这不是系统的分析,也不是表格。也从地球物理学家的角度来看的个人观点。但是我总是对阅读Gartner MQ感到好奇,他们完美地提出了一些观点。因此,我在技术方面,市场方面和哲学方面都需要关注一些事情。
这不是针对深入学习机器学习的人,而是针对对市场上正在发生的事情感兴趣的人。
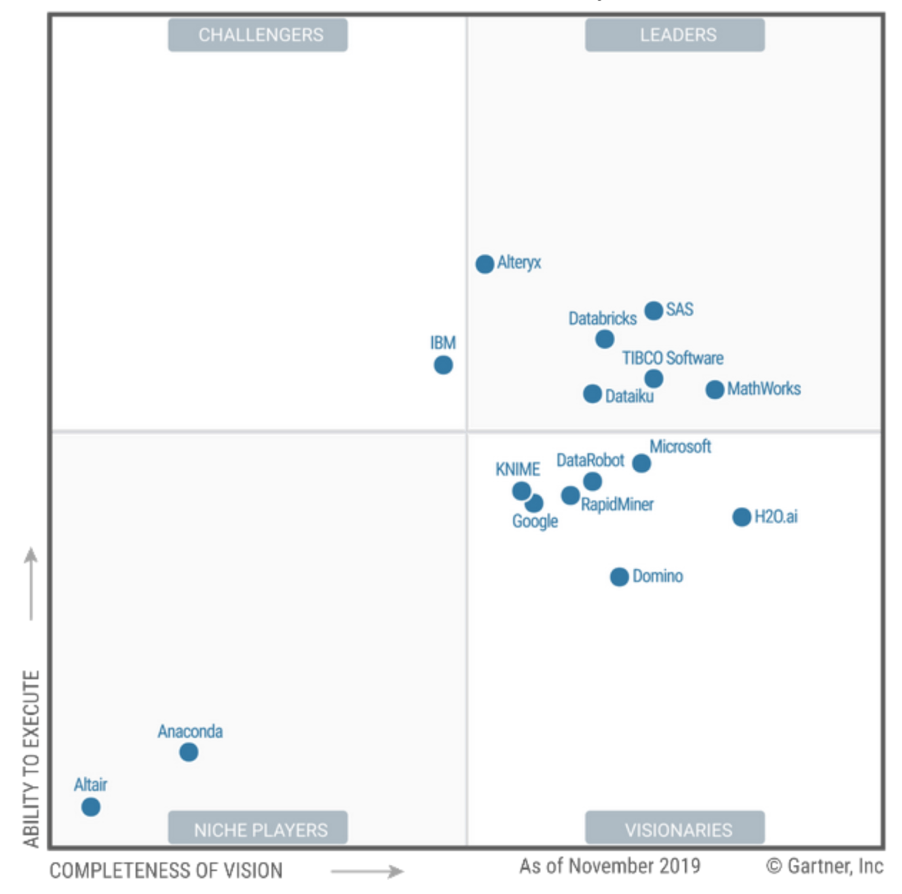
DSML市场本身在逻辑上嵌套在BI和Cloud AI开发人员服务之间。
喜欢的第一引号和术语:
- “领导者可能不是最佳选择” -市场领导者不一定是您所需要的。很紧急!由于缺乏能干的客户,他们一直在寻找“最佳”解决方案,而不是“合适”的解决方案。
- 模型操作化简称为MOP。哈巴狗对每个人都很难!-(酷哈巴狗主题使模型正常工作)。
- 笔记本环境是一个重要的概念,它将代码,注释,数据和结果组合在一起。这非常清楚,很有希望,并且可以大大减少UI代码的数量。
- «Rooted in OpenSource» — – .
- «Citizen Data Scientists» — , , , . .
- «Democratise» — “ ”. «democratise the data» «free the data», . «Democratise» — long tail . — !
- «Exploratory Data Analysis – EDA» — . . . , . ,
- “可重现性” -最大限度保留环境的所有参数,输入和输出,以便您可以在进行一次重复实验。实验测试环境中最重要的术语!
所以:
Alteryx
很酷的界面只是一个玩具。当然,可伸缩性有点严格。因此,各地的工程师社区与tsatski一起玩。Analytics(分析)拥有自己的全部功能。它使我想起了90年代编程的Coscad光谱相关数据分析套件。
水蟒
一个由Python和R专家组成的社区。开源分别很大。原来,我的同事们一直在使用。我不知道
数据砖
由三个开源项目组成-自2013年以来,Spark开发人员已经筹集了很多钱。我必须直接阅读Wiki:
“ 2013年9月,Databricks宣布已从Andreessen Horowitz筹集了1,390万美元。该公司在2014年额外筹集了3300万美元,在2016年筹集了6000万美元,在2017年筹集了1.4亿美元,在2019年2月筹集了2.5亿美元,在2019年10月筹集了4亿美元”!一些伟大的人Spark看到了。不熟悉对不起!
这些项目是:
- Delta Lake -Spark上的ACID最近已发布(我们在Elasticsearch上实现的梦想)-它将其转换为数据库:严格的方案,ACID,审核,版本...
- ML Flow-模型跟踪,打包,管理和存储。
- 考拉-对星火熊猫据帧API -熊猫-的Python API与一般的表和数据的工作。
您会看到关于Spark的信息,他突然不知道或忘记了:link。维多斯基(Vidosiki)看了一些无聊但详尽的咨询啄木鸟的例子:用于数据科学的DataBrick(链接)和用于数据工程的DataBrick (链接)。
简而言之,Databricks推出了Spark。想要在云中正常使用Spark的人会按预期毫不犹豫地使用DataBrick :) Spark是这里的主要区别。
我发现Spark Streaming并不是真正的假实时或微批处理。而且,如果您需要真正的Real Real time,它位于Apache STORM中。仍然每个人都说并写道Spark比MapReduce更酷。口号是这个。
数据库
端到端很酷的事情。有很多广告。不明白它与Alteryx有何不同?
数据机器人
用于准备数据的Paxata是一家独立的公司,于2019年12月被Data Robots收购。筹集了20 MUSD并出售。 7年后的一切。
在Paxata中而不是Excel中准备数据-请参见此处:link。
在两个数据集之间有自动欺骗和连接提议。一件很棒的事情-整理数据,甚至更多地强调文本信息(link)。
数据目录是没人需要的“实时”数据集的一个很好的目录。
同样有趣的是如何在Paxata中创建目录(link)。
«According to analyst firm Ovum, the software is made possible through advances in predictive analytics, machine learning and the NoSQL data caching methodology.[15] The software uses semantic algorithms to understand the meaning of a data table's columns and pattern recognition algorithms to find potential duplicates in a data-set.[15][7] It also uses indexing, text pattern recognition and other technologies traditionally found in social media and search software.»
Data Robot的主要产品在这里。他们的口号是从模型到企业应用!发现了与危机有关的石油行业咨询服务,但非常平淡无趣:link。在Mops或MLops上观看了他们的视频(link)。这是科学怪人,由6-7项对各种产品的收购构成。
当然,很明显,一个庞大的数据科学家团队应该具有这样一种用于处理模型的环境,否则,他们将产生许多模型而从不部署任何东西。在我们的石油和天然气上游现实中,可以成功创建一个模型,这已经是一个巨大的进步!
该过程本身非常让人联想到地质地球物理设计系统的工作,例如Petrel... 所有杂物制作和修改模型。收集模型中的数据。然后,我们制作了参考模型并将其投入生产!例如,地质模型和ML模型之间有许多相似之处。
骨牌
强调开放平台和协作。允许免费使用业务用户。他们的数据实验室非常类似于Sharepoint。 (并且从名称上强烈地赋予了IBM)。所有实验都链接到原始数据集。多么熟悉:)在我们的实践中-将一些数据拖入模型中,然后将其清理并按顺序放入模型中,所有这些都已存在于模型中,您无法在初始数据中找到终点。
Domino具有出色的基础架构虚拟化。我收集了机器每秒多少个内核,然后开始计数。立即如何尚不完全清楚。到处都有Docker。很多自由!可以连接任何最新版本的工作空间。并行运行实验。跟踪和选择成功者。
与DataRobot相同-结果以应用程序的形式发布给业务用户。对于特别有天赋的“利益相关者”。并且还监视模型的实际使用。哈巴狗的一切!
我不完全了解复杂模型如何投入生产。提供了一些API来为它们提供数据并获取结果。
水
无人驾驶AI是用于Supervised ML的非常紧凑和直接的系统。一切都在一个盒子里。目前尚不清楚后端。
该模型将自动打包到REST服务器或Java App中。这是一个好主意。可解释性和解释性已经做了很多工作。对模型操作结果的解释和解释(本质上什么是不能解释的,否则一个人可以计算出相同的结果)。
首次详细考虑了有关非结构化数据和NLP的案例研究。高质量的建筑图片。总的来说,我喜欢这些图片。
有一个大型开源H2O框架尚不完全清楚(一组算法/库?)。自己的可视笔记本电脑,无需像Jupiter一样编程(链接)。我还阅读了有关现实中包装的Pojo和Mojo-H2O模型的信息。第一个在额头上,第二个在优化上。H20是唯一(Gartner)凭借其优势以及可扩展性工作向其撰写文本分析和NLP的人员(!)。这是非常重要的!
同上:用于铁和云集成的高性能,优化和行业标准。
弱点是合乎逻辑的-与自己的开源软件相比,Driversles AI弱而狭窄。与相同的Paxata相比,数据准备简直是la脚!并忽略工业数据-流,图,地理。好吧,一切都不对。
尼米
我喜欢主页上的6个非常具体非常有趣的业务案例。强大的开源。
Gartner已从领导人降为有远见的人。鉴于Leader并非始终是最佳选择,所以赚钱不佳对用户来说是一个好兆头。
关键字就像在H2O中一样-增强,表示帮助贫穷的公民数据科学家。这是第一次有人在评论中对性能进行责骂!有趣?就是说,计算能力如此之大,以至于性能根本不是系统性的问题?Gartner关于此词“ Augmented”有另一篇文章,我无法理解。
而且KNIME似乎是该评论中的第一位非美国人!(我们的设计师非常喜欢他们的目标网页。奇怪的人。
MathWorks
MatLb是一个众所周知的古老荣誉朋友!适用于生活和情况各个领域的工具箱。完全不同。实际上,通常所有场合的数学很多很多!
用于系统设计的Simulink附加产品。我进入了Digital Twins的工具箱-我对此一无所知,但是这里已经写了很多东西。适用于石油工业。通常,这是与数学和工程学深度不同的根本产品。选择特定的数学工具包。根据Gartner的说法,他们都有问题,例如聪明的工程师-没有协作-模型中的每个谣言,没有民主,没有可利用性。
RapidMiner
在良好的开源环境下,我(与Matlab一起)经历了很多,也听到了很多。像往常一样在TurboPrep中埋了一点。我对如何从脏数据中获取干净数据感兴趣。
再一次,您可以在功能演示中看到人们在2018年营销材料方面表现出色,并且说英语的人很糟糕。
自2001年以来就来自多特蒙德,他们拥有强大的德国历史)

我不了解该网站在开放源代码中到底提供了什么-您需要更深入地研究。关于部署和AutoML概念的优质视频。
RapidMiner Server后端也没有什么特别的。它可能是紧凑的,并且可以在开箱即用的情况下很好地工作。打包在Docker中。仅在RapidMiner服务器上的共享环境。然后是Radoop,hadup的数据,Studio工作流中来自Spark的押韵计数。
像炙手可热的年轻小贩“条棍贩子”所期望的那样将它们推低。但是,Gartner预测企业领域将取得成功。你可以在那里筹钱。德国人知道圣洁:)不要提及SAP !!!
他们为公民做很多事!但是在页面上,您可以看到Gartner如何说他们很难进行销售创新,他们不是在争取覆盖范围,而是在争取利润。
我离开了SAS和Tibco典型的BI供应商...两者都在顶部,这证实了我的信念,即普通的DataScience逻辑上是
从BI增长而来的,而不是从云和Hadoop基础架构中发展出来的。来自业务,即不是来自IT。例如在Gazpromneft中:link,成熟的DSML环境是从可靠的BI实践中发展出来的。但是,也许她对MDM和其他事物有污点和偏见。
SAS
没什么好说的。只有明显的事情。
泰科
该策略在页面长达Wiki的购物清单中读取。是的,长话短说,但28!查尔斯 我年轻时曾贿赂BI Spotfire(2007)。Jaspersoft(2014)以及更多的预测分析供应商提供了更多报告(Insightful(S-plus)(2008),Statistica(2017)和Alpine Data(2017),事件处理和流Streambase System(2013),MDM Orchestra Networks(2018)) )和Snappy Data(2019)内存平台。
嗨,弗兰基!
