1什么是Voynich手稿?
Voynich手稿是一部神秘的手稿(抄本,手稿或只是一本书),大约有240页,大概是15世纪问世的。手稿于1912年由一位著名的碳素主义者作家埃塞尔·沃伊尼奇(Ethel Voynich)的丈夫-威尔弗雷德·沃伊尼奇(Wilfred Voynich)的一位古董商意外购得,并很快成为公众财产。
稿件的语言尚未确定。手稿的许多研究人员建议手稿的文本是加密的。其他人确信该手稿是用一种在当今我们所知的文字中无法幸免的语言编写的。还有一些人认为Voynich手稿是胡说八道(请参阅荒诞主义法典Seraphinianus的现代赞美诗)。
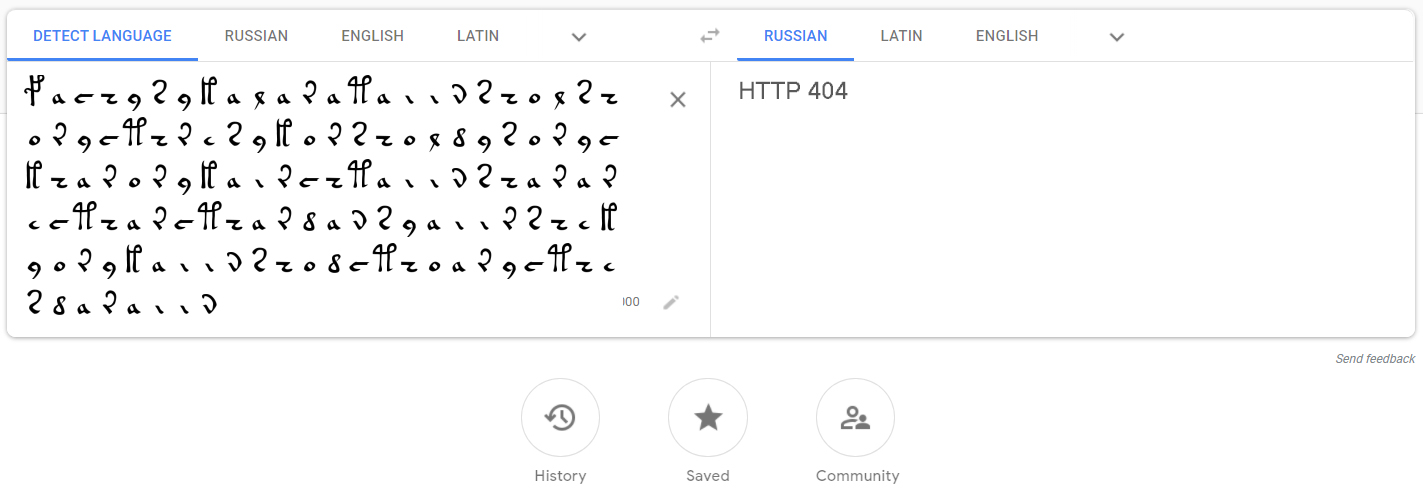
举例来说,我将提供带有文字和若虫的主题的扫描片段:

2为什么这个古怪的手稿如此有趣?
也许这是伪造的晚?显然不是。与都灵裹尸布不同,放射性碳分析和其他对羊皮纸的古老性提出质疑的尝试都没有给出明确的答案。但是Voynich不可能在20世纪初预见到同位素分析……
但是,如果手稿是一组顽皮的僧侣笔下毫无意义的信件,那是一位意识形态改变了的贵族呢?不,绝对不是。例如,我会毫不注意地敲击按键,以描绘大家熟悉的已调制QWERTY键盘白噪声,例如“ asfds dsf”。笔迹学检查表明,提交人用坚定的手书写了他所熟知的字母符号。另外,手稿文本中字母和单词的分布相关性对应于“活着的”文本。例如,在有条件地分为6个部分的手稿中,通常在其中一个部分中找到“特有”一词,而在其他部分中却没有。
但是,如果手稿是一个复杂的密码,并且试图破解它在理论上是没有意义的,该怎么办?如果我们相信文字的古老年代,那么加密版本的可能性就很小。中世纪本可以只提供一个替代密码,埃德加·爱伦·坡(Edgar Allan Poe)轻松而优雅地破解了它。同样,对于绝大多数密码,文本中字母和单词的相关性并不常见。
尽管在翻译古代文字方面取得了巨大的成功,包括使用现代计算资源,但伏依尼奇手稿仍然无视经验丰富的专业语言学家或年轻的野心勃勃的数据科学家。
3但是如果我们知道手稿的语言该怎么办
...但是拼写不同吗?例如,谁在此文本中识别拉丁语?

这是另一个示例-将英文文本音译为希腊文:
in one of the many little suburbs which cling to the outskirts of london
ιν ονε οφ θε μανυ λιττλε συμπυρμπσ whιχ cλιγγ το θε ουτσκιρτσ οφ λονδονPython的Transliterate库。注意:这不再是替换密码-一些多字母组合以一个字母传输,反之亦然。
我将尝试识别(分类)手稿的语言,或者从已知的语言中找到与之最接近的手稿,突出其特征并对其进行训练:
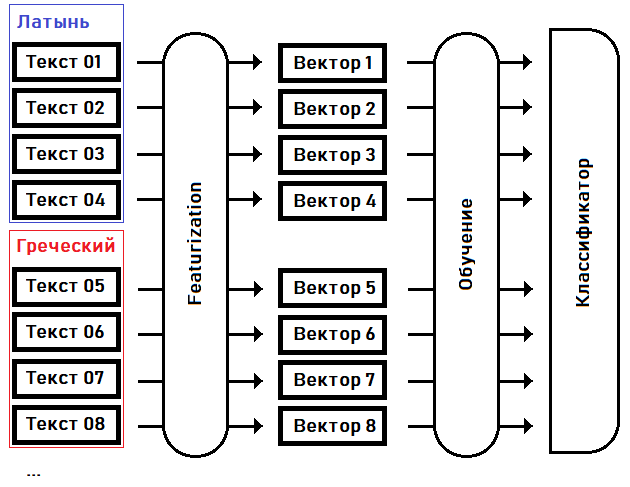
在第一阶段-特征化-我们将文本转换为特征向量:固定大小的实数数组,其中向量的每个维负责源文本自身的特殊特征(特征)。例如,让我们在向量的第15维上达成一致,以保持文本中最常见单词的出现频率,在第16维上-第二受欢迎的单词......在第N维上-相同重复单词序列的最长长度等。
在第二步(训练)中,我们基于对每种文本的语言的先验知识来选择分类器的系数。
训练完分类器后,我们可以使用此模型来确定训练样本中未包含的文本的语言。例如,对于伏尼契手稿的文本。
4画面是如此简单-有什么收获?
棘手的部分是如何准确地将文本文件转换为矢量。将小麦与谷壳分开,仅保留作为语言整体特征的那些特征,而不是每个特定的文本。
如果为简化起见,如果我们将源文本转换为编码(即数字),然后将其“馈送”到许多神经网络模型之一中,则结果可能不会令我们满意。最有可能的是,根据此类数据训练的模型将与字母相关联,并且该模型首先基于符号来尝试确定未知文本的语言。
但是手稿的字母“没有类似物”。而且,我们不能完全依靠字母分布中的模式。从理论上讲,也可以按照另一种语言的规则来转移一种语言的语音(该语言是Elvish-符文是Mordor)。
狡猾的抄写员没有使用我们所知道的标点符号或数字。可以将所有文本视为单词流,分为多个段落。甚至不确定一句话在哪里结束而另一句话在哪里开始。
这意味着我们将相对于字母提升到更高的水平,并且我们将依靠单词。我们将基于手稿的文本来编译字典,并在单词级别上跟踪模式。
5手稿原文
当然,您不需要自己将Voynich手稿的复杂字符编码为Unicode等价字符,反之亦然,例如,在这里,我们已经为我们完成了这项工作。使用默认选项,我得到的内容与手稿的第一行等效:
fachys.ykal.ar.ataiin.shol.shory.cth!res.y.kor.sholdy!-句号和感叹号(以及EVA字母中的许多其他字符)只是分隔符,出于我们的目的,可以将它们替换为空格。问号和星号是无法识别的单词/字母。
为了进行验证,让我们在此处替换文本并获得手稿的片段:
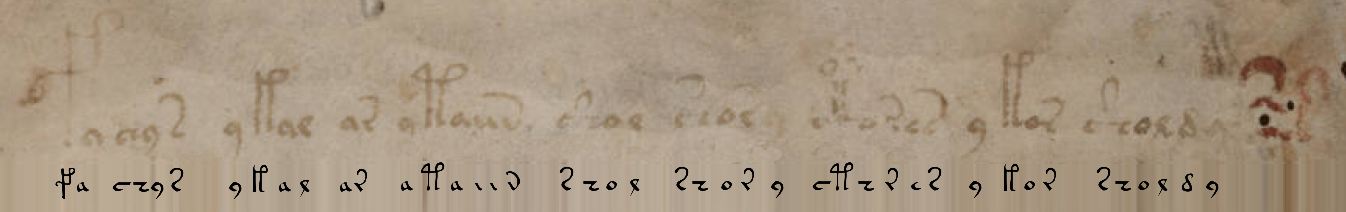
6程序-文本分类器(Python)
这是代码存储库的链接,其中包含您需要测试实际代码的最少README提示。
我收集了20多种拉丁语,俄语,英语,波兰语和希腊语的文本,试图将每个文本的数量保持在±35,000个单词(Voynich手稿的数量)内。
我尝试用一种拼写方式选择接近的约会文本-例如,在俄语文本中,我避免使用字母Ѣ,而用不同的变音符号写希腊字母的变体导致了一个共同的分母。我还从文本中删除了数字和特价。字符,多余的空格,将字母转换为一种大小写。
下一步是构建包含以下信息的“字典”:
- 文本中每个单词的使用频率,
- 单词的“根”-或更确切地说,一组单词的不变部分,
- 通用的“前缀”和“结尾”-或更确切地说,单词的开头和结尾以及构成实际单词的“根”,
- 2个和3个相同单词的共同序列及其出现的频率。
我将单字的“根”用引号引起来-例如,一种简单的算法(有时甚至是我本人)无法确定“支持”一词的根是什么?通过成为ka?下率?
一般而言,该词汇表是用于构建特征向量的半准备数据。我为什么要挑出这个阶段-为每种语言以及每种语言的一组文本编译和缓存字典?事实是,建立这样的字典需要很长时间,每个文本文件大约需要半分钟。我已经有120多个文本文件。
7功能化
获得特征向量仅仅是进一步分类器的一个初步阶段。当然,作为OOP怪胎,我为上游逻辑创建了一个抽象类BaseFeaturizer,以免违反依赖反转的原理。该类的后代可以将一个或多个文本文件立即转换为数值向量。
同样,继承者类必须为每个单独的特征(特征向量的i坐标)命名。如果我们决定可视化分类的机器逻辑,这将派上用场。例如,向量的第0维将被标记为CRw1-从相邻位置(滞后1)处的文本中提取的单词频率的自相关。
从BaseFeaturizer类,我继承了该类WordMorphFeaturizer,其逻辑基于整个文本中以及12个单词的滑动窗口内单词的使用频率。
一个重要方面是,除了文本本身之外,BaseFeaturizer的特定继承者的代码还需要根据其基础编写的词典(CorpusFeatures类),这些词典很可能在开始训练和测试模型时已缓存在磁盘上。
8分类
下一个抽象类是BaseClassifier。可以训练该对象,然后通过文本的特征向量对文本进行分类。
为了实现(RandomForestLangClassifier类),我从sklearn库中选择了Random Forest Classifier算法。为什么使用这个特定的分类器?
- 随机森林分类器的默认参数适合我,
- 它不需要规范化输入数据,
- 提供了决策算法的简单直观的可视化。
由于我认为随机森林分类器可以很好地完成其任务,因此我没有编写任何其他实现。
9培训和测试
随机选择了80%的文件(这些文件来自拜伦,阿克萨科夫,阿普列乌斯,保罗·帕萨尼亚斯和其他作者的作品,我可以以txt格式找到它们的文本)来训练分类器。其余20%(28个文件)已确定用于样本外测试。
当我在大约30种英语和20种俄语文本上测试分类器时,分类器给出了很大的错误率:在几乎一半的情况下,文本的语言确定不正确。但是当我以5种语言(俄语,英语,拉丁语,古希腊语和波兰语)启动〜120个文本文件时,分类器停止犯错并开始正确识别28个测试用例中27-28个文件的语言。
然后,我使问题复杂了一些:我将19世纪的爱尔兰小说《瑞秋·格雷》(Rachel Gray)转录成希腊文,并将其提交给训练有素的分类员。再次正确定义了音译文本的语言。
10分类算法清晰
这就是经过训练的“随机森林分类器”中的100棵树之一(为了使图像更具可读性,我切除了右子树的3个节点):(
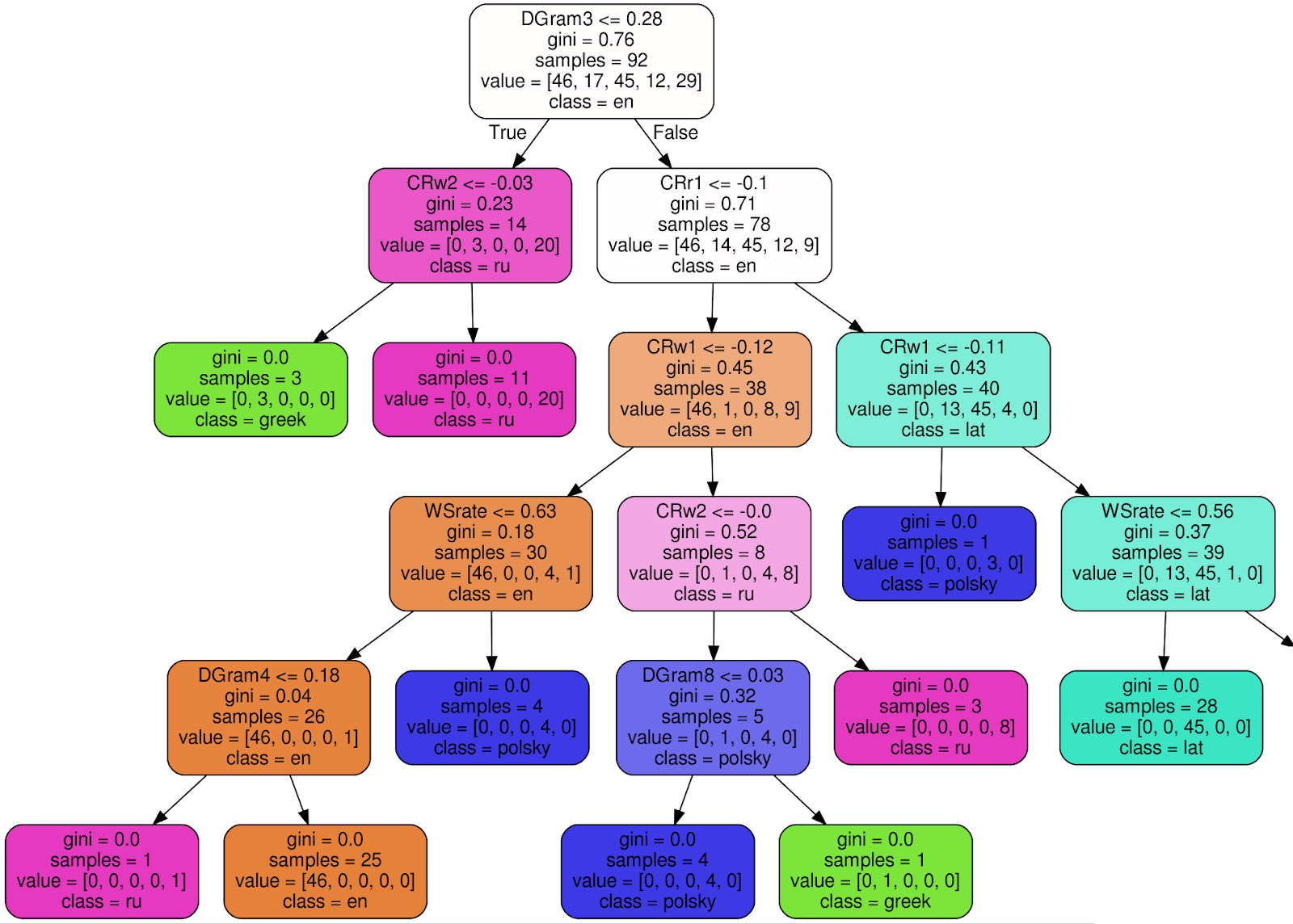
以根节点为例,我将解释每个签名的含义:
- DGram3 <= 0.28-分类标准。在这种情况下,DGram3是由WordMorphFeaturizer类命名的特征向量的特定维,即在12个单词的滑动窗口中第三最常见单词的频率,
- gini = 0.76 — , Gini impurity, , , . , , - . . , gini, , 0 ( ),
- samples = 92 — , ,
- value = [46, 17, 45, 12, 29] — , (46 , 17 , 45 ..),
- class = en ( ) — .
如果满足条件(对于根节点,DGram3 <= 0.28),请转到左侧的子树,否则-转到右侧。在每一页中,所有文本应分配给一个类别(语言),基尼不确定性标准criterion0。
最后的决定是由在分类器训练期间构建的100棵相似树组成的集合。
11该程序如何定义手稿的语言?
拉丁语,概率估计为0.59。当然,这还不是解决本世纪问题的方法。
手稿字典和拉丁语字典之间一一对应是很困难的,即使不是不可能的。例如,以下是十个最常用的单词:Voynich手稿,拉丁语,

古希腊语和俄语:
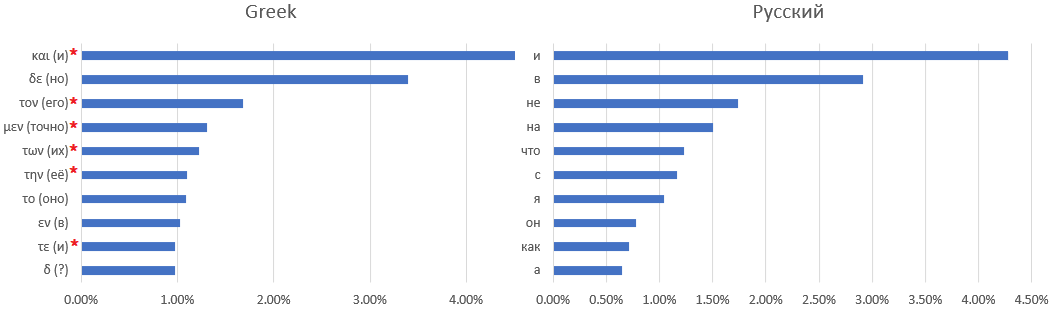
星号标记的单词很难找到与俄语等效的单词-例如,文章或介词会根据上下文而改变含义。
明显的匹配
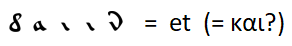
扩展了用其他常用词替换字母的规则,我找不到。您只能做假设-例如,最常见的词是连词“ and”-除英语以外的所有其他语言都考虑过,在英语中,定冠词“ the”将连词“ and”推到第二位。
下一步是什么?
首先,如果可能的话,有必要尝试用现代法语,西班牙语,...,中东语言的文本补充语言样本-旧英语,法语(15世纪之前)等。即使这些语言都不是手稿的语言,已知语言定义的准确性仍会提高,并且可能会选择与手稿语言更接近的等效语言。
一个更具创造性的挑战是尝试为每个单词定义词性。对于多种语言(当然首先是英语),PoS(词性)令牌生成器作为可供下载的软件包的一部分,可以很好地完成此任务。但是,如何确定未知语言中单词的作用呢?
苏联语言学家B.V.也解决了类似的问题。 Sukhotin-例如,他描述了算法:
- 将未知字母的字符分隔为元音和辅音-不幸的是,不是100%可靠的,特别是对于具有非平凡语音的语言,例如法语,
- 文本中不带空格的词素选择。
对于PoS标记化,我们可以基于单词的使用频率,2/3个单词的组合出现,单词在文本各部分中的分布:并集和粒子应比名词更均匀地分布。
文学
我不会在这里留下NLP书籍和教程的链接-在网络上就足够了。取而代之的是,我将列出对我来说是一个伟大发现的艺术品,小时候,英雄们必须努力工作才能解开密文:
- E. A. Poe:金甲虫是永恒的经典
- 巴本科(V. Babenko):“会议”是80年代后期著名的,有点前瞻性的侦探小说,
- K. Kirita:“来自Chereshnevaya街上的骑士,或穿白衣服的女孩的城堡”是一本引人入胜的少年小说,对于读者的年龄而言,这本书并不打折。