你好!我们-ITMO机器学习实验室的科学家以及VKontakte的Core ML团队-正在进行联合研究。VK的重要任务之一是帖子的自动分类:不仅需要生成主题提要,而且还必须识别不需要的内容。评估人员参与了此类记录的处理。同时,使用诸如主动学习的机器学习范例可以显着降低他们的工作成本。
本文将讨论它在多模式数据分类中的应用。我们将向您介绍主动学习的一般原理和方法,将其应用于任务的特殊性以及在研究过程中获得的见解。

介绍
— machine learning, . , , , .
, (, Amazon Mechanical Turk, .) . — reCAPTCHA, , , , — Google Street View. — .
Amazon DALC (Deep Active Learning from targeted Crowds). , . Monte Carlo Dropout ( ). — noisy annotation. , « , », .
Amazon . : / . , , . , : , . .
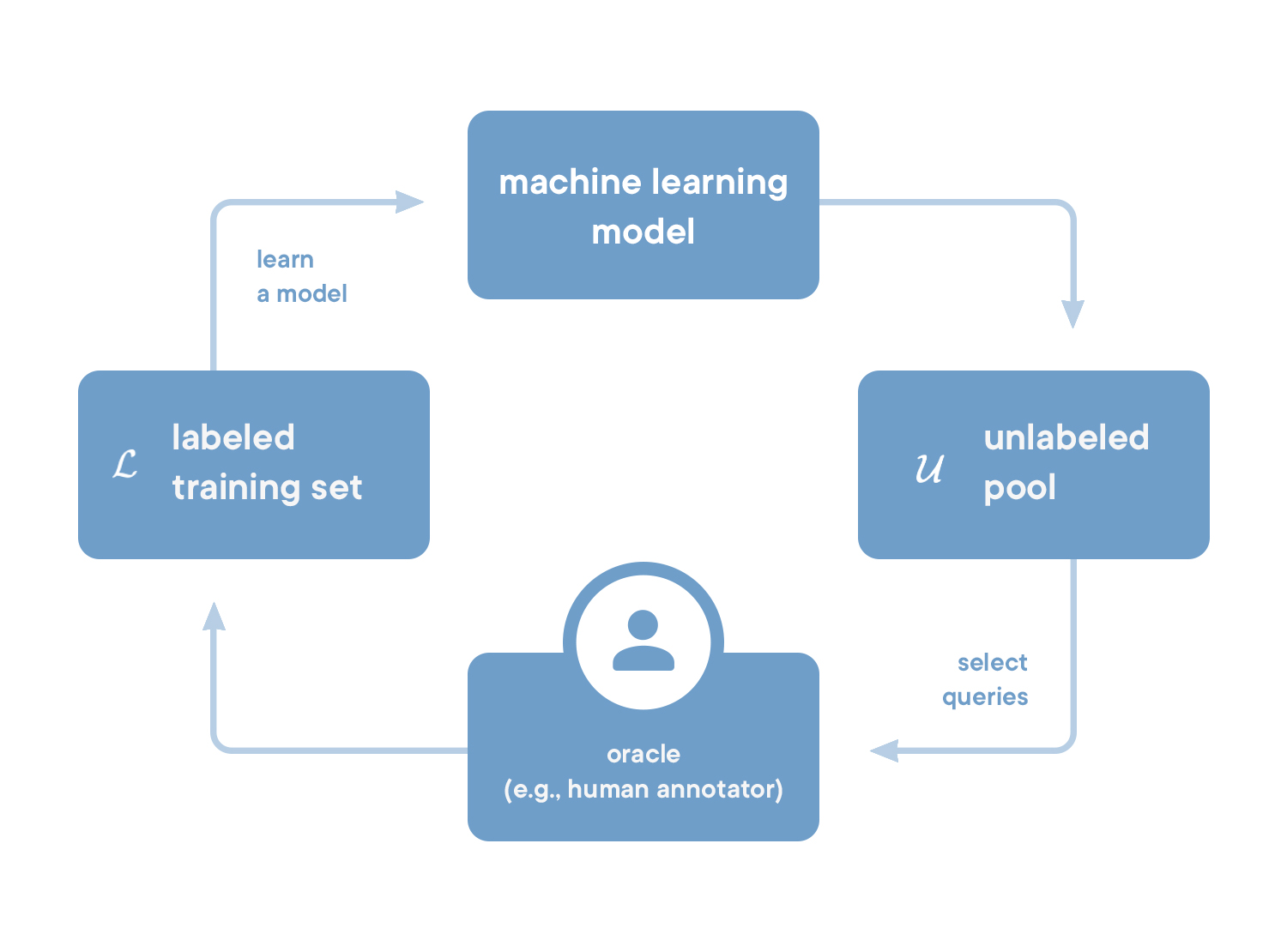
. 1. pool-based
. , , ( ). : , .
, — . (. — query). , . ( , ) .
, , .
, — . ( ). ≈250 . . () 50 — — :
- , (. embedding), ;
- .
, (. . 2).
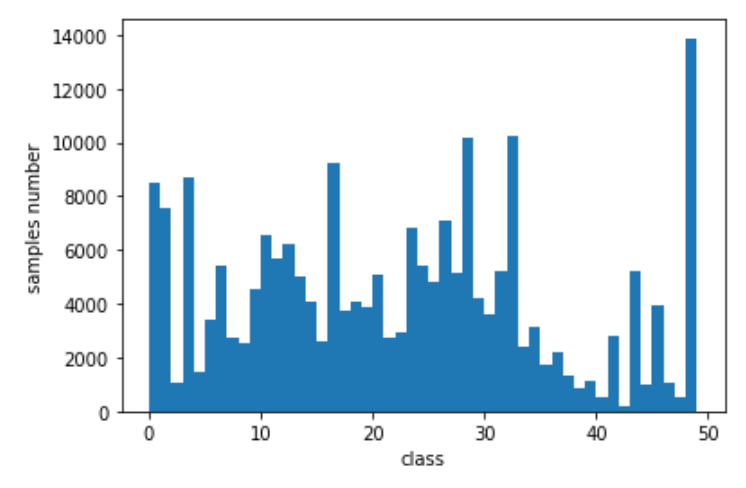
. 2 —
ML — . , .
. , . , , , . , , early stopping. , .
. residual , highway , (. encoder). , (. fusion): , .
— , . -.
, — , . , .
. , (. 3):
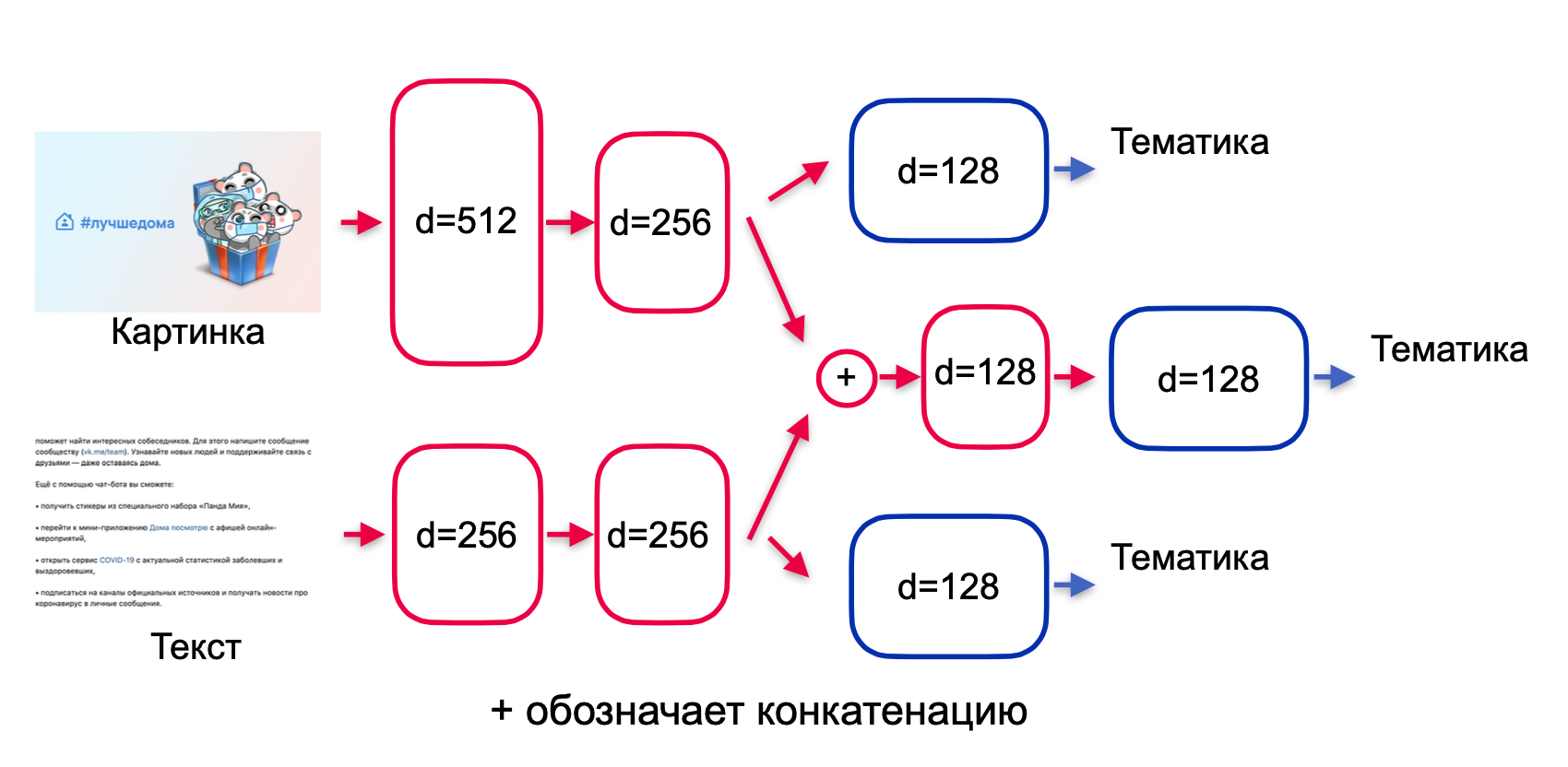
. 3.
. , . , , . , ( + ) — .
, . 3, :
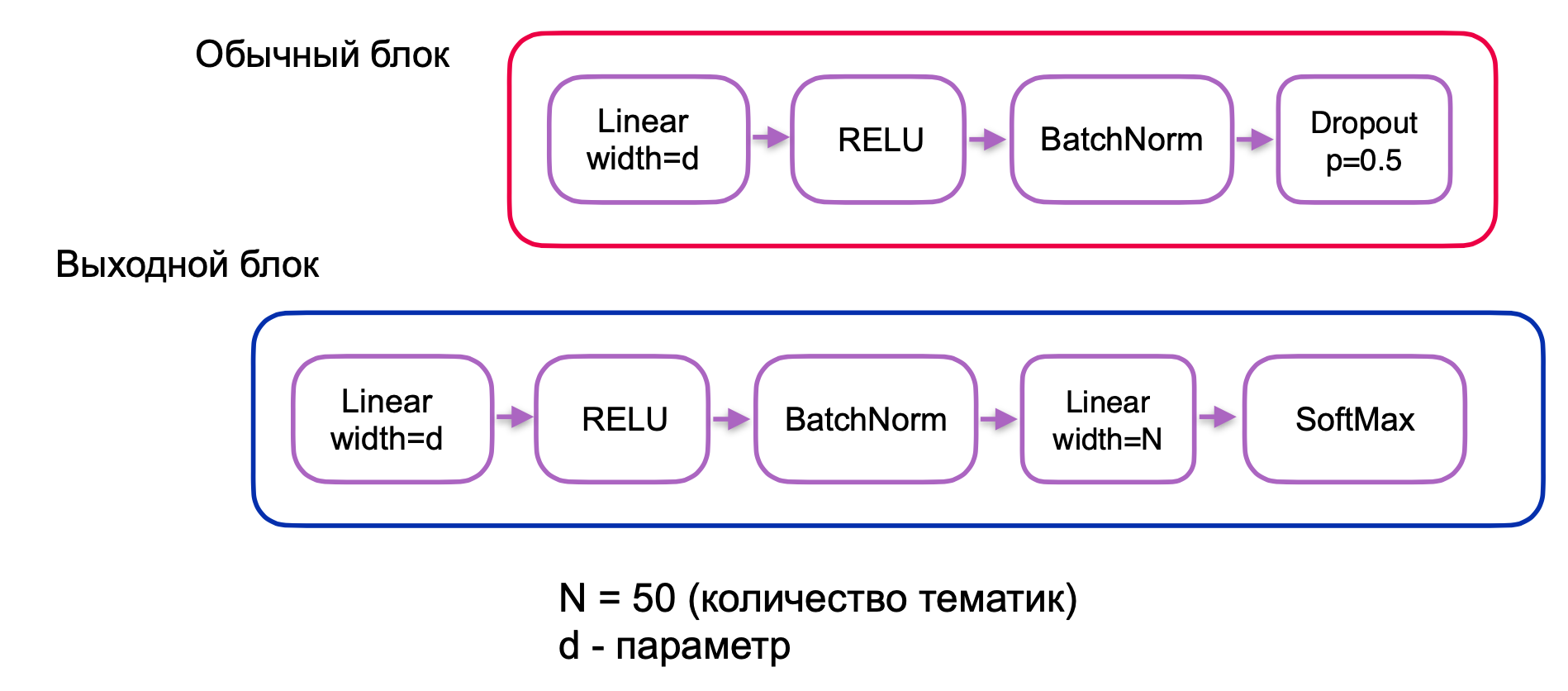
. 4.
, , . , ó , , .
, : ? :
- ;
- ;
- .
. : maximum likelihood , - . :
— ( -), — , .
Pool-based sampling
— , . pool-based sampling :
- - .
- .
- , , .
- .
- ( ).
- 3–5 (, ).
, 3–6 — .
, , :
, . , : . , , , . . , 2 000.
. , . ( ). , , . , . 20 .
. , . — , . 100 200.
, , , .
№1: batch size
baseline , ( ) (. 5).
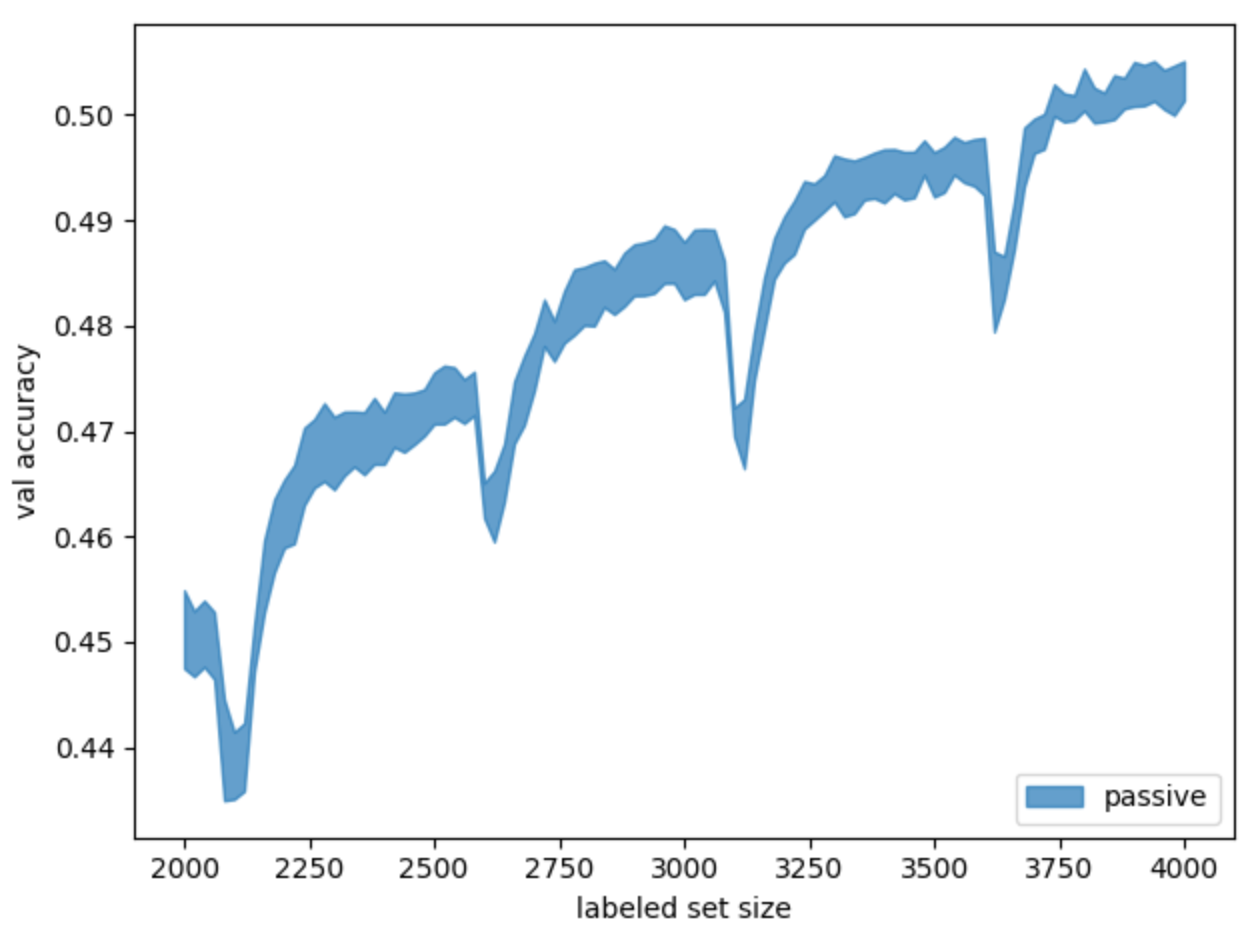
. 5. baseline- .
random state. .
. «» , , .
, (. batch size). 512 — - (50). , batch size . . :
- upsample, ;
- , .
batch size: (1).
— batch size, — .
“” (. 6).

. 6. batch size (passive ) (passive + flexible )
: c . , , batch size . .
.
Uncertainty
:
1. (. Least confident sampling)
, :
— , — , — , — , .
该措施可以理解如下。假设对象丢失函数看起来像. , . .
. , : {0,5; 0,49; 0,01}, — {0,49; 0,255; 0,255}. , (0,49) , (0,5). , ó : . , .
2. (. Margin sampling)
, , , :
— , — .
, . , . , , MNIST ( ) — , . .
3. (. Entropy sampling)
:
— - .
, , . :
- , , ;
- , .
(. 7).
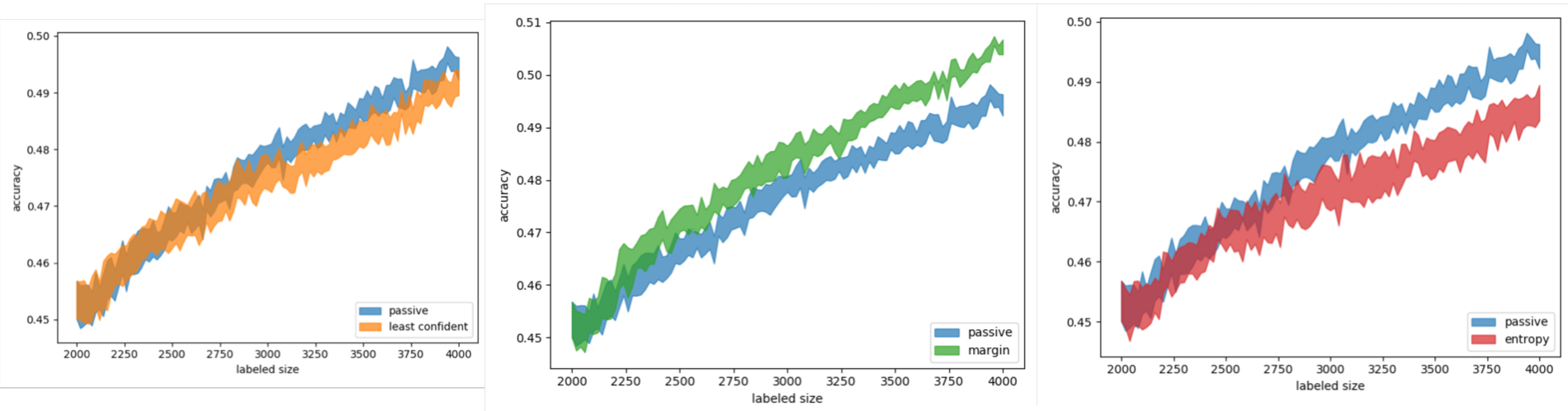
. 7. uncertainty sampling ( — , — , — )
, least confident entropy sampling , . margin sampling .
, , : MNIST. , , entropy sampling , . , .
. , — , — . , .
BALD
, , — BALD sampling (Bayesian Active Learning by Disagreement). .
, query-by-committee (QBC). — . uncertainty sampling. , . QBC Monte Carlo Dropout, .
, , — . dropout . dropout , ( ). , dropout- (. 8). Monte Carlo Dropout (MC Dropout) . , . ( dropout) Mutual Information (MI). MI , , — , . .
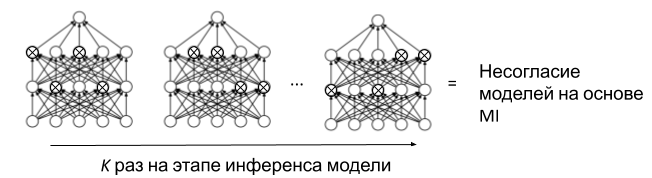
. 8. MC Dropout BALD
, QBC MC Dropout uncertainty sampling. , (. 9).
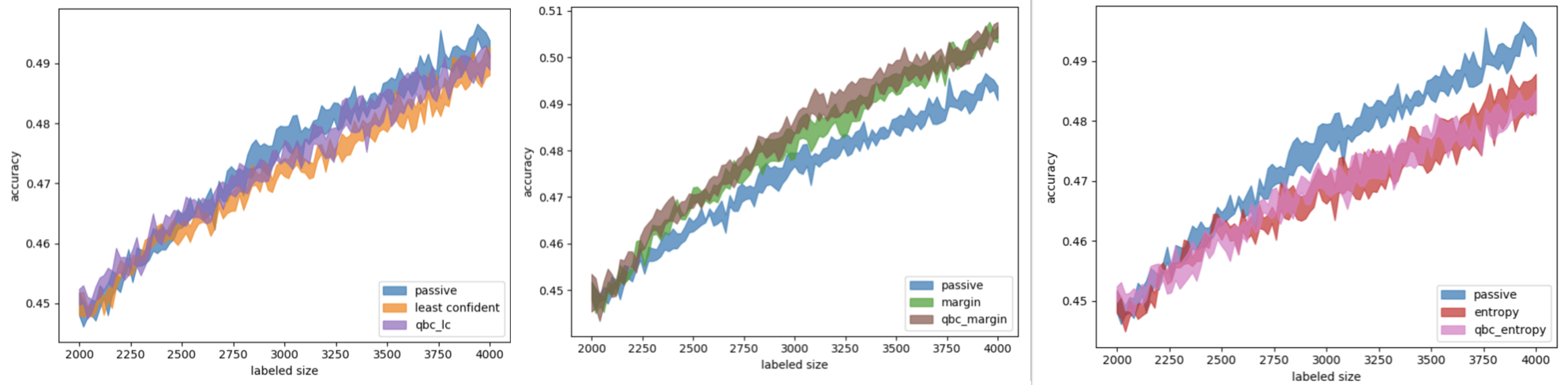
. 9. uncertainty sampling ( QBC ) ( — , — , — )
BALD. , Mutual Information :
— , — .
(5) , — . , , . BALD . 10.

. 10. BALD
, , .
query-by-committee BALD , . , uncertainty sampling. , — , — , — , — , .
BALD tf.keras, . PyTorch, dropout , batch normalization , .
№2: batch normalization
batch normalization. batch normalization — , . , , , , batch normalization. , . , . BALD. (. 11).
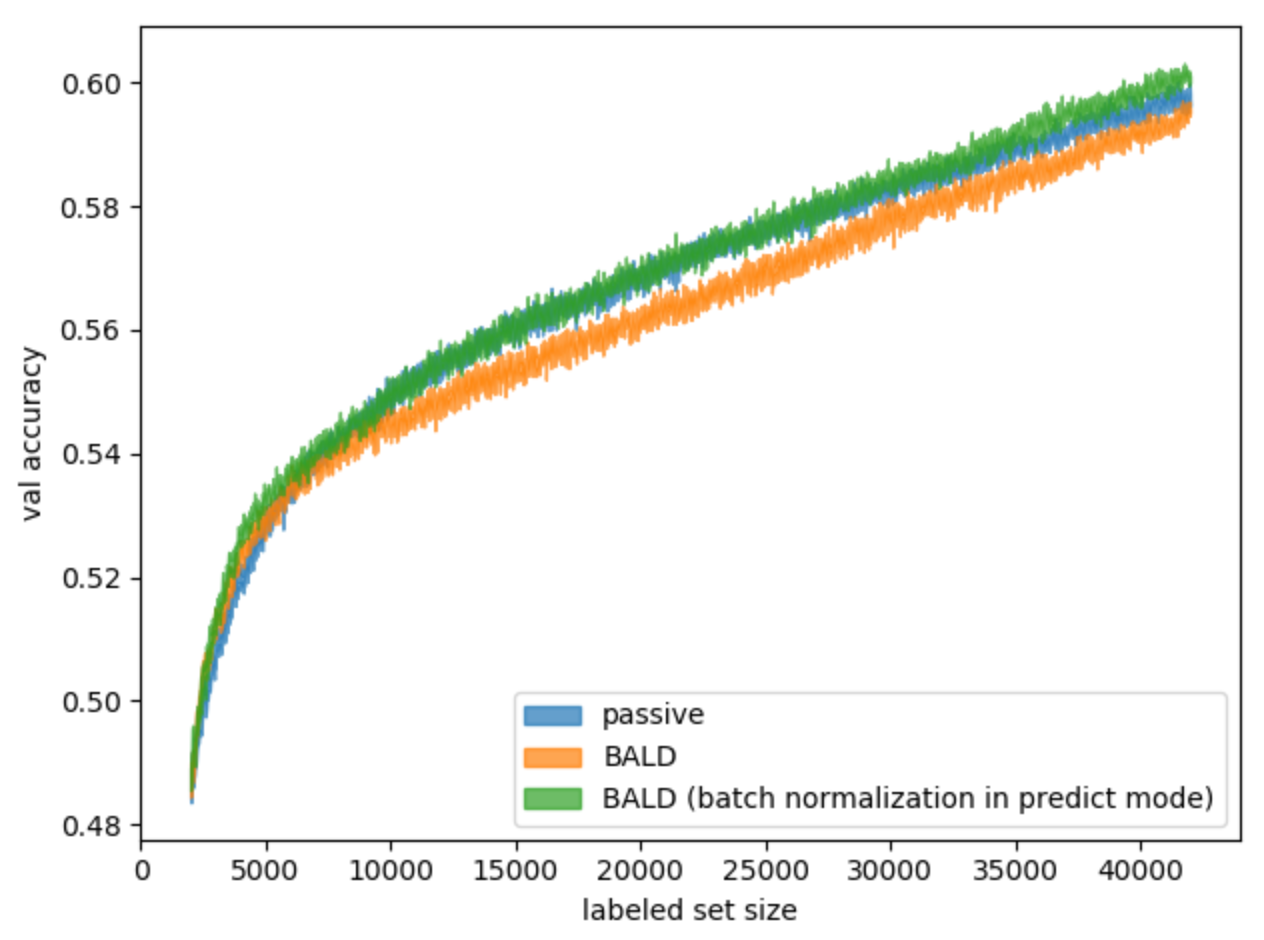
. 11. batch normalization BALD
, , .
batch normalization, . , .
Learning loss
. , . , .
, . — . , . learning loss, . , (. 12).
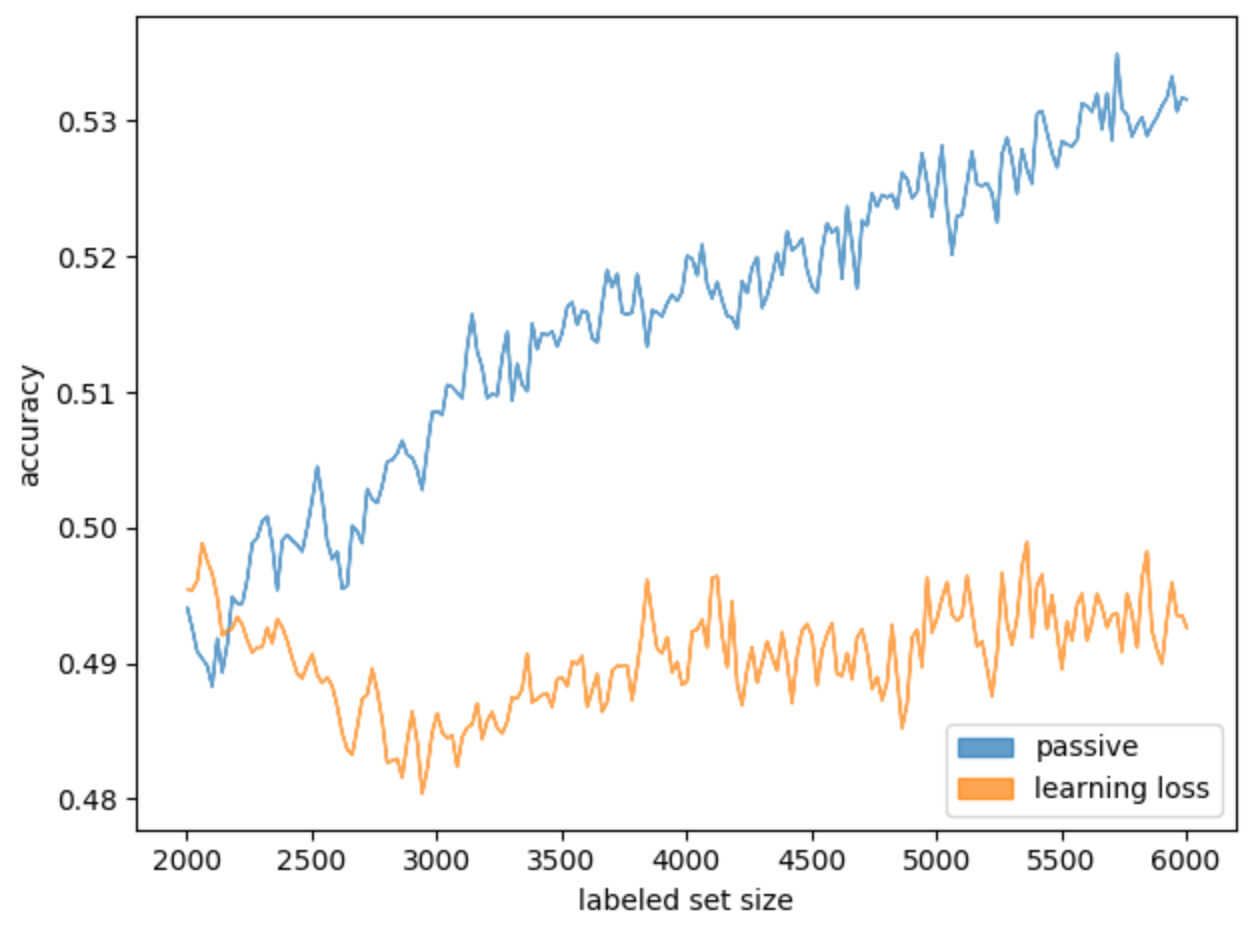
. 12. Learning loss
learning loss . .
. , . «» learning loss: , , . ideal learning loss (. 13).

. 13. ideal learning loss
, learning loss.
, . , , - , . :
- (2000 ), ;
- 10000 ( );
- ;
- ;
- 100 ;
- , , 1;
- .
, , . , ( margin sampling).
1.
| p-value | ||
|---|---|---|
| loss | -0,2518 | 0,0115 |
| margin | 0,2461 | 0,0136 |
, margin sampling — , , , . c .
: ?
, , (. 14).
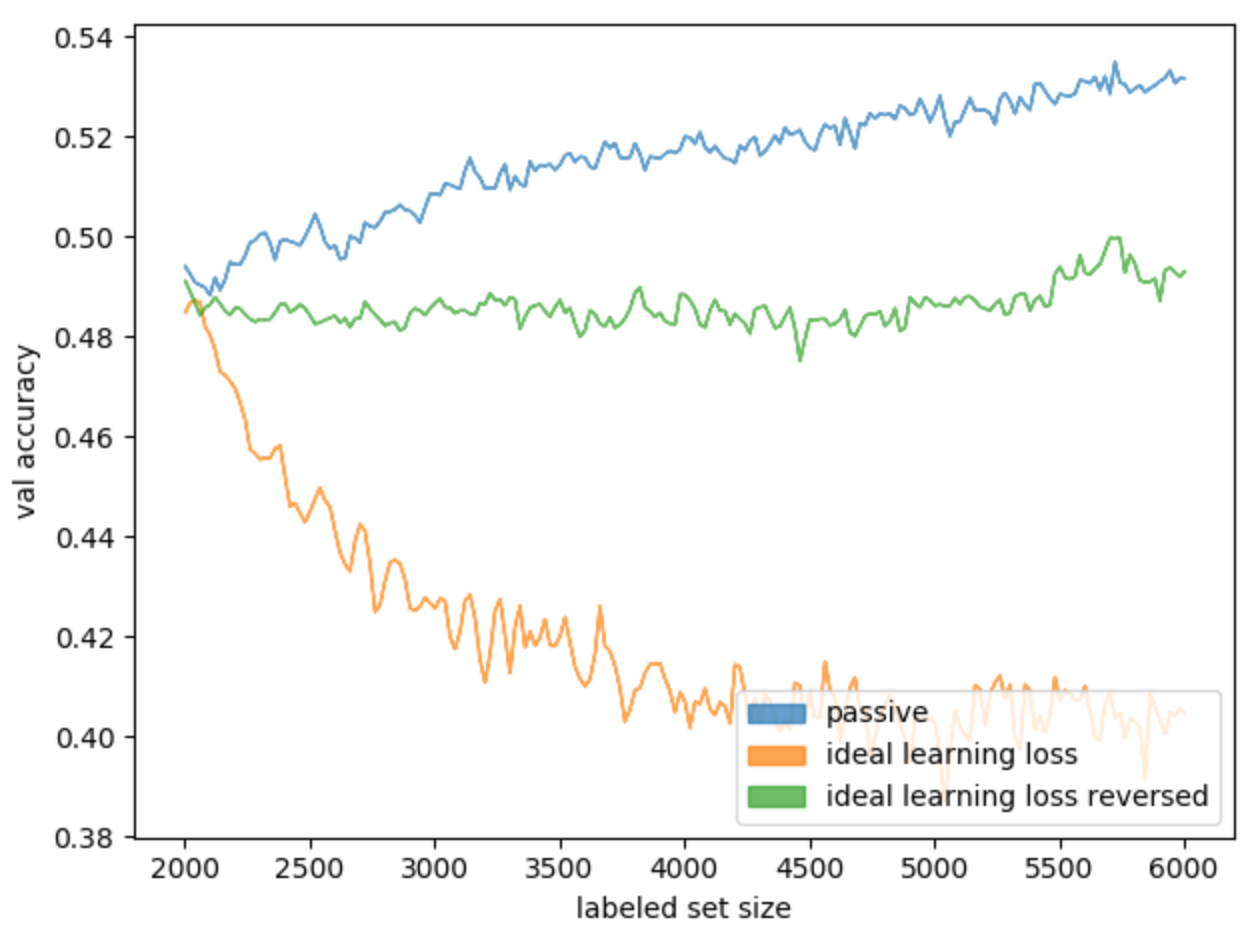
. 14. ideal learning loss ideal learning loss
, MNIST :
2. MNIST
| p-value | ||
|---|---|---|
| loss | 0,2140 | 0,0326 |
| 0,2040 | 0,0418 |
ideal learning loss , (. 15).

. 15. MNIST ideal learning loss. — ideal learning loss, —
, , , , . .
learning loss , uncertainty sampling: , — , — . , , . , .
, . . , margin sampling — . 16.
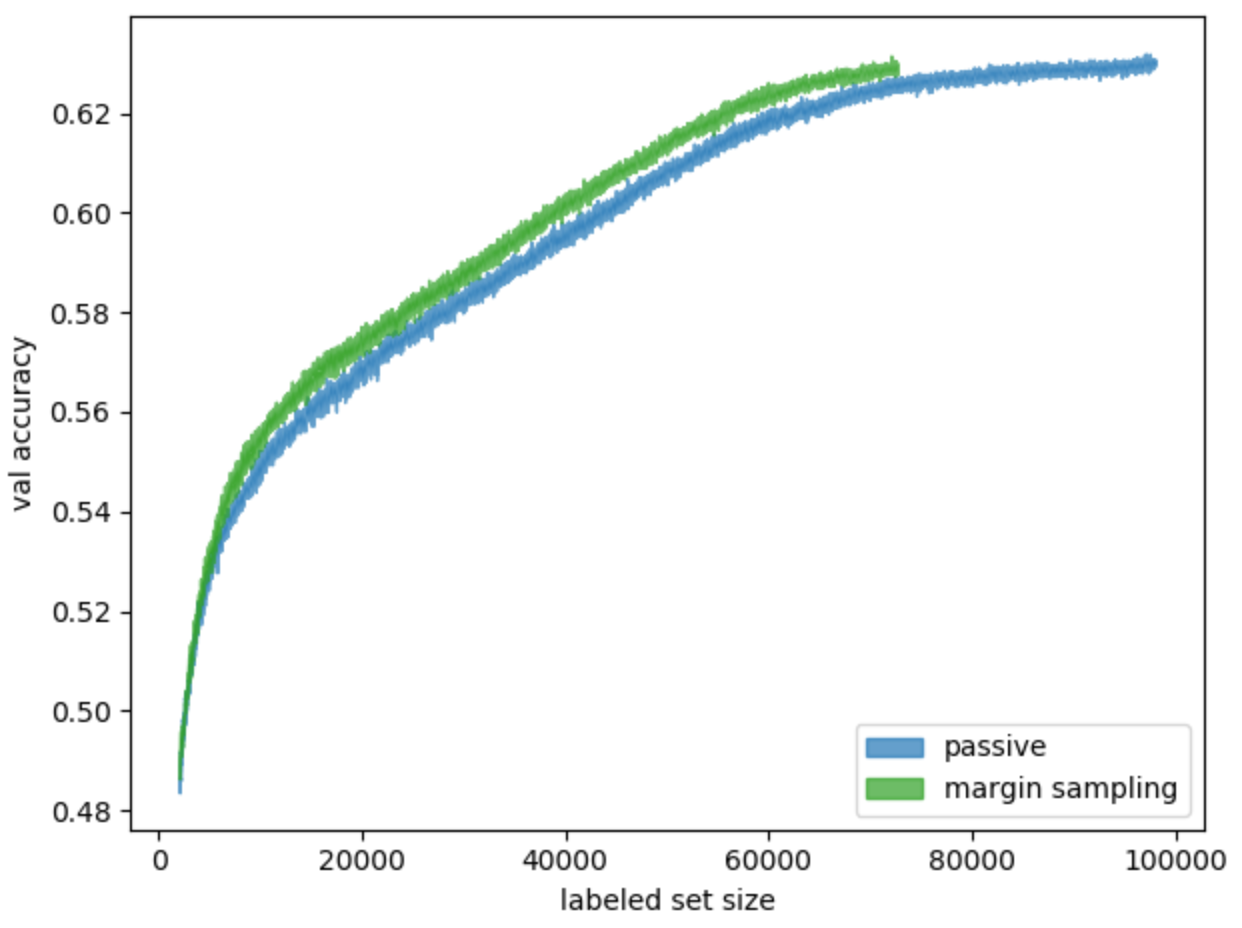
. 16. ( ) , margin sampling
: ( — margin sampling), — , , . ≈25 . . 25% — .
, . , , .
, , . , :
- batch size;
- , , — , batch normalization.