description "undercloud" --os-type=Linux --os-variant=centos7.0 --ram=8192 --vcpus=8 --disk path=/var/lib/libvirt/images/undercloud.qcow2,bus=virtio,size=40,format=qcow2 --network network:ovs-network-1,model=virtio,portgroup=access-100 --network network:ovs-network-1,model=virtio,portgroup=access-101 --graphics none --location /var/lib/libvirt/boot/CentOS-7-x86_64-Minimal-2003.iso --extra-args console=ttyS0在安装过程中,您可以设置所有必要的参数,例如计算机名称,密码,用户,ntp服务器等,可以立即配置端口,但是安装后,我可以更轻松地通过控制台进入计算机并更正必要的文件。如果您已经有现成的映像,则可以使用它,也可以按照我的方式进行操作-下载Centos 7的最小映像并使用它来安装VM。
成功安装后,您应该拥有一个可以在其上放置undercloud的虚拟机
[root@hp-gen9 bormoglotx]# virsh list
Id Name State
----------------------------------------------------
6 dns-server running
62 undercloud running首先,我们在安装过程中安装必要的工具:
sudo yum update -y
sudo yum install -y net-tools
sudo yum install -y wget
sudo yum install -y ipmitool
安装Undercloud
创建一个堆栈用户,设置密码,将其添加到sudoer中,并使其能够通过sudo执行root命令,而无需输入密码:
useradd stack
passwd stack
echo “stack ALL=(root) NOPASSWD:ALL” > /etc/sudoers.d/stack
chmod 0440 /etc/sudoers.d/stack现在,我们在hosts文件中指定undercloud的全名:
vi /etc/hosts
127.0.0.1 undercloud.openstack.rnd localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6接下来,添加存储库并安装我们需要的软件:
sudo yum install -y https://trunk.rdoproject.org/centos7/current/python2-tripleo-repos-0.0.1-0.20200409224957.8bac392.el7.noarch.rpm
sudo -E tripleo-repos -b queens current
sudo -E tripleo-repos -b queens current ceph
sudo yum install -y python-tripleoclient
sudo yum install -y ceph-ansible注意:如果您不打算安装ceph,则不需要输入与ceph相关的命令。我使用了Queens版本,但是您可以使用任何您喜欢的其他版本。接下来,将undercloud配置文件复制到用户的堆栈主目录中:
cp /usr/share/instack-undercloud/undercloud.conf.sample ~/undercloud.conf现在,我们需要通过将其调整为我们的安装来修复该文件。
在文件的开头,添加以下行:
vi undercloud.conf
[DEFAULT]
undercloud_hostname = undercloud.openstack.rnd
local_ip = 192.168.255.1/24
network_gateway = 192.168.255.1
undercloud_public_host = 192.168.255.2
undercloud_admin_host = 192.168.255.3
undercloud_nameservers = 192.168.255.253
generate_service_certificate = false
local_interface = eth0
local_mtu = 1450
network_cidr = 192.168.255.0/24
masquerade = true
masquerade_network = 192.168.255.0/24
dhcp_start = 192.168.255.11
dhcp_end = 192.168.255.50
inspection_iprange = 192.168.255.51,192.168.255.100
scheduler_max_attempts = 10因此,请进行以下设置:
undercloud_hostname-完整的undercloud服务器名称必须与DNS服务器中的条目
local_ip -undercloud一起提供给网络
network_gateway-相同的本地地址,该本地地址将用作安装期间访问外部世界的网关overcloud节点,还匹配本地ip
undercloud_public_host-外部API地址,从配置网络中分配了任何免费地址
undercloud_admin_host内部API地址,从配置网络中分配了任何免费地址
undercloud_nameservers -DNS服务器
generate_service_certificate-该行在当前示例中非常重要,因为如果未将其设置为false,则会在安装过程中收到错误消息,该问题在网络配置中的Red Hat Bug跟踪器
local_interface接口上进行了描述。此接口将在部署undercloud期间重新配置,因此您需要在
undercloud上具有两个接口-一个用于访问它,另一个用于供应local_mtu -MTU。由于我们有一个测试实验室,并且MTU我有1,500个OVS Svicha端口,因此有必要在1450年投入价值,该价值将被封装在VxLAN包中
network_cidr-设置网络
伪装-使用NAT访问外部网络
masquerade_network-一个将进行NAT的网络-s
dhcp_start-在
overcloud部署过程中将地址分配给节点的地址池的起始地址dhcp_end-在overcloud部署过程中地址将分配给节点的地址池的最终地址
inspection_iprange-自省所需的地址池(不应与上述池相交) )
scheduler_max_attempts-尝试安装overcloud的最大尝试次数(必须大于或等于节点数)
描述文件后,您可以给出命令来部署undercloud:
openstack undercloud install
该过程需要10到30分钟,具体取决于您的熨斗。最终,您应该看到如下输出:
vi undercloud.conf
2020-08-13 23:13:12,668 INFO:
#############################################################################
Undercloud install complete.
The file containing this installation's passwords is at
/home/stack/undercloud-passwords.conf.
There is also a stackrc file at /home/stack/stackrc.
These files are needed to interact with the OpenStack services, and should be
secured.
#############################################################################此输出表明您已经成功安装了undercloud,现在您可以检查undercloud的状态并继续安装overcloud。
如果查看ifconfig的输出,将看到出现了一个新的网桥接口
[stack@undercloud ~]$ ifconfig
br-ctlplane: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 192.168.255.1 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe2c:89e prefixlen 64 scopeid 0x20<link>
ether 52:54:00:2c:08:9e txqueuelen 1000 (Ethernet)
RX packets 14 bytes 1095 (1.0 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 20 bytes 1292 (1.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0现在将通过此界面执行Overcloud部署。
从下面的输出中可以看到,我们在一个节点上拥有所有服务:
(undercloud) [stack@undercloud ~]$ openstack host list
+--------------------------+-----------+----------+
| Host Name | Service | Zone |
+--------------------------+-----------+----------+
| undercloud.openstack.rnd | conductor | internal |
| undercloud.openstack.rnd | scheduler | internal |
| undercloud.openstack.rnd | compute | nova |
+--------------------------+-----------+----------+下面是undercloud网络部分的配置:
(undercloud) [stack@undercloud ~]$ python -m json.tool /etc/os-net-config/config.json
{
"network_config": [
{
"addresses": [
{
"ip_netmask": "192.168.255.1/24"
}
],
"members": [
{
"dns_servers": [
"192.168.255.253"
],
"mtu": 1450,
"name": "eth0",
"primary": "true",
"type": "interface"
}
],
"mtu": 1450,
"name": "br-ctlplane",
"ovs_extra": [
"br-set-external-id br-ctlplane bridge-id br-ctlplane"
],
"routes": [],
"type": "ovs_bridge"
}
]
}
(undercloud) [stack@undercloud ~]$Overcloud安装
目前,我们只有Undercloud,而我们没有足够的节点来构建Overcloud。因此,首先,我们将部署所需的虚拟机。在部署过程中,undercloud本身将在overcloud机器上安装操作系统和必要的软件-也就是说,我们不需要完全部署机器,而只需为其创建一个磁盘(或多个磁盘)并确定其参数-实际上,我们得到的是一台裸露的服务器,未安装操作系统...
转到包含我们的虚拟机磁盘的文件夹,然后创建所需大小的磁盘:
cd /var/lib/libvirt/images/
qemu-img create -f qcow2 -o preallocation=metadata control-1.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata compute-1.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata compute-2.qcow2 60G
qemu-img create -f qcow2 -o preallocation=metadata storage-1.qcow2 160G
qemu-img create -f qcow2 -o preallocation=metadata storage-2.qcow2 160G由于我们是从根开始执行的,因此我们需要更改这些磁盘的所有者,以免出现权限问题:
[root@hp-gen9 images]# ls -lh
total 5.8G
drwxr-xr-x. 2 qemu qemu 4.0K Aug 13 16:15 backups
-rw-r--r--. 1 root root 61G Aug 14 03:07 compute-1.qcow2
-rw-r--r--. 1 root root 61G Aug 14 03:07 compute-2.qcow2
-rw-r--r--. 1 root root 61G Aug 14 03:07 control-1.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:03 dns-server.qcow2
-rw-r--r--. 1 root root 161G Aug 14 03:07 storage-1.qcow2
-rw-r--r--. 1 root root 161G Aug 14 03:07 storage-2.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:07 undercloud.qcow2
[root@hp-gen9 images]#
[root@hp-gen9 images]#
[root@hp-gen9 images]# chown qemu:qemu /var/lib/libvirt/images/*qcow2
[root@hp-gen9 images]# ls -lh
total 5.8G
drwxr-xr-x. 2 qemu qemu 4.0K Aug 13 16:15 backups
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 compute-1.qcow2
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 compute-2.qcow2
-rw-r--r--. 1 qemu qemu 61G Aug 14 03:07 control-1.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:03 dns-server.qcow2
-rw-r--r--. 1 qemu qemu 161G Aug 14 03:07 storage-1.qcow2
-rw-r--r--. 1 qemu qemu 161G Aug 14 03:07 storage-2.qcow2
-rw-------. 1 qemu qemu 41G Aug 14 03:08 undercloud.qcow2
[root@hp-gen9 images]# 注意:如果您打算安装ceph以便对其进行研究,请使用至少两个磁盘创建至少3个节点,并在模板中指示将使用虚拟磁盘vda,vdb等。太好了,现在我们需要定义所有这些机器:
virt-install --name control-1 --ram 32768 --vcpus 8 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/control-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --network network:ovs-network-1,model=virtio,portgroup=trunk-1 --dry-run --print-xml > /tmp/control-1.xml
virt-install --name storage-1 --ram 16384 --vcpus 4 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/storage-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/storage-1.xml
virt-install --name storage-2 --ram 16384 --vcpus 4 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/storage-2.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/storage-2.xml
virt-install --name compute-1 --ram 32768 --vcpus 12 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/compute-1.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/compute-1.xml
virt-install --name compute-2 --ram 32768 --vcpus 12 --os-variant centos7.0 --disk path=/var/lib/libvirt/images/compute-2.qcow2,device=disk,bus=virtio,format=qcow2 --noautoconsole --vnc --network network:ovs-network-1,model=virtio,portgroup=access-100 --dry-run --print-xml > /tmp/compute-2.xml 最后是--print-xml> /tmp/storage-1.xml命令,该命令会在/ tmp /文件夹中创建一个包含每台计算机描述的xml文件,如果不添加它,将无法定义虚拟机。
现在我们需要在virsh中定义所有这些机器:
virsh define --file /tmp/control-1.xml
virsh define --file /tmp/compute-1.xml
virsh define --file /tmp/compute-2.xml
virsh define --file /tmp/storage-1.xml
virsh define --file /tmp/storage-2.xml
[root@hp-gen9 ~]# virsh list --all
Id Name State
----------------------------------------------------
6 dns-server running
64 undercloud running
- compute-1 shut off
- compute-2 shut off
- control-1 shut off
- storage-1 shut off
- storage-2 shut off
[root@hp-gen9 ~]#现在有一点细微差别-TripleO使用IPMI来在安装和内省期间管理服务器。
自省是检查硬件以便获得进一步供应节点所需的参数的过程。内省使用具有讽刺意味的方法执行-具有讽刺意味的服务旨在与裸机服务器协同工作。
但这是问题所在-如果IPMI Iron服务器具有单独的端口(或共享端口,但这并不重要),则虚拟机将没有此类端口。在这里,有一个名为vbmc的拐杖可以帮助我们-一个实用程序,可让您模拟IPMI端口。对于需要在ESXI虚拟机管理程序上建立这样的实验室的人来说,这种细微差别尤其值得关注-如果,当然,我不知道它是否具有vbmc的类似物,那么在部署所有内容之前,您应该对此问题感到困惑。
安装vbmc:
yum install yum install python2-virtualbmc如果您的操作系统找不到软件包,请添加存储库:
yum install -y https://www.rdoproject.org/repos/rdo-release.rpm现在,我们配置实用程序。这里的一切都是陈腐的。现在逻辑上vbmc列表中没有服务器
[root@hp-gen9 ~]# vbmc list
[root@hp-gen9 ~]# 为了使它们出现,必须以这种方式手动声明它们:
[root@hp-gen9 ~]# vbmc add control-1 --port 7001 --username admin --password admin
[root@hp-gen9 ~]# vbmc add storage-1 --port 7002 --username admin --password admin
[root@hp-gen9 ~]# vbmc add storage-2 --port 7003 --username admin --password admin
[root@hp-gen9 ~]# vbmc add compute-1 --port 7004 --username admin --password admin
[root@hp-gen9 ~]# vbmc add compute-2 --port 7005 --username admin --password admin
[root@hp-gen9 ~]#
[root@hp-gen9 ~]# vbmc list
+-------------+--------+---------+------+
| Domain name | Status | Address | Port |
+-------------+--------+---------+------+
| compute-1 | down | :: | 7004 |
| compute-2 | down | :: | 7005 |
| control-1 | down | :: | 7001 |
| storage-1 | down | :: | 7002 |
| storage-2 | down | :: | 7003 |
+-------------+--------+---------+------+
[root@hp-gen9 ~]#我认为命令语法很清楚,没有解释。但是,目前,我们所有的会话都处于DOWN状态。要使它们进入UP状态,必须启用它们:
[root@hp-gen9 ~]# vbmc start control-1
2020-08-14 03:15:57,826.826 13149 INFO VirtualBMC [-] Started vBMC instance for domain control-1
[root@hp-gen9 ~]# vbmc start storage-1
2020-08-14 03:15:58,316.316 13149 INFO VirtualBMC [-] Started vBMC instance for domain storage-1
[root@hp-gen9 ~]# vbmc start storage-2
2020-08-14 03:15:58,851.851 13149 INFO VirtualBMC [-] Started vBMC instance for domain storage-2
[root@hp-gen9 ~]# vbmc start compute-1
2020-08-14 03:15:59,307.307 13149 INFO VirtualBMC [-] Started vBMC instance for domain compute-1
[root@hp-gen9 ~]# vbmc start compute-2
2020-08-14 03:15:59,712.712 13149 INFO VirtualBMC [-] Started vBMC instance for domain compute-2
[root@hp-gen9 ~]#
[root@hp-gen9 ~]#
[root@hp-gen9 ~]# vbmc list
+-------------+---------+---------+------+
| Domain name | Status | Address | Port |
+-------------+---------+---------+------+
| compute-1 | running | :: | 7004 |
| compute-2 | running | :: | 7005 |
| control-1 | running | :: | 7001 |
| storage-1 | running | :: | 7002 |
| storage-2 | running | :: | 7003 |
+-------------+---------+---------+------+
[root@hp-gen9 ~]#最后一点-您需要更正防火墙规则(或者完全禁用它):
firewall-cmd --zone=public --add-port=7001/udp --permanent
firewall-cmd --zone=public --add-port=7002/udp --permanent
firewall-cmd --zone=public --add-port=7003/udp --permanent
firewall-cmd --zone=public --add-port=7004/udp --permanent
firewall-cmd --zone=public --add-port=7005/udp --permanent
firewall-cmd --reload
现在,让我们进入undercloud并检查一切是否正常。主机地址为192.168.255.200,我们在准备部署期间将必需的ipmitool程序包添加到undercloud:
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power status
Chassis Power is off
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power on
Chassis Power Control: Up/On
[stack@undercloud ~]$
[root@hp-gen9 ~]# virsh list
Id Name State
----------------------------------------------------
6 dns-server running
64 undercloud running
65 control-1 running如您所见,我们已经通过vbmc成功启动了控制节点。现在将其关闭并继续:
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power off
Chassis Power Control: Down/Off
[stack@undercloud ~]$ ipmitool -I lanplus -U admin -P admin -H 192.168.255.200 -p 7001 power status
Chassis Power is off
[stack@undercloud ~]$
[root@hp-gen9 ~]# virsh list --all
Id Name State
----------------------------------------------------
6 dns-server running
64 undercloud running
- compute-1 shut off
- compute-2 shut off
- control-1 shut off
- storage-1 shut off
- storage-2 shut off
[root@hp-gen9 ~]#下一步是对将要安装overcloud的节点进行自省。为此,我们需要准备一个带有节点描述的json文件。请注意,与在裸机上进行安装不同,该文件指定每台计算机上运行vbmc的端口。
[root@hp-gen9 ~]# virsh domiflist --domain control-1
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:20:a2:2f
- network ovs-network-1 virtio 52:54:00:3f:87:9f
[root@hp-gen9 ~]# virsh domiflist --domain compute-1
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:98:e9:d6
[root@hp-gen9 ~]# virsh domiflist --domain compute-2
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:6a:ea:be
[root@hp-gen9 ~]# virsh domiflist --domain storage-1
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:79:0b:cb
[root@hp-gen9 ~]# virsh domiflist --domain storage-2
Interface Type Source Model MAC
-------------------------------------------------------
- network ovs-network-1 virtio 52:54:00:a7:fe:27注意:控制节点上有两个接口,但是在这种情况下并不重要,在此安装中,一个接口就足够了。现在我们正在准备一个json文件。我们需要指定执行配置所通过的端口的罂粟地址,节点参数,为其指定名称并指示如何获取ipmi:
{
"nodes":[
{
"mac":[
"52:54:00:20:a2:2f"
],
"cpu":"8",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"control-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7001"
},
{
"mac":[
"52:54:00:79:0b:cb"
],
"cpu":"4",
"memory":"16384",
"disk":"160",
"arch":"x86_64",
"name":"storage-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7002"
},
{
"mac":[
"52:54:00:a7:fe:27"
],
"cpu":"4",
"memory":"16384",
"disk":"160",
"arch":"x86_64",
"name":"storage-2",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7003"
},
{
"mac":[
"52:54:00:98:e9:d6"
],
"cpu":"12",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"compute-1",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7004"
},
{
"mac":[
"52:54:00:6a:ea:be"
],
"cpu":"12",
"memory":"32768",
"disk":"60",
"arch":"x86_64",
"name":"compute-2",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"admin",
"pm_addr":"192.168.255.200",
"pm_port":"7005"
}
]
}现在,我们需要准备具有讽刺意味的图像。为此,请通过wget下载并安装:
(undercloud) [stack@undercloud ~]$ sudo wget https://images.rdoproject.org/queens/delorean/current-tripleo-rdo/overcloud-full.tar --no-check-certificate
(undercloud) [stack@undercloud ~]$ sudo wget https://images.rdoproject.org/queens/delorean/current-tripleo-rdo/ironic-python-agent.tar --no-check-certificate
(undercloud) [stack@undercloud ~]$ ls -lh
total 1.9G
-rw-r--r--. 1 stack stack 447M Aug 14 10:26 ironic-python-agent.tar
-rw-r--r--. 1 stack stack 1.5G Aug 14 10:26 overcloud-full.tar
-rw-------. 1 stack stack 916 Aug 13 23:10 stackrc
-rw-r--r--. 1 stack stack 15K Aug 13 22:50 undercloud.conf
-rw-------. 1 stack stack 2.0K Aug 13 22:50 undercloud-passwords.conf
(undercloud) [stack@undercloud ~]$ mkdir images/
(undercloud) [stack@undercloud ~]$ tar -xpvf ironic-python-agent.tar -C ~/images/
ironic-python-agent.initramfs
ironic-python-agent.kernel
(undercloud) [stack@undercloud ~]$ tar -xpvf overcloud-full.tar -C ~/images/
overcloud-full.qcow2
overcloud-full.initrd
overcloud-full.vmlinuz
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ ls -lh images/
total 1.9G
-rw-rw-r--. 1 stack stack 441M Aug 12 17:24 ironic-python-agent.initramfs
-rwxr-xr-x. 1 stack stack 6.5M Aug 12 17:24 ironic-python-agent.kernel
-rw-r--r--. 1 stack stack 53M Aug 12 17:14 overcloud-full.initrd
-rw-r--r--. 1 stack stack 1.4G Aug 12 17:18 overcloud-full.qcow2
-rwxr-xr-x. 1 stack stack 6.5M Aug 12 17:14 overcloud-full.vmlinuz
(undercloud) [stack@undercloud ~]$将图像上传到undercloud:
(undercloud) [stack@undercloud ~]$ openstack overcloud image upload --image-path ~/images/
Image "overcloud-full-vmlinuz" was uploaded.
+--------------------------------------+------------------------+-------------+---------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+------------------------+-------------+---------+--------+
| c2553770-3e0f-4750-b46b-138855b5c385 | overcloud-full-vmlinuz | aki | 6761064 | active |
+--------------------------------------+------------------------+-------------+---------+--------+
Image "overcloud-full-initrd" was uploaded.
+--------------------------------------+-----------------------+-------------+----------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+-----------------------+-------------+----------+--------+
| 949984e0-4932-4e71-af43-d67a38c3dc89 | overcloud-full-initrd | ari | 55183045 | active |
+--------------------------------------+-----------------------+-------------+----------+--------+
Image "overcloud-full" was uploaded.
+--------------------------------------+----------------+-------------+------------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+----------------+-------------+------------+--------+
| a2f2096d-c9d7-429a-b866-c7543c02a380 | overcloud-full | qcow2 | 1487475712 | active |
+--------------------------------------+----------------+-------------+------------+--------+
Image "bm-deploy-kernel" was uploaded.
+--------------------------------------+------------------+-------------+---------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+------------------+-------------+---------+--------+
| e413aa78-e38f-404c-bbaf-93e582a8e67f | bm-deploy-kernel | aki | 6761064 | active |
+--------------------------------------+------------------+-------------+---------+--------+
Image "bm-deploy-ramdisk" was uploaded.
+--------------------------------------+-------------------+-------------+-----------+--------+
| ID | Name | Disk Format | Size | Status |
+--------------------------------------+-------------------+-------------+-----------+--------+
| 5cf3aba4-0e50-45d3-929f-27f025dd6ce3 | bm-deploy-ramdisk | ari | 461759376 | active |
+--------------------------------------+-------------------+-------------+-----------+--------+
(undercloud) [stack@undercloud ~]$检查是否已加载所有图像
(undercloud) [stack@undercloud ~]$ openstack image list
+--------------------------------------+------------------------+--------+
| ID | Name | Status |
+--------------------------------------+------------------------+--------+
| e413aa78-e38f-404c-bbaf-93e582a8e67f | bm-deploy-kernel | active |
| 5cf3aba4-0e50-45d3-929f-27f025dd6ce3 | bm-deploy-ramdisk | active |
| a2f2096d-c9d7-429a-b866-c7543c02a380 | overcloud-full | active |
| 949984e0-4932-4e71-af43-d67a38c3dc89 | overcloud-full-initrd | active |
| c2553770-3e0f-4750-b46b-138855b5c385 | overcloud-full-vmlinuz | active |
+--------------------------------------+------------------------+--------+
(undercloud) [stack@undercloud ~]$再说一遍-您需要添加DNS服务器:
(undercloud) [stack@undercloud ~]$ openstack subnet list
+--------------------------------------+-----------------+--------------------------------------+------------------+
| ID | Name | Network | Subnet |
+--------------------------------------+-----------------+--------------------------------------+------------------+
| f45dea46-4066-42aa-a3c4-6f84b8120cab | ctlplane-subnet | 6ca013dc-41c2-42d8-9d69-542afad53392 | 192.168.255.0/24 |
+--------------------------------------+-----------------+--------------------------------------+------------------+
(undercloud) [stack@undercloud ~]$ openstack subnet show f45dea46-4066-42aa-a3c4-6f84b8120cab
+-------------------+-----------------------------------------------------------+
| Field | Value |
+-------------------+-----------------------------------------------------------+
| allocation_pools | 192.168.255.11-192.168.255.50 |
| cidr | 192.168.255.0/24 |
| created_at | 2020-08-13T20:10:37Z |
| description | |
| dns_nameservers | |
| enable_dhcp | True |
| gateway_ip | 192.168.255.1 |
| host_routes | destination='169.254.169.254/32', gateway='192.168.255.1' |
| id | f45dea46-4066-42aa-a3c4-6f84b8120cab |
| ip_version | 4 |
| ipv6_address_mode | None |
| ipv6_ra_mode | None |
| name | ctlplane-subnet |
| network_id | 6ca013dc-41c2-42d8-9d69-542afad53392 |
| prefix_length | None |
| project_id | a844ccfcdb2745b198dde3e1b28c40a3 |
| revision_number | 0 |
| segment_id | None |
| service_types | |
| subnetpool_id | None |
| tags | |
| updated_at | 2020-08-13T20:10:37Z |
+-------------------+-----------------------------------------------------------+
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ neutron subnet-update f45dea46-4066-42aa-a3c4-6f84b8120cab --dns-nameserver 192.168.255.253
neutron CLI is deprecated and will be removed in the future. Use openstack CLI instead.
Updated subnet: f45dea46-4066-42aa-a3c4-6f84b8120cab
(undercloud) [stack@undercloud ~]$现在我们可以发出内省命令:
(undercloud) [stack@undercloud ~]$ openstack overcloud node import --introspect --provide inspection.json
Started Mistral Workflow tripleo.baremetal.v1.register_or_update. Execution ID: d57456a3-d8ed-479c-9a90-dff7c752d0ec
Waiting for messages on queue 'tripleo' with no timeout.
5 node(s) successfully moved to the "manageable" state.
Successfully registered node UUID b4b2cf4a-b7ca-4095-af13-cc83be21c4f5
Successfully registered node UUID b89a72a3-6bb7-429a-93bc-48393d225838
Successfully registered node UUID 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e
Successfully registered node UUID bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8
Successfully registered node UUID 766ab623-464c-423d-a529-d9afb69d1167
Waiting for introspection to finish...
Started Mistral Workflow tripleo.baremetal.v1.introspect. Execution ID: 6b4d08ae-94c3-4a10-ab63-7634ec198a79
Waiting for messages on queue 'tripleo' with no timeout.
Introspection of node b89a72a3-6bb7-429a-93bc-48393d225838 completed. Status:SUCCESS. Errors:None
Introspection of node 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e completed. Status:SUCCESS. Errors:None
Introspection of node bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 completed. Status:SUCCESS. Errors:None
Introspection of node 766ab623-464c-423d-a529-d9afb69d1167 completed. Status:SUCCESS. Errors:None
Introspection of node b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 completed. Status:SUCCESS. Errors:None
Successfully introspected 5 node(s).
Started Mistral Workflow tripleo.baremetal.v1.provide. Execution ID: f5594736-edcf-4927-a8a0-2a7bf806a59a
Waiting for messages on queue 'tripleo' with no timeout.
5 node(s) successfully moved to the "available" state.
(undercloud) [stack@undercloud ~]$从输出中可以看到,一切都结束了而没有错误。让我们检查所有节点是否可用:
(undercloud) [stack@undercloud ~]$ openstack baremetal node list
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
| UUID | Name | Instance UUID | Power State | Provisioning State | Maintenance |
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | None | power off | available | False |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | None | power off | available | False |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | None | power off | available | False |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | None | power off | available | False |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | None | power off | available | False |
+--------------------------------------+-----------+---------------+-------------+--------------------+-------------+
(undercloud) [stack@undercloud ~]$ 如果节点处于其他状态(通常是可管理的),则出了点问题,您需要查看日志,找出发生原因。请记住,在这种情况下,我们正在使用虚拟化,并且可能存在与使用虚拟机或vbmc相关的错误。
接下来,我们需要指定哪个节点将执行哪个功能-即,指示该节点将使用的配置文件:
(undercloud) [stack@undercloud ~]$ openstack overcloud profiles list
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| Node UUID | Node Name | Provision State | Current Profile | Possible Profiles |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | available | None | |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | available | None | |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | available | None | |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | available | None | |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | available | None | |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
(undercloud) [stack@undercloud ~]$ openstack flavor list
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
| ID | Name | RAM | Disk | Ephemeral | VCPUs | Is Public |
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
| 168af640-7f40-42c7-91b2-989abc5c5d8f | swift-storage | 4096 | 40 | 0 | 1 | True |
| 52148d1b-492e-48b4-b5fc-772849dd1b78 | baremetal | 4096 | 40 | 0 | 1 | True |
| 56e66542-ae60-416d-863e-0cb192d01b09 | control | 4096 | 40 | 0 | 1 | True |
| af6796e1-d0c4-4bfe-898c-532be194f7ac | block-storage | 4096 | 40 | 0 | 1 | True |
| e4d50fdd-0034-446b-b72c-9da19b16c2df | compute | 4096 | 40 | 0 | 1 | True |
| fc2e3acf-7fca-4901-9eee-4a4d6ef0265d | ceph-storage | 4096 | 40 | 0 | 1 | True |
+--------------------------------------+---------------+------+------+-----------+-------+-----------+
(undercloud) [stack@undercloud ~]$我们指示每个节点的配置文件:
openstack baremetal node set --property capabilities='profile:control,boot_option:local' b4b2cf4a-b7ca-4095-af13-cc83be21c4f5
openstack baremetal node set --property capabilities='profile:ceph-storage,boot_option:local' b89a72a3-6bb7-429a-93bc-48393d225838
openstack baremetal node set --property capabilities='profile:ceph-storage,boot_option:local' 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e
openstack baremetal node set --property capabilities='profile:compute,boot_option:local' bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8
openstack baremetal node set --property capabilities='profile:compute,boot_option:local' 766ab623-464c-423d-a529-d9afb69d1167我们检查是否已正确完成所有操作:
(undercloud) [stack@undercloud ~]$ openstack overcloud profiles list
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| Node UUID | Node Name | Provision State | Current Profile | Possible Profiles |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
| b4b2cf4a-b7ca-4095-af13-cc83be21c4f5 | control-1 | available | control | |
| b89a72a3-6bb7-429a-93bc-48393d225838 | storage-1 | available | ceph-storage | |
| 20a16cc0-e0ce-4d88-8f17-eb0ce7b4d69e | storage-2 | available | ceph-storage | |
| bfc1eb98-a17a-4a70-b0b6-6c0db0eac8e8 | compute-1 | available | compute | |
| 766ab623-464c-423d-a529-d9afb69d1167 | compute-2 | available | compute | |
+--------------------------------------+-----------+-----------------+-----------------+-------------------+
(undercloud) [stack@undercloud ~]$如果一切正确,我们给出命令来部署overcloud:
openstack overcloud deploy --templates --control-scale 1 --compute-scale 2 --ceph-storage-scale 2 --control-flavor control --compute-flavor compute --ceph-storage-flavor ceph-storage --libvirt-type qemu在实际安装中,自然会使用自定义模板,在我们的情况下,这将使过程变得非常复杂,因为有必要解释模板中的每个编辑。如前所述,即使是简单的安装也足以让我们了解其工作原理。
注意:在这种情况下,需要使用--libvirt-type qemu变量,因为我们将使用嵌套虚拟化。否则,您将不会运行虚拟机。
现在您大约有一个小时,甚至更多(取决于硬件的功能),并且您只能希望在此之后看到以下铭文:
2020-08-14 08:39:21Z [overcloud]: CREATE_COMPLETE Stack CREATE completed successfully
Stack overcloud CREATE_COMPLETE
Host 192.168.255.21 not found in /home/stack/.ssh/known_hosts
Started Mistral Workflow tripleo.deployment.v1.get_horizon_url. Execution ID: fcb996cd-6a19-482b-b755-2ca0c08069a9
Overcloud Endpoint: http://192.168.255.21:5000/
Overcloud Horizon Dashboard URL: http://192.168.255.21:80/dashboard
Overcloud rc file: /home/stack/overcloudrc
Overcloud Deployed
(undercloud) [stack@undercloud ~]$现在您有了openstack的几乎完整版本,您可以在其中学习,进行实验等。
让我们检查一下一切是否正常。在用户的主目录堆栈中,有两个文件-一个文件stackrc(用于管理undercloud)和另一个文件overcloudrc(用于管理overcloud)。这些文件必须指定为源,因为它们包含身份验证所需的信息。
(undercloud) [stack@undercloud ~]$ openstack server list
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
| fd7d36f4-ce87-4b9a-93b0-add2957792de | overcloud-controller-0 | ACTIVE | ctlplane=192.168.255.15 | overcloud-full | control |
| edc77778-8972-475e-a541-ff40eb944197 | overcloud-novacompute-1 | ACTIVE | ctlplane=192.168.255.26 | overcloud-full | compute |
| 5448ce01-f05f-47ca-950a-ced14892c0d4 | overcloud-cephstorage-1 | ACTIVE | ctlplane=192.168.255.34 | overcloud-full | ceph-storage |
| ce6d862f-4bdf-4ba3-b711-7217915364d7 | overcloud-novacompute-0 | ACTIVE | ctlplane=192.168.255.19 | overcloud-full | compute |
| e4507bd5-6f96-4b12-9cc0-6924709da59e | overcloud-cephstorage-0 | ACTIVE | ctlplane=192.168.255.44 | overcloud-full | ceph-storage |
+--------------------------------------+-------------------------+--------+-------------------------+----------------+--------------+
(undercloud) [stack@undercloud ~]$
(undercloud) [stack@undercloud ~]$ source overcloudrc
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$ openstack project list
+----------------------------------+---------+
| ID | Name |
+----------------------------------+---------+
| 4eed7d0f06544625857d51cd77c5bd4c | admin |
| ee1c68758bde41eaa9912c81dc67dad8 | service |
+----------------------------------+---------+
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$
(overcloud) [stack@undercloud ~]$ openstack network agent list
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| ID | Agent Type | Host | Availability Zone | Alive | State | Binary |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
| 10495de9-ba4b-41fe-b30a-b90ec3f8728b | Open vSwitch agent | overcloud-novacompute-1.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| 1515ad4a-5972-46c3-af5f-e5446dff7ac7 | L3 agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-l3-agent |
| 322e62ca-1e5a-479e-9a96-4f26d09abdd7 | DHCP agent | overcloud-controller-0.localdomain | nova | :-) | UP | neutron-dhcp-agent |
| 9c1de2f9-bac5-400e-998d-4360f04fc533 | Open vSwitch agent | overcloud-novacompute-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| d99c5657-851e-4d3c-bef6-f1e3bb1acfb0 | Open vSwitch agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-openvswitch-agent |
| ff85fae6-5543-45fb-a301-19c57b62d836 | Metadata agent | overcloud-controller-0.localdomain | None | :-) | UP | neutron-metadata-agent |
+--------------------------------------+--------------------+-------------------------------------+-------------------+-------+-------+---------------------------+
(overcloud) [stack@undercloud ~]$我的安装仍然需要轻轻一点-在控制器上添加路由,因为我正在使用的机器位于不同的网络上。为此,请转到heat-admin帐户下的control-1并编写路径
(undercloud) [stack@undercloud ~]$ ssh heat-admin@192.168.255.15
Last login: Fri Aug 14 09:47:40 2020 from 192.168.255.1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ip route add 10.169.0.0/16 via 192.168.255.254好了,现在您可以进入地平线了。所有信息-地址,登录名和密码-都在文件/ home / stack / overcloudrc中。最终方案如下所示:

顺便说一下,在我们的安装中,机器的地址是通过DHCP发出的,如您所见,它们是“随机”发出的。如果需要,您可以在模板中硬编码应在部署期间将哪个地址附加到哪台计算机。
虚拟机之间的流量如何流动?
在本文中,我们将考虑传递流量的三个选项
- 一个L2网络中的一台虚拟机管理程序上的两台机器
- 一个L2网络中不同虚拟机管理程序上的两台机器
- 不同网络上的两台计算机(在网络之间生根)
下次将考虑通过外部网络使用浮动地址以及分布式路由访问外部世界的案例,目前我们将重点关注内部流量。
为了进行测试,我们将以下方案放在一起:
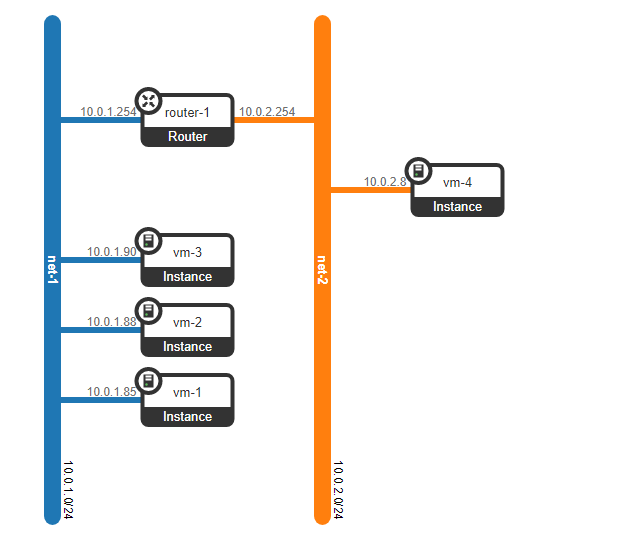
我们已经创建了4个虚拟机-一个L2网络中的3个虚拟机-net-1,而net-2网络中的另外1个虚拟机
(overcloud) [stack@undercloud ~]$ nova list --tenant 5e18ce8ec9594e00b155485f19895e6c
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
| ID | Name | Tenant ID | Status | Task State | Power State | Networks |
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
| f53b37b5-2204-46cc-aef0-dba84bf970c0 | vm-1 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-1=10.0.1.85 |
| fc8b6722-0231-49b0-b2fa-041115bef34a | vm-2 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-1=10.0.1.88 |
| 3cd74455-b9b7-467a-abe3-bd6ff765c83c | vm-3 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-1=10.0.1.90 |
| 7e836338-6772-46b0-9950-f7f06dbe91a8 | vm-4 | 5e18ce8ec9594e00b155485f19895e6c | ACTIVE | - | Running | net-2=10.0.2.8 |
+--------------------------------------+------+----------------------------------+--------+------------+-------------+-----------------+
(overcloud) [stack@undercloud ~]$ 让我们看看创建的机器位于哪些虚拟机管理程序上:
(overcloud) [stack@undercloud ~]$ nova show f53b37b5-2204-46cc-aef0-dba84bf970c0 | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-1 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-0.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000001 |(overcloud) [stack@undercloud ~]$ nova show fc8b6722-0231-49b0-b2fa-041115bef34a | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-2 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-1.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000002 |(overcloud) [stack@undercloud ~]$ nova show 3cd74455-b9b7-467a-abe3-bd6ff765c83c | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-3 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-0.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000003 |(overcloud) [stack@undercloud ~]$ nova show 7e836338-6772-46b0-9950-f7f06dbe91a8 | egrep "hypervisor_hostname|instance_name|hostname"
| OS-EXT-SRV-ATTR:hostname | vm-4 |
| OS-EXT-SRV-ATTR:hypervisor_hostname | overcloud-novacompute-1.localdomain |
| OS-EXT-SRV-ATTR:instance_name | instance-00000004 |(overcloud)[stack @ undercloud〜] $
机器vm-1和vm-3位于compute-0上,机器vm-2和vm-4位于节点compute-1上。
此外,已创建虚拟路由器以启用指定网络之间的路由:
(overcloud) [stack@undercloud ~]$ openstack router list --project 5e18ce8ec9594e00b155485f19895e6c
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
| ID | Name | Status | State | Distributed | HA | Project |
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
| 0a4d2420-4b9c-46bd-aec1-86a1ef299abe | router-1 | ACTIVE | UP | False | False | 5e18ce8ec9594e00b155485f19895e6c |
+--------------------------------------+----------+--------+-------+-------------+-------+----------------------------------+
(overcloud) [stack@undercloud ~]$ 路由器具有两个虚拟端口,它们充当网络的网关:
(overcloud) [stack@undercloud ~]$ openstack router show 0a4d2420-4b9c-46bd-aec1-86a1ef299abe | grep interface
| interfaces_info | [{"subnet_id": "2529ad1a-6b97-49cd-8515-cbdcbe5e3daa", "ip_address": "10.0.1.254", "port_id": "0c52b15f-8fcc-4801-bf52-7dacc72a5201"}, {"subnet_id": "335552dd-b35b-456b-9df0-5aac36a3ca13", "ip_address": "10.0.2.254", "port_id": "92fa49b5-5406-499f-ab8d-ddf28cc1a76c"}] |
(overcloud) [stack@undercloud ~]$ 但是在查看流量如何运行之前,让我们先了解一下当前在控制节点(也是网络节点)和计算节点上的资源。让我们从一个计算节点开始。
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-vsctl show
[heat-admin@overcloud-novacompute-0 ~]$ sudo sudo ovs-appctl dpif/show
system@ovs-system: hit:3 missed:3
br-ex:
br-ex 65534/1: (internal)
phy-br-ex 1/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/2: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
br-tun:
br-tun 65534/3: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff0f 3/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.15)
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$目前,该节点具有三个ovs桥-br-int,br-tun和br-ex。如我们所见,它们之间有一组接口。为了便于理解,我们将所有这些接口放在图表上,看看会发生什么。

从将VxLAN隧道引发的地址中,可以看到一个隧道在compute-1(192.168.255.26)上引发,第二个隧道则在control-1(192.168.255.15)上。但是最有趣的是br-ex没有物理接口,如果您查看配置了哪些流,您会发现此桥目前只能丢弃流量。
[heat-admin@overcloud-novacompute-0 ~]$ ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 192.168.255.19 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe6a:eabe prefixlen 64 scopeid 0x20<link>
ether 52:54:00:6a:ea:be txqueuelen 1000 (Ethernet)
RX packets 2909669 bytes 4608201000 (4.2 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1821057 bytes 349198520 (333.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-novacompute-0 ~]$ 从输出中可以看到,地址直接固定到物理端口,而不是虚拟网桥接口。
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-ex
port VLAN MAC Age
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-ex
cookie=0x9169eae8f7fe5bb2, duration=216686.864s, table=0, n_packets=303, n_bytes=26035, priority=2,in_port="phy-br-ex" actions=drop
cookie=0x9169eae8f7fe5bb2, duration=216686.887s, table=0, n_packets=0, n_bytes=0, priority=0 actions=NORMAL
[heat-admin@overcloud-novacompute-0 ~]$ 根据第一个规则,必须丢弃来自phy-br-ex端口的所有内容。
实际上,除了从该接口(与br-int的连接)之外,没有其他流量可到达该网桥,并且从丢弃的角度判断,BUM流量已经到达网桥。
也就是说,来自该节点的流量只能通过VxLAN隧道,而不能通过其他通道。但是,如果您打开DVR,情况将会改变,但是我们将在另一时间处理它。当使用网络隔离(例如使用VLAN)时,第0个VLAN中将没有一个L3接口,而是多个接口。但是,VxLAN流量将以相同的方式从节点流出,但也封装在某种专用的vlan中。
我们找出计算节点,然后转到控制节点。
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl dpif/show
system@ovs-system: hit:930491 missed:825
br-ex:
br-ex 65534/1: (internal)
eth0 1/2: (system)
phy-br-ex 2/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/3: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
br-tun:
br-tun 65534/4: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff13 3/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.19)
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$实际上,我们可以说一切都一样,但是ip地址不再在物理接口上,而是在虚拟网桥上。这样做是由于该端口是流量将通过它流向外界的端口。
[heat-admin@overcloud-controller-0 ~]$ ifconfig br-ex
br-ex: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 192.168.255.15 netmask 255.255.255.0 broadcast 192.168.255.255
inet6 fe80::5054:ff:fe20:a22f prefixlen 64 scopeid 0x20<link>
ether 52:54:00:20:a2:2f txqueuelen 1000 (Ethernet)
RX packets 803859 bytes 1732616116 (1.6 GiB)
RX errors 0 dropped 63 overruns 0 frame 0
TX packets 808475 bytes 121652156 (116.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-ex
port VLAN MAC Age
3 100 28:c0:da:00:4d:d3 35
1 0 28:c0:da:00:4d:d3 35
1 0 52:54:00:98:e9:d6 0
LOCAL 0 52:54:00:20:a2:2f 0
1 0 52:54:00:2c:08:9e 0
3 100 52:54:00:20:a2:2f 0
1 0 52:54:00:6a:ea:be 0
[heat-admin@overcloud-controller-0 ~]$ 此端口绑定到br-ex桥,并且由于上面没有vlan标签,因此该端口是允许所有vlan进入的中继端口,现在流量不带标签就流到外面,如上面输出中的vlan-id 0所示。
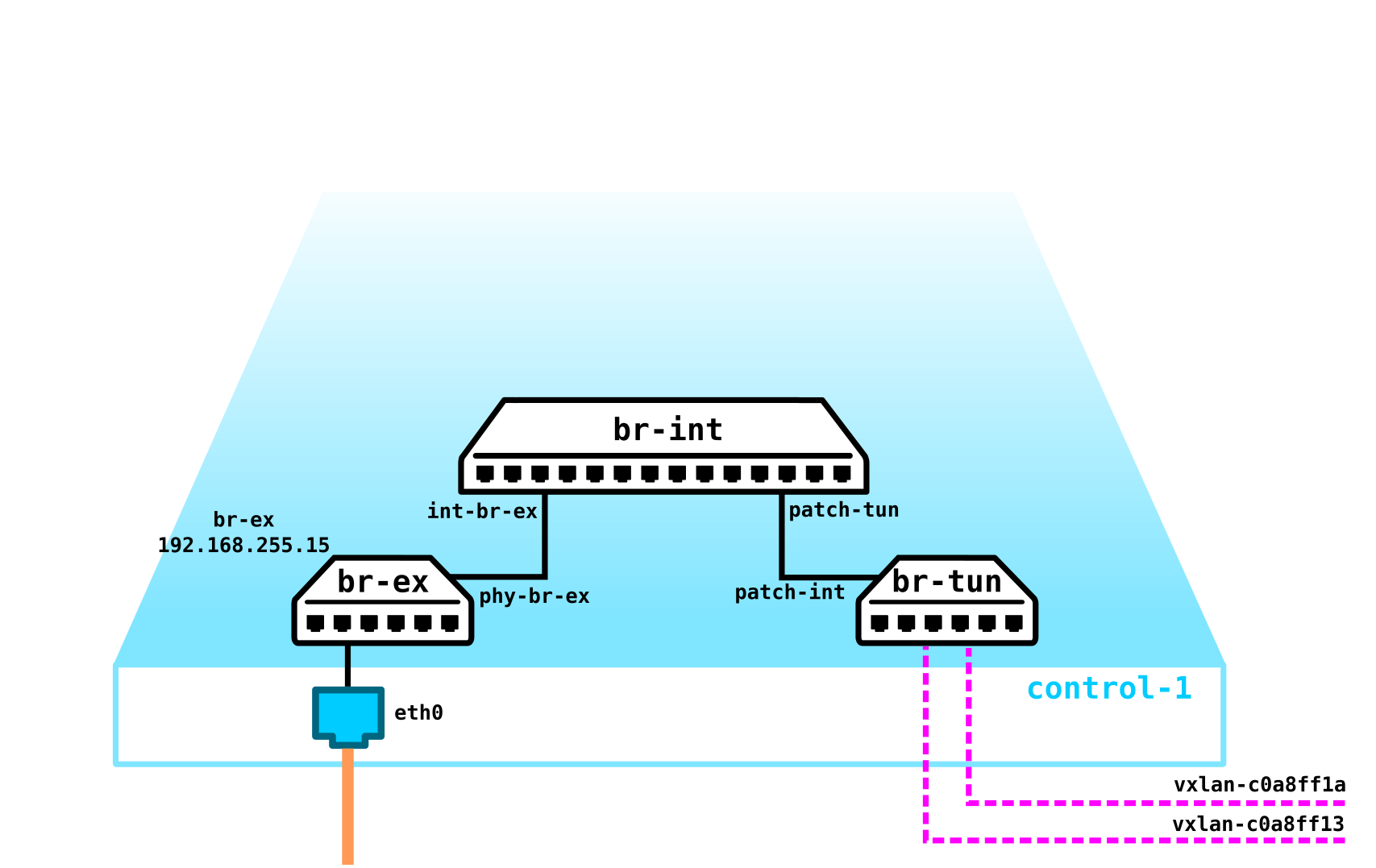
此刻,其他所有内容都类似于计算节点-相同的网桥,相同的隧道通往两个计算节点。
在本文中,我们将不考虑存储节点,但是为了理解,必须说这些节点的网络部分太平庸了。在我们的例子中,只有一个物理端口(eth0)挂有ip地址,仅此而已。没有VxLAN隧道,隧道桥等-根本没有ov,因为其中没有任何意义。使用网络隔离时-该节点将具有两个接口(物理端口,波特或只有两个VLAN-没关系-取决于您要的是什么)-一个用于管理,第二个用于流量(写入VM磁盘,从磁盘等)。
我们弄清楚了在没有任何服务的情况下节点上的内容。现在让我们启动4个虚拟机,看看上面描述的方案是如何变化的-我们应该有端口,虚拟路由器等。
到目前为止,我们的网络如下所示:
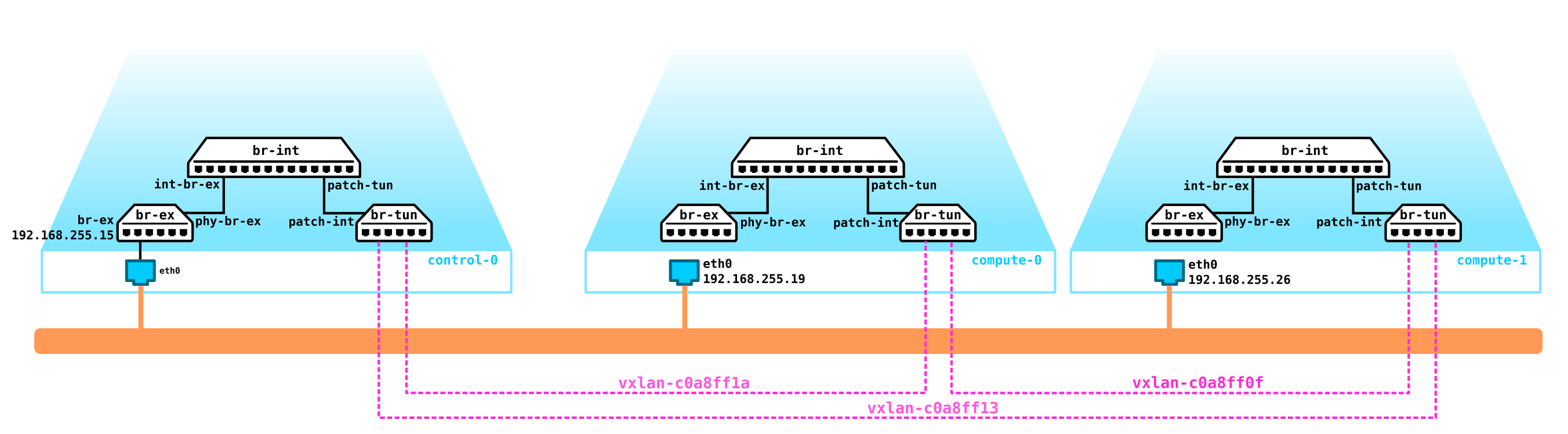
每台计算机上都有两个虚拟机。让我们看看compute-0如何包含所有内容。
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh list
Id Name State
----------------------------------------------------
1 instance-00000001 running
3 instance-00000003 running
[heat-admin@overcloud-novacompute-0 ~]$ 该机器只有一个虚拟接口-tap95d96a75-a0:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Type Source Model MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
该接口着眼于linux桥:
[heat-admin@overcloud-novacompute-0 ~]$ sudo brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242904c92a8 no
qbr5bd37136-47 8000.5e4e05841423 no qvb5bd37136-47
tap5bd37136-47
qbr95d96a75-a0 8000.de076cb850f6 no qvb95d96a75-a0
tap95d96a75-a0
[heat-admin@overcloud-novacompute-0 ~]$ 从输出中可以看到,旅中只有两个接口-tap95d96a75-a0和qvb95d96a75-a0。
值得详细介绍一下OpenStack中的虚拟网络设备的类型:如您所知,如果在旅中有一个qvb95d96a75-a0端口,即vEth对,那么它的对应端口在哪里,在逻辑上应称为qvo95d96a75-a0。让我们看看OVS上有哪些端口。
vtap-连接到实例(VM)的虚拟接口
qbr-Linux网桥
qvb和qvo-连接到Linux网桥和Open vSwitch网桥的vEth对
br-int,br-tun, br-vlan-打开vSwitch桥接
patch-,int-br-,phy-br--打开vSwitch补丁接口连接桥接
qg,qr,ha,fg,sg-打开vSwitch端口,虚拟设备使用该端口连接到OVS
[heat-admin@overcloud-novacompute-0 ~]$ sudo sudo ovs-appctl dpif/show
system@ovs-system: hit:526 missed:91
br-ex:
br-ex 65534/1: (internal)
phy-br-ex 1/none: (patch: peer=int-br-ex)
br-int:
br-int 65534/2: (internal)
int-br-ex 1/none: (patch: peer=phy-br-ex)
patch-tun 2/none: (patch: peer=patch-int)
qvo5bd37136-47 6/6: (system)
qvo95d96a75-a0 3/5: (system)
br-tun:
br-tun 65534/3: (internal)
patch-int 1/none: (patch: peer=patch-tun)
vxlan-c0a8ff0f 3/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.15)
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$ 如我们所见,端口位于br-int中。Br-int充当终止虚拟机端口的交换机。除qvo95d96a75-a0外,输出还显示端口qvo5bd37136-47。这是第二个虚拟机的端口。结果,我们的方案现在看起来像这样:

细心的读者应该立即关注的问题-为什么虚拟机端口和OVS端口之间的linux桥?事实是,安全组用于保护机器,无非就是iptables。OVS不适用于iptables,因此发明了这样的“拐杖”。但是,它已经超越了自己的功能-在新版本中被conntrack取代。
也就是说,该方案最终看起来像这样:

一个L2网络中的一台虚拟机管理程序上的两台机器
由于这两个VM处于同一L2网络中,并且位于同一虚拟机管理程序上,因此它们之间的流量将通过br-int从逻辑上讲进入本地,因为两台计算机都位于同一VLAN中:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Type Source Model MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000003
Interface Type Source Model MAC
-------------------------------------------------------
tap5bd37136-47 bridge qbr5bd37136-47 virtio fa:16:3e:83:ad:a4
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int
port VLAN MAC Age
6 1 fa:16:3e:83:ad:a4 0
3 1 fa:16:3e:44:98:20 0
[heat-admin@overcloud-novacompute-0 ~]$ 同一L2网络中不同虚拟机管理程序上的两台计算机
现在,让我们看一下流量如何在同一L2网络中但位于不同虚拟机管理程序上的两台计算机之间流动。老实说,什么都不会改变很多,只是虚拟机管理程序之间的流量将通过vxlan隧道。让我们来看一个例子。
我们将在它们之间监视流量的虚拟机的地址:
[heat-admin@overcloud-novacompute-0 ~]$ sudo virsh domiflist instance-00000001
Interface Type Source Model MAC
-------------------------------------------------------
tap95d96a75-a0 bridge qbr95d96a75-a0 virtio fa:16:3e:44:98:20
[heat-admin@overcloud-novacompute-0 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo virsh domiflist instance-00000002
Interface Type Source Model MAC
-------------------------------------------------------
tape7e23f1b-07 bridge qbre7e23f1b-07 virtio fa:16:3e:72:ad:53
[heat-admin@overcloud-novacompute-1 ~]$ 我们在br-int的compute-0处查看转发表:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:72:ad:53
2 1 fa:16:3e:72:ad:53 1
[heat-admin@overcloud-novacompute-0 ~]流量应该流向端口2-让我们看看该端口是什么:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:7e:7f:28:1f:bd:54
2(patch-tun): addr:0a:bd:07:69:58:d9
3(qvo95d96a75-a0): addr:ea:50:9a:3d:69:58
6(qvo5bd37136-47): addr:9a:d1:03:50:3d:96
LOCAL(br-int): addr:1a:0f:53:97:b1:49
[heat-admin@overcloud-novacompute-0 ~]$这是patch-tun-即br-tun的接口。让我们看看br-tun上的数据包发生了什么:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:72:ad:53
cookie=0x8759a56536b67a8e, duration=1387.959s, table=20, n_packets=1460, n_bytes=138880, hard_timeout=300, idle_age=0, hard_age=0, priority=1,vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:72:ad:53 actions=load:0->NXM_OF_VLAN_TCI[],load:0x16->NXM_NX_TUN_ID[],output:2
[heat-admin@overcloud-novacompute-0 ~]$ 数据包打包到VxLAN中并发送到端口2。让我们看一下端口2的位置:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:b2:d1:f8:21:96:66
2(vxlan-c0a8ff1a): addr:be:64:1f:75:78:a7
3(vxlan-c0a8ff0f): addr:76:6f:b9:3c:3f:1c
LOCAL(br-tun): addr:a2:5b:6d:4f:94:47
[heat-admin@overcloud-novacompute-0 ~]$这是compute-1上的vxlan隧道:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl dpif/show | egrep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/4: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.19, remote_ip=192.168.255.26)
[heat-admin@overcloud-novacompute-0 ~]$转到compute-1,然后查看该软件包接下来将发生什么:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:44:98:20
2 1 fa:16:3e:44:98:20 1
[heat-admin@overcloud-novacompute-1 ~]$ Mac位于compute-1的br-int转发表中,从上面的输出中可以看到,它可以通过端口2看到,端口2是通向br-tun的端口:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:8a:d7:f9:ad:8c:1d
2(patch-tun): addr:46:cc:40:bd:20:da
3(qvoe7e23f1b-07): addr:12:78:2e:34:6a:c7
4(qvo3210e8ec-c0): addr:7a:5f:59:75:40:85
LOCAL(br-int): addr:e2:27:b2:ed:14:46好吧,那么我们看一下compute-1的br-int中有一个目标mac:
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:72:ad:53
3 1 fa:16:3e:72:ad:53 0
[heat-admin@overcloud-novacompute-1 ~]$ 也就是说,接收到的数据包将飞到端口3,实例00000003虚拟机已位于端口3后面。
在虚拟基础架构上部署Openstack进行学习的好处在于,我们可以轻松捕获虚拟机管理程序之间的流量并查看发生了什么。这是我们现在要执行的操作,在vnet端口上向tcp-0运行tcpdump:
[root@hp-gen9 bormoglotx]# tcpdump -vvv -i vnet3
tcpdump: listening on vnet3, link-type EN10MB (Ethernet), capture size 262144 bytes
*****************omitted*******************
04:39:04.583459 IP (tos 0x0, ttl 64, id 16868, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.19.39096 > 192.168.255.26.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 8012, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.1.88: ICMP echo request, id 5634, seq 16, length 64
04:39:04.584449 IP (tos 0x0, ttl 64, id 35181, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.26.speedtrace-disc > 192.168.255.19.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 59124, offset 0, flags [none], proto ICMP (1), length 84)
10.0.1.88 > 10.0.1.85: ICMP echo reply, id 5634, seq 16, length 64
*****************omitted*******************第一行显示地址为10.0.1.85的修补程序转到地址10.0.1.88(ICMP流量),并将其包装在带有vni 22的VxLAN数据包中,并且该数据包从主机192.168.255.19(计算为0)到主机192.168.255.26(计算-1)。我们可以检查VNI是否与ovs中指定的VNI匹配。
让我们回到此行操作=加载:0-> NXM_OF_VLAN_TCI [],加载:0x16-> NXM_NX_TUN_ID [],输出:2。0x16是十六进制的vni。让我们将此数字转换为第十个系统:
16 = 6*16^0+1*16^1 = 6+16 = 22也就是说,vni对应于现实。
第二行显示了返程流量,那么,在此处对其进行解释是没有意义的,并且一切都很清楚。
不同网络上的两台计算机(网络之间的路由)
今天的最后一种情况是使用虚拟路由器在一个项目内的网络之间进行路由。我们正在考虑没有DVR的情况(我们将在另一篇文章中介绍),因此路由发生在网络节点上。在我们的情况下,网络节点不是单独的实体,而是位于控制节点上。
首先,让我们看一下路由的工作原理:
$ ping 10.0.2.8
PING 10.0.2.8 (10.0.2.8): 56 data bytes
64 bytes from 10.0.2.8: seq=0 ttl=63 time=7.727 ms
64 bytes from 10.0.2.8: seq=1 ttl=63 time=3.832 ms
^C
--- 10.0.2.8 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 3.832/5.779/7.727 ms由于在这种情况下,数据包必须到达网关并路由到那里,因此我们需要找出网关的MAC地址,为此,我们将在实例中查看ARP表:
$ arp
host-10-0-1-254.openstacklocal (10.0.1.254) at fa:16:3e:c4:64:70 [ether] on eth0
host-10-0-1-1.openstacklocal (10.0.1.1) at fa:16:3e:e6:2c:5c [ether] on eth0
host-10-0-1-90.openstacklocal (10.0.1.90) at fa:16:3e:83:ad:a4 [ether] on eth0
host-10-0-1-88.openstacklocal (10.0.1.88) at fa:16:3e:72:ad:53 [ether] on eth0现在,让我们看看应该将流量与目的地(10.0.1.254)发送到哪里fa:16:3e:c4:64:70:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-appctl fdb/show br-int | egrep fa:16:3e:c4:64:70
2 1 fa:16:3e:c4:64:70 0
[heat-admin@overcloud-novacompute-0 ~]$ 我们看一下端口2的位置:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:7e:7f:28:1f:bd:54
2(patch-tun): addr:0a:bd:07:69:58:d9
3(qvo95d96a75-a0): addr:ea:50:9a:3d:69:58
6(qvo5bd37136-47): addr:9a:d1:03:50:3d:96
LOCAL(br-int): addr:1a:0f:53:97:b1:49
[heat-admin@overcloud-novacompute-0 ~]$ 一切都是合乎逻辑的,流量一直流向br-tun。让我们看看它将包装在哪个vxlan隧道中:
[heat-admin@overcloud-novacompute-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:c4:64:70
cookie=0x8759a56536b67a8e, duration=3514.566s, table=20, n_packets=3368, n_bytes=317072, hard_timeout=300, idle_age=0, hard_age=0, priority=1,vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:c4:64:70 actions=load:0->NXM_OF_VLAN_TCI[],load:0x16->NXM_NX_TUN_ID[],output:3
[heat-admin@overcloud-novacompute-0 ~]$ 第三个端口是vxlan隧道:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:a2:69:00:c5:fa:ba
2(vxlan-c0a8ff1a): addr:86:f0:ce:d0:e8:ea
3(vxlan-c0a8ff13): addr:72:aa:73:2c:2e:5b
LOCAL(br-tun): addr:a6:cb:cd:72:1c:45
[heat-admin@overcloud-controller-0 ~]$ 查看控制节点:
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$ 流量到达了控制节点,因此我们需要去控制节点,看看路由将如何发生。
您还记得,内部的控制节点看起来完全像计算节点-相同的三个网桥,只有br-ex有一个物理端口,节点可以通过该端口向外部发送流量。实例创建更改了计算节点上的配置-将Linux网桥,iptables和接口添加到了节点。网络和虚拟路由器的创建也在控制节点的配置上留下了自己的印记。
因此,很明显,网关罂粟地址应该在控制节点上的br-int转发表中。让我们检查一下它的存在和外观:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:c4:64:70
5 1 fa:16:3e:c4:64:70 1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:2e:58:b6:db:d5:de
2(patch-tun): addr:06:41:90:f0:9e:56
3(tapca25a97e-64): addr:fa:16:3e:e6:2c:5c
4(tap22015e46-0b): addr:fa:16:3e:76:c2:11
5(qr-0c52b15f-8f): addr:fa:16:3e:c4:64:70
6(qr-92fa49b5-54): addr:fa:16:3e:80:13:72
LOCAL(br-int): addr:06:de:5d:ed:44:44
[heat-admin@overcloud-controller-0 ~]$ 从端口qr-0c52b15f-8f可以看到Mac。如果返回到Openstack中的虚拟端口列表,则此端口类型用于将各种虚拟设备连接到OVS。更确切地说,qr是通向虚拟路由器的端口,它表示为名称空间。
让我们看看服务器上有哪些名称空间:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns
qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe (id: 2)
qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 (id: 1)
qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 (id: 0)
[heat-admin@overcloud-controller-0 ~]$ 多达三份。但是从名称来看,您可以猜测每个名称的目的。稍后我们将返回ID为0和1的实例,现在,我们对名称空间qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe感兴趣:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe ip route
10.0.1.0/24 dev qr-0c52b15f-8f proto kernel scope link src 10.0.1.254
10.0.2.0/24 dev qr-92fa49b5-54 proto kernel scope link src 10.0.2.254
[heat-admin@overcloud-controller-0 ~]$ 这个名称空间有两个我们之前创建的内部名称空间。两个虚拟端口都添加到br-int中。让我们检查端口qr-0c52b15f-8f的批量地址,因为根据目标罂粟地址判断,流量正好进入了此接口。
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe ifconfig qr-0c52b15f-8f
qr-0c52b15f-8f: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.0.1.254 netmask 255.255.255.0 broadcast 10.0.1.255
inet6 fe80::f816:3eff:fec4:6470 prefixlen 64 scopeid 0x20<link>
ether fa:16:3e:c4:64:70 txqueuelen 1000 (Ethernet)
RX packets 5356 bytes 427305 (417.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5195 bytes 490603 (479.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[heat-admin@overcloud-controller-0 ~]$ 也就是说,在这种情况下,所有操作均根据标准路由定律进行。由于流量是针对主机10.0.2.8的,因此它必须通过第二个接口qr-92fa49b5-54并通过vxlan隧道到达计算节点:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe arp
Address HWtype HWaddress Flags Mask Iface
10.0.1.88 ether fa:16:3e:72:ad:53 C qr-0c52b15f-8f
10.0.1.90 ether fa:16:3e:83:ad:a4 C qr-0c52b15f-8f
10.0.2.8 ether fa:16:3e:6c:ad:9c C qr-92fa49b5-54
10.0.2.42 ether fa:16:3e:f5:0b:29 C qr-92fa49b5-54
10.0.1.85 ether fa:16:3e:44:98:20 C qr-0c52b15f-8f
[heat-admin@overcloud-controller-0 ~]$ 一切都是合乎逻辑的,不足为奇。我们从br-int中主机10.0.2.8的罂粟地址的可见位置进行查看:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:6c:ad:9c
2 2 fa:16:3e:6c:ad:9c 1
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:2e:58:b6:db:d5:de
2(patch-tun): addr:06:41:90:f0:9e:56
3(tapca25a97e-64): addr:fa:16:3e:e6:2c:5c
4(tap22015e46-0b): addr:fa:16:3e:76:c2:11
5(qr-0c52b15f-8f): addr:fa:16:3e:c4:64:70
6(qr-92fa49b5-54): addr:fa:16:3e:80:13:72
LOCAL(br-int): addr:06:de:5d:ed:44:44
[heat-admin@overcloud-controller-0 ~]$ 正如预期的那样,流量流向br-tun,让我们看看流量流向哪个隧道:
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl dump-flows br-tun | grep fa:16:3e:6c:ad:9c
cookie=0x2ab04bf27114410e, duration=5346.829s, table=20, n_packets=5248, n_bytes=498512, hard_timeout=300, idle_age=0, hard_age=0, priority=1,vlan_tci=0x0002/0x0fff,dl_dst=fa:16:3e:6c:ad:9c actions=load:0->NXM_OF_VLAN_TCI[],load:0x63->NXM_NX_TUN_ID[],output:2
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo ovs-ofctl show br-tun | grep addr
1(patch-int): addr:a2:69:00:c5:fa:ba
2(vxlan-c0a8ff1a): addr:86:f0:ce:d0:e8:ea
3(vxlan-c0a8ff13): addr:72:aa:73:2c:2e:5b
LOCAL(br-tun): addr:a6:cb:cd:72:1c:45
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$ 流量在compute-1之前进入隧道。好吧,在compute-1上,一切都很简单-从数据包br-tun到br-int,再从那里到虚拟机的接口:
[heat-admin@overcloud-controller-0 ~]$ sudo sudo ovs-appctl dpif/show | grep vxlan-c0a8ff1a
vxlan-c0a8ff1a 2/5: (vxlan: egress_pkt_mark=0, key=flow, local_ip=192.168.255.15, remote_ip=192.168.255.26)
[heat-admin@overcloud-controller-0 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-appctl fdb/show br-int | grep fa:16:3e:6c:ad:9c
4 2 fa:16:3e:6c:ad:9c 1
[heat-admin@overcloud-novacompute-1 ~]$ sudo ovs-ofctl show br-int | grep addr
1(int-br-ex): addr:8a:d7:f9:ad:8c:1d
2(patch-tun): addr:46:cc:40:bd:20:da
3(qvoe7e23f1b-07): addr:12:78:2e:34:6a:c7
4(qvo3210e8ec-c0): addr:7a:5f:59:75:40:85
LOCAL(br-int): addr:e2:27:b2:ed:14:46
[heat-admin@overcloud-novacompute-1 ~]$ 让我们检查一下这确实是正确的接口:
[heat-admin@overcloud-novacompute-1 ~]$ brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02429c001e1c no
qbr3210e8ec-c0 8000.ea27f45358be no qvb3210e8ec-c0
tap3210e8ec-c0
qbre7e23f1b-07 8000.b26ac0eded8a no qvbe7e23f1b-07
tape7e23f1b-07
[heat-admin@overcloud-novacompute-1 ~]$
[heat-admin@overcloud-novacompute-1 ~]$ sudo virsh domiflist instance-00000004
Interface Type Source Model MAC
-------------------------------------------------------
tap3210e8ec-c0 bridge qbr3210e8ec-c0 virtio fa:16:3e:6c:ad:9c
[heat-admin@overcloud-novacompute-1 ~]$实际上,我们一路走遍了整个程序包。我认为您注意到流量通过不同的vxlan隧道并通过不同的VNI退出。让我们看一下它们是哪种VNI,然后在节点的控制端口上收集转储,并确保流量完全按照上述说明进行。
因此,到compute-0的隧道具有以下操作=加载:0-> NXM_OF_VLAN_TCI [],加载:0x16-> NXM_NX_TUN_ID [],输出:3。将0x16转换为十进制表示法:
0x16 = 6*16^0+1*16^1 = 6+16 = 22到compute-1的隧道具有以下VNI:操作=负载:0-> NXM_OF_VLAN_TCI [],负载:0x63-> NXM_NX_TUN_ID [],输出:2。以十进制表示法转换0x63:
0x63 = 3*16^0+6*16^1 = 3+96 = 99好吧,现在让我们看看转储:
[root@hp-gen9 bormoglotx]# tcpdump -vvv -i vnet4
tcpdump: listening on vnet4, link-type EN10MB (Ethernet), capture size 262144 bytes
*****************omitted*******************
04:35:18.709949 IP (tos 0x0, ttl 64, id 48650, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.19.41591 > 192.168.255.15.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 64, id 49042, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.2.8: ICMP echo request, id 5378, seq 9, length 64
04:35:18.710159 IP (tos 0x0, ttl 64, id 23360, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.15.38983 > 192.168.255.26.4789: [no cksum] VXLAN, flags [I] (0x08), vni 99
IP (tos 0x0, ttl 63, id 49042, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.1.85 > 10.0.2.8: ICMP echo request, id 5378, seq 9, length 64
04:35:18.711292 IP (tos 0x0, ttl 64, id 43596, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.26.42588 > 192.168.255.15.4789: [no cksum] VXLAN, flags [I] (0x08), vni 99
IP (tos 0x0, ttl 64, id 55103, offset 0, flags [none], proto ICMP (1), length 84)
10.0.2.8 > 10.0.1.85: ICMP echo reply, id 5378, seq 9, length 64
04:35:18.711531 IP (tos 0x0, ttl 64, id 8555, offset 0, flags [DF], proto UDP (17), length 134)
192.168.255.15.38983 > 192.168.255.19.4789: [no cksum] VXLAN, flags [I] (0x08), vni 22
IP (tos 0x0, ttl 63, id 55103, offset 0, flags [none], proto ICMP (1), length 84)
10.0.2.8 > 10.0.1.85: ICMP echo reply, id 5378, seq 9, length 64
*****************omitted*******************第一个数据包是带有vni 22的从主机192.168.255.19(compute-0)到主机192.168.255.15(control-1)的vxlan数据包,其中的ICMP数据包从主机10.0.1.85打包到主机10.0.2.8。如上所述,vni对应于我们在输出中看到的。
第二个数据包是从主机192.168.255.15(control-1)到具有vni 99的主机192.168.255.26(compute-1)的vxlan数据包,其中的ICMP数据包从主机10.0.1.85打包到主机10.0.2.8。如上所述,vni对应于我们在输出中看到的。
接下来的两个数据包是从10.0.2.8而不是10.0.1.85返回的流量。
也就是说,结果,我们得到了以下控制节点方案:

像一切一样?我们忘记了两个名称空间:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns
qrouter-0a4d2420-4b9c-46bd-aec1-86a1ef299abe (id: 2)
qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 (id: 1)
qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 (id: 0)
[heat-admin@overcloud-controller-0 ~]$ 当我们谈论云平台的体系结构时,如果计算机自动从DHCP服务器接收地址,那就太好了。这是我们两个网络10.0.1.0/24和10.0.2.0/24的两个DHCP服务器。
让我们检查一下是否是如此。此名称空间中只有一个地址-10.0.1.1-DHCP服务器本身的地址,它也包含在br-int中:
[heat-admin@overcloud-controller-0 ~]$ sudo ip netns exec qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2 ifconfig
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 1 bytes 28 (28.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1 bytes 28 (28.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
tapca25a97e-64: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.0.1.1 netmask 255.255.255.0 broadcast 10.0.1.255
inet6 fe80::f816:3eff:fee6:2c5c prefixlen 64 scopeid 0x20<link>
ether fa:16:3e:e6:2c:5c txqueuelen 1000 (Ethernet)
RX packets 129 bytes 9372 (9.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 49 bytes 6154 (6.0 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0让我们看看控制节点上名称中是否包含qdhcp-67a3798c-32c0-4c18-8502-2531247e3cc2的进程:
[heat-admin@overcloud-controller-0 ~]$ ps -aux | egrep qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638
root 640420 0.0 0.0 4220 348 ? Ss 11:31 0:00 dumb-init --single-child -- ip netns exec qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638 /usr/sbin/dnsmasq -k --no-hosts --no-resolv --pid-file=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/pid --dhcp-hostsfile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/host --addn-hosts=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/addn_hosts --dhcp-optsfile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/opts --dhcp-leasefile=/var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/leases --dhcp-match=set:ipxe,175 --local-service --bind-dynamic --dhcp-range=set:subnet-335552dd-b35b-456b-9df0-5aac36a3ca13,10.0.2.0,static,255.255.255.0,86400s --dhcp-option-force=option:mtu,1450 --dhcp-lease-max=256 --conf-file= --domain=openstacklocal
heat-ad+ 951620 0.0 0.0 112944 980 pts/0 S+ 18:50 0:00 grep -E --color=auto qdhcp-7d541e74-1c36-4e1d-a7c4-0968c8dbc638
[heat-admin@overcloud-controller-0 ~]$ 有一个这样的过程,根据上面输出中显示的信息,例如,我们可以查看当前的租金:
[heat-admin@overcloud-controller-0 ~]$ cat /var/lib/neutron/dhcp/7d541e74-1c36-4e1d-a7c4-0968c8dbc638/leases
1597492111 fa:16:3e:6c:ad:9c 10.0.2.8 host-10-0-2-8 01:fa:16:3e:6c:ad:9c
1597491115 fa:16:3e:76:c2:11 10.0.2.1 host-10-0-2-1 *
[heat-admin@overcloud-controller-0 ~]$结果,我们在控制节点上获得了这样的一组服务:

好吧,请记住-只是-4台计算机,2个内部网络和一个虚拟路由器...我们现在没有外部网络,没有大量不同项目,每个项目都有自己的网络(重叠) ),然后关闭了分布式路由器,但最后在测试台中只有一个控制节点(为了容错,必须有一个法定数量的三个节点)。在商业中,一切都“稍微”复杂一点是合乎逻辑的,但是在这个简单的示例中,我们理解了它应该如何工作-当然,如果您拥有3或300个名称空间,那很重要,但是从整个结构的操作角度来看,什么都不会改变太多……但是到目前为止不要坚持某种供应商SDN。但这是一个完全不同的故事。
我希望这很有趣。如果有好的评论/补充,或者我公开撒谎的地方(我是一个人,我的意见永远是主观的)-写出需要纠正/添加的内容-我们将纠正/添加所有内容。
总而言之,我想谈一谈将Openstack(原始版本和供应商版本)与VMWare的云解决方案进行比较-在过去的两年中,我经常被问到这个问题,老实说,我对此感到厌倦,但是仍然。我认为这两种解决方案很难比较,但是我们可以明确地说这两种解决方案都有缺点,并且在选择一种解决方案时,必须权衡利弊。
如果OpenStack是社区驱动的解决方案,那么VMWare有权只做它想做的事情(阅读-对其有利可图),这是合乎逻辑的-因为它是一家用来从客户那里赚钱的商业公司。但是有一个庞大而繁琐的BUT-例如,您可以从Nokia退出OpenStack,然后从Juniper(Contrail Cloud)切换到解决方案,但您将很难脱离VMWare。对我来说,这两个解决方案看起来像这样-Openstack(供应商)是一个放置在其中的简单笼子,但是您有钥匙,可以随时退出。 VMWare是一个金色的笼子,所有者拥有笼子的钥匙,这将使您付出高昂的代价。
我既不竞选第一个产品也不选择第二个产品-您选择所需的东西。但是,如果我有这样的选择,那么我会选择两种解决方案-用于IT云的VMWare(低负载,便捷的管理),来自某个供应商的OpenStack(诺基亚和Juniper提供非常好的交钥匙解决方案)-电信云。我不会将Openstack用于纯IT-就像用大炮射击麻雀一样,但是除了冗余之外,我看不到使用它的任何禁忌症。但是,从外部看,在电信中使用VMWare(如何在福特Raptor上运输瓦砾)很漂亮,但是驾驶员必须进行10次而不是一次。
我认为,VMWare的最大缺点是它完全封闭-公司不会向您提供有关其工作方式的任何信息,例如vSAN或虚拟机管理程序核心中的内容-它根本无法盈利-也就是说,您永远不会成为VMWare的专家-没有供应商的支持,您就注定要失败(我经常遇到被平庸的问题所困扰的VMWare专家)。对我来说,VMWare购买的是带锁引擎盖的汽车-是的,也许您有可以更换正时皮带的专家,但是只有向您出售此解决方案的人才能打开引擎盖。我个人不喜欢无法适应的解决方案。您会说,您可能不必去做内幕。是的,这是可能的,但是当您需要从20-30个虚拟机,40-50个网络,其中一半要出门,另一半则要求SR-IOV加速,否则您将需要更多的此类机器-否则性能将不足。
还有其他观点,因此,由您决定选择什么,最重要的是,您要对以后的选择负责。这只是我的看法-曾经看过并触摸过至少4种产品的人-诺基亚,瞻博网络,红帽和VMWare。也就是说,我有一些要比较的地方。