
大纹理问题
渲染巨型纹理的想法本身并不新鲜。似乎更容易-加载一百万个百万像素的巨大纹理,并使用它绘制对象。但是,与往常一样,存在一些细微差别:
- 图形API在宽度和高度上限制纹理的最大大小。它可能取决于硬件和驱动程序。今天的最大尺寸是32768x32768像素。
- 即使我们突破了这些限制,32768x32768 RGBA纹理也将占用4 GB的视频内存。视频存储器速度很快,位于宽总线上,但是相对昂贵。因此,它通常小于系统内存,而小于磁盘内存。
1.大纹理的现代渲染
由于图像不符合限制,因此自然会提出一种解决方案-将其分解成碎片(平铺):

此方法的各种变体仍用于分析几何。这不是通用方法;它要求在CPU上进行非平凡的计算。每个图块都作为一个单独的对象绘制,这增加了开销,并且排除了应用双线性纹理过滤的可能性(图块边界之间会有一条可见线)。但是,纹理大小限制可以通过纹理数组来规避!是的,此纹理的宽度和高度仍然有限,但是出现了其他图层。层数也有限制,但是您可以指望2048,尽管火山的规格仅承诺256。在1060 GTX视频卡上,您可以创建包含32768 * 32768 * 2048像素的纹理。只是无法创建它,因为它需要8 TB的内存,并且没有太多的视频内存。如果将其应用于硬件压缩块BC1,则此类纹理将“仅”占用1 TB。它仍然不能放入视频卡中,但是我会告诉您如何处理它。
因此,我们仍然将原始图像切成碎片。但是现在,它不再是每个图块的单独纹理,而只是包含所有图块的巨大纹理数组中的一块。每个块都有自己的索引,所有块按顺序排列。首先按列,然后按行,然后按层:
关于测试纹理的来源有一点点偏离
例如-我从这里拍摄了地球的图像。我将其原始大小从43200x2160增加到65536x32768。当然,这并没有添加细节,但是我得到了所需的图像,该图像不适合一个纹理层。然后,我使用双线性过滤将其递归地减半,直到得到512 x 256像素的图块。然后,将生成的图层打成512x256的图块。压缩它们BC1并将它们顺序写入文件。像这样:
结果,我们得到了一个1,431,633,920字节的文件,由21845个图块组成。512 x 256大小不是随机的。512 x 256 BC1压缩图像正好为65536字节,这是稀疏图像的块大小-本文的英雄。切片大小对于渲染并不重要。
描画大纹理的技术的描述
因此,我们加载了一个纹理数组,其中的图块按列/线/层顺序排列。
然后,绘制此纹理的着色器可能如下所示:
layout(set=0, binding=0) uniform sampler2DArray u_Texture;
layout(location = 0) in vec2 v_uv;
layout(location = 0) out vec4 out_Color;
int lodBase[8] = { 0, 1, 5, 21, 85, 341, 1365, 5461};
int tilesInWidth = 32768 / 512;
int tilesInHeight = 32768 / 256;
int tilesInLayer = tilesInWidth * tilesInHeight;
void main() {
float lod = log2(1.0f / (512.0f * dFdx(v_uv.x)));
int iLod = int(clamp(floor(lod),0,7));
int cellsSize = int(pow(2,iLod));
int tX = int(v_uv.x * cellsSize); //column index in current level of detail
int tY = int(v_uv.y * cellsSize); //row index in current level of detail
int tileID = lodBase[iLod] + tX + tY * cellsSize; //global tile index
int layer = tileID / tilesInLayer;
int row = (tileID % tilesInLayer) / tilesInWidth;
int column = (tileID % tilesInWidth);
vec2 inTileUV = fract(v_uv * cellsSize);
vec2 duv = (inTileUV + vec2(column,row)) / vec2(tilesInWidth,tilesInHeight);
out_Color = texelFetch(u_Texture,ivec3(duv * textureSize(u_Texture,0).xy,layer),0);
}
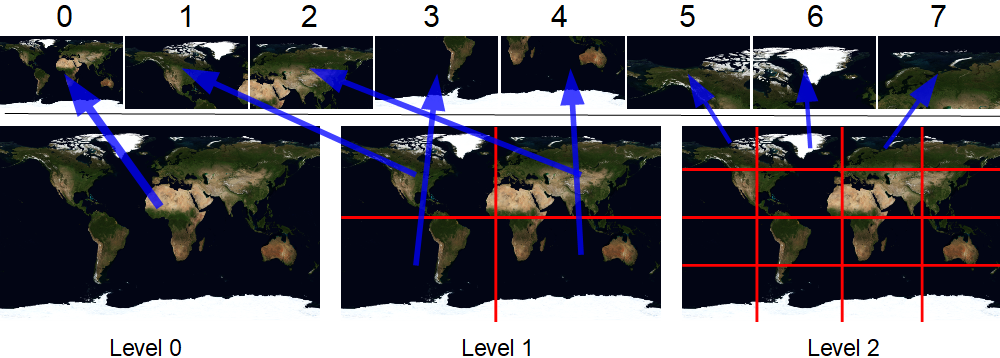
让我们来看看这个着色器。首先,我们需要确定要选择的详细程度。出色的功能dFdx将帮助我们实现这一目标。为了大大简化,它返回在相邻像素中传递的属性较大的值。在演示中,我绘制了一个纹理坐标在0..1范围内的平面矩形。当此矩形为X像素宽时,dFdx(v_uv.x)将返回1 /X。因此,第一级瓦片将以dFdx == 1/512逐像素下降。第二个是1/1024,第三个是1/2048,依此类推。细节级别本身可以如下计算:log2(1.0f /(512.0f * dFdx(v_uv.x)))。让我们从中切除小数部分。然后,我们计算关卡中的宽度/高度有多少块。
让我们使用一个示例来考虑其余部分的计算:

这里lod = 2,u = 0.65,v = 0.37,
因为lod等于2,则cellSize等于4。图片显示此级别包含16个图块(4行4列)-一切正确。
TX = INT(0.65 * 4)= INT(2.6)= 2
TY = INT(0.37 * 4)= INT(1.48)= 1
,即在关卡内,此图块位于第三列和第二行(从零开始索引)。
我们还需要片段的局部坐标(图片中的黄色箭头)。只需将原始纹理坐标乘以行/列中的单元格数量并取小数部分,就可以轻松计算出它们。在上面的计算中,它们已经存在-0.6和0.48。
现在,我们需要此图块的全局索引。为此,我使用了lodBase预计算数组。它通过索引存储先前(较小)所有级别中有多少个图块的值。向其中添加关卡内图块的本地索引。例如,结果为lodBase [2] + 1 * 4 + 2 = 5 + 4 + 2 =11。这也是正确的。
知道了全局索引后,我们现在需要在纹理数组中找到图块的坐标。为此,我们需要知道在宽度和高度上可以容纳多少块瓷砖。他们的乘积是该层中可容纳多少瓷砖。在此示例中,为简单起见,我将这些常量直接拼接在着色器代码中。接下来,我们获取纹理坐标并从中读取纹理像素。请注意,sampler2DArray用作采样器。因此,texelFetch 我们在第三个坐标-层号中传递一个三分量矢量。
纹理未完全加载(部分驻留图像)
如我上面所述,巨大的纹理会占用大量视频内存。而且,从该纹理中使用了非常少的像素。该问题的解决方案-部分居留纹理出现在2011年。简而言之,其本质-可能不在内存中!同时,规范保证应用程序不会崩溃,并且所有已知的实现都保证返回零。此外,该规范还保证,如果支持扩展,则支持的保证块大小(以字节为单位)-64 KB。纹理中构建块的分辨率与此尺寸相关:
| TEXEL SIZE(位) | 方块形状(2D) | 方块形状(3D) |
|---|---|---|
| 4位 | 512×256×1 | 不支持 |
| 8位 | 256×256×1 | 64×32×32 |
| 16位 | 256×128×1 | 32×32×32 |
| 32位 | 128×128×1 | 32×32×16 |
| 64位 | 128×64×1 | 32×16×16 |
| 128位 | 64×64×1 | 16×16×16 |
实际上,规范中没有关于4位纹理像素的任何内容,但是我们始终可以使用vkGetPhysicalDeviceSparseImageFormatProperties来找到它们。
VkSparseImageFormatProperties sparseProps;
ermy::u32 propsNum = 1;
vkGetPhysicalDeviceSparseImageFormatProperties(hphysicalDevice, VK_FORMAT_BC1_RGB_SRGB_BLOCK, VkImageType::VK_IMAGE_TYPE_2D,
VkSampleCountFlagBits::VK_SAMPLE_COUNT_1_BIT, VkImageUsageFlagBits::VK_IMAGE_USAGE_SAMPLED_BIT | VkImageUsageFlagBits::VK_IMAGE_USAGE_TRANSFER_DST_BIT
, VkImageTiling::VK_IMAGE_TILING_OPTIMAL, &propsNum, &sparseProps);
int pageWidth = sparseProps.imageGranularity.width;
int pageHeight = sparseProps.imageGranularity.height;
这种稀疏纹理的创建与通常不同。
首先,必须在VkImageCreateInfo中的标志中指定VK_IMAGE_CREATE_SPARSE_BINDING_BIT和VK_IMAGE_CREATE_SPARSE_RESIDENCY_BIT,
其次,不需要通过内存vkBindImageMemory进行绑定。
您需要通过vkGetImageMemoryRequirements找出可以使用的内存类型。它还会告诉您加载整个纹理需要多少内存,但是我们不需要这个数字。
相反,我们需要在应用程序级别上决定可以同时显示多少个图块?
加载一些图块后,将不再加载其他图块。在演示中,我只是将手指指向天空,并为1,24个图块分配了内存。听起来很浪费,但只有50兆字节,而1.4GB的完全加载纹理。您还需要在主机上分配内存以进行暂存-缓冲区。
const int sparseBlockSize = 65536;
int numHotPages = 512; //
VkMemoryRequirements memReqsOpaque;
vkGetImageMemoryRequirements(device, mySparseImage, &memReqsOpaque); // memoryTypeBits. -
VkMemoryRequirements image_memory_requirements;
image_memory_requirements.alignment = sparseBlockSize ; //
image_memory_requirements.size = sparseBlockSize * numHotPages;
image_memory_requirements.memoryTypeBits = memReqsOpaque.memoryTypeBits;
这样,我们将拥有一个巨大的纹理,其中仅加载了一些零件。它看起来像这样:

瓷砖管理
在下面的内容中,我将使用术语tile表示一块纹理(图中的深绿色和灰色正方形),使用术语page表示一个预先分配在视频内存中的大块中的一块(图中的浅绿色和浅蓝色矩形)。
在创建了这样一个稀疏的VkImage之后,可以通过着色器中的VkImageView使用它。当然,这将是无用的-采样将返回零,没有数据,但是与通常的VkImage不同,不会有任何东西掉落并且调试层不会发誓。进入此纹理的数据不仅需要加载,而且还需要卸载,因为我们可以节省视频内存。
OpenGL方法由驱动程序为每个块提供内存分配,在我看来似乎并不正确。是的,也许在那里使用了一些聪明而快速的分配器,因为块大小是固定的。事实证明,在火山中稀疏驻留纹理的示例中使用了类似的方法。但是无论如何,选择一个大的线性页面块,然后在应用程序侧将这些页面绑定到特定的纹理图块并用数据填充它们绝对不会变慢。
因此,稀疏纹理的接口将包括以下方法:
void CommitTile(int tileID, void* dataPtr); // 64
void FreeTile(int tileID);
void Flush();
为了分组瓷砖的填充/释放,需要最后一种方法。一次更新一个瓦片非常昂贵,每帧更新一次。让我们按顺序查看它们。
//void CommitTile(int tileID, void* dataPtr)
int freePageID = _getFreePageID();
if (freePageID != -1)
{
tilesByPageIndex[freePageID] = tileID;
tilesByTileID[tileID] = freePageID;
memcpy(stagingPtr + freePageID * pageDataSize, tileData, pageDataSize);
int pagesInWidth = textureWidth / pageWidth;
int pagesInHeight = textureHeight / pageHeight;
int pagesInLayer = pagesInWidth * pagesInHeight;
int layer = tileID / pagesInLayer;
int row = (tileID % pagesInLayer) / pagesInWidth;
int column = tileID % pagesInWidth;
VkSparseImageMemoryBind mbind;
mbind.subresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
mbind.subresource.mipLevel = 0;
mbind.subresource.arrayLayer = layer;
mbind.extent.width = pageWidth;
mbind.extent.height = pageHeight;
mbind.extent.depth = 1;
mbind.offset.x = column * pageWidth;
mbind.offset.y = row * pageHeight;
mbind.offset.z = 0;
mbind.memory = optimalTilingMem;
mbind.memoryOffset = freePageID * pageDataSize;
mbind.flags = 0;
memoryBinds.push_back(mbind);
VkBufferImageCopy copyRegion;
copyRegion.bufferImageHeight = pageHeight;
copyRegion.bufferRowLength = pageWidth;
copyRegion.bufferOffset = mbind.memoryOffset;
copyRegion.imageExtent.depth = 1;
copyRegion.imageExtent.width = pageWidth;
copyRegion.imageExtent.height = pageHeight;
copyRegion.imageOffset.x = mbind.offset.x;
copyRegion.imageOffset.y = mbind.offset.y;
copyRegion.imageOffset.z = 0;
copyRegion.imageSubresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
copyRegion.imageSubresource.baseArrayLayer = layer;
copyRegion.imageSubresource.layerCount = 1;
copyRegion.imageSubresource.mipLevel = 0;
copyRegions.push_back(copyRegion);
return true;
}
return false;
首先,我们需要找到一个空闲块。我只是遍历这些页面的数组,并寻找第一个包含存根编号-1的页面。这将是空闲页面的索引。我使用memcpy将数据从磁盘复制到暂存缓冲区。源是具有特定图块偏移量的内存映射文件。此外,通过图块的ID,我可以考虑其在纹理数组中的位置(x,y,层)。
接下来,最有趣的部分开始-填充VkSparseImageMemoryBind结构。是她将视频内存绑定到图块。它的重要字段是:
memory。这是一个VkDeviceMemory对象。它为所有页面预分配了内存。
memoryOffset。这是我们需要的页面的字节偏移量。
接下来,我们需要将数据从登台缓冲区复制到此新绑定的内存中。这是使用vkCmdCopyBufferToImage完成的。
由于我们将一次复制许多部分,因此在此位置我们仅填写结构,并说明要复制的位置和位置。这里重要的是bufferOffset,它指示登台缓冲区中已经存在的偏移量。在这种情况下,它与视频内存中的偏移量一致,但是策略可以不同。例如,将瓷砖分为热,暖和冷。热的存储在视频内存中,热的存储在内存中,冷的存储在磁盘上。然后,登台缓冲区可以更大,并且偏移量也可以不同。
//void FreeTile(int tileID)
if (tilesByTileID.count(tileID) > 0)
{
i16 hotPageID = tilesByTileID[tileID];
int pagesInWidth = textureWidth / pageWidth;
int pagesInHeight = textureHeight / pageHeight;
int pagesInLayer = pagesInWidth * pagesInHeight;
int layer = tileID / pagesInLayer;
int row = (tileID % pagesInLayer) / pagesInWidth;
int column = tileID % pagesInWidth;
VkSparseImageMemoryBind mbind;
mbind.memory = optimalTilingMem;
mbind.subresource.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
mbind.subresource.mipLevel = 0;
mbind.subresource.arrayLayer = layer;
mbind.extent.width = pageWidth;
mbind.extent.height = pageHeight;
mbind.extent.depth = 1;
mbind.offset.x = column * pageWidth;
mbind.offset.y = row * pageHeight;
mbind.offset.z = 0;
mbind.memory = VK_NULL_HANDLE;
mbind.memoryOffset = 0;
mbind.flags = 0;
memoryBinds.push_back(mbind);
tilesByPageIndex[hotPageID] = -1;
tilesByTileID.erase(tileID);
return true;
}
return false;
这是我们将内存与磁贴解耦的地方。为此,分配内存VK_NULL_HANDLE。
//void Flush();
cbuff = hostDevice->CreateOneTimeSubmitCommandBuffer();
VkImageSubresourceRange imageSubresourceRange;
imageSubresourceRange.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
imageSubresourceRange.baseMipLevel = 0;
imageSubresourceRange.levelCount = 1;
imageSubresourceRange.baseArrayLayer = 0;
imageSubresourceRange.layerCount = numLayers;
VkImageMemoryBarrier bSamplerToTransfer;
bSamplerToTransfer.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
bSamplerToTransfer.pNext = nullptr;
bSamplerToTransfer.srcAccessMask = 0;
bSamplerToTransfer.dstAccessMask = VK_ACCESS_TRANSFER_WRITE_BIT;
bSamplerToTransfer.oldLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
bSamplerToTransfer.newLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
bSamplerToTransfer.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bSamplerToTransfer.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bSamplerToTransfer.image = opaqueImage;
bSamplerToTransfer.subresourceRange = imageSubresourceRange;
VkSparseImageMemoryBindInfo imgBindInfo;
imgBindInfo.image = opaqueImage;
imgBindInfo.bindCount = memoryBinds.size();
imgBindInfo.pBinds = memoryBinds.data();
VkBindSparseInfo sparseInfo;
sparseInfo.sType = VK_STRUCTURE_TYPE_BIND_SPARSE_INFO;
sparseInfo.pNext = nullptr;
sparseInfo.waitSemaphoreCount = 0;
sparseInfo.pWaitSemaphores = nullptr;
sparseInfo.bufferBindCount = 0;
sparseInfo.pBufferBinds = nullptr;
sparseInfo.imageOpaqueBindCount = 0;
sparseInfo.pImageOpaqueBinds = nullptr;
sparseInfo.imageBindCount = 1;
sparseInfo.pImageBinds = &imgBindInfo;
sparseInfo.signalSemaphoreCount = 0;
sparseInfo.pSignalSemaphores = nullptr;
VkImageMemoryBarrier bTransferToSampler;
bTransferToSampler.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
bTransferToSampler.pNext = nullptr;
bTransferToSampler.srcAccessMask = 0;
bTransferToSampler.dstAccessMask = VK_ACCESS_SHADER_READ_BIT;
bTransferToSampler.oldLayout = VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL;
bTransferToSampler.newLayout = VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL;
bTransferToSampler.srcQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bTransferToSampler.dstQueueFamilyIndex = VK_QUEUE_FAMILY_IGNORED;
bTransferToSampler.image = opaqueImage;
bTransferToSampler.subresourceRange = imageSubresourceRange;
vkQueueBindSparse(graphicsQueue, 1, &sparseInfo, fence);
vkWaitForFences(device, 1, &fence, true, UINT64_MAX);
vkResetFences(device, 1, &fence);
vkCmdPipelineBarrier(cbuff, VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT, VK_PIPELINE_STAGE_TRANSFER_BIT, 0, 0, nullptr, 0, nullptr, 1, &bSamplerToTransfer);
if (copyRegions.size() > 0)
{
vkCmdCopyBufferToImage(cbuff, stagingBuffer, opaqueImage, VkImageLayout::VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL, copyRegions.size(), copyRegions.data());
}
vkCmdPipelineBarrier(cbuff, VK_PIPELINE_STAGE_TRANSFER_BIT, VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT, 0, 0, nullptr, 0, nullptr, 1, &bTransferToSampler);
hostDevice->ExecuteCommandBuffer(cbuff);
copyRegions.clear();
memoryBinds.clear();
主要工作以这种方法进行。在调用它的时候,我们已经有两个带有VkSparseImageMemoryBind和VkBufferImageCopy的数组。我们填写用于调用vkQueueBindSparse的结构,然后调用它。这不是一个阻塞函数(就像Vulkan中的几乎所有函数一样),因此我们将需要显式等待其执行。为此,将最后一个参数传递给它VkFence,我们将等待其执行。实际上,就我而言,等待这个隔离栅丝毫不影响程序的性能。但是,从理论上讲,这是必需的。
将内存附加到图块后,需要在图块中填写图片。这是通过vkCmdCopyBufferToImage函数完成的。
您可以使用布局将数据填充到纹理中VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL,并将它们放入具有布局VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL的着色器中。因此,我们需要两个障碍。请注意,在VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL中,我们严格从VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL而不是从VK_IMAGE_LAYOUT_UNDEFINED进行翻译。由于我们仅填充纹理的一部分,因此对我们来说重要的是不要丢失之前填充的那些部分。
这是有关其工作原理的视频。一种纹理。一个对象。数以万计的瓷砖。
幕后还剩下的是如何在应用程序中确定如何实际找出哪个磁贴需要加载和卸载。在描述新方法好处的部分中,要点之一是可以使用复杂的几何图形。在同一测试中,我本人使用最简单的正交投影和矩形。而且我会分析地计算瓷砖的ID。不喜欢运动。
实际上,可见图块的ID被计数两次。解析地在CPU上,诚实地在片段着色器上。看起来,为什么不从片段着色器中拾取它们呢?但这不是那么简单。这将是第二篇文章。