期待已久的有关使用pyOpenRPA管理第三方WEB应用程序的教程。在第二部分中,我们将分析机器人对HTML / JS的影响原理。我们还将用自己的双手制造一个小型但非常有示范性的机器人。
对于那些与房地产买卖相关的人,该机器人将非常有用。

对于那些第一次和我们在一起的人
pyOpenRPA是一个开源RPA平台,完全替代了顶级商业RPA平台。
您可以在此处详细了解其用途。
导航pyOpenRPA教程
本教程由一系列文章组成,重点介绍RPA所需的关键技术。
掌握了这些技术之后,您将有机会深入研究摆在您面前的任务的细节。
教程文章列表(已发布和已计划):
- 放弃付费的RPA平台并依靠OpenSource(pyOpenRPA)
- pyOpenRPA教程。管理窗口化GUI应用程序
- >> pyOpenRPA教程。WEB应用程序管理(我们在Chrome,Firefox,Opera中观看的内容)
- pyOpenRPA . &
- pyOpenRPA .
.
[ ]
- — - , - . - , , , , . , , - .
1990- — 2000- .
, #, ( , ). WEB " ?"/" ?". WEB
?
, / .
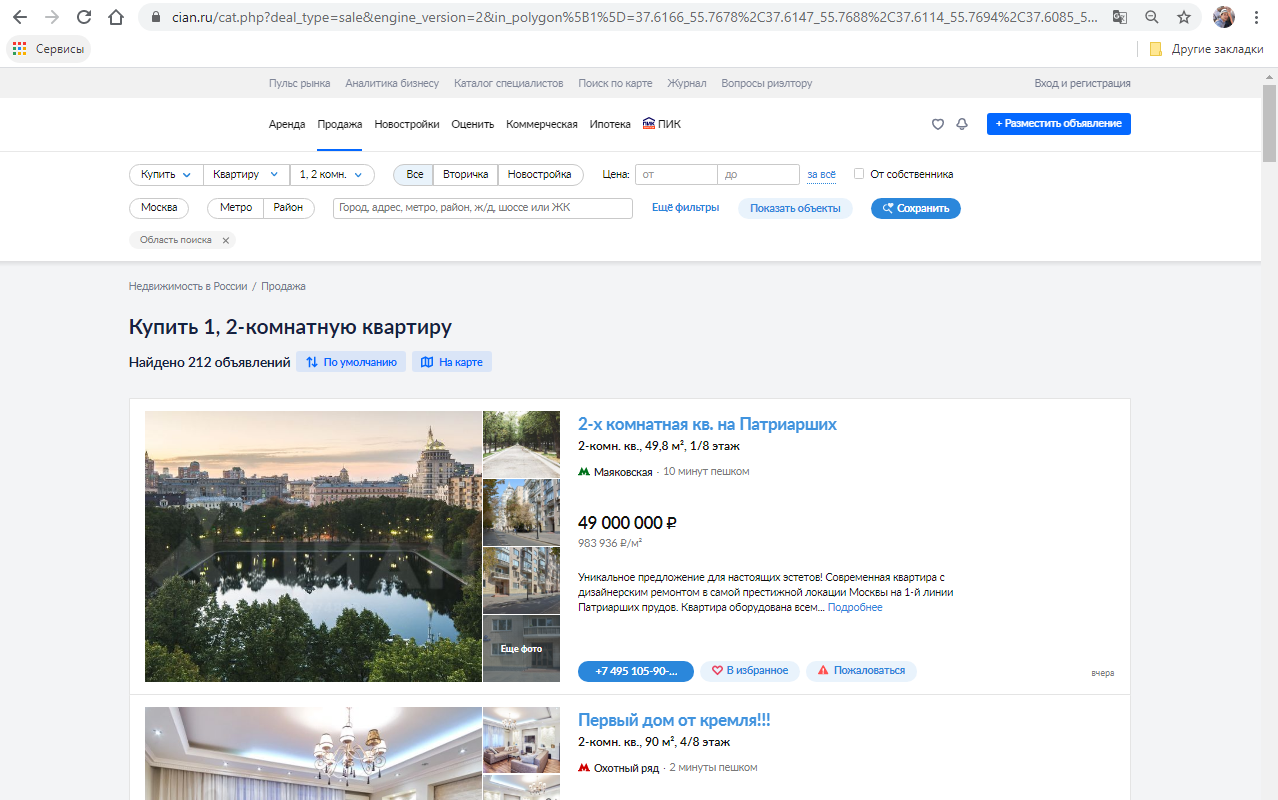
?
WEB — . + .
WEB : CSS, XPath, id, class, attribute. CSS .
( )
, ( ).
: , . .json :
{
"SearchKeyStr": "_", #
"SearchTitleStr": ", ", #
"SearchURLStr": "https://www.cian.ru/cat.php?deal_type=sale&engine_version=2&in_polygon%5B1%5D=37.6166_55.7678%2C37.6147_55.7688%2C37.6114_55.7694%2C37.6085_55.7698%2C37.6057_55.77%2C37.6018_55.77%2C37.5987_55.77%2C37.5961_55.7688%2C37.5942_55.7677%2C37.5928_55.7663%2C37.5915_55.7647%2C37.5908_55.7631%2C37.5907_55.7616%2C37.5909_55.7595%2C37.5922_55.7577%2C37.5944_55.7563%2C37.5968_55.7555%2C37.6003_55.7547%2C37.603_55.7543%2C37.6055_55.7542%2C37.6087_55.7541%2C37.6113_55.7548%2C37.6135_55.756%2C37.6151_55.7574%2C37.6163_55.7589%2C37.6179_55.7606%2C37.6187_55.7621%2C37.619_55.7637%2C37.6194_55.7651%2C37.6193_55.7667%2C37.6178_55.7679%2C37.6153_55.7683%2C37.6166_55.7678&offer_type=flat&polygon_name%5B1%5D=%D0%9E%D0%B1%D0%BB%D0%B0%D1%81%D1%82%D1%8C+%D0%BF%D0%BE%D0%B8%D1%81%D0%BA%D0%B0&room1=1&room2=1", # URL of the CIAN search [str]
"SearchDatetimeStr": "2020-08-01 09:33:00.838081", # ,
"SearchItems": { #
"https://www.cian.ru/sale/flat/219924574/:": { # URL
"TitleStr": "3-. ., 31,4 ², 5/8 ", #
"PriceFloat": 10000000.0, #
"PriceSqmFloat": 133333.0, # 1 . .
"SqMFloat": 31.4, # - . .
"FloorCurrentInt": 5, #
"FloorTotalInt": 8, #
"RoomCountInt": 3 # -
}
}
}0. ( pyOpenRPA)
RPA , pyOpenRPA , : RPA , pyOpenRPA . RPA ( pyOpenRPA Python).
- 1, . GitLab
- 2, . pyOpenRPA Python 3 (pip install pyOpenRPA)
( 1). - . pyOpenRPA , , — . #Enjoy :)
1.
, , . . , — WEB .
:
- Selenium WebDriver
- Google Chrome Mozilla Firefox Internet Explorer
- Python 3
1 (. 0), pyOpenRPA (#). pyOpenRPA portable (Google Chrome, Mozilla Firefox, Python3 32|64 ..).
, pyOpenRPA Selenium. WEB. pyOpenRPA.
:
- pyOpenRPA > Wiki > RUS_Tutorial > WebGUI_Habr:
- "3. MonitoringCIAN_Run_64.py" — , WEB
- "3. MonitoringCIAN_Run_64.cmd" — 1- .exe
"3. MonitoringCIAN_Run_64.cmd" :
cd %~dp0..\..\..\Sources
..\Resources\WPy64-3720\python-3.7.2.amd64\python.exe "..\Wiki\RUS_Tutorial\WebGUI_Habr\3. MonitoringCIAN_Run_64.py"
pause >nulSelenium WebDriver :
##########################
# Init the Chrome web driver
###########################
def WebDriverInit(inWebDriverFullPath, inChromeExeFullPath, inExtensionFullPathList):
# Set full path to exe of the chrome
lWebDriverChromeOptionsInstance = webdriver.ChromeOptions()
lWebDriverChromeOptionsInstance.binary_location = inChromeExeFullPath
# Add extensions
for lExtensionItemFullPath in inExtensionFullPathList:
lWebDriverChromeOptionsInstance.add_extension (lExtensionItemFullPath)
# Run chrome instance
lWebDriverInstance = None
if inWebDriverFullPath:
# Run with specified web driver path
lWebDriverInstance = webdriver.Chrome(executable_path = inWebDriverFullPath, options=lWebDriverChromeOptionsInstance)
else:
lWebDriverInstance = webdriver.Chrome(options = lWebDriverChromeOptionsInstance)
# Return the result
return lWebDriverInstance2. WEB CSS
WEB Google Chrome, pyOpenRPA ( 1 0).
Google Chrome (pyOpenRPA repo\Resources\GoogleChromePortable\App\Chrome-bin\chrome.exe, Ctrl + Shift + i)
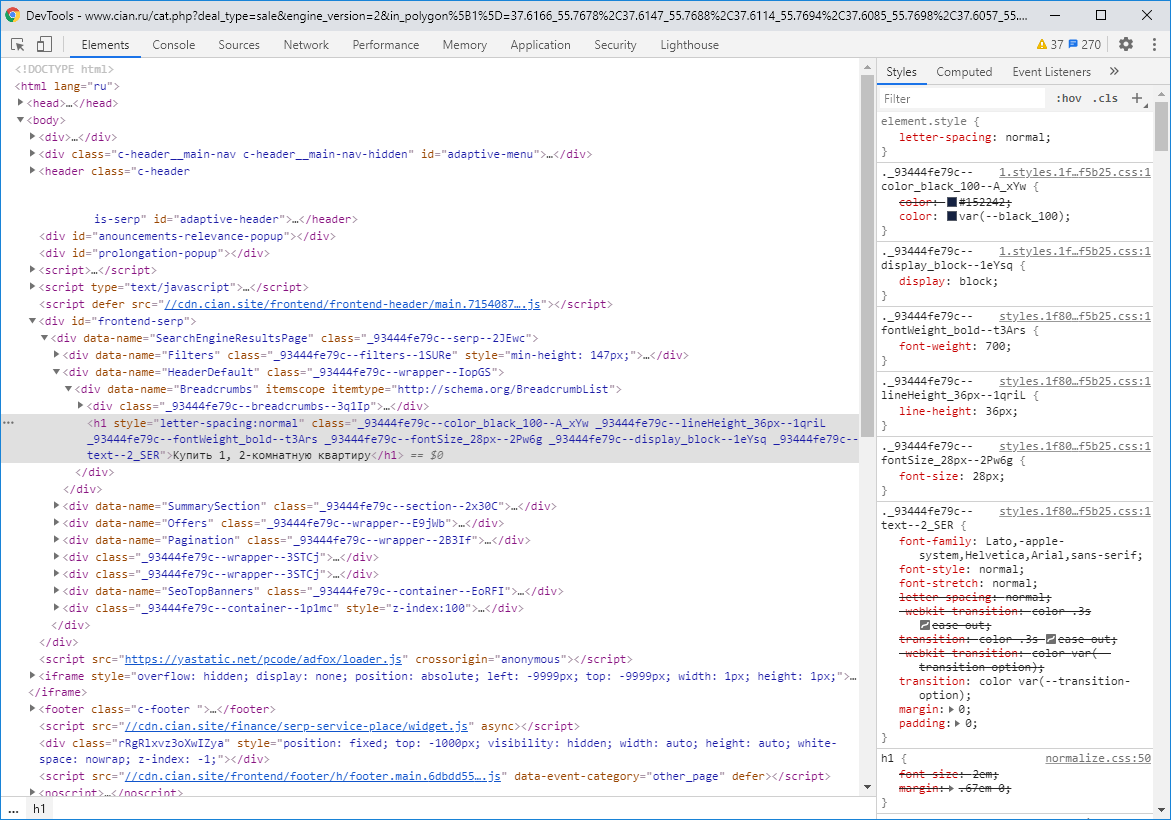
, . .

, CSS Google Chrome. CSS
CSS "Console". , CSS .
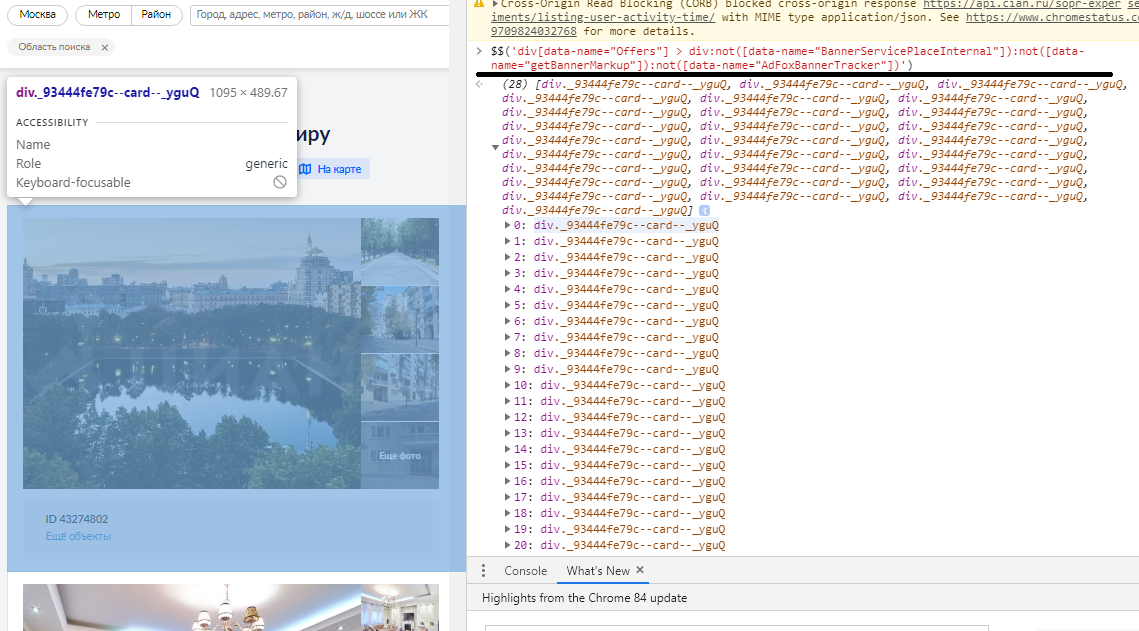
CSS .
, , .
:
- div[data-name="BannerServicePlaceInternal"]
- div[data-name="getBannerMarkup"]
- div[data-name="AdFoxBannerTracker"]
CSS , . CSS .
- CSS , : div[data-name="Offers"] > div:not([data-name="BannerServicePlaceInternal"]):not([data-name="getBannerMarkup"]):not([data-name="AdFoxBannerTracker"])
CSS : , , URL .
- CSS , : div[data-name="TopTitle"],div[data-name="Title"]
- CSS , : div[data-name="Price"] > div[class="header"],div[data-name="TopPrice"] > div[class="header"]
- CSS , URL : a[class*="--header--"]
CSS .
- CSS , : div[data-name="Pagination"] li[class*="active"] + li a
3. /
CSS . , .
:
lOfferItemInfo = { # Item URL with https
"TitleStr": "3-. ., 31,4 ², 5/8 ", # Offer title [str]
"PriceFloat": 10000000.0, # Price [float]
"PriceSqmFloat": 133333.0, # CALCULATED Price per square meters [float]
"SqMFloat": 31.4, # Square meters in flat [float]
"FloorCurrentInt": 5, # Current floor [int]
"FloorTotalInt": 8, # Current floor [int]
"RoomCountInt": 3 # Room couint [int]
}.
lOfferListCSSStr = 'div[data-name="Offers"] > div:not([data-name="BannerServicePlaceInternal"]):not([data-name="getBannerMarkup"]):not([data-name="AdFoxBannerTracker"])'
lOfferList = inWebDriver.find_elements_by_css_selector(css_selector=lOfferListCSSStr).
for lOfferItem in lOfferList:WEB : , , URL .
lTitleStr = lOfferItem.find_element_by_css_selector(css_selector='div[data-name="TopTitle"],div[data-name="Title"]').text # Extract title text
lPriceStr = lOfferItem.find_element_by_css_selector(css_selector='div[data-name="Price"] > div[class*="header"],div[data-name="TopPrice"] > div[class*="header"]').text # Extract total price
lURLStr = lOfferItem.find_element_by_css_selector(css_selector='a[class*="--header--"]').get_attribute("href") # Extract offer URL
lOfferItemInfo["TitleStr"] = lTitleStr # set the title
lPriceStr = lPriceStr.replace(" ","").replace("₽","") # Remove some extra symbols
lOfferItemInfo["PriceFloat"] = round(float(lPriceStr),2) # Convert price to the float type.
""
lREResult = re.search(r".*, (\d*,?\d*) ², (\d*)/(\d*) .", lTitleStr) # run the re lOfferItemInfo["RoomCountInt"] = 1 # Room count lSqmStr = lREResult.group(1) lSqmStr= lSqmStr.replace(",",".") lOfferItemInfo["SqMFloat"] = round(float(lSqmStr),2) # sqm count lOfferItemInfo["FloorCurrentInt"] = int(lREResult.group(2)) # Floor current lOfferItemInfo["FloorTotalInt"] = int(lREResult.group(3)) # Floor total lOfferItemInfo["PriceSqmFloat"] = round(lOfferItemInfo["PriceFloat"] / lOfferItemInfo["SqMFloat"],2) # Sqm per M
""
lREResult = re.search(r".*(\d)-. .*, (\d*,?\d*) ², (\d*)/(\d*) .", lTitleStr) # run the re lOfferItemInfo["RoomCountInt"] = int(lREResult.group(1)) # Room count lSqmStr = lREResult.group(2) lSqmStr= lSqmStr.replace(",",".") lOfferItemInfo["SqMFloat"] = round(float(lSqmStr),2) # sqm count lOfferItemInfo["FloorCurrentInt"] = int(lREResult.group(3)) # Floor current lOfferItemInfo["FloorTotalInt"] = int(lREResult.group(4)) # Floor total lOfferItemInfo["PriceSqmFloat"] = round(lOfferItemInfo["PriceFloat"] / lOfferItemInfo["SqMFloat"],2) # Sqm per M
, ( ) .
( 2) CSS . .click() .
, .click Selenium ( ). JavaScript Selenium. JavaScript , . :
inWebDriver.execute_script("""document.querySelector('div[data-name="Pagination"] li[class*="active"] + li a').click()"""), . .
# wait while preloader is active
lDoWaitBool = True
while lDoWaitBool:
lPreloaderCSS = inWebDriver.find_elements_by_css_selector(css_selector='div[class*="--preloadOverlay--"]') # So hard to catch the element :)
if len(lPreloaderCSS)>0: time.sleep(0.5) # preloader is here - wait
else: lDoWaitBool = False # Stop wait if preloader is dissappear.json .
# Check dir - create if not exists
if not os.path.exists(os.path.join('Datasets',lResult['SearchKeyStr'])):
os.makedirs(os.path.join('Datasets',lResult['SearchKeyStr']))
# Save result in file
lFile = open(f"{os.path.join('Datasets',lResult['SearchKeyStr'],lDatetimeNowStr.replace(' ','_').replace('-','_').replace(':','_').replace('.','_'))}.json","w",encoding="utf-8")
lFile.write(json.dumps(lResult))
lFile.close()4.
— , . WEB , . , :
- .
- (, :) )
( :) ).
, .
.
# wait while preloader is active. If timeout - retry all job lTimeFromFLoat = time.time() # get current time in float (seconds) lDoWaitBool = True while lDoWaitBool: lPreloaderCSS = inWebDriver.find_elements_by_css_selector(css_selector='div[class*="--preloadOverlay--"]') if len(lPreloaderCSS)>0: time.sleep(0.5) # preloader is here - wait else: lDoWaitBool = False # Stop wait if preloader is dissappear if (time.time() - lTimeFromFLoat) > 15: # check if timeout is more than 15 seconds lRetryJobBool = True # Loading error on page - do break, then retry the job if inLogger: inLogger.warning(f" {15} ., ") break # break the loop if lRetryJobBool == True: # break the loop if RetryJobBool is true break
(, :) )
lPageNumberInt = int(inWebDriver.find_element_by_css_selector(css_selector='li[class*="--active--"] span').text) # Get the current page int from web and check with iterator (if not equal - retry all job) if lPageNumberInt == lPageCounterInt: ... ... else: lRetryJobBool = True if inLogger: inLogger.warning( f" . : {lPageNumberInt}, : {lPageCounterInt}")
5.
.
( GitLab):
# Init Chrome web driver with extensions (if applicable)
# Import section
from selenium import webdriver
import time
import re # Regexp to extract info from string
import json
import datetime
import os
import re
import copy
import logging
# Store structure (.json)
"""
{
"SearchKeyStr": "_",
"SearchTitleStr": ", ", # Title of the search [str]
"SearchURLStr": "https://www.cian.ru/cat.php?deal_type=sale&engine_version=2&in_polygon%5B1%5D=37.6166_55.7678%2C37.6147_55.7688%2C37.6114_55.7694%2C37.6085_55.7698%2C37.6057_55.77%2C37.6018_55.77%2C37.5987_55.77%2C37.5961_55.7688%2C37.5942_55.7677%2C37.5928_55.7663%2C37.5915_55.7647%2C37.5908_55.7631%2C37.5907_55.7616%2C37.5909_55.7595%2C37.5922_55.7577%2C37.5944_55.7563%2C37.5968_55.7555%2C37.6003_55.7547%2C37.603_55.7543%2C37.6055_55.7542%2C37.6087_55.7541%2C37.6113_55.7548%2C37.6135_55.756%2C37.6151_55.7574%2C37.6163_55.7589%2C37.6179_55.7606%2C37.6187_55.7621%2C37.619_55.7637%2C37.6194_55.7651%2C37.6193_55.7667%2C37.6178_55.7679%2C37.6153_55.7683%2C37.6166_55.7678&offer_type=flat&polygon_name%5B1%5D=%D0%9E%D0%B1%D0%BB%D0%B0%D1%81%D1%82%D1%8C+%D0%BF%D0%BE%D0%B8%D1%81%D0%BA%D0%B0&room1=1&room2=1", # URL of the CIAN search [str]
"SearchDatetimeStr": "2020-08-01 09:33:00.838081", # Date of data extraction, [str]
"SearchItems": {
"https://www.cian.ru/sale/flat/219924574/:": { # Item URL with https
"TitleStr": "3-. ., 31,4 ², 5/8 ", # Offer title [str]
"PriceFloat": 10000000.0, # Price [float]
"PriceSqmFloat": 133333.0, # CALCULATED Price per square meters [float]
"SqMFloat": 31.4, # Square meters in flat [float]
"FloorCurrentInt": 5, # Current floor [int]
"FloorTotalInt": 8, # Current floor [int]
"RoomCountInt": 3 # Room couint [int]
}
}
}
"""
##########################
# Init the Chrome web driver
###########################
gChromeExeFullPath = r'..\Resources\GoogleChromePortable\App\Chrome-bin\chrome.exe'
gExtensionFullPathList = []
gWebDriverFullPath = r'..\Resources\SeleniumWebDrivers\Chrome\chromedriver_win32 v84.0.4147.30\chromedriver.exe'
def WebDriverInit(inWebDriverFullPath, inChromeExeFullPath, inExtensionFullPathList):
# Set full path to exe of the chrome
lWebDriverChromeOptionsInstance = webdriver.ChromeOptions()
lWebDriverChromeOptionsInstance.binary_location = inChromeExeFullPath
# Add extensions
for lExtensionItemFullPath in inExtensionFullPathList:
lWebDriverChromeOptionsInstance.add_extension (lExtensionItemFullPath)
# Run chrome instance
lWebDriverInstance = None
if inWebDriverFullPath:
# Run with specified web driver path
lWebDriverInstance = webdriver.Chrome(executable_path = inWebDriverFullPath, options=lWebDriverChromeOptionsInstance)
else:
lWebDriverInstance = webdriver.Chrome(options = lWebDriverChromeOptionsInstance)
# Return the result
return lWebDriverInstance
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# def to extract list of offers from one job
def OffersByJobExtractDict(inLogger, inWebDriver, inJob):
# BUG 0 - if timeout - retry the job +
# BUG 1 - do mouse scroll to to emulate user activity - cian can hold the robot
# BUG 2 - check the page to retry job offer if page is not next +
# BUG 3 - RE fall on -, 85,6 ², 4/8 +
lRetryJobBool = True # Init flag if some error is raised - retry
while lRetryJobBool:
lRetryJobBool = False # Set false until some another action will appear
lResult = copy.deepcopy(inJob) # do copy the structure
lFilterURLStr = lResult["SearchURLStr"]
inWebDriver.get(lFilterURLStr) # Open the URL
lDatetimeNowStr = str(datetime.datetime.now())
lResult.update({
"SearchDatetimeStr": lDatetimeNowStr, # Date of data extraction, [str]
"SearchItems": {} # prepare the result
})
# Get List of the page
lNextPageItemCSS = 'div[data-name="Pagination"] li[class*="active"] + li a'
lNextPageItem = inWebDriver.find_element_by_css_selector(lNextPageItemCSS)
lPageCounterInt = 1 # Init the page counter
while lNextPageItem:
lPageNumberInt = int(inWebDriver.find_element_by_css_selector(css_selector='li[class*="--active--"] span').text) # Get the current page int from web and check with iterator (if not equal - retry all job)
if lPageNumberInt == lPageCounterInt:
lOfferListCSSStr = 'div[data-name="Offers"] > div:not([data-name="BannerServicePlaceInternal"]):not([data-name="getBannerMarkup"]):not([data-name="AdFoxBannerTracker"])'
lOfferList = inWebDriver.find_elements_by_css_selector(css_selector=lOfferListCSSStr)
for lOfferItem in lOfferList: # Processing the item, extract info
lOfferItemInfo = { # Item URL with https
"TitleStr": "3-. ., 31,4 ², 5/8 ", # Offer title [str]
"PriceFloat": 10000000.0, # Price [float]
"PriceSqmFloat": 133333.0, # CALCULATED Price per square meters [float]
"SqMFloat": 31.4, # Square meters in flat [float]
"FloorCurrentInt": 5, # Current floor [int]
"FloorTotalInt": 8, # Current floor [int]
"RoomCountInt": 3 # Room couint [int]
}
lTitleStr = lOfferItem.find_element_by_css_selector(css_selector='div[data-name="TopTitle"],div[data-name="Title"]').text # Extract title text
if inLogger: inLogger.info(f" : {lTitleStr}")
lPriceStr = lOfferItem.find_element_by_css_selector(css_selector='div[data-name="Price"] > div[class*="header"],div[data-name="TopPrice"] > div[class*="header"]').text # Extract total price
lURLStr = lOfferItem.find_element_by_css_selector(css_selector='a[class*="--header--"]').get_attribute("href") # Extract offer URL
lOfferItemInfo["TitleStr"] = lTitleStr # set the title
lPriceStr = lPriceStr.replace(" ","").replace("₽","") # Remove some extra symbols
lOfferItemInfo["PriceFloat"] = round(float(lPriceStr),2) # Convert price to the float type
#Check if
if "" in lTitleStr.upper():
lREResult = re.search(r".*, (\d*,?\d*) ², (\d*)/(\d*) .", lTitleStr) # run the re
lOfferItemInfo["RoomCountInt"] = 1 # Room count
lSqmStr = lREResult.group(1)
lSqmStr= lSqmStr.replace(",",".")
lOfferItemInfo["SqMFloat"] = round(float(lSqmStr),2) # sqm count
lOfferItemInfo["FloorCurrentInt"] = int(lREResult.group(2)) # Floor current
lOfferItemInfo["FloorTotalInt"] = int(lREResult.group(3)) # Floor total
lOfferItemInfo["PriceSqmFloat"] = round(lOfferItemInfo["PriceFloat"] / lOfferItemInfo["SqMFloat"],2) # Sqm per M
else:
lREResult = re.search(r".*(\d)-. .*, (\d*,?\d*) ², (\d*)/(\d*) .", lTitleStr) # run the re
lOfferItemInfo["RoomCountInt"] = int(lREResult.group(1)) # Room count
lSqmStr = lREResult.group(2)
lSqmStr= lSqmStr.replace(",",".")
lOfferItemInfo["SqMFloat"] = round(float(lSqmStr),2) # sqm count
lOfferItemInfo["FloorCurrentInt"] = int(lREResult.group(3)) # Floor current
lOfferItemInfo["FloorTotalInt"] = int(lREResult.group(4)) # Floor total
lOfferItemInfo["PriceSqmFloat"] = round(lOfferItemInfo["PriceFloat"] / lOfferItemInfo["SqMFloat"],2) # Sqm per M
lResult['SearchItems'][lURLStr] = lOfferItemInfo # Set item in result dict
# Click next page item
lNextPageItem = None
lNextPageList = inWebDriver.find_elements_by_css_selector(lNextPageItemCSS)
if len(lNextPageList)>0:
lNextPageItem = lNextPageList[0]
try:
#lNextPageItem = WebDriverWait(lWebDriver, 10).until(EC.visibility_of_element_located((By.CSS_SELECTOR, 'div[data-name="Pagination"]')))
#lNextPageItem.click()
inWebDriver.execute_script("""document.querySelector('div[data-name="Pagination"] li[class*="active"] + li a').click()""")
except Exception as e:
print(e)
time.sleep(0.5) # some init operations
# wait while preloader is active. If timeout - retry all job
lTimeFromFLoat = time.time() # get current time in float (seconds)
lDoWaitBool = True
while lDoWaitBool:
lPreloaderCSS = inWebDriver.find_elements_by_css_selector(css_selector='div[class*="--preloadOverlay--"]')
if len(lPreloaderCSS)>0: time.sleep(0.5) # preloader is here - wait
else: lDoWaitBool = False # Stop wait if preloader is dissappear
if (time.time() - lTimeFromFLoat) > 15: # check if timeout is more than 15 seconds
lRetryJobBool = True # Loading error on page - do break, then retry the job
if inLogger: inLogger.warning(f" {15} ., ")
break # break the loop
if lRetryJobBool == True: # break the loop if RetryJobBool is true
break
lPageCounterInt = lPageCounterInt + 1 # Increment the page counter
else:
lRetryJobBool = True
if inLogger: inLogger.warning(
f" . : {lPageNumberInt}, : {lPageCounterInt}")
if lRetryJobBool == False: # break the loop if RetryJobBool is true
# Check dir - create if not exists
if not os.path.exists(os.path.join('Datasets',lResult['SearchKeyStr'])):
os.makedirs(os.path.join('Datasets',lResult['SearchKeyStr']))
# Save result in file
lFile = open(f"{os.path.join('Datasets',lResult['SearchKeyStr'],lDatetimeNowStr.replace(' ','_').replace('-','_').replace(':','_').replace('.','_'))}.json","w",encoding="utf-8")
lFile.write(json.dumps(lResult))
lFile.close()
# Google Chrome with selenium web driver
lWebDriver = WebDriverInit(inWebDriverFullPath = gWebDriverFullPath, inChromeExeFullPath = gChromeExeFullPath, inExtensionFullPathList = gExtensionFullPathList)
lFilterURLStr = "https://www.cian.ru/cat.php?deal_type=sale&engine_version=2&in_polygon%5B1%5D=37.6166_55.7678%2C37.6147_55.7688%2C37.6114_55.7694%2C37.6085_55.7698%2C37.6057_55.77%2C37.6018_55.77%2C37.5987_55.77%2C37.5961_55.7688%2C37.5942_55.7677%2C37.5928_55.7663%2C37.5915_55.7647%2C37.5908_55.7631%2C37.5907_55.7616%2C37.5909_55.7595%2C37.5922_55.7577%2C37.5944_55.7563%2C37.5968_55.7555%2C37.6003_55.7547%2C37.603_55.7543%2C37.6055_55.7542%2C37.6087_55.7541%2C37.6113_55.7548%2C37.6135_55.756%2C37.6151_55.7574%2C37.6163_55.7589%2C37.6179_55.7606%2C37.6187_55.7621%2C37.619_55.7637%2C37.6194_55.7651%2C37.6193_55.7667%2C37.6178_55.7679%2C37.6153_55.7683%2C37.6166_55.7678&offer_type=flat&polygon_name%5B1%5D=%D0%9E%D0%B1%D0%BB%D0%B0%D1%81%D1%82%D1%8C+%D0%BF%D0%BE%D0%B8%D1%81%D0%BA%D0%B0&room1=1&room2=1"
lJobItem = {
"SearchKeyStr": "_",
"SearchTitleStr": ", ", # Title of the search [str]
"SearchURLStr": lFilterURLStr,
# URL of the CIAN search [str]
}
OffersByJobExtractDict(inLogger = logging, inWebDriver = lWebDriver, inJob = lJobItem).
WEB open source pyOpenRPA. pyOpenRPA .
Desktop WEB . - .
, , .
!