介绍
哈Ha!
许多人喜欢上一部分,因此我再次整理了Boost文档的一半,并发现了一些需要写的东西。奇怪的是,boost.compute周围没有boost.asio周围的刺激。毕竟,该库是跨平台的,而且还提供了一个方便的接口(在c ++框架内),用于与GPU和CPU上的并行计算进行交互。
所有部分
- 第1部分
- 第2部分
内容
- 异步操作
- 自定义功能
- 不同模式下不同设备速度的比较
- 结论
异步操作
看起来会快得多吗?加速使用计算命名空间中的容器的一种方法是使用异步函数。 Boost.compute为我们提供了多种工具。其中,compute :: future类用于控制函数的使用,而copy_async(),fill_async()函数用于复制或填充数组。当然,也有用于处理事件的工具,但是没有必要考虑它们。以下是使用以上所有功能的示例:
auto device = compute::system::default_device();
auto context = compute::context::context(device);
auto queue = compute::command_queue(context, device);
std::vector<int> vec_std = {1, 2, 3};
compute::vector<int> vec_compute(vec_std.size(), context);
compute::vector<int> for_filling(10, context);
int num_for_fill = 255;
compute::future<void> filling = compute::fill_async(for_filling.begin(),
for_filling.end(), num_for_fill, queue); //
compute::future<void> copying = compute::copy_async(vec_std.begin(),
vec_std.end(), vec_compute.begin(), queue); //
filling.wait();
copying.wait();
这里没有什么特别的解释。前三行是所需类的标准初始化,然后是两个用于复制的向量,一个用于填充的向量,其变量将分别填充先前的向量和直接用于填充和复制的函数。然后,我们等待它们的执行。
对于使用STL处理std :: future的人来说,这里的一切都是一样的,只是在不同的命名空间中,没有std :: async()的类似物。
自定义计算功能
在上一部分中,我说过我将解释如何使用自己的方法来处理数据数组。我计算了3种方法:使用宏,使用make_function_from_source <>()以及对lambda表达式使用特殊的框架。
我将从第一个选项开始-宏。首先,我将附上示例代码,然后说明其工作方式。
BOOST_COMPUTE_FUNCTION(float,
add,
(float x, float y),
{ return x + y; });
第一个参数是返回值的类型,然后是函数的名称,其参数和函数的主体。此外,在名称add下,该函数可以在例如calculate :: transform()函数中使用。使用此宏与常规lambda表达式非常相似,但是我检查了它们是否起作用。
第二种方法(可能是最困难的方法)与第一种方法非常相似。我查看了前一个宏的代码,结果发现它使用了第二种方法。
compute::function<float(float)> add = compute::make_function_from_source<float(float)>
("add", "float add(float x, float y) { return x + y; }");
这里的一切比乍看之下显而易见,make_function_from_source()函数仅使用两个参数,其中一个是函数的名称,第二个是其实现。声明函数后,可以使用与实现宏之后相同的方式来使用它。
好吧,最后一个选择是lambda表达框架。用法示例:
compute::transform(com_vec.begin(),
com_vec.end(),
com_vec.begin(),
compute::_1 * 2,
queue);
作为第四个参数,我们指示我们要将第一个向量中的每个元素乘以2,一切都非常简单并且就地完成。
布尔表达式可以用相同的方式指定。例如,在compute :: count_if()方法中:
std::vector<int> source_std = { 1, 2, 3 };
compute::vector<int> source_compute(source_std.begin() ,source_std.end(), queue);
auto counter = compute::count_if(source_compute.begin(),
source_compute.end(),
compute::lambda::_1 % 2 == 0,
queue);
因此,我们已经计算了数组中的所有偶数,计数器将等于1。
不同模式下不同设备的速度比较
好吧,我在本文中要写的最后一件事是比较不同设备和不同模式(仅适用于CPU)上的数据处理速度。一般而言,这种比较将证明何时将GPU用于计算和并行计算。
我将进行如下测试:在所有设备上使用compute,我将调用compute :: sort()函数,以便对1亿个浮点值的数组进行排序。要测试单线程模式,请在相同大小的数组上调用std :: sort。对于每个设备,我将使用chrono标准库记录时间(以毫秒为单位),并将所有内容输出到控制台。
结果如下:

现在,我将仅对一千个值执行相同的操作。这次时间将以微秒为单位。

这次,单线程模式的处理器领先于所有人。由此得出的结论是,只有在涉及真正的大数据时,才需要进行这种操作。
我想做更多的测试,所以让我们做一个计算余弦,平方根和平方的测试。
在余弦的计算中,差异非常大(GPU在一个线程中的运行速度比CPU快60倍)。
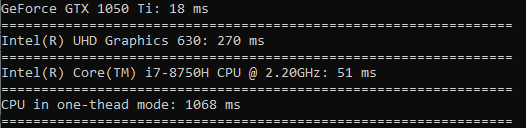
平方根的计算速度几乎与排序速度相同。
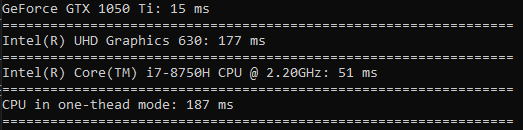
在平方上花费的时间与排序相比没有什么区别(GPU仅快3.5倍)。

结论
因此,在阅读本文之后,您学习了如何使用异步函数复制数组并填充数组。我们了解了您可以通过什么方式使用自己的函数对数据进行计算。并且还清楚地看到了何时应该使用GPU或CPU进行并行计算,以及何时可以使用一个线程。
我很高兴收到积极的反馈,感谢您的宝贵时间!
祝你们好运!