
任何计算机的所有中央处理单元,无论是廉价的笔记本电脑还是价值数百万美元的服务器,都具有称为缓存的设备。而且它具有多个级别的可能性很高。
这可能很重要,否则为什么要安装它?但是缓存有什么作用,为什么它具有不同的级别?“ 12向组合”是什么意思?
什么是缓存?
TL; DR:这是一个很小但速度非常快的内存,它紧邻CPU的逻辑块。
但是,我们当然可以了解有关缓存的更多信息……
让我们从一个假想的魔术存储系统开始:它无限快速,可以同时处理无限数量的数据传输,并始终提供可靠和安全的存储。当然,附近没有任何东西,但是如果是这样,处理器的结构将更加简单。
这样,处理器将只需要逻辑块用于加法,乘法等,以及一个数据传输控制系统,因为我们的理论存储系统能够即时发送和接收所有必要的数字;等待数据传输时,逻辑块不必处于空闲状态。
但据我们所知,还没有这种神奇的存储技术。取而代之的是,我们拥有硬盘驱动器或固态驱动器,即使其中最好的驱动器也远远不能满足现代处理器所需的处理能力。
伟大的存储技术
之所以如此,原因是现代处理器的速度非常快-它们只需要一个时钟周期就可以将两个64位整数相加。如果处理器以4 GHz运行,则只有0.00000000025秒或四分之一纳秒。
同时,旋转的硬盘要花几千纳秒才能在磁盘上找到数据,更不用说传输它们了,而固态驱动器要花数十或几百纳秒。
显然,这样的驱动器不能建内处理器,因此它们之间会有物理上的隔离。因此,增加了移动数据的时间,这加剧了这种情况。
las,这就是数据存储的绝妙之处。
这就是为什么我们需要在处理器和主驱动器之间放置另一个存储系统的原因。它应该比存储设备快,能够同时处理多个数据传输,并且离处理器更近。
好了,我们已经有了这样的系统,它叫做RAM;它存在于每台计算机中,并完全执行此任务。
几乎所有此类存储都属于DRAM (动态随机存取存储器)类型。它们能够比任何存储设备更快地传输数据。
但是,尽管速度极快,但DRAM无法存储如此数量的数据。美光公司开发的
一些最大的DDR4内存芯片可存储32 Gb或4 GB数据。最大的硬盘驱动器可存储4000倍。
因此,尽管我们提高了数据网络的速度,但仍需要其他系统(硬件和软件)来确定应将哪些数据存储在有限的DRAM中,以备处理器处理。
DRAM可以制造在芯片封装(这被称为嵌入式DRAM)。但是,处理器非常小,因此无法容纳大量内存。

Xbox 360 GPU左侧有10MB DRAM来源:CPU Grave Yard
绝大多数DRAM都位于处理器附近,并与主板相连,并且始终是最靠近处理器的组件。但是,该内存仍然不够快...
DRAM大约需要100纳秒才能找到数据,但至少每秒能够传输数十亿比特。看来我们需要另一个可以在CPU和DRAM块之间放置的存储阶段。
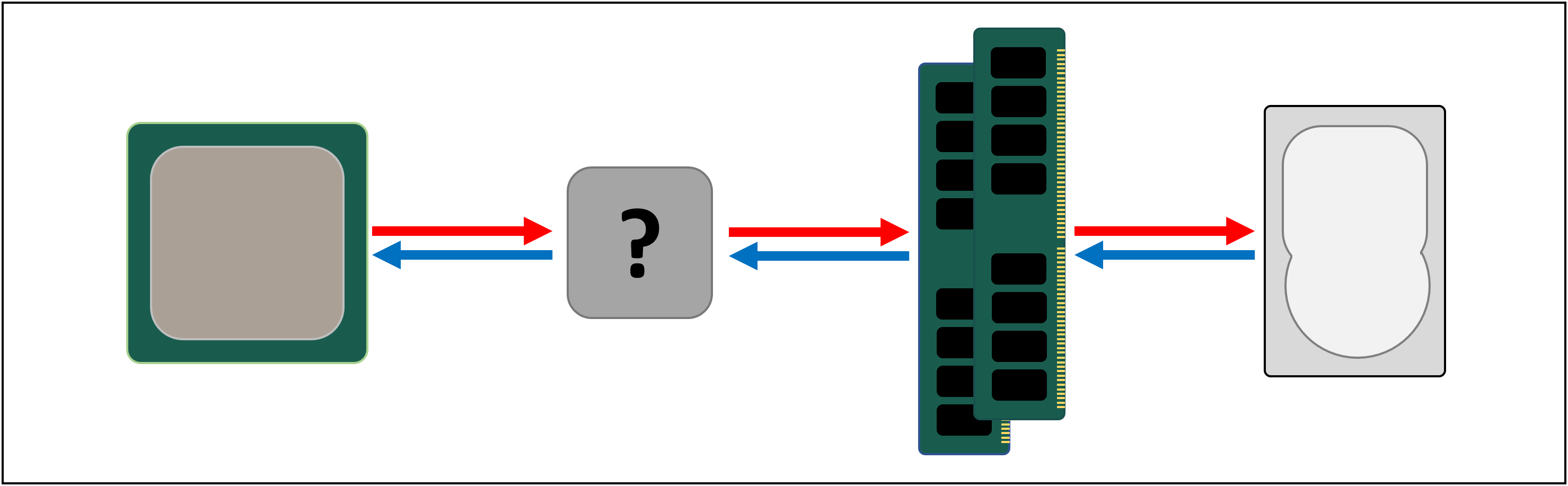
剩下的阶段出现在场景中:SRAM(静态随机存取存储器)。 DRAM使用微观电容器以电荷形式存储数据,而SRAM使用晶体管完成相同的任务,这些晶体管的运行速度与处理器的逻辑块相同(比DRAM快10倍)。
当然,SRAM有一个缺点,它又与空间有关。
晶体管存储器占用太多比DRAM更多的空间:在相同的尺寸为4GB DDR4芯片,你可以得到低于SRAM的100MB。但是,由于它是使用与CPU相同的制造工艺制造的,因此SRAM可以直接嵌入到处理器内部,并尽可能靠近逻辑块。
每增加一个步骤,我们就以存储量为代价提高了传输数据的速度。我们可以继续并添加新步骤,这将更快但更小。
所以我们有了更严格的定义高速缓存概念:位于处理器内部的SRAM的集合;它们通过高速传输和存储数据来最大化处理器利用率。您对这个定义满意吗?太好了,因为从现在开始事情会变得更加复杂!
现金:多层停车场
如上所述,缓存是必需的,因为我们没有魔术存储系统可以处理处理器逻辑块的数据消耗。现代的CPU和GPU包含许多SRAM,它们按层次结构排列-一系列具有以下结构的缓存:
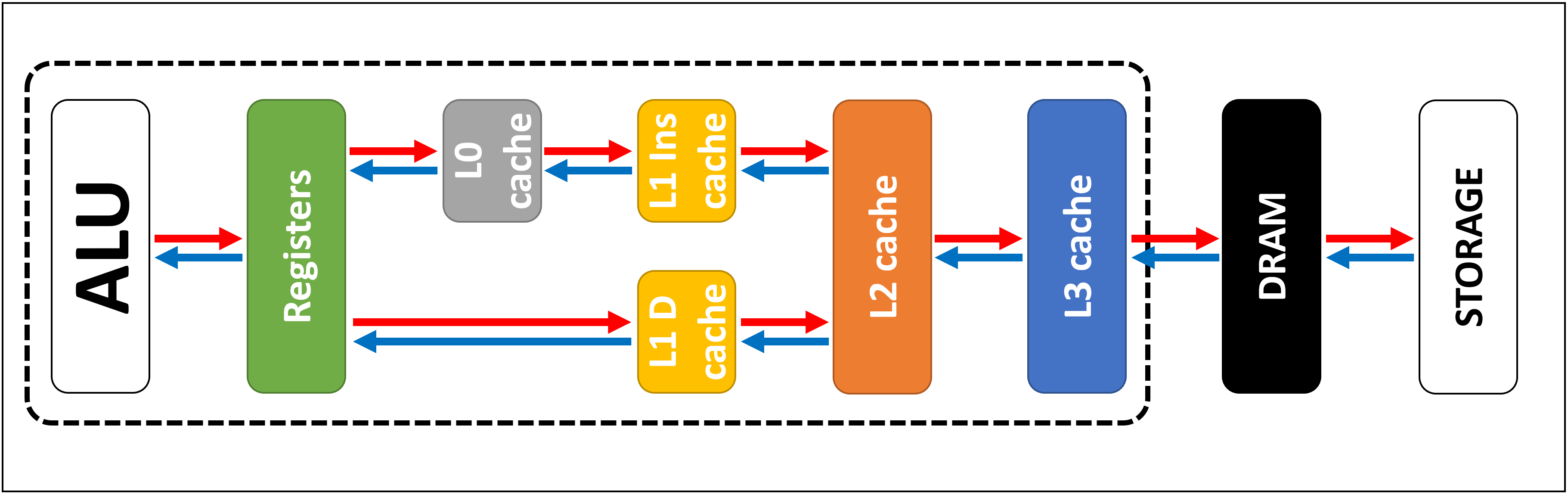
在上图中,处理器(CPU)用虚线矩形表示。左侧是ALU(算术逻辑单元);这些是执行数学运算的结构。尽管不是严格意义上的高速缓存,但最接近ALU的内存级别是寄存器(它们在寄存器文件中排序)。
它们每个都存储一个数字,例如64位整数。该值本身可以是某些数据的元素,特定指令的代码或某些其他数据的存储地址。
台式机处理器中的注册文件非常小,例如,在每个Intel Core i9-9900K内核中这样的文件有两个存储区,一个用于整数的存储区仅包含180个64位整数。向量的另一个寄存器文件(数字的小数组)包含168个256位元素。也就是说,每个内核的总寄存器文件略少于7 KB。为了进行比较,用于流式多处理器的Nvidia GeForce RTX 2080 Ti寄存器文件(如GPU称为CPU核心模拟)的大小为256 KB。
寄存器与高速缓存一样,都是SRAM,但是它们的速度不超过它们所服务的ALU的速度。他们在一个时钟周期内传输数据。但是它们并不是为了存储大量数据(仅一个元素)而设计的,因此它们旁边总是有更大的内存块:这是第一级缓存(级别1)。
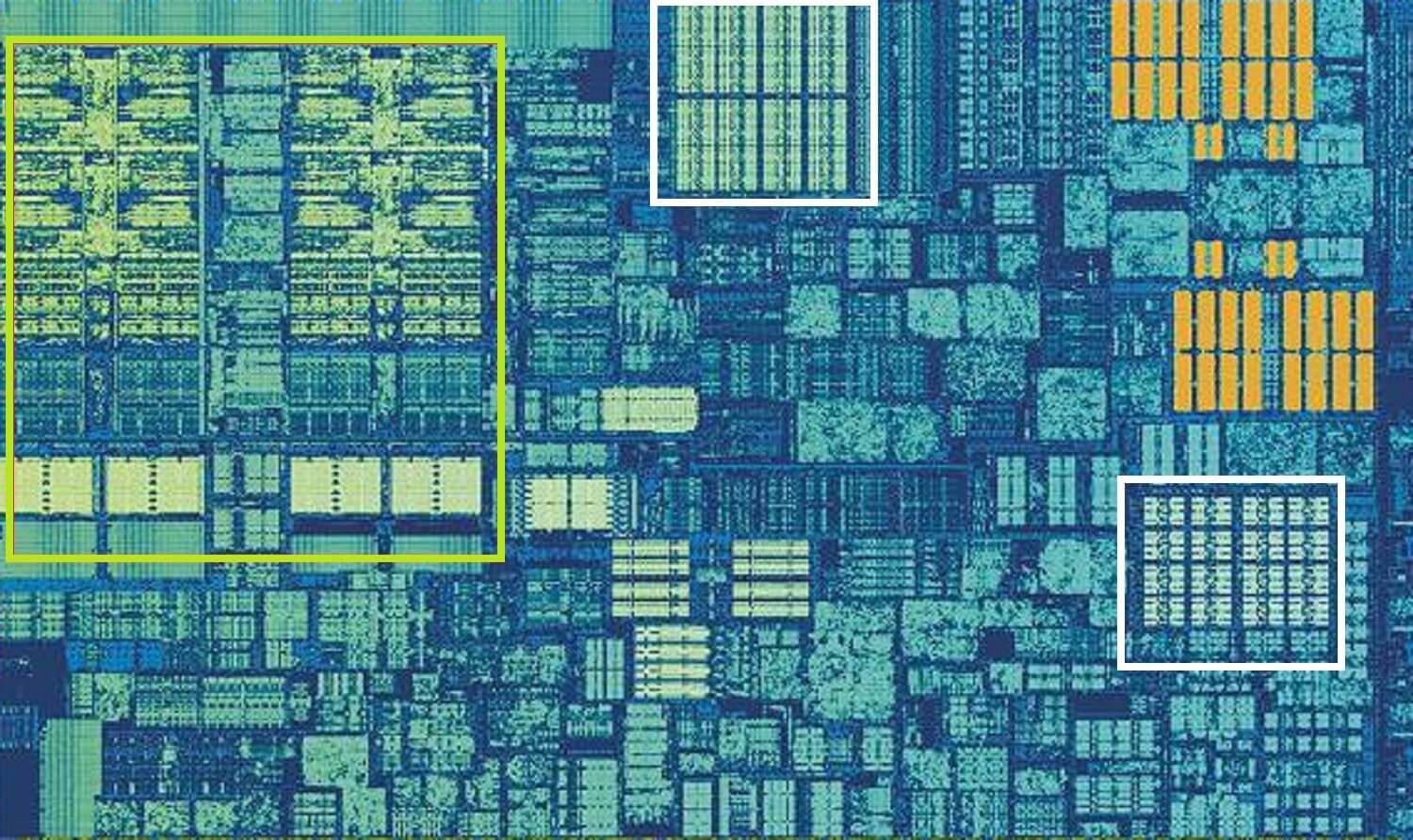
一个Intel Skylake处理器核心。来源:Wikichip
上图是Intel Skylake台式机处理器核心之一的放大图。
ALU和寄存器文件位于左侧,并由绿色框包围。在照片的顶部,白色表示1级数据缓存。它包含的信息并不多,只有32 KB,但是与寄存器一样,它也非常靠近逻辑块,并以相同的速度运行。
右侧的另一个白色矩形显示了1级指令高速缓存,大小也为32 KB。顾名思义,它存储了各种准备拆分为较小微指令的命令。(通常用μops表示)必须执行的ALU。还有一个针对它们的缓存,可以将其归为0级,因为它比L1缓存小(仅包含1,500个操作)并且更近。
您可能想知道为什么这些SRAM这么小?为什么它们没有兆字节大小?数据和指令高速缓存一起在芯片上占据的空间几乎与主要逻辑块相同,因此增加它们将导致总裸片面积的增加。
但是其大小为几千字节的主要原因是,随着内存容量的增加,搜索和检索数据所需的时间也增加了。 L1高速缓存需要非常快,因此需要在大小和速度之间进行权衡-最多大约需要5个时钟周期才能从该高速缓存中获取数据(浮点值更多)。
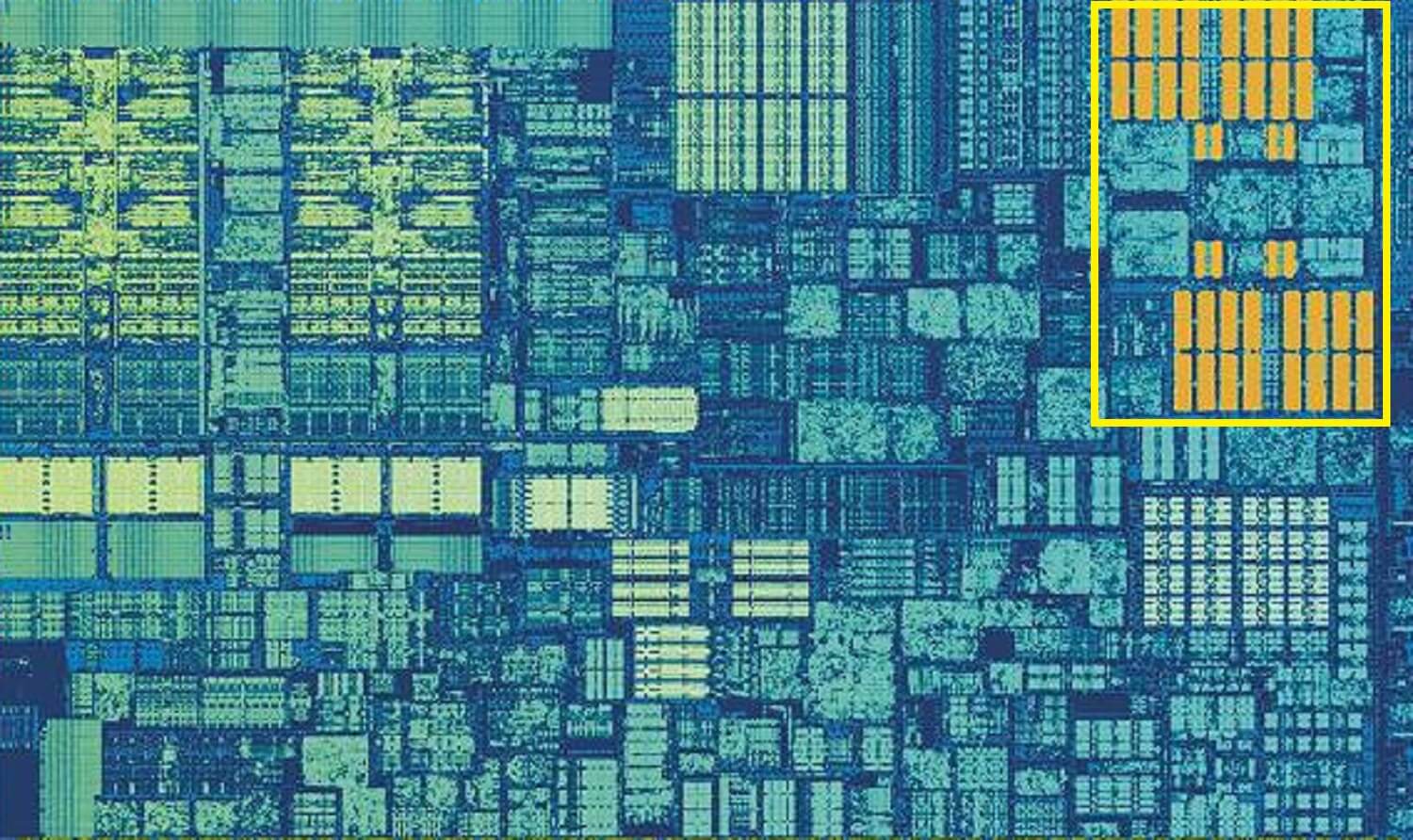
Skylake的L2高速缓存:256KB SRAM
但是,如果这是处理器内部唯一的高速缓存,其性能将遇到意外的障碍。这就是内核内建另一层内存的原因:二级缓存,这是包含指令和数据的通用存储块。
它始终大于级别1:在AMD Zen 2处理器中,它需要512KB才能为低级缓存提供足够的数据。但是,较大的大小需要牺牲-与1级相比,从此缓存中查找和传输数据大约需要两倍的时间。
在第一个Intel Pentium时代,二级缓存是一个单独的芯片,可以安装在单独的小板上(例如DIMM RAM),也可以内置在主板上。逐渐地,它进入了处理器本身的外壳,最后,它被完全集成到了芯片晶体中。这发生在奔腾III和AMD K6-III等处理器时代。
这项成就不久之后便是支持较低级别的缓存所需的另一个级别,并且它赶在多核芯片鼎盛时期赶上了。

英特尔Kaby Lake芯片。资料来源:Wikichip
这张Intel Kaby Lake芯片的图片在左侧显示了四个内核(集成GPU占据了几乎一半的裸片,在右侧)。每个内核都有其自己的“个人”级别1和2高速缓存集(以白色和黄色框突出显示),但它们也具有第三组SRAM块。
第三级高速缓存(第3级)虽然直接位于一个核心的旁边,但对于其他所有核心却是完全相同的-每个核心都可以自由访问另一个核心的L3缓存的内容。它更大(2至32 MB),但也慢得多,平均超过30个周期,尤其是当内核需要使用驻留在远离缓存块的数据时。
下面显示的是AMD Zen 2体系结构的一个核心:32KB的1级数据和指令高速缓存(在白框中),512KB的2级高速缓存(在黄框中)和巨大的4MB的L3高速缓存块(在红色框中)。

放大AMD Zen 2处理器的单核来源:Fritzchens Fritz
但是,等等:32KB如何占用比512KB更多的物理空间?如果1级存储的数据很少,为什么与L2和L3高速缓存相比,它的容量过大?
不只是数字
高速缓存通过加速数据到逻辑块的传输并在附近保留常用指令和数据的副本来提高性能。缓存中存储的信息分为两部分:数据本身以及它最初位于系统内存/存储中的位置-该地址称为缓存标签。
当处理器执行需要从/向存储器读取或写入数据的操作时,首先检查一级缓存中的标签,如果所需的数据在那里(发生缓存命中),则该数据几乎是立刻。当在高速缓存的最低级别上找不到所需标签时,将发生高速缓存未命中。
在L1高速缓存中创建了一个新标签,其余的处理器体系结构接管了该任务,在高速缓存的其他级别(如果需要,可扩展到主存储)中查找该标签的数据。但是要释放L1缓存中用于此新标签的空间,必须将某些东西扔到L2中。
这导致仅在几个时钟周期内执行近乎恒定的数据混排。实现此目的的唯一方法是围绕SRAM创建一个复杂的结构来处理数据管理。换句话说,如果处理器内核仅由一个ALU组成,则L1缓存将更加简单,但是由于有数十个(并且其中许多都混杂有两个指令流),因此缓存需要许多连接来移动数据。
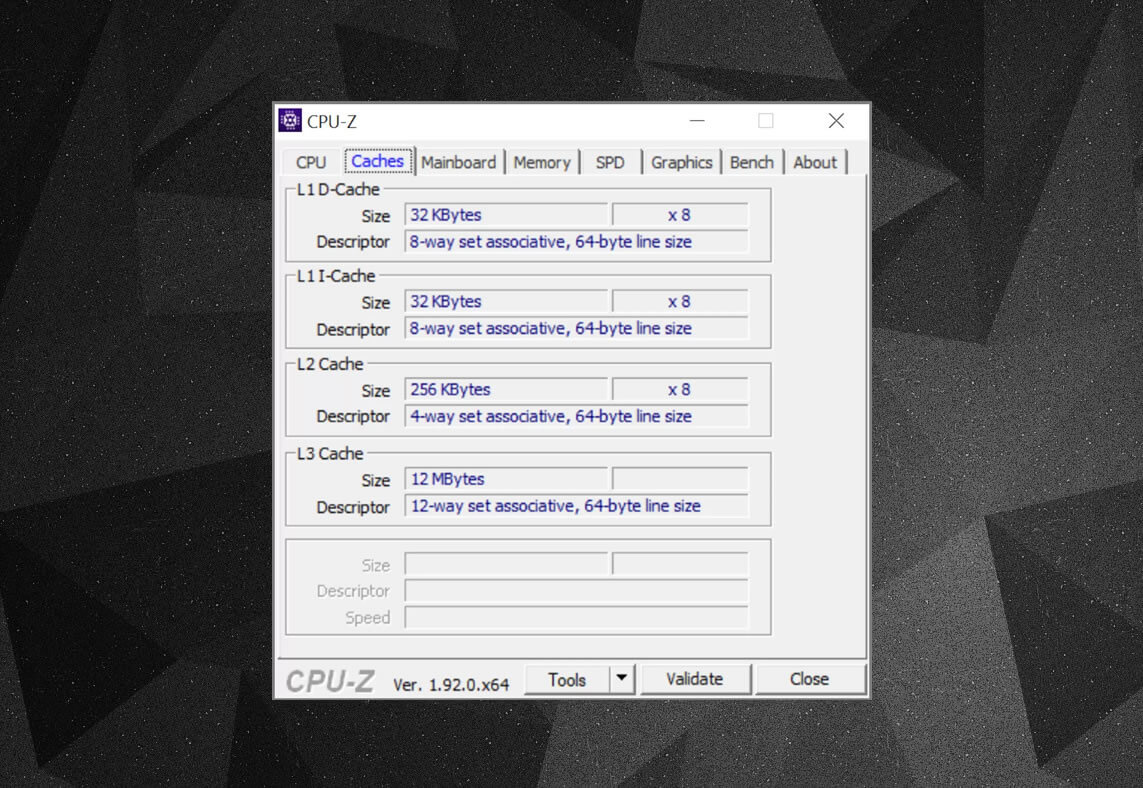
您可以使用诸如CPU-Z之类的免费程序来检查计算机处理器中的缓存信息。但是所有这些信息意味着什么?一个重要的元素是集合关联标签,它指示用于将数据块从系统内存复制到缓存的规则。
上面的缓存信息适用于Intel Core i7-9700K。它的每个1级高速缓存都分为64个小块,称为set,并且这些块中的每一个也分为高速缓存行。(大小为64个字节)。 “集合关联”是指来自系统的数据块绑定到一个特定集合中的高速缓存行,并且不能随意绑定到其他位置。
“ 8向”表示一个块可以与该集中的8条高速缓存行关联。关联性级别越高(即“路径”越大),在处理器查找期间发生高速缓存命中的机会就越大,并且由高速缓存未命中引起的损失也就越少。这种系统的缺点是增加的复杂性和功耗以及较低的性能,因为必须为每个数据块处理更多的缓存行。

包含缓存L1 + L2,牺牲者缓存L3,回写策略,甚至还有ECC。资料来源:Fritzchens Fritz
缓存复杂性的另一方面与数据在不同层之间的存储方式有关。规则在包含策略中设置。例如,英特尔酷睿处理器具有完全包含的L1 + L3缓存。这意味着,例如,级别1中的某些数据可能存在于级别3中。这似乎浪费了宝贵的缓存空间,但好处是,如果处理器错过了较低级别的标签,则不需要在顶层搜索数据。
在相同的处理器中,L2缓存是非包含性的:存储在该处的所有数据都不会复制到任何其他层。这样可以节省空间,但会导致芯片的内存系统在L3中查找丢失的标签(标签总是更大)。受害者缓存在原理上相似,但是它们用于存储从较低级别携带的信息。例如,AMD Zen 2处理器使用受害者缓存L3,该缓存仅存储来自L2的数据。
还有其他缓存策略,例如将数据写入缓存和主系统内存。这些称为写策略;大多数现代处理器使用回写式缓存-这意味着将数据写入高速缓存层时,在将其副本写入系统内存之前会有一个延迟。通常,只要数据保留在高速缓存中,此暂停就会持续-RAM仅在从高速缓存中“弹出”该信息时才接收此信息。

具有20 MB L1高速缓存和40 MB L2高速缓存的Nvidia GA100 GPU
对于处理器设计者来说,高速缓存大小,类型和策略的选择是要平衡驱动器以增加处理器功率,增加复杂性和芯片空间。如果有可能创建1000个通道的20MB级别1关联缓存,使其不占用曼哈顿的区域(并且不消耗相同的电量),那么我们所有人都将拥有配备此类芯片的计算机!
在过去的十年中,现代处理器中最低级别的缓存几乎保持不变。但是,三级缓存的大小继续增长。如果十年前购买的Intel i7-980X的价格为999美元,则可能会有12MB的缓存。今天只剩下一半可购买64 MB。
总而言之,缓存是绝对必要且出色的设备。我们没有介绍CPU和GPU中的其他类型的缓存(例如,关联的转换缓冲区或纹理缓存),但是由于它们都具有相同的简单结构和级别布局,因此理解它们并不困难。
您的主板上有一台带有L2缓存的计算机吗?奔腾II和赛扬(例如300a)子板怎么样?还记得您的第一个共享L3处理器吗?
广告
我们公司提供带有Intel和AMD处理器的租用服务器。在后一种情况下,这些是史诗服务器!带有AMD EPYC的VDS,CPU核心频率高达3.4 GHz。最大配置为128个CPU内核,512 GB RAM,4000 GB NVMe。
