这样,他们忘记了模式只是可能的解决方案。像任何原理一样,模式也有适用范围,因此了解它们很重要。通往地狱的道路铺就了盲目和宗教信仰,甚至连权威性词语也铺平了道路。
框架中必要模式的存在并不能保证其正确而有意识的应用。

活动记录的闪光与贫穷
让我们看一下Active Record模式作为一种反模式,某些编程语言和框架试图以各种可能的方式避免这种模式。
Active Record的本质很简单:我们将业务逻辑与实体存储逻辑一起存储。换句话说,简单地说,数据库中的每个表都对应一个实体类以及一个行为。
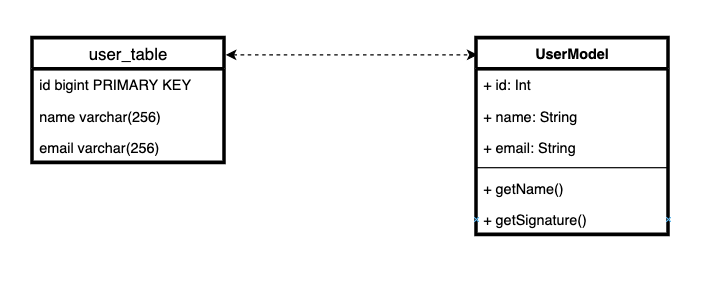
有相当强烈的意见认为,在一类中将业务逻辑与存储逻辑相结合是一种非常糟糕且无法使用的模式。它违反了唯一责任原则。因此,Django ORM在设计上很糟糕。
确实,在同一类中组合存储逻辑和域逻辑可能不是很好。
让我们以用户和个人资料模型为例。这是一个相当普遍的模式。有一个主板,还有一个附加板,它不总是必须存储的,但有时存储必要的数据。

事实证明,“用户”域的实体现在存储在两个表中,并且在代码中有两个类。每次我们直接对中进行一些更正时
user.profile,我们都需要记住这是一个单独的模型,并且我们对其进行了更改。并分别保存。
def create(self, validated_data):
# create user
user = User.objects.create(
url = validated_data['url'],
email = validated_data['email'],
# etc ...
)
profile_data = validated_data.pop('profile')
# create profile
profile = Profile.objects.create(
user = user
first_name = profile_data['first_name'],
last_name = profile_data['last_name'],
# etc...
)
return user
要获取用户列表,必须考虑是否要从这些用户那里获取属性
profile,以便立即选择两个带有连接的符号而不是使其SELECT N+1循环。
user = User.objects.get(email='example@examplemail.com')
user.userprofile.company_name
user.userprofile.country
如果在微服务体系结构中,部分用户数据存储在另一个服务中,例如LDAP中的角色和权限,情况将变得更糟。
当然,与此同时,我真的不希望API的外部用户以某种方式关心它。有一个REST资源
/users/{user_id},我想使用它而不考虑数据存储的内部方式。如果它们存储在不同的源中,那么更改用户或获取数据列表将更加困难。
一般来说,ORM!=域模型!

现实世界与“数据库中的一个表-域的一个实体”的假设相差越多,Active Record模式的问题就越多。
事实证明,每次编写业务逻辑时,都必须记住域的本质是如何存储的。
ORM方法是最低的抽象级别。他们不支持主题领域的任何限制,这意味着他们提供了犯错的机会。它们还向用户隐藏了实际上在数据库中进行了哪些查询,这导致效率低下且查询时间长。当循环而不是联接或过滤器进行查询时,经典的方法。
除了查询构建(构建查询的能力)之外,ORM还给我们带来了什么?没关系。是否可以迁移到新数据库?谁在他们的正确思想和坚定的记忆力下转移到了新数据库中,ORM对此做了帮助?如果您不是将它看作是将域模型(!)映射到数据库中的尝试,而是将其看作是一个简单的库,该库使您可以方便地对数据库进行查询,那么一切都准备就绪。
即使在类
Model的名称和文件的名称中使用了它models,它们也不会成为模型。不要开玩笑 这只是标签的描述。他们不会帮助封装任何东西。
但是,如果一切都那么糟糕,那该怎么办?来自分层体系结构的模式可以解决。
分层架构反击!
分层体系结构背后的想法很简单:我们将业务逻辑,存储逻辑和使用逻辑分开。
将存储与状态更改分开似乎完全合乎逻辑。那些。制作一个单独的层,可以接收和保存“抽象”存储中的数据。
例如,我们将所有存储逻辑保留在storage类中
Repository。控制器(或服务层)仅使用它来获取和保存实体。然后,我们可以根据需要更改存储和接收的逻辑,这将是一个地方!而且,当我们编写客户端代码时,我们可以确保我们没有忘记一个保存或从中删除的地方,并且我们不会重复相同的代码很多次。
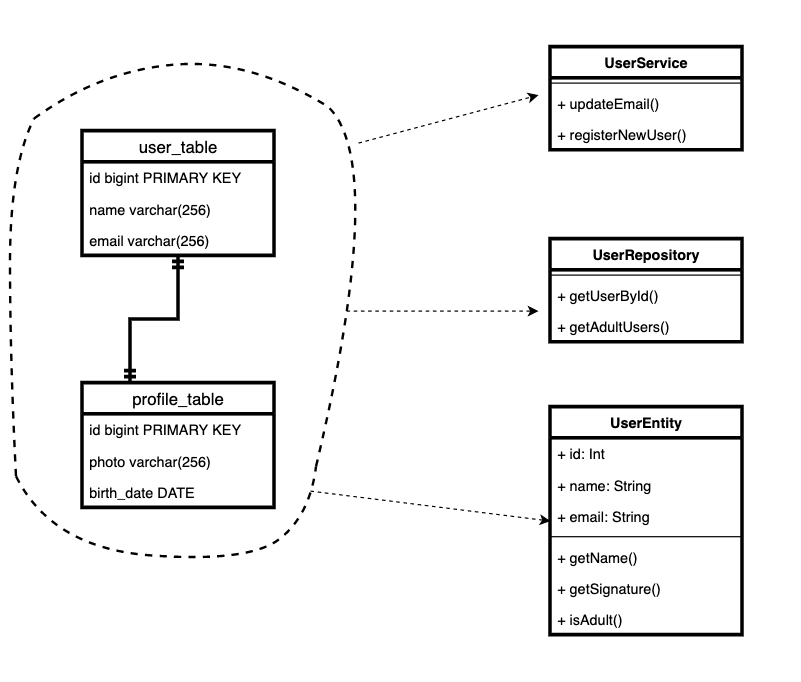
对我们来说,实体是否由不同表或微服务中的记录组成都无关紧要。或者是否将根据类型具有不同行为的实体存储在一张表中。
但是这种责任分工不是免费的。应当理解,为了防止“不良”代码更改,还创建了其他抽象层。显然,它
Repository掩盖了对象存储在SQL数据库中的事实,因此我们必须尽量不要让SQLism越界Repository。并且所有请求,即使是最简单和最明显的请求,都必须拖到存储层中。
例如,如果有必要通过名称和部门来设立办公室,则必须这样写:
#
interface OfficeRepository: CrudRepository<OfficeEntity, Long> {
@Query("select o from OfficeEntity o " +
"where o.number = :office and o.branch.number = :branch")
fun getOffice(@Param("branch") branch: String,
@Param("office") office: String): OfficeEntity?
...
对于Active Record,一切都变得更加简单:
Office.objects.get(name=’Name’, branch=’Branch’)
即使业务实体实际上是以非平凡的方式存储(在多个表中,在不同的服务中等等),也并非如此简单。为了很好地(正确地)实现此模式(为此创建了该模式),大多数情况下,您必须使用诸如汇总,工作单元和数据映射器之类的模式。
正确选择一个聚合,正确遵守对其施加的所有限制以及正确进行数据映射是困难的。而且只有非常优秀的开发人员才能完成此任务。对于Active Record,可以做到“正确”的一切。
普通开发人员会怎样?那些了解所有模式并坚决相信,如果他们使用分层体系结构,那么他们的代码将自动变得可维护且良好,与Active Record不同。他们为每个表创建CRUD存储库。他们的工作原理是
一盘式-一个仓库-一个实体。
否:
一个存储库-一个域对象。

他们还盲目地认为,如果在类中使用单词Entity,则表示域模型。就像ModelActive Record中的单词一样。
结果是形成了一个更复杂,灵活性更低的存储层,它具有Active Record和Repository / Data映射器的所有负面特性。
但是分层架构并不止于此。通常也区分服务层。
这种服务层的正确实现也是一项艰巨的任务。并且,例如,经验不足的开发人员会创建一个服务层,这是一个服务-存储库或ORM(DAO)的代理。那些。编写服务是为了使它们实际上不封装业务逻辑:
#
@Service
class AccountServiceImpl(val accountDaoService: AccountDaoService) : AccountService {
override fun saveAccount(account: Account) =
accountDaoService.saveAccount(convertClass(account, AccountEntity::class.java))
override fun deleteAccount(id: Long) =
accountDaoService.deleteAccount(id)
而且,Active Record和Service层都有很多缺点。
结果,在年轻的和缺乏经验的模式爱好者编写的分层Java框架和代码中,每单位业务逻辑的抽象数量开始超过所有合理的限制。
虽然有层,但它们都是琐碎的,只是用于调用下一层的层。
框架中OOP模式的存在并不能保证其正确和适当的应用。
没有银弹
很显然,没有银弹。复杂的解决方案用于复杂的问题,简单的解决方案用于简单的问题。
而且没有好的和坏的模式。在一种情况下,Active Record是好的,在其他情况下,它是分层的体系结构。是的,对于绝大多数的中小规模的应用程序,活动记录工作相当好。对于绝大多数中小型应用程序,分层架构(la Spring)的性能更差。而对于逻辑丰富的复杂应用程序和Web服务则恰恰相反。
应用程序或服务越简单,所需的抽象层就越少。
在业务逻辑不多的微服务中,使用分层体系结构通常毫无意义。普通的事务脚本(控制器中的脚本)可能完全适合手头的任务。
实际上,优秀的开发人员与劣质的开发人员的不同之处在于,他不仅了解模式,而且还了解何时应用这些模式。