对于需要在多台服务器上管理数据和应用程序的公司而言,基础架构至关重要。
对于每家公司而言,工作流的重要部分是监视基础结构节点,尤其是在没有直接访问来解决新出现的问题的情况下。此外,大量使用某些资源可以指示基础结构故障和过载。但是,监视不仅可以用于预防,而且可以用于评估在生产中使用新软件的可能后果。市场上目前有几种可跟踪资源消耗的即用型解决方案,但是它们仍然存在两个关键问题:安装和配置的高成本以及与第三方软件相关的安全性问题。
第一个问题是价格问题:每个月的费用从十欧元(消费者价格)到数千欧元(企业价格)不等,具体取决于要监视的主机数量。例如,假设我要监视三个节点一年。以每月10欧元的价格,我将花费120欧元,而一家小公司将不得不花上10,000至20,000,这在财务上是站不住脚的决定,只会破坏整个预算。
第二个问题是第三方软件。鉴于需要进行分析的用户数据(无论是个人还是公司)必须由第三方处理,因此出现了一个问题:第三方如何收集数据并将其呈现给用户?通常,为此,在节点上安装了一个特殊的应用程序,可以通过该应用程序进行监视,但是通常,此类应用程序有时间变得过时或与客户端的操作系统不兼容。研究人员在信息安全领域的经验阐明了使用“专有软件”的问题。您相信这样的软件吗?我不是
我有Tor和一些加密货币的节点因此,我更喜欢免费,开源,易于自定义的监视替代方案。在本文中,我们将研究三个这样的工具:Grafana,InfluxBD和CollectD。

监控方式
为了有效地分析基础架构的每个指标,我们需要一个可以从我们感兴趣的设备中获取统计信息的应用程序。在这方面,CollectD可以提供帮助:此守护程序对所有可以存储在磁盘上或通过网络传输的参数进行分组和收集(“ collects”,因此是这样的名称)。
然后,数据将被传输到InfluxDB实例:这是一个时间序列数据库(TSBD),它将数据链接到服务器接收数据的时间(UNIX编码的时间戳)。因此,CollectD发送的数据将作为事件序列到达。
最后,我们将使用Grafana:此程序将连接到InfluxDB,并在用户友好的彩色仪表板上显示数据。借助各种图形和直方图,我们将能够实时跟踪CPU,RAM等的数据。

InfluxDB

让我们从InfluxDB开始,InfluxDB是一个免费的TSBD,用于将数据存储为一系列事件。这个Go开发的数据库将成为我们监控“系统”的核心。
每当数据到达时,默认情况下都会将UNIX标签绑定到该标签。这种方法的灵活性使用户不必存储变量“时间”,否则该变量将非常复杂。假设我们有几个位于不同大陆的设备。我们将如何处理“时间”变量?我们是否要将所有数据与格林威治标准时间相关,还是我们将为每个节点分配自己的时区?如果数据存储在不同的时区,我们如何在图表上正确显示它?如您所见,问题接arise而至。
由于InfluxDB会跟踪时间并自动标记每个数据的到达,因此它可以将数据同步写入特定的数据库。这就是为什么InfluxDB通常表示为时间轴的原因:写入数据不会影响数据库的性能(这在MySQL中有时会发生),因为写入只是在时间轴中添加特定事件。因此,程序的名称来自对时间的无休止的“流”感知。
安装与配置
InfluxDB的另一个优点是它易于安装,并且由项目社区提供了广泛的文档,从而为它提供了广泛的支持。InfluxDB有两种类型的界面:命令行(对于开发人员来说是一种方便的工具,但是对于处理大量数据而言准备不足)和用于与数据库直接交互的HTTP API。
您不仅可以从官方站点下载InfluxDB,还可以通过软件包管理系统下载InfluxDB(我们将通过Debian进行演示)。另外,建议在安装之前通过GPG检查软件包,因此下面我们导入InfluxDB软件包的密钥:
root@node#~: curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
root@node#~: source /etc/os-release
root@node#~: echo "deb https://repos.influxdata.com/debian $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/influxdb.list最后,我们将更新并安装InfluxDB:
root@node#~: apt-get update
root@node#~: apt-get install influxdb要运行,我们将使用
systemctl:
root@node#~: service start influxdb 为了防止有恶意的人登录到我们,我们将创建一个名为“管理员”的用户。您可以通过类似InfluxDB SQL的查询语言“ InfluxQL ”与数据库进行交互。要创建一个新用户,我们将运行一个request
create user。
root@node#~: influx
Connected to http://localhost:8086
InfluxDB shell version: x.y.z
>
> CREATE USER admin WITH PASSWORD 'MYPASSISCOOL' WITH ALL PRIVILEGES在同一个CLI界面中,我们将创建一个“指标”数据库,用于存储指标。
> CREATE DATABASE metrics接下来,我们将配置InfluxBD(
/etc/influxdb/influxdb.conf)来打开端口24589(UDP)上的接口,并直接连接到“ metrics”数据库以支持CollectD。我们还需要下载文件types.db并将其放置在该地址/usr/share/collectd/(或任何其他文件夹)中,以正确确定CollectD以其本机格式传输的数据。
root@node#~: nano /etc/influxdb/influxdb.conf
[Collectd]
enabled = true
bind-address = ":24589"
database = "metrics"
typesdb = "/usr/share/collectd/types.db"您可以在文档中阅读有关配置的CollectD的更多信息。
已收集

我们的监控基础架构中的CollectD将充当数据聚合器,简化向InfluxDB的数据传输。根据定义,CollectD可从CPU,RAM,硬盘驱动器,网络接口,进程中收集指标。该程序的潜力是无限的,尤其是当您考虑到已经可用的各种插件以及一组计划的插件时。
如您所见,安装CollectD很简单:
root@node#~: apt-get install collectd collectd-utils让我们用一个简化的例子来说明CollectD的工作方式。假设我想知道我节点上的进程数。为了检查这一点,CollectD将进行API调用以找出每单位时间的进程数(按定义为5000毫秒),仅此而已。聚合器接收到数据后,就会将其通过需要配置的模块(称为“网络”)传输到InfluxDB进行配置。
使用我们的编辑器打开文件
/etc/collectd.conf,滚动到该部分Network并按如下所示进行编辑。确保指定InfluxDB(INFLUXDB_IP)接口所在的IP 。
root@node#~: nano /etc/collectd.conf
...
<Plugin network>
<Server "INFLUXDB_IP" "24589">
</Server>
ReportStats true
</Plugin>
...
我建议在转发给InfluxDB的配置文件中更改主机名(在我们的基础架构中,这是一个“集中式”数据库,因为它位于同一节点上)。因此,我们将不会接收到不必要的数据,并且数据被其他节点覆盖的风险将消失。

格拉法纳

一张图值得一千张图片
考虑到释义的报价,通过图形和表格观察实时基础结构指标可以使我们高效,及时地采取行动。我们将使用Grafana为我们的图形和表格创建和自定义仪表板。
Grafana是一款免费的图形指标工具,与多种数据库(包括InfluxDB)兼容,用户可以在其中满足一条特定条件的数据,从而创建警报。例如,如果处理器达到峰值,则可能会收到Slack,Mattermost,电子邮件等警报。此外,我将警报配置为当有人“进入”我的基础架构时主动监视每种情况。
Grafana不需要任何特殊设置:正如我们前面提到的,InfluxDB“扫描”“时间”变量。集成本身非常简单:我们将从导入公钥开始,以从Grafana官方网站添加软件包(取决于您的操作系统):
root@node#~: wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -
root@node#~: echo "deb https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
root@node#~: apt-get update && apt-get install grafana然后让我们通过systemctl运行它:
root@node#~: systemctl start grafana-web现在,当我们在浏览器中导航到localhost:3000页面时,我们应该看到Grafana登录界面。根据定义,您可以通过登录admin和密码admin(建议更改第一个登录凭据后)。

让我们转到Sources部分,在其中添加我们的Influx数据库:


现在,我们在New Dashboard标签下看到一个绿色的小矩形。将光标悬停在其上方,然后选择“添加面板”,然后选择“图形”:

现在,您可以看到带有测试数据的图形。单击该图的标题,然后单击“编辑”。使用Grafana,您可以创建智能查询:您无需知道数据库中的每个字段,Grafana将从适合分析的参数列表中为您提供这些查询。
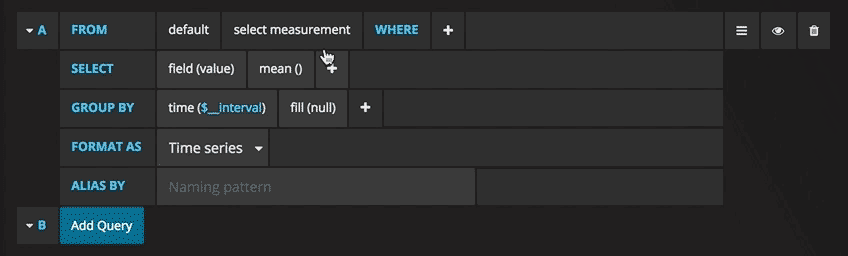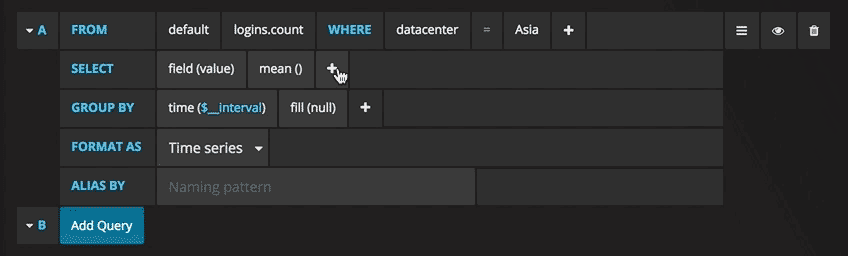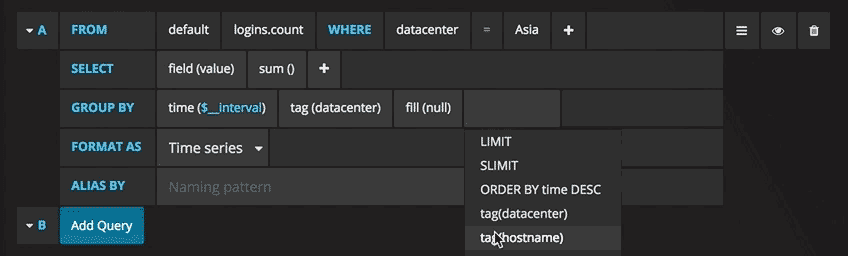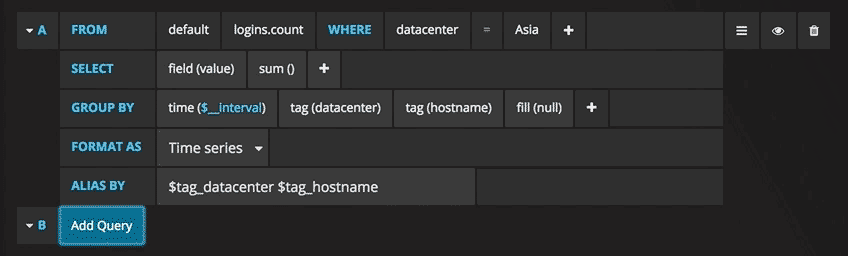
编写查询从未如此简单:只需选择您感兴趣的指标,然后单击“刷新”即可。我还建议按主机划分指标,以便更轻松地隔离问题。如果您对其他控制面板创意感兴趣,则可以访问Grafana网站,获取各种示例启发。
我们注意到Grafana是一个非常可扩展的工具,它使我们能够比较彼此之间非常不同的数据。没有一个单一的指标无法获得,因此只有您的才智限制了您。跟踪您的设备并实时获得有关基础架构的最完整概述!
