
. OTUS Machine Learning: . , -, : « ML» « ».在本教程的第一部分中,我们成功地将分类模型保存到本地目录,并完成了与Jupyter Notebook相关的所有模型开发工作。从现在开始,重点将放在部署我们的模型上。要重用模型进行预测,您可以
predict()像在Jupyter Notebook中通常那样简单地加载它并调用该方法。
为了测试模型,在与file相同的文件夹中
model.pkl,main.py使用以下代码创建一个文件:
import pickle
# ,
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
#
with open('./model.pkl', 'rb') as model_pkl:
knn = pickle.load(model_pkl)
# ( )
unseen = np.array([[3.2, 1.1, 1.5, 2.1]])
result = knn.predict(unseen)
#
print('Predicted result for observation ' + str(unseen) + ' is: ' + str(result))重用模型进行预测。
您可以在未知观测值上多次调用预报器方法,而无需重新启动训练过程。但是,当您在终端中运行此py文件时,可能会遇到如下错误:
Traceback (most recent call last):
File "main.py", line 4, in <module>
from sklearn.neighbors import KNeighborsClassifier
ImportError: No module named sklearn.neighbors这是因为我们正在使用的软件包在运行文件的环境中不可用。这意味着用于开发模型(conda)的环境与运行时(conda外部的python环境)并不相同,并且在其他环境中运行代码时,这可能被视为潜在问题。我特别希望您看到此错误,以帮助您理解问题,并再次强调使用容器部署我们的代码以避免此类问题的重要性。现在,您可以使用“ pip install”命令简单地手动安装所有必需的软件包。我们稍后会回到这里自动执行此操作。
在安装所有软件包并成功运行文件之后,模型应快速返回以下消息:
Predicted result for observation [[3.2 1.1 1.5 2.1]] is: [1]如您在此处看到的,我们使用硬编码的未知数据来测试模型。这些数字分别代表萼片的长度,宽度,花瓣的长度和宽度。但是,由于我们要将模型公开为服务,因此必须将其公开为接受包含这四个参数的请求并返回预测结果的函数。然后,该函数可用于API服务器(后端)或部署在无服务器运行时中,例如Google Cloud Functions。在本教程中,我们将尝试共同构建一个API服务器并将其放入Docker容器中。
API如何工作?
让我们谈谈当今的Web应用程序如何工作。大多数Web应用程序都有两个主要组件,它们涵盖了应用程序所需的几乎所有功能:前端和后端。前端专注于为用户提供界面(网页),而前端服务器通常存储HTML,CSS,JS和其他静态文件,例如图像和声音。另一方面,后端服务器将处理所有响应从前端发送的请求的业务逻辑。

Web应用程序结构的说明。
这是在浏览器中打开“中”时发生的情况。
- HTTP-
medium.com. DNS-, , . ., . -
* .html,* .css,* .js, - . - Medium . , «clap» () .
- (javascript) HTTP- id . URL- , . id XXXXXXX.
- (, ) .
- .
- , .
当然,这可能与使用中型Web应用程序时发生的过程不完全相同,并且实际上比这复杂得多,但是这种简化的过程可以帮助您了解Web应用程序的工作方式。
现在,我要让您关注上图中的蓝色箭头。这些是HTTP请求(从浏览器发送)和HTTP响应(由浏览器接收或发送到浏览器)。处理来自浏览器的请求并将响应返回到后端服务器的组件称为“ API”。
以下是API定义:
(API — application program interface) — , . , API , .
API!
有许多框架可以帮助我们使用Python构建API,包括Flask,Django,Pyramid,Falcon和Tornado。此处列出了这些结构的优缺点以及比较。我将在本教程中使用Flask,但是技术和工作流程与其他方法相同,或者,此时您可以使用自己喜欢的框架。
可以使用以下命令通过pip安装最新版本的Flask:
pip install Flask现在您需要做的就是在初始化Flask应用程序之后将上一步中的代码转换为一个函数,并为其注册一个API端点。默认情况下,Flask应用程序在本地主机(127.0.0.1)上运行,并将在端口5000上侦听请求。
import pickle
# ,
import numpy as np
import sys
from sklearn.neighbors import KNeighborsClassifier
# Flask API
from flask import Flask, request
#
with open('./model.pkl', 'rb') as model_pkl:
knn = pickle.load(model_pkl)
# Flask
app = Flask(__name__)
# API
@app.route('/predict')
def predict_iris():
#
sl = request.args.get('sl')
sw = request.args.get('sw')
pl = request.args.get('pl')
pw = request.args.get('pw')
# predict
#
unseen = np.array([[sl, sw, pl, pw]])
result = knn.predict(unseen)
#
return 'Predicted result for observation ' + str(unseen) + ' is: ' + str(result)
if __name__ == '__main__':
app.run()将模型表示为API
在终端上,您应该看到以下内容:
* Serving Flask app "main" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)打开浏览器,然后在地址栏中输入以下查询:
http://localhost:5000/predict?sl=3.2&sw=1.1&pl=1.5&pw=2.1如果您的浏览器中出现类似的内容,那么恭喜!您现在将机器学习模型作为具有API端点的服务公开。
Predicted result for observation [['3.2' '1.1' '1.5' '2.1']] is: [1]使用Postman进行API测试
我们最近使用浏览器进行了快速的API测试,但这不是一种非常有效的方法。例如,我们不能使用GET方法,而是使用POST方法,并且在标头中带有身份验证令牌,并且让浏览器发送这样的请求并不容易。在软件开发中,Postman被广泛用于测试API,并且对于基本使用完全免费。
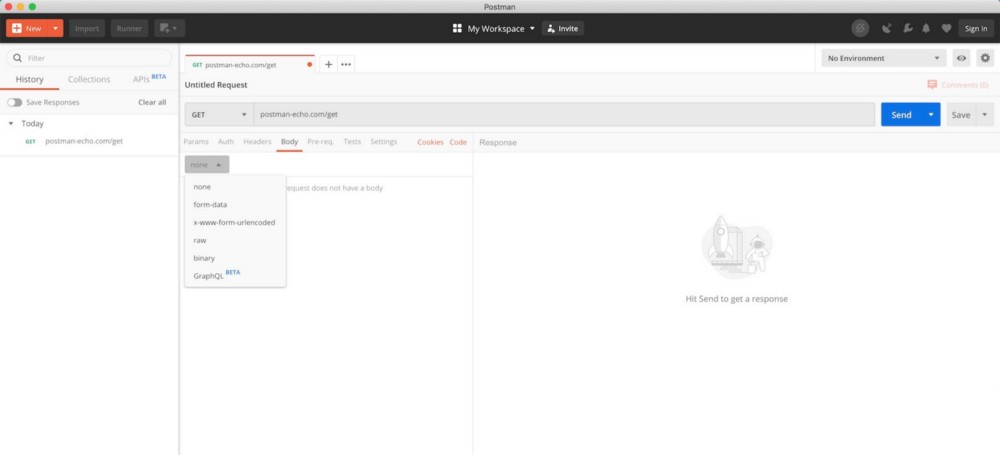
Postman UI(来自Postman下载页面)
下载并安装Postman之后,打开该工具,并按照以下说明提交请求。

通过邮递员发送GET请求
- , GET , API GET . , POST .
- URL .
- . , .
- «», API.
- .
- HTTP-. .
既然您知道如何通过API端点将机器学习模型作为服务公开并通过Postma测试该端点,那么下一步就是使用Docker容器化您的应用程序,在此我们将深入研究Docker的工作原理以及它如何为我们提供帮助。解决我们之前遇到的所有依赖问题。
阅读第一部分。