因此,有两种类型的Web机器人-合法的和恶意的。合法的包括搜索引擎,RSS阅读器。恶意Web bot的示例包括漏洞扫描程序,抓取工具,垃圾邮件发送者,DDoS攻击bot和支付卡欺诈木马。一旦确定了网络bot的类型,便可以对其应用各种策略。如果漫游器是合法的,则可以降低其对服务器的请求优先级或降低对某些资源的访问级别。如果某个漫游器被识别为恶意,则可以将其阻止或将其发送到沙箱以进行进一步分析。检测,分析和分类Web bot很重要,因为它们可能会造成危害,例如泄露关键业务数据。而且,由于多达66%的网络bot流量恰好是Web机器人的流量,因此它将减少服务器的负载并减少流量中的所谓噪音。恶意流量。
现有方法
有多种检测网络流量中的Web bot的技术,范围从限制对主机的请求频率,将IP地址列入黑名单,分析User-Agent HTTP标头的值,对设备进行指纹识别以及最后实施CAPTCHA,以及使用网络行为分析机器学习。
但是,使用各种知识库和威胁情报来收集有关站点的信誉信息并保持黑名单为最新状态,这是一个昂贵且费力的过程,因此,在使用代理服务器时,建议不要这样做。
对User-Agent字段进行近似近似的分析似乎很有用,但没有什么可以阻止Web bot或用户将此字段的值更改为有效字段,伪装成普通用户并为浏览器或合法bot使用有效的User-Agent。我们称这种网络机器人为假冒者。使用各种设备指纹(跟踪鼠标移动或检查客户端渲染HTML页面的能力)使我们能够突出显示更难检测的模仿人类行为的Web机器人,例如,请求其他页面(样式文件,图标等),解析JavaScript。这种方法基于客户端代码注入,这通常是不可接受的,因为插入其他脚本时出错会破坏Web应用程序。
应该注意的是,网络机器人也可以在线检测到:会话将被实时评估。关于这种问题的表述的描述可以在Cabri等人[1]以及Zi Chu [2]的著作中找到。另一种方法是仅在会话结束后进行分析。显然,最有趣的是第一个选项,它使您可以更快地做出决策。
拟议的方法
我们使用机器学习技术和ELK(Elasticsearch Logstash Kibana)技术堆栈来识别和分类Web机器人。研究的对象是HTTP会话。会话是在固定的时间间隔内来自一个节点的一系列请求(IP地址和HTTP请求中的User-Agent字段的唯一值)。 Derek和Gohale使用30分钟的间隔来定义会话边界[3]。 Iliu等人认为这种方法不能保证真正的会话唯一性,但是仍然可以接受。由于可以更改User-Agent字段,因此可能会出现比实际更多的会话。因此,Nikiforakis及其合作者根据是否支持ActiveX,是否启用Flash,屏幕分辨率,操作系统版本,提出了更多的微调。
如果User-Agent字段动态变化,我们将在形成单独的会话时考虑一个可接受的错误。为了识别机器人会话,我们将建立一个清晰的二进制分类模型并使用:
- 网络机器人(标签机器人)生成的自动网络活动;
- 人为产生的网络活动(标记为人)。
要按活动类型对网络机器人进行分类,让我们从下表中构建一个多类模型。
| 名称 | 描述 | 标签 | 示例 |
|---|---|---|---|
| 爬行者 | 网络机器人
收集 网页 |
履带式 | SemrushBot,
360Spider, Heritrix |
| 社交网络 | 各种
社交网络的网络机器人 |
社交网络 | LinkedInBot,
WhatsApp Bot, Facebook bot |
| Rss读者 | -,
RSS |
rss | Feedfetcher,
Feed Reader, SimplePie |
| -
|
search_engines | Googlebot, BingBot,
YandexBot |
|
| -,
|
libs_tools | Curl, Wget,
python-requests, scrapy |
|
| - | bots | ||
| ,
User-Agent |
unknown |
我们还将解决模型在线培训的问题。
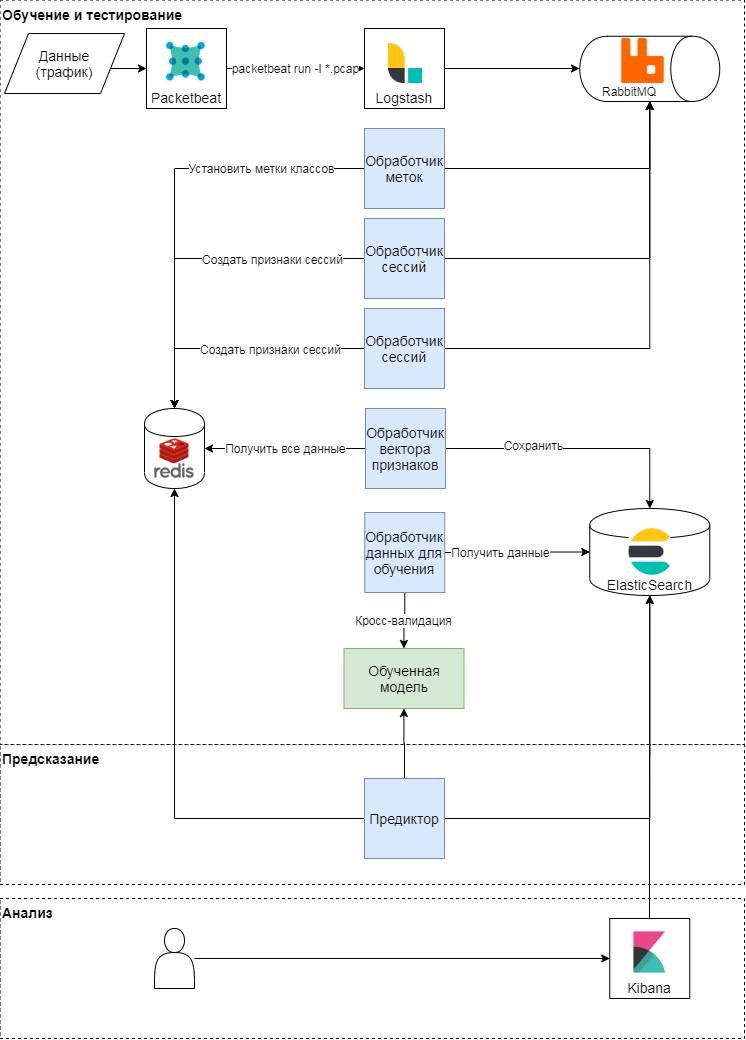
拟议方法的概念方案
该方法分为三个阶段:培训和测试,预测,结果分析。让我们更详细地考虑前两个。从概念上讲,该方法遵循学习和应用机器学习模型的经典模式。首先,确定质量指标和分类属性。之后,形成特征向量,并进行一系列实验(各种交叉检查)以验证模型并选择超参数。在最后阶段,选择最佳模型,并在递延样本上检查模型的质量。
模型训练与测试
packetbeat模块用于解析流量。原始HTTP请求被发送到logstash,在该日志中,使用Celery术语中的Ruby脚本生成任务。它们每个都以会话标识符,请求时间,请求正文和标头进行操作。会话标识符(关键字)-来自IP地址和用户代理的串联的哈希函数值。在此阶段,将创建两种类型的任务:
- 在为会话建立特征向量时,
- 通过基于请求文本和User-Agent标记类。
这些任务被发送到队列,消息处理程序在其中执行它们。因此,贴标程序处理程序使用专家判断来执行标记类的任务,并基于所使用的User-Agent打开来自浏览器服务的数据。结果被写入键值存储。会话处理器生成特征向量(请参见下表),并将每个键的结果写入键值存储中,并设置键寿命(TTL)。
| 标志 | 描述 |
|---|---|
| 伦 | 每个会话的请求数 |
| len_pages | 页面中每个会话的请求数
(URI以.htm,.html,.php, .asp,.aspx,.jsp结尾) |
| len_static_request |
静态页面中每个会话的请求数 |
| len_sec | 会话时间(以秒为单位) |
| len_unique_uri | 每个会话
包含唯一URI的请求数 |
| headers_cnt | 每个会话的标头数 |
| has_cookie | 是否有Cookie标头 |
| has_referer | 是否有Referer标头 |
| mean_time_page | 每会话平均每页时间 |
| mean_time_request | 每个会话每个请求的平均时间 |
| 卑鄙的人 | 每个会话的平均标头数 |
这就是形成特征矩阵并设置每个会话的目标类标签的方式。基于此矩阵,会进行模型的定期训练以及随后对超参数的选择。对于训练,我们使用了:逻辑回归,支持向量机,决策树,决策树上的梯度提升,随机森林算法。使用随机森林算法可获得最相关的结果。
预测
在流量解析期间,将更新键值存储中会话属性的向量:当会话中出现新请求时,将重新计算描述该请求的属性。例如,每次将新请求添加到会话时,都会计算会话中标头平均数目的符号(mean_headers)。Predictor将会话特征向量发送到模型,并将模型的响应写到Elasticsearch进行分析。
实验
我们在SecurityLab.ru门户的流量上测试了我们的解决方案。数据量-超过15 GB,超过130小时。会话数超过10,000,由于建议的模型使用了统计功能,因此包含少于10个请求的会话未参与培训和测试。我们使用经典的质量指标作为质量指标-每个班级的准确性,完整性和F量度。
测试网络机器人检测模型
我们将建立并评估一个二进制分类模型,即,我们将检测机器人,然后根据活动类型对其进行分类。基于五层分层交叉验证的结果(这正是所考虑的数据所需要的,因为存在严重的类不平衡),我们可以说构造的模型相当好(准确性和完整性-超过98%)能够区分人类用户和机器人的类别。
| 平均准确度 | 平均丰满度 | 平均F测度 | |
|---|---|---|---|
| 机器人 | 0.86 | 0.90 | 0.88 |
| 人的 | 0.98 | 0.97 | 0.97 |
下表显示了在延期样品上测试模型的结果。
| 准确性 | 完整性 | F测量 | 数
例 |
|
|---|---|---|---|---|
| 机器人 | 0.88 | 0.90 | 0.89 | 1816年 |
| 人的 | 0.98 | 0.98 | 0.98 | 9071 |
延迟采样中的质量指标值与模型验证期间的质量指标值大致重合,这意味着这些数据上的模型可以概括训练中获得的知识。
让我们考虑第一种错误。如果专业地标出这些数据,则误差矩阵将发生显着变化。这意味着在标记模型数据时会发生一些错误,但是模型仍然能够正确识别此类会话。
| 准确性 | 完整性 | F测量 | 数
例 |
|
|---|---|---|---|---|
| 机器人 | 0.93 | 0.92 | 0.93 | 2446 |
| 人的 | 0.98 | 0.98 | 0.98 | 8441 |
让我们看一个示例会话模仿者。它包含12个类似的查询。下图显示了其中一个请求。
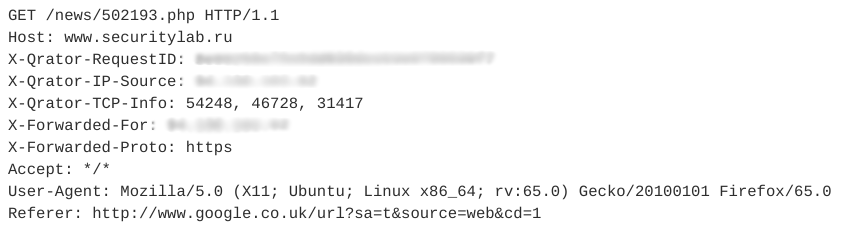
此会话中的所有后续请求都具有相同的结构,只是URI不同。
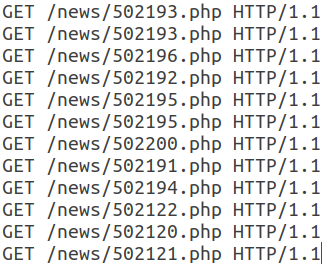
请注意,此网络机器人使用有效的User-Agent,添加了通常非自动使用的Referer字段,并且每个会话的标头数量很少。另外,请求的时间特性(会话时间,每个请求的平均时间)使我们可以说此活动是自动的,属于RSS阅读器类别。在这种情况下,漫游器本身会伪装成普通用户。
测试网络机器人分类模型
要按活动类型对网络机器人进行分类,我们将使用与之前实验相同的数据和算法。下表显示了在延期样品上测试模型的结果。
| 准确性 | 完整性 | F测量 | 数
例 |
|
|---|---|---|---|---|
| 机器人 | 0.82 | 0.81 | 0.82 | 194 |
| 履带式 | 0.87 | 0.72 | 0.79 | 65 |
| libs_tools | 0.27 | 0.17 | 0.21 | 十八 |
| rss | 0.95 | 0.97 | 0.96 | 1823 |
| 搜索引擎 | 0.84 | 0.76 | 0.80 | 228 |
| 社交网络 | 0.80 | 0.79 | 0.84 | 73 |
| 未知 | 0.65 | 0.62 | 0.64 | 45 |
libs_tools类别的质量很低,但是用于评估的示例数量不足,因此我们无法谈论结果的正确性。应该进行第二系列的实验,以便根据更多数据对网络机器人进行分类。我们可以自信地说,当前的模型具有相当高的准确性和完整性,能够将RSS阅读器,搜索引擎和一般bot的类别分开。
根据对正在考虑的数据进行的这些实验,自动创建了超过22%的会话(总容量超过15 GB),其中87%与使用各种库和实用程序的通用机器人,未知机器人,RSS阅读器,网络机器人的活动有关。 ... 因此,如果按活动类型过滤Web bot的网络流量,则建议的方法将使使用的服务器资源上的负载减少至少9-10%。
在线测试网络机器人分类模型
该实验的本质如下:实时地,在解析流量之后,识别特征并为每个会话形成特征向量。定期将每个会话发送到模型进行预测,并保存其结果。
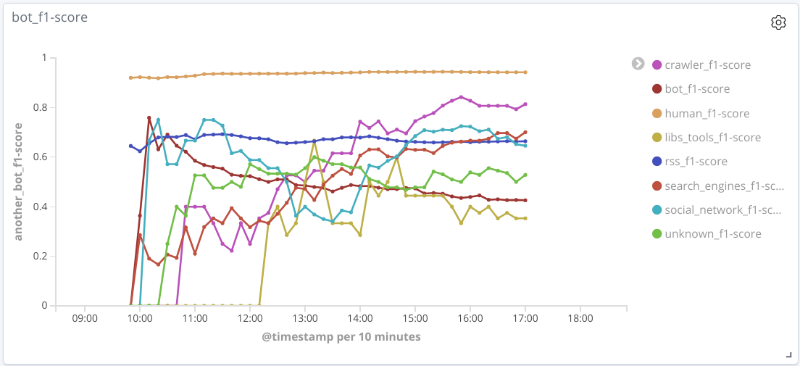
每个类别的模型随时间的F度量下
图说明了最有趣的类别的质量度量值随时间的变化。它们上的点的大小与特定时间的样本会话数有关。

搜索引擎类的

精确
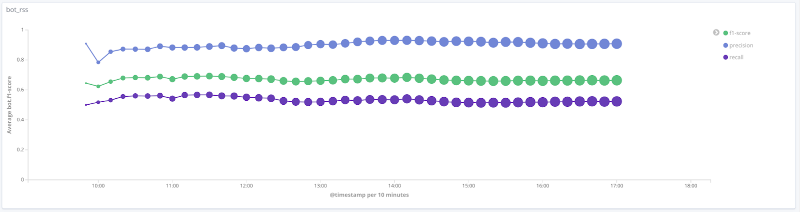
度,完整性,F度量rss类的

精确度,完整性,F度量rss类的精确度,完整性,F度量爬虫类的

精确度,完整性,F度量类人
对于所考虑数据的许多类别(人员,rss,search_engines),模型的质量是可以接受的(准确性和完整性超过80%)。对于爬虫类,此示例的会话次数增加且特征向量发生质的变化,模型的质量随之提高:完整性从33%增加到80%。由于libs_tools类的示例数量很少(少于50个),因此无法得出合理的结论。因此,无法确认阴性结果(质量差)。
主要成果和进一步发展
我们描述了一种使用机器学习算法和统计功能来检测和分类Web机器人的方法。在所考虑的数据上,所提出的二进制分类解决方案的平均准确性和完整性超过95%,这表明该方法是有前途的。对于某些类型的网络机器人,平均准确性和完整性约为80%。
构造模型的验证需要对会话进行真实评估。如前所述,当目标类具有正确的标记时,模型的性能将得到显着改善。不幸的是,现在很难自动构建这样的标记,并且您不得不求助于专家标记,这使机器学习模型的构建变得复杂,但是却允许您在数据中找到隐藏的模式。
为了进一步发展Web机器人的分类和检测问题,建议:
- 分配其他类别的机器人并重新培训,测试模型;
- 添加其他标志以对网络机器人进行分类。例如,添加一个robots.txt属性(二进制),该属性负责是否访问robots.txt页面,使您可以将一类网络机器人的平均F分数提高3%,而不会恶化其他类别的其他质量指标;
- 考虑到其他元功能和专家判断,对目标类别进行更正确的标记。
作者:Nikolay Lyfenko,Positive Technologies先进技术小组首席专家
资料来源
[1] Cabri A. et al. Online Web Bot Detection Using a Sequential Classification Approach. 2018 IEEE 20th International Conference on High Performance Computing and Communications.
[2] Chu Z., Gianvecchio S., Wang H. (2018) Bot or Human? A Behavior-Based Online Bot Detection System. In: Samarati P., Ray I., Ray I. (eds) From Database to Cyber Security. Lecture Notes in Computer Science, vol. 11170. Springer, Cham.
[3] Derek D., Gokhale S. An integrated method for real time and offline web robot detection. Expert Systems 33. 2016.
[4] Iliou Ch., et al. Towards a framework for detecting advanced Web bots. Proceedings of the 14th International Conference on Availability, Reliability and Security. 2019.
[5] Nikiforakis N., Kapravelos A., Joosen W., Kruegel C., Piessens F. and Vigna G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, 2013, pp. 541—555.
[2] Chu Z., Gianvecchio S., Wang H. (2018) Bot or Human? A Behavior-Based Online Bot Detection System. In: Samarati P., Ray I., Ray I. (eds) From Database to Cyber Security. Lecture Notes in Computer Science, vol. 11170. Springer, Cham.
[3] Derek D., Gokhale S. An integrated method for real time and offline web robot detection. Expert Systems 33. 2016.
[4] Iliou Ch., et al. Towards a framework for detecting advanced Web bots. Proceedings of the 14th International Conference on Availability, Reliability and Security. 2019.
[5] Nikiforakis N., Kapravelos A., Joosen W., Kruegel C., Piessens F. and Vigna G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, 2013, pp. 541—555.