int main()
{
int n = 500000000;
int *a = new int[n + 1];
for (int i = 0; i <= n; i++)
a[i] = i;
for (int i = 2; i * i <= n; i++)
{
if (a[i]) {
for (int j = i*i; j <= n; j += i) {
a[j] = 0;
}
}
}
delete[] a;
return 0;
}这是一个专门用于实验的简单应用程序,它使用Eratosthenes筛子搜索素数。让我们运行解决方案20次,并计算每次执行的用户时间。
测试台说明
i7-8750H @ 2,20
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
32 RAM
O:
Ubuntu 18.04.4
5.3.0-53-generic
优化之前的执行时间分散:
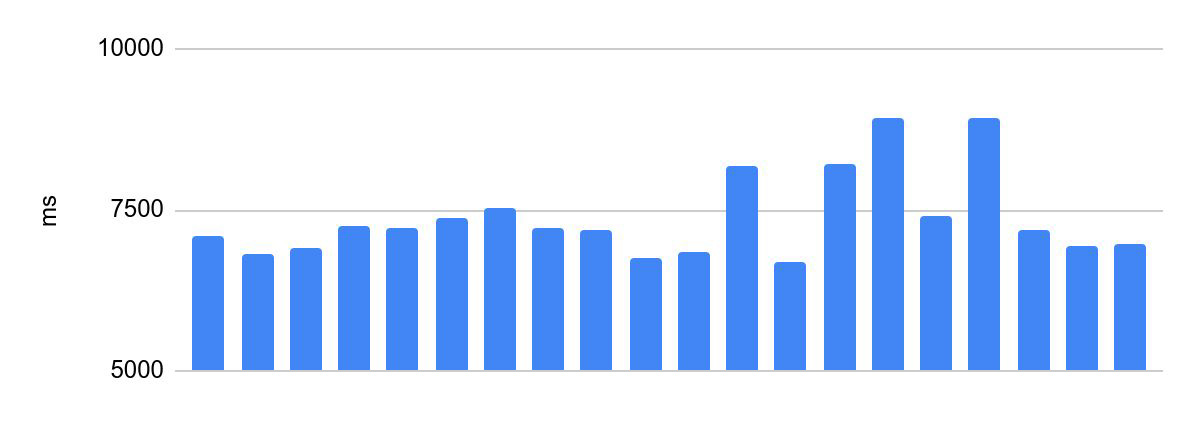
最快和最慢的执行时间之差为2230 ms。
这对于奥运会编程是不可接受的。参与者代码的执行时间是其解决方案成功的标准之一,也是比赛的条件之一,奖品的分配取决于此。因此,对这样的系统有一个重要的要求-相同代码的相同验证时间。在下文中,我们将其称为代码执行的一致性。
让我们尝试调整执行时间。
芯线绝缘
让我们从显而易见的地方开始。流程争夺核心,您需要以某种方式隔离核心以执行解决方案。此外,启用超线程后,操作系统将一个物理处理器核心定义为两个单独的逻辑核心。为了诚实地隔离内核,我们需要禁用超线程。这可以在BIOS设置中完成。
现成的Linux内核支持启动标志来隔离内核isolcpus。在grub设置中将此标志添加到GRUB_CMDLINE_LINUX_DEFAULT:/ etc / default / grub。例如:
GRUB_CMDLINE_LINUX_DEFAULT="... isolcpus=0,1"
运行update-grub并重新启动系统。
一切都按预期进行-系统未使用前两个内核:

让我们从孤立的内核开始。CPU Affinity配置允许您将进程绑定到特定的内核。有几种方法可以做到这一点。例如,让我们在porto容器中运行解决方案(使用cpu_set参数选择内核):
portoctl exec test command='sudo stress.sh' cpu_set=0Offtop:我们使用QEMU-KVM在生产中运行解决方案。在本文中使用了porto容器,以使其更易于显示。
使用专用于该解决方案的内核启动,而无需加载相邻内核:

相差375 ms。情况有所好转,但仍然太多了。
Tyunim表演
让我们尝试压力测试。哪一个?我们的任务是使用多个线程加载所有内核。这可以通过几种方式完成:
- 编写一个简单的应用程序,它将创建许多线程并开始在每个线程中计数。
- :
cat /dev/zero | pbzip2 -c > /dev/null. pbzip2 — bzip2. - stress
stress --cpu 12.
使用专用于解决方案的核心启动,相邻核心上有负载:

差异为1354毫秒:比无负载多一秒钟。显然,尽管我们在隔离的内核上运行,但负载仍影响了执行时间。可以看出,在某一时刻执行时间减少了。乍一看,这是违反直觉的:随着负载的增加,性能也会提高。
在生产中,这种行为(当执行时间开始在负载下浮动时)可能会非常痛苦。在这种情况下负载是多少?来自参与者的决策流,通常是在大型比赛和奥林匹克竞赛中。
原因是Intel Turbo Boost在负载下被激活-一种提高频率的技术。禁用它。对于我的立场,我也关闭了SpeedStep... 对于AMD处理器,必须关闭Turbo Core Cool'n'Quiet。以上所有操作都是在BIOS中完成的,其主要思想是禁用自动控制处理器频率的功能。
在禁用Turbo Boost的隔离内核上运行并在相邻内核上加载:

看起来不错,但两者之间的差异仍然为252ms。而且那仍然太多了。
Offtop:注意平均执行时间如何减少约25%。在日常生活中,残疾人技术是好的。
我们摆脱了对内核的竞争,稳定了内核频率-现在没有任何影响它们。那么区别从何而来呢?
NUMA
非统一内存访问或非统一内存体系结构,“具有不均匀内存的体系结构”。在NUMA系统中(即,通常在任何现代多处理器计算机上),每个处理器都有本地内存,该内存被视为总内存的一部分。每个处理器都可以访问其本地内存和其他处理器的本地内存(远程内存)。不平衡之处在于访问本地内存的速度明显更快。
正是由于这种不均匀性,演出时间才开始“走动”。让我们通过将执行绑定到特定的numa节点来修复它。为此,将numa节点添加到波尔图容器配置中:
portoctl exec test command='stress.sh' cpu_set="node 0" cpu_set=0在禁用Turbo Boost的隔离内核上运行,NUMA配置和相邻内核上的负载:
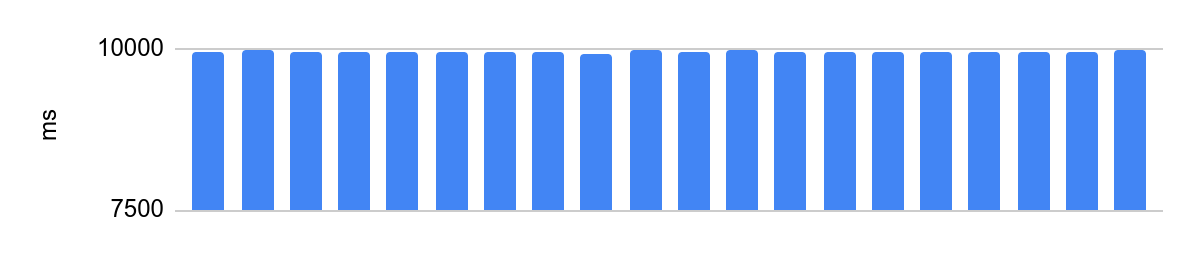
差异为48毫秒,并且在禁用处理器优化后的平均执行时间为10秒。在10秒时48ms相当于0.5%的误差,非常好。
重要的扰流板
有关isolcpus的更多信息
isolcpus标志有一个问题:某些系统线程仍可以调度到隔离的内核。
因此,在生产中,我们使用具有此标志扩展功能的修补内核。因此,在进行线程调度时,考虑到该标志,我们选择内核。
, 3.18. kthread_run, . CPU, isolcpus.
— slave_cpus , .
— slave_cpus , .
对未来的计划
池
如果一台决定性的机器比另一台决定性的机器功能更强大,那么对内核隔离的调整就无济于事-结果,我们在执行时间上仍将有很大的不同。因此,您需要考虑异构环境。到目前为止,我们只是不支持异构性-整个决策机器都配备了相同的硬件。但是在不久的将来,我们将开始将不同的硬件划分为同类的池,并且每个竞赛都将在具有相同硬件的相同池中举行。
迁移到云
该系统面临的新挑战是需要在Yandex.Cloud中启动。按照当今的标准,铁服务器是不可靠的,需要采取行动,但保持包裹执行的一致性很重要。在这里,仍在研究技术可能性。有一种想法认为,在极端情况下,云计算机可以运行不需要严格执行时间的解决方案。因此,我们将减少铁机上的负荷,它们只会处理仅需要一致性的解决方案。还有另一种选择:首先检查云中的包裹,如果不符合时间限制,请在真实硬件上重新检查。
收集统计数据
即使进行了所有调整,处理器也不可避免地会受到限制。为了减少负面影响,我们将并行执行解决方案,比较结果,如果结果不同,则重新检查。另外,如果其中一台决定性的机器在不断退化,这是使它停止运行并处理原因的借口。
结论
竞赛具有特殊性-看来一切都归结为简单地运行代码并获得结果。在本文中,我仅揭示了此过程的一个小方面。服务的每一层都有这样的东西。