
我从个人经验告诉我什么地方和什么时候派上用场。通过调查和论文,可以清楚地了解下一步的工作和在何处进行挖掘-但是在这里,我有一个非常主观的个人经历,也许您的情况与我完全不同。
为什么知道并能够处理查询语言很重要?从根本上讲,在数据科学中,有几个最重要的工作阶段,而第一个也是最重要的阶段(当然,没有它,什么都行不通!)是数据获取或检索。通常,某种形式的数据位于某个地方,您需要从那里“获取”它。
查询语言只允许您提取这些数据!今天我将向您介绍对我来说很方便的那些查询语言,并且我将告诉您显示在哪里以及如何准确地进行-为什么需要学习。
总共将有三个主要的数据查询类型块,我们将在本文中进行分析:
- 当谈论诸如关系代数或SQL之类的查询语言时,他们通常会理解``标准''查询语言。
- 脚本查询语言,例如pandas python技巧,numpy或shell脚本。
- 查询知识图和图数据库的语言。
这里编写的所有内容只是一种个人经验,它派上了用场,描述了情况和``为什么需要''-每个人都可以尝试类似的情况如何满足您,并在事先处理这些语言之前尝试为它们做准备。 (紧急)申请项目,甚至在需要他们的项目上申请。
“标准”查询语言
准确地说,标准查询语言在我们谈论查询时通常会想到它们。
关系代数
为什么今天需要关系代数?为了对为什么以某种方式安排查询语言并有意使用它们有一个好主意,您需要了解底层的核心。
什么是关系代数?
形式定义如下:关系代数是关系数据模型中关系操作的封闭系统。更人性化的是,这是对表进行操作的系统,因此结果也始终是表。
查看所有相关的业务在这个文章从哈布尔-在这里,我们描述为什么你需要知道和它派上用场。
做什么的?
您将开始了解一般会添加哪些查询语言以及特定查询语言的表达式后面进行了哪些操作-常常使您对查询语言中的内容和工作方式有更深入的了解。
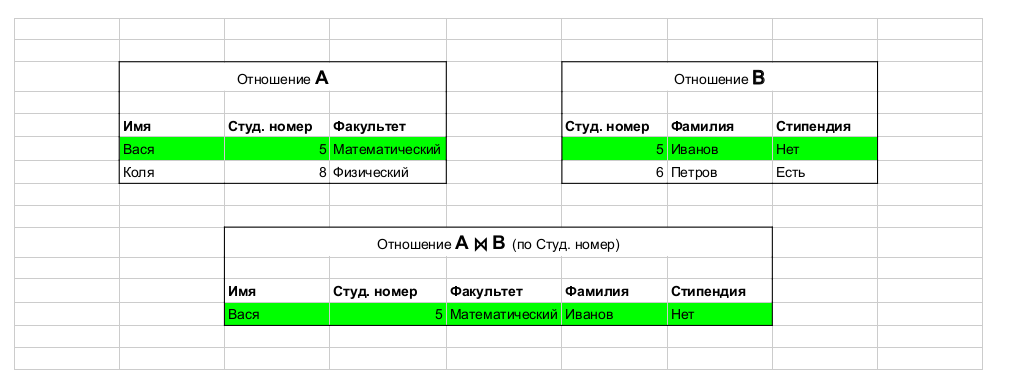
来自这个文章。示例操作:join,用于联接表。
学习资料:
斯坦福大学的入门课程。通常,关于关系代数和理论的材料很多-Coursera,Udacity。还有大量的在线资料,包括优质的学术课程。我的个人建议是很好地理解关系代数-这是基础。
的SQL

来自这个文章。
实际上,SQL是关系代数的实现-重要的警告是,SQL是声明性的!也就是说,使用关系代数语言编写查询,实际上是说出计数方式,但是使用SQL则指定要提取的内容,然后DBMS已经使用关系代数语言生成了(有效的)表达式(在Codd定理下,它们的对等关系为我们所知)。 ...
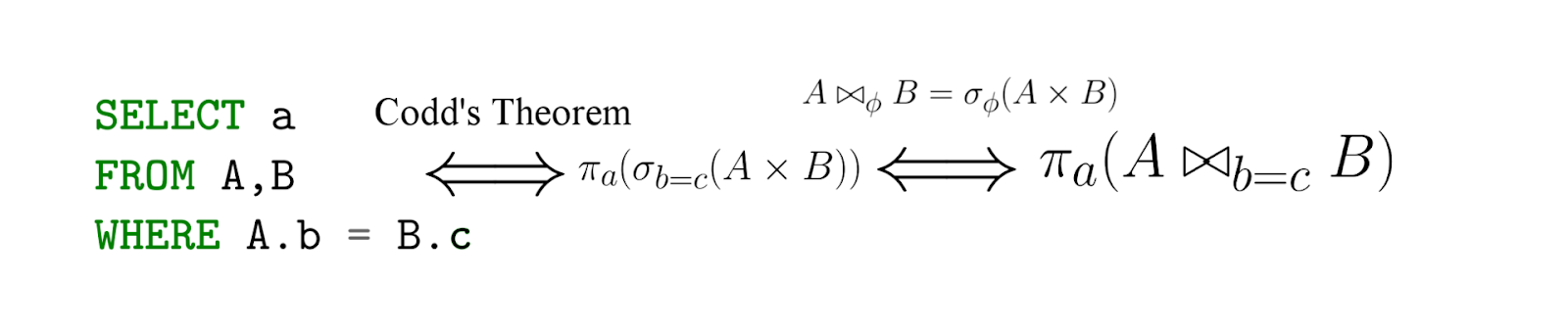
来自这个文章。
做什么的?
关系型DBMS:Oracle,Postgres,SQL Server等实际上仍然存在,并且与它们进行交互的可能性非常高,这意味着您将不得不阅读SQL(很有可能)或在其中写入SQL(也不太可能)。
阅读和学习什么
从上面的相同链接(在关系代数上),有大量的材料,例如本材料。
顺便说一下,什么是NoSQL?
“值得再次强调的是,“ NoSQL”一词具有完全自发性,并且背后没有公认的定义或科学机构。关于哈布雷的相应文章。
实际上,人们意识到不需要完整的关系模型来解决许多问题,尤其是对于那些以性能为基础且某些简单查询以聚合为主导的问题而言-快速读取度量并将其写入数据库,并且大多数功能都是关系性的至关重要。结果不仅是不必要的,而且是有害的-性能为什么要归一化,如果它将破坏我们最重要的事情(对于某些特定任务)?
此外,通常需要灵活的模式而不是经典关系模型的固定数学模式-当部署系统并快速开始工作,处理结果非常关键时,这将极大地简化应用程序开发-或者存储数据的模式和类型并不那么重要。
例如,我们正在创建一个专家系统,我们希望将信息与一些元信息一起存储在某个域中-我们可能不知道所有字段,并且为每条记录存储JSON是很老套的-这为我们提供了一个非常灵活的环境来扩展数据模型和快速迭代-因此,在这种情况下NoSQL的情况甚至更可取且可读。条目的示例(来自我的一个项目,其中NoSQL就在需要它的地方)。
{"en_wikipedia_url":"https://en.wikipedia.org/wiki/Johnny_Cash",
"ru_wikipedia_url":"https://ru.wikipedia.org/wiki/?curid=301643",
"ru_wiki_pagecount":149616,
"entity":[42775," ","ru"],
"en_wiki_pagecount":2338861}
您可以在此处阅读有关NoSQL的更多信息。
学习什么?
相反,您只需要善于分析您的任务,具有什么属性以及可以使用适合该描述的NoSQL系统-并已经研究了该系统。
脚本查询语言
乍一看,似乎Python与它有什么关系-它是一种编程语言,而与查询完全无关。

- 熊猫是数据科学的直接瑞士刀,其中发生了大量的数据转换,聚合等。
- Numpy是矢量计算,矩阵和线性代数。
- Scipy在这个软件包中是很多数学,尤其是统计数据。
- Jupyter实验室-大量探索性数据分析非常适合笔记本电脑-能够使用。
- 请求-联网。
- Pysparks在数据工程师中非常受欢迎,很可能仅由于它们的普及而需要与this或spark交互。
- *硒对于从站点和资源收集数据非常有用,有时根本没有其他方法可以获取数据。
我的最高提示:学习Python!
大熊猫
让我们以以下代码为例:
import pandas as pd
df = pd.read_csv(“data/dataset.csv”)
# Calculate and rename aggregations
all_together = (df[df[‘trip_type’] == “return”]
.groupby(['start_station_name','end_station_name'])\
.agg({'trip_duration_seconds': [np.size, np.mean, np.min, np.max]})\
.rename(columns={'size': 'num_trips',
'mean': 'avg_duration_seconds',
'amin': min_duration_seconds',
‘amax': 'max_duration_seconds'}))实际上,我们可以看到该代码适合经典的SQL模式。
SELECT start_station_name, end_station_name, count(trip_duration_seconds) as size, …..
FROM dataset
WHERE trip_type = ‘return’
GROUPBY start_station_name, end_station_name但是重要的是该代码是脚本和管道的一部分,实际上,我们将请求嵌入到Python管道中。在这种情况下,查询语言来自诸如Pandas或pySpark之类的库。
通常,在pySpark中,我们本着以下精神通过查询语言看到了类似的数据转换类型:
df.filter(df.trip_type = “return”)\
.groupby(“day”)\
.agg({duration: 'mean'})\
.sort()在何处阅读什么内容查找
有关Python本身的研究材料不是问题。网上有关于熊猫,pySpark的大量教程和关于Spark(以及DS本身)的课程。总的来说,这里的材料很棒,如果我不得不选择一个包装来重点关注的话,那当然是熊猫。DS + Python捆绑包中还有很多资料。
Shell作为查询语言
实际上,我必须处理的许多数据处理和分析项目都是在Java中调用Python的代码的Shell脚本,以及Shell命令本身。因此,通常,您可以将bash / zsh / etc中的管道视为一些高级请求(当然,您可以在那里进行推入循环,但这对于Shell语言中的DS代码而言并不常见),让我们举一个简单的示例-我需要映射wikidata和到俄语和英语Wiki的完整链接,为此,我从bash中的命令编写了一个简单的查询,对于输出,我用Python编写了一个简单的脚本,将其汇总如下:
pv “data/latest-all.json.gz” |
unpigz -c |
jq --stream $JQ_QUERY |
python3 scripts/post_process.py "output.csv"
哪里
JQ_QUERY = 'select((.[0][1] == "sitelinks" and (.[0][2]=="enwiki" or .[0][2] =="ruwiki") and .[0][3] =="title") or .[0][1] == "id")' 实际上,这就是创建必要映射的整个管道,正如我们所看到的,它以流模式工作:
- pv filepath-根据文件大小提供进度条,并将其内容传递到
- unpigz -c读取档案的一部分并给jq
- 带有键的jq-流立即产生结果并将其传递给Python中的后处理器(就像第一个示例一样)
- 在内部,后处理器是一个简单的状态机,用于格式化输出
总体而言,复杂的管道以流模式处理大数据(0.5TB),而没有大量资源,由一个简单的管道和几个工具组成。
另一个重要提示:在终端中表现出色且高效,并用bash / zsh / etc编写。在哪里有用?是的,几乎到处都是-网上也有很多学习资料。特别是,这是我以前的文章。
R脚本
同样,读者可能会惊呼-好吧,这是一种完整的编程语言!当然,他会是对的。但是,我通常必须始终在这样的上下文中处理R:实际上,它与查询语言非常相似。
R是统计计算框架和静态计算和可视化语言(根据此)。
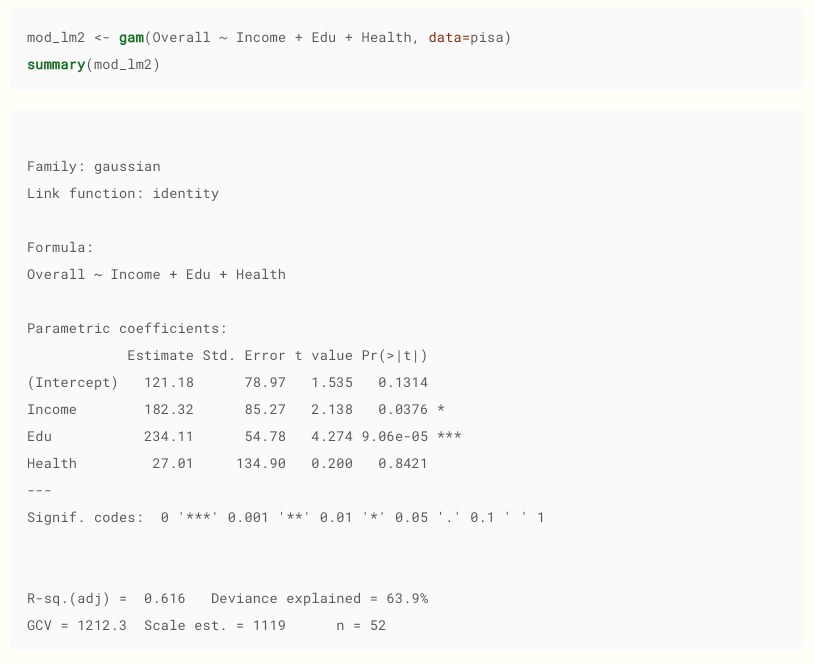
采取从这里。顺便说一句,我推荐好的材料。
为什么要和一位科学家约会才能认识R?至少因为在R中有大量非IT人员从事数据分析。我在以下地方见过面:
- 制药部门。
- 生物学家。
- 金融部门。
- 受过纯数学教育,处理统计数据的人。
- 专门的统计和机器学习模型(通常只能在上游版本中作为R包找到)。
为什么实际上是查询语言?在通常的形式中,实际上是创建模型的请求,包括读取数据和修复查询参数(模型),以及可视化ggplot2等程序包中的数据-这也是编写查询的一种形式。
渲染查询示例
ggplot(data = beav,
aes(x = id, y = temp,
group = activ, color = activ)) +
geom_line() +
geom_point() +
scale_color_manual(values = c("red", "blue"))通常,R中的许多想法已迁移到python程序包,例如pandas,numpy或scipy,例如数据帧和数据矢量化-因此,总的来说,R中的许多内容对您而言似乎都很熟悉和方便。
有很多研究资料,例如这一本。
知识图
在这里我有一点不寻常的经历,因为我仍然经常不得不使用知识图和图的查询语言。因此,让我们简单地介绍一下基础知识,因为这部分更具异国情调。
在经典的关系数据库中,我们有一个固定的模式-这里的模式是灵活的,每个谓词实际上是一个“列”,甚至更多。
想象一下,您将为一个人建模并想描述关键事物,例如,让我们以道格拉斯·亚当斯(Douglas Adams)为例,我们将以此描述为基础。
www.wikidata.org/wiki/Q42
如果我们使用的是关系数据库,则必须创建一个巨大的表或包含大量列的表,其中大多数将为NULL或填充一些默认的False值,例如,不太可能我们中的许多人都在韩国国家图书馆中有一个条目-当然,我们可以将它们放在单独的表中,但这最终将是尝试使用固定关系的谓词对灵活逻辑进行建模。
因此,可以想象所有数据都以图形或二进制和一元逻辑表达式存储。
您甚至可以在哪里碰到这个?首先,使用Wiki数据以及任何图形数据库或连接的数据。
以下是我曾经使用和使用的主要查询语言。
SPARQL
Wiki:
SPARQL ( . SPARQL Protocol and RDF Query Language) — , RDF, . SPARQL W3C .
但实际上,它是查询逻辑一元和二进制谓词的语言。您只是有条件地说明布尔表达式中固定的内容,而不是布尔值(非常简单)。
在其上执行SPARQL查询的RDF(资源描述框架)本身是一个三元组
object, predicate, subject-该查询本着以下精神根据指定的约束条件选择必要的三元组:找到一个X,使得p_55(X,q_33)为真-当然,p_55是什么-ID为55的关系,而q_33是ID为33的对象(这是整个故事,再次省略了各种细节)。
数据显示示例:
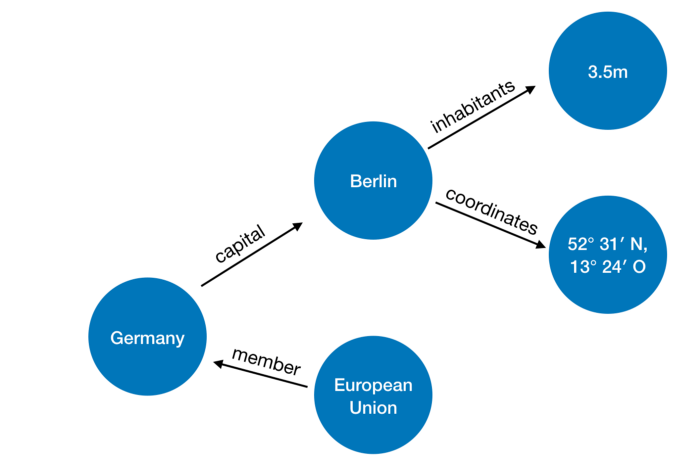
图片和国家的例子在这里。
基本查询示例

实际上,我们要查找变量?Country的值,这样对于谓词
member_of,member_of(?Country,q458)和q458确实是欧盟的ID。
python引擎内部真实SPARQL查询的示例:
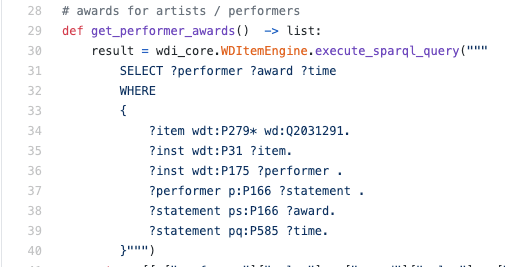
通常,我必须读SPARQL而不是写-在这种情况下,很可能至少在基本水平上理解该语言是一项有用的技能,以便准确地了解如何检索数据。
在线上有很多学习资料,例如这一本和这一本。我本人通常会用谷歌搜索特定的结构和示例,到目前为止,我已经足够了。
逻辑查询语言
您可以在我的文章中阅读有关该主题的更多信息。在这里,我们将简要讨论为什么逻辑语言非常适合编写查询。实际上,RDF只是形式为p(X)和h(X,Y)的逻辑语句的集合,并且逻辑查询如下所示:
output(X) :- country(X), member_of(X,“EU”).
在这里,我们谈论的是在以下情况下创建新的谓词输出/ 1(/ 1表示一元):只要X对那个国家(X)是正确的-即X是那个国家并且也是member_of(X,“ EU”)。
也就是说,在这种情况下,我们通常以相同的方式呈现数据和规则,这使得对任务进行建模非常容易且很好。
你在哪里见过面:一个大型公司的大型项目,以及使用这种语言编写查询的公司,以及系统核心中的当前项目-似乎是一件很奇怪的事情,但有时会发生。
逻辑语言处理Wikidata中的代码片段示例:
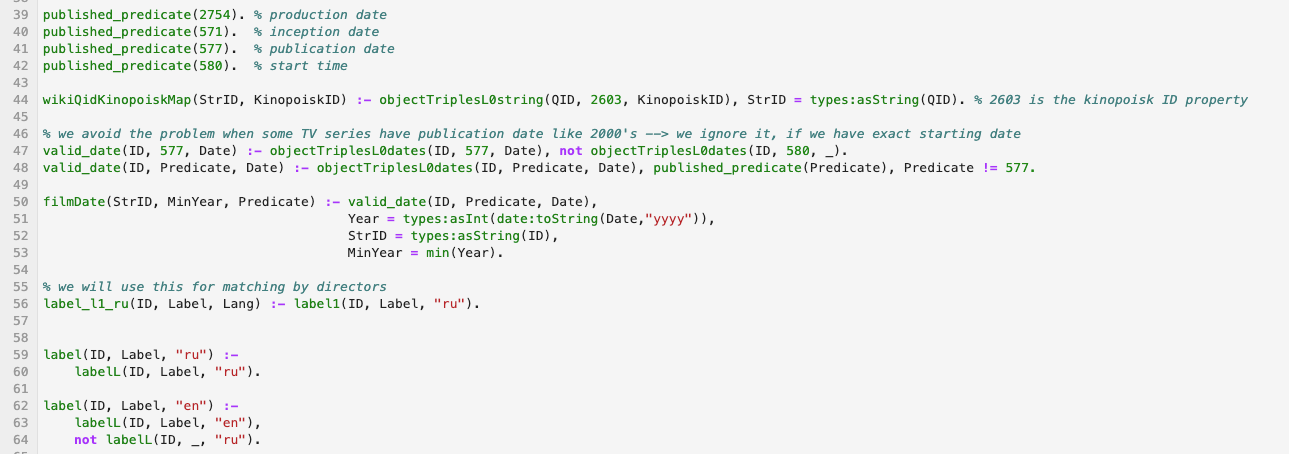
资料:我将在此处提供一些指向现代逻辑编程语言的答案集编程的链接-我建议您对其进行研究:
- http://peace.eas.asu.edu/aaai12tutorial/asp-tutorial-aaai.pdf
- http://ceur-ws.org/Vol-1145/tutorial1.pdf
- https://www.youtube.com/watch?v=gVQ0bP8zyHw
- https://www.youtube.com/watch?v=kdcd7Je2glc
- https://potassco.org/book/
- http://potassco.sourceforge.net/teaching.html
- https://www.cs.uni-potsdam.de/~torsten/Potassco/Tutorials/fmcad12.pdf
