对于小麦遗传学,一项重要任务是确定倍性(细胞核中相同的染色体组数)。解决此问题的经典方法是基于分子遗传方法的使用,这种方法昂贵且劳动强度大。仅在实验室条件下才能确定植物类型。因此,在这项工作中,我们检验了以下假设:是否可以仅基于耳朵的图像,使用计算机视觉方法确定小麦的倍性。

资料说明
为了解决这个问题,甚至在研讨会开始之前,就已经准备了一个数据集,其中每个植物物种的倍性都是已知的。我们总共可以使用2344张六倍体照片和1259张四脯氨酸照片。
大多数植物是使用两种方案拍照的。第一种情况-在桌子上有一个投影,第二个案例-在衣夹上有4个投影。在照片中,始终会出现colorchecker的调色板,需要对其进行归一化并确定比例。

总共3603张照片,带有644个唯一的种子编号。数据集包含20种小麦:10种六倍体,10种四倍体; 496种独特的基因型; 10种独特的植被。 2015年至2018年间在温室中种植了植物ICG SB RAS。生物材料由尼古拉·彼得罗维奇·贡恰洛夫院士提供。
验证方式
我们数据集中的一棵植物最多可以对应5张使用不同协议和不同投影拍摄的照片。我们将数据分为3个分层集:训练(训练样本),有效(验证样本)和保留(延迟样本),比率分别为60%,20%和20%。在划分时,我们考虑到某个基因型的所有照片将始终出现在一个子样本中。该验证方案已用于所有训练有素的模型。
尝试经典的CV和ML方法
我们用来解决问题的第一种方法是基于我们先前开发的现有算法。该算法允许从每个图像中提取固定的一组不同的定量特征。例如,耳朵的长度,芒的面积等。有关该算法的详细说明,请参阅Genaev等人的《通过分析2D图像的小麦穗形态分析》,2019年。使用此算法和机器学习方法,我们训练了几种模型来预测倍性的类型。
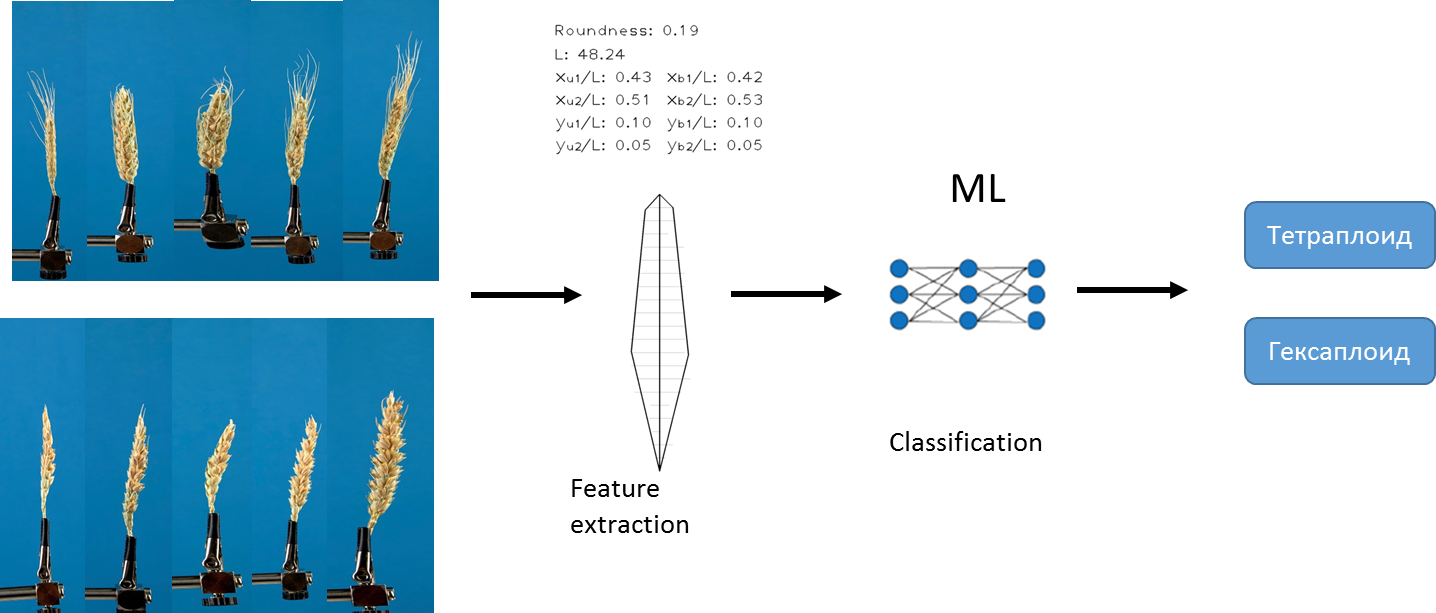
我们使用了Logistic回归方法,随机森林和梯度增强。数据已预先规范化... 我们选择AUC作为衡量准确性的标准。
| 方法 | 培养 | 有效 | 坚持 |
| 逻辑回归 | 0.77 | 0.70 | 0.72 |
| 随机森林 | 1.00 | 0.83 | 0.82 |
| 提升 | 0.99 | 0.83 | 0.85 |
梯度提升方法显示了延迟采样的最佳精度;我们使用了CatBoost实现。
解释结果
对于每个模型,我们收到每个特征的“重要性”的估计值。结果,我们获得了所有功能的列表,并根据它们的重要性进行了排名,并选择了前10个功能:遮阳篷面积,圆度指数,圆度,周长,茎长,xu2,L,xb2,yu2,ybm。 (每个功能的描述可以在此处找到)。
重要特征的一个例子是耳朵的长度和周长。这些特性在四倍体和六倍体中的值分布在直方图上显示。可以看出六倍体的分布向更高的值移动。

我们使用t-SNE方法对前10个功能进行了聚类
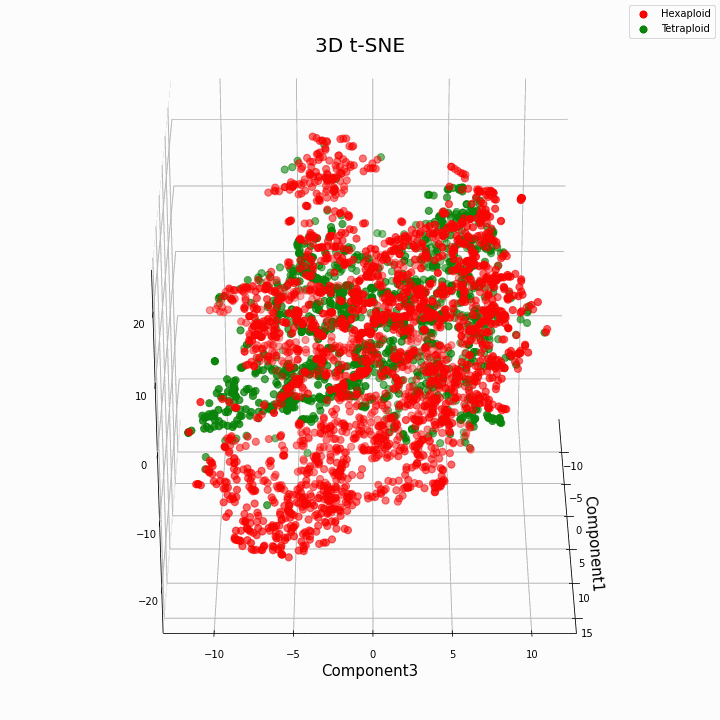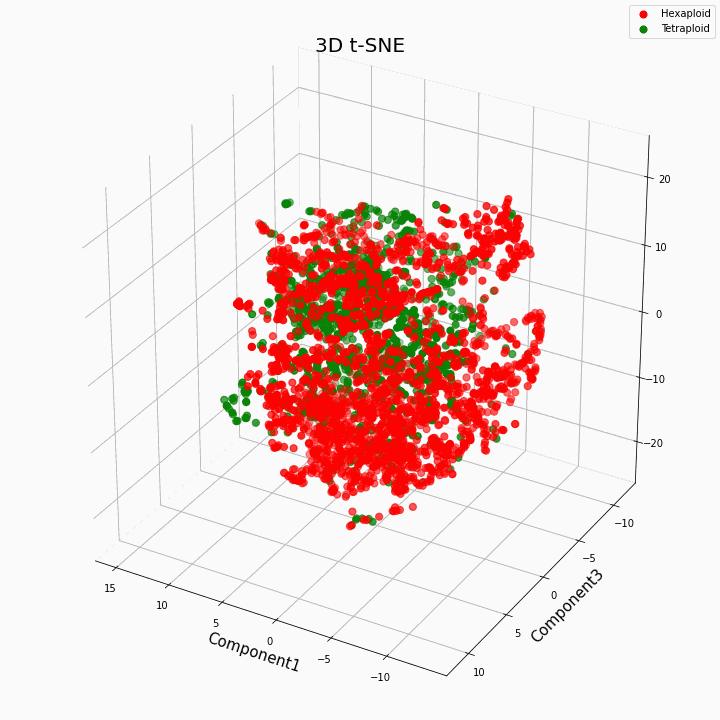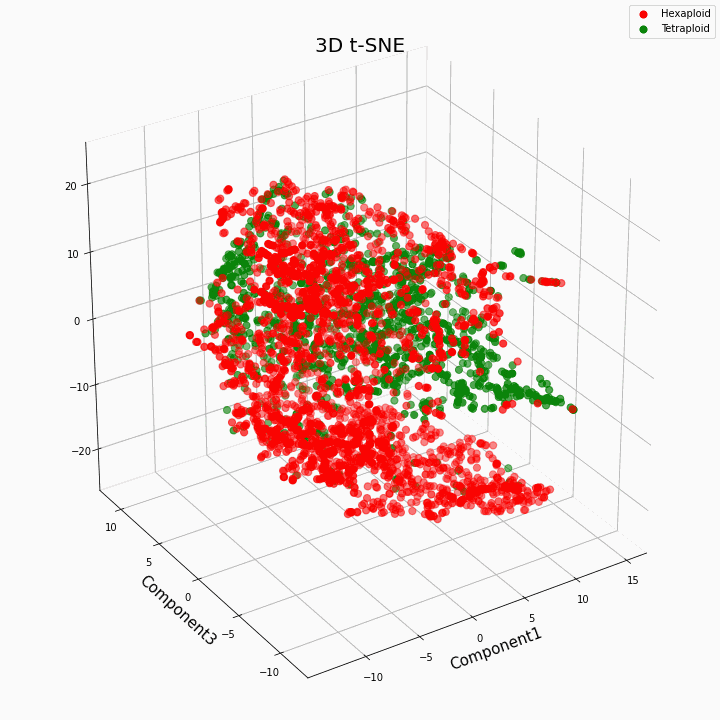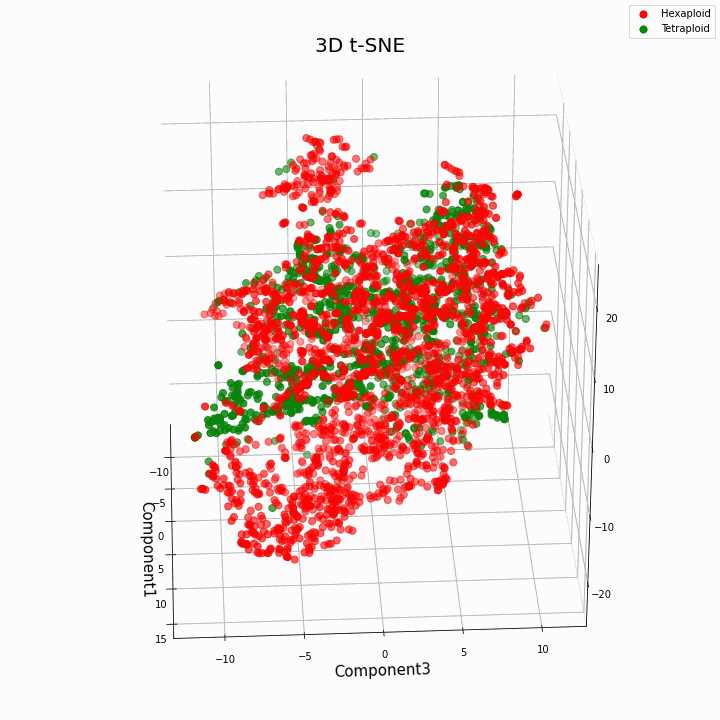
总的来说,更大的倍性赋予性状更多的可变值。六倍体的特征在于性状值的更大的散布/方差。这是因为六倍体中基因的拷贝数更多,因此这些基因的“功”变体的数目增加了。
为了证实我们关于六倍体表型变异性更大的假设,我们使用了F统计量。 F统计量给出了两个分布方差差异的重要性。我们考虑了p值小于0.05的情况,以驳斥两种分布之间没有差异的零假设。我们针对每个特征独立运行此测试。测试条件:应该有一个独立观察的样本(对于多幅图像,不是这种情况)和正态分布。为了满足这些条件,我们测试了每只耳朵的一张图像。他们仅按照“桌子”上的协议在一个投影中拍摄照片。结果显示在表中。可以看出,六倍体和四倍体的方差在7个字符上有显着差异。此外,在所有情况下,六倍体的分散值均较高。六倍体中较大的表型变异性可以通过一个基因的大量拷贝来解释。
| Name | F-statistic | p-value | Disp Hexaploid | Disp Tetraploid |
| Awns area | 0.376 | 1.000 | 1.415 | 3.763 |
| Circularity index | 1.188 | 0.065 | 0.959 | 0.807 |
| Roundness | 1.828 | 0.000 | 1.312 | 0.718 |
| Perimeter | 1.570 | 0.000 | 1.080 | 0.688 |
| Stem length | 3.500 | 0.000 | 1.320 | 0.377 |
| xu2 | 3.928 | 0.000 | 1.336 | 0.340 |
| L | 3.500 | 0.000 | 1.320 | 0.377 |
| xb2 | 4.437 | 0.000 | 1.331 | 0.300 |
| yu2 | 4.275 | 0.000 | 2.491 | 0.583 |
| ybm | 1.081 | 0.248 | 0.695 | 0.643 |
我们的数据包括20种植物。 10个六倍体小麦和10个四倍体。
我们对聚类结果进行了着色,以使每个点的颜色+形状与特定视图相对应。

大多数物种在图表上占据相当紧凑的区域。尽管这些领域可以与其他领域重叠很多。另一方面,在一个物种内,可以有明确定义的簇,例如,紧凑型T,Peropavlovskyi。
我们对10个特征的每个物种的值进行平均,得到10的表20.其中20个物种中的每个对应于10个特征的向量。对于这些数据,建立了一个相关矩阵,并进行了层次聚类分析。图中的蓝色方块对应四倍体。

通常,在人工树上,小麦种类分为四倍体和六倍体。六倍体物种清楚地分为两个簇:中毛-玛氏茶,普通小麦,云南香菜和长毛-瓦氏乳杆菌,petropavlovskyi,斯佩尔塔毛。唯一的例外是,唯一的野生多倍体(四倍体)物种T. dicoccoides被分类为六倍体。
同时,四倍体物种包括具有紧密穗型的六倍体小麦-T. compactum,T。antiquorum和T. sphaerococcum,以及普通小麦的人造等基因系ANK-23。
尝试CNN

为了解决从耳朵的图像确定小麦倍性的问题,我们训练了EfficientNet B0体系结构的卷积神经网络,并在ImageNet上预训练了权重。 CrossEntropyLoss被用作损失函数;亚当优化器;一批的大小是16;图像调整为224x224;学习率根据fit_one_cycle策略更改,初始lr = 1e-4。我们对网络进行了10个时期的训练,随机应用以下增强功能:旋转-20 +20度,更改亮度,对比度,饱和度,镜像。根据AUC度量标准选择最佳模型,在每个时期结束时计算其值。
其结果是,在精确度上的延迟样本AUC = 0.995,其对应于accuracy_score= 0.987,误差为1.3%。这是一个很好的结果。
结论
这项工作很好地说明了一个由5个学生和2个策展人组成的团队如何在几个星期内解决紧急生物学问题并获得新的科学成果的方法。
我想表达我的感激之情,在我们项目的所有参与者:尼基塔Prokhoshin,阿列克谢·普里霍季科,叶夫根尼·Zavarzin,阿尔乔姆Pronozin,安娜Paulish,叶夫根尼·Komyshev,米哈伊尔Genaev。
Koval Vasily Sergeevich和Kruchinina Yulia Vladimirovna拍摄玉米穗。
Nikolai Petrovich Goncharov和Afonnikov Dmitry Arkadyevich提供了所提供的生物材料,并有助于解释结果。
新西伯利亚州立大学数学中心和细胞学和俄罗斯科学院西伯利亚分院遗传学研究所组织的活动和计算能力。

PS我们打算准备本文的第二部分,在这里我们将告诉您有关穗的细分和单个穗的选择。